Lucene
1 Lucene简介
Lucene是apache下的一个开源的全文检索引擎工具包。
1.1 全文检索(Full-text Search)
1.1.1 定义
全文检索就是先分词创建索引,再执行搜索的过程。
分词:就是将一段文字分成一个个单词
全文检索就将一段文字分成一个个单词去查询数据!!!
1.1.2 应用场景
1.1.2.1 搜索引擎(了解)
搜索引擎是一个基于全文检索、能独立运行、提供搜索服务的软件系统。
|
1.1.2.2 电商站内搜索(重点)
思考:电商网站内,我们都是通过输入关键词来搜索商品的。如果我们根据关键词,直接查询数据库,会有什么后果?
答:我们只能使用模糊搜索,来进行匹配,会导致很多数据匹配不到。所以,我们必须使用全文检索。
|
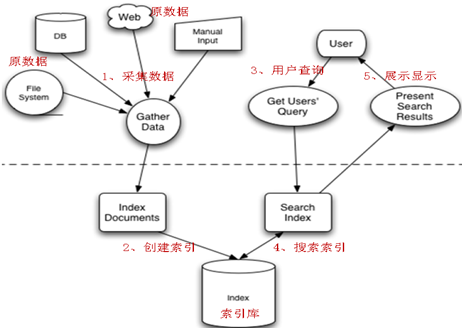
1.2 Lucene实现全文检索的流程
|
全文检索的流程分为两大部分:索引流程、搜索流程。
索引流程:采集数据--->构建文档对象--->创建索引(将文档写入索引库)。
搜索流程:创建查询--->执行搜索--->渲染搜索结果。
索引流程
第一步:采集数据
Lucene全文检索,不是直接查询数据库,所以需要先将数据采集出来。
(1)创建Book类


public class Book { private Integer bookId; // 图书ID private String name; // 图书名称 private Float price; // 图书价格 private String pic; // 图书图片 private String description; // 图书描述 // 补全get\set方法 }
(2)创建一个BookDao类
public class BookDao { public List<Book> getAll() { // 数据库链接 Connection connection = null; // 预编译statement PreparedStatement preparedStatement = null; // 结果集 ResultSet resultSet = null; // 图书列表 List<Book> list = new ArrayList<Book>(); try { // 加载数据库驱动 Class.forName("com.mysql.jdbc.Driver"); // 连接数据库 connection = DriverManager.getConnection( "jdbc:mysql://localhost:3306/lucene", "root", "gzsxt"); // SQL语句 String sql = "SELECT * FROM book"; // 创建preparedStatement preparedStatement = connection.prepareStatement(sql); // 获取结果集 resultSet = preparedStatement.executeQuery(); // 结果集解析 while (resultSet.next()) { Book book = new Book(); book.setBookId(resultSet.getInt("id")); book.setName(resultSet.getString("name")); book.setPrice(resultSet.getFloat("price")); book.setPic(resultSet.getString("pic")); book.setDescription(resultSet.getString("description")); list.add(book); } } catch (Exception e) { e.printStackTrace(); }finally { if(null!=resultSet){ try { resultSet.close(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(null!=preparedStatement){ try { preparedStatement.close(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(null!=connection){ try { connection.close(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } return list; } }
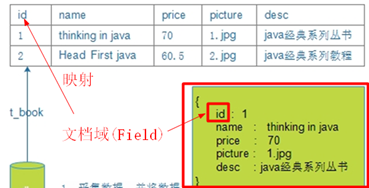
第二步:将数据转换成Lucene文档
Lucene是使用文档类型来封装数据的,所有需要先将采集的数据转换成文档类型。其格式为:
public List<Document> getDocuments(List<Book> books){ // Document对象集合 List<Document> docList = new ArrayList<Document>(); // Document对象 Document doc = null; for (Book book : books) { // 创建Document对象,同时要创建field对象 doc = new Document(); // 根据需求创建不同的Field Field id = new TextField("id", book.getBookId().toString(), Store.YES); Field name = new TextField("name", book.getName(), Store.YES); Field price = new TextField("price", book.getPrice().toString(),Store.YES); Field pic = new TextField("pic", book.getPic(), Store.YES); Field desc = new TextField("description", book.getDescription(), Store.YES); // 把域(Field)添加到文档(Document)中 doc.add(id); doc.add(name); doc.add(price); doc.add(pic); doc.add(desc); docList.add(doc); } return docList; }
第三步:创建索引库
说明:Lucene是在将文档写入索引库的过程中,自动完成分词、创建索引的。因此创建索引库,从形式上看,就是将文档写入索引库!
搜索流程
说明:搜索的时候,需要指定搜索哪一个域(也就是字段),并且,还要对搜索的关键词做分词处理。
public void searchDocumentByIndex(){ try { // 1、 创建查询(Query对象) // 创建分析器 Analyzer analyzer = new StandardAnalyzer(); QueryParser queryParser = new QueryParser("name", analyzer); Query query = queryParser.parse("name:java教程"); // 2、 执行搜索 // a) 指定索引库目录 Directory directory = FSDirectory.open(new File("F:\\lucene\\0719")); // b) 创建IndexReader对象 IndexReader reader = DirectoryReader.open(directory); // c) 创建IndexSearcher对象 IndexSearcher searcher = new IndexSearcher(reader); // d) 通过IndexSearcher对象执行查询索引库,返回TopDocs对象 // 第一个参数:查询对象 // 第二个参数:最大的n条记录 TopDocs topDocs = searcher.search(query, 10); // e) 提取TopDocs对象中前n条记录 ScoreDoc[] scoreDocs = topDocs.scoreDocs; System.out.println("查询出文档个数为:" + topDocs.totalHits); for (ScoreDoc scoreDoc : scoreDocs) { // 文档对象ID int docId = scoreDoc.doc; Document doc = searcher.doc(docId); // f) 输出文档内容 System.out.println("==============================="); System.out.println("文档id:" + docId); System.out.println("图书id:" + doc.get("id")); System.out.println("图书name:" + doc.get("name")); System.out.println("图书price:" + doc.get("price")); System.out.println("图书pic:" + doc.get("pic")); System.out.println("图书description:" + doc.get("description")); } // g) 关闭IndexReader reader.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号