
集群搭建
Win10 64位系统;Vmware 12; Ubuntu12
jdk-7u80-linux-x64.rpm;Hadoop-2.7.1.tar.gz;scala-2.11.6.tgz;spark-2.0.1-bin-hadoop2.7.tgz
192.168.86.128 master host;文件最后一行
192.168.86.132 slave1
192.168.86.133 slave1; SSH 免密登陆
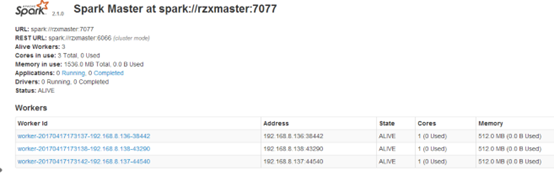
访问192.168.8.137:8085(8085端口是设置在spark-env.sh中的SPARK_MASTER_WEBUI_PORT,可自行设置),结果如下:则说明成功了. Flume,kafka,hive组建进一步安装
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkConf = new SparkConf().setAppName("LauncherStreaming")
//每60秒一个批次
val ssc = new StreamingContext(sparkConf, Seconds(60))
// 从Kafka中读取数据
val kafkaStream = KafkaUtils.createStream(
ssc,
"hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181", // Kafka集群使用的zookeeper
"launcher-streaming", // 该消费者使用的group.id
Map[String, Int]("launcher_click" -> 0, "launcher_click" -> 1), // 日志在Kafka中的topic及其分区
StorageLevel.MEMORY_AND_DISK_SER).map(_._2) // 获取日志内容
kafkaStream.foreachRDD((rdd: RDD[String], time: Time) => {
val result = rdd.map(log => parseLog(log)) // 分析处理原始日志
.filter(t => StringUtils.isNotBlank(t._1) && StringUtils.isNotBlank(t._2))
// 存入hdfs
result.saveAsHadoopFile(HDFS_DIR, classOf[String], classOf[String], classOf[LauncherMultipleTextOutputFormat[String, String]])
})
ssc.start()
// 等待实时流
ssc.awaitTermination()
}
1. 使用三台虚拟机搭建Hadoop集群
2. 一定要在每台机器上配置ssh免密码登录
3. 由于需要给/etc/hosts文件配置3台虚拟机的IP,所以尽量给三台虚拟机设置静态IP。不然即使之前整个集群搭建成功了,但是当某一台的IP变化后,这个集群又不可以使用了。
4. 对文件/etc/profile修改后,一定要使用source /etc/profile去执行一遍,不然配置的环境变量不会生效。
5. 重启虚拟机后,需要重新启动Hadoop,启动成功后,除了hadoop/bin目录之外,在其他地方使用hadoop命令报错“命令不存在”,很有可能是需要使用source /etc/profile来使该文件中关于hadoop安装位置的环境变量生效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号