中文分词方法以及一些算法
对于搜索引擎的搜索准确度影响很大
1.基于字符串匹配(机械分词) 一般作为一个初分手段
(1)正向最大匹配法(需要充分大的词典)
例子: 将句子 ’ 今天来了许多新同事 ’ 分词。 设最大词长为5
今天来了许
今天来了
今天来
今天 ====》 得到一个词 – 今天
来了许多新
来了许多
来了许
来了
来 ====》 得到一个词 – 来
了许多新同
了许多新
了许多
了许
了 ====》 得到一个词 – 了
许多新同事
许多新同
许多新
许多 ====》得到一个词 – 许多
新同事
新同
新 ====》得到一个词 – 新
同事 ====》得到一个词 – 同事
最后正向最大匹配的结果是:/今天/来/了/许多/新/同事/
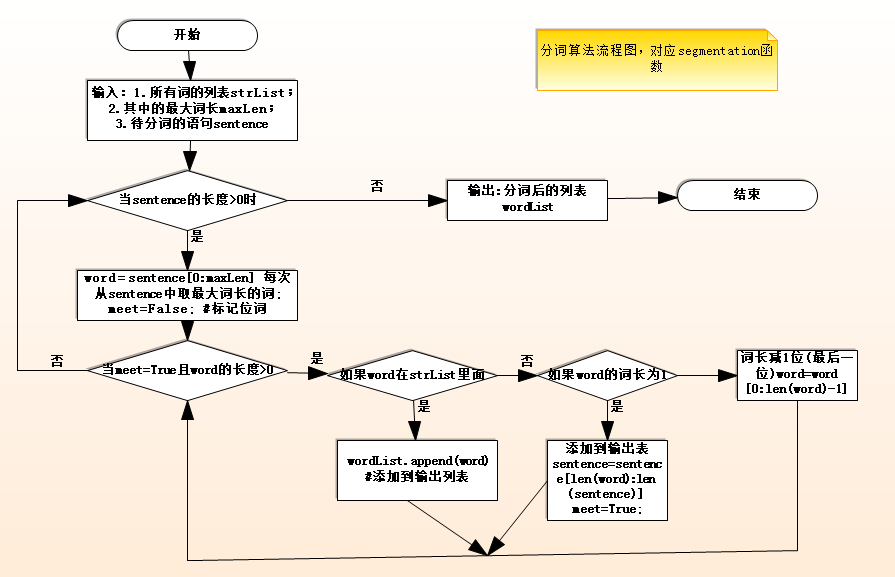
缺陷:效率不高,尤其对于长文本分词、精确度不高、不能解决词的歧义问题
(2)逆向最大匹配
与正向最大匹配法大致相同,方向相反, 逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少
(3)最小切分法
使每一句切分出来的词数最少
(4)双向匹配法
结合正向最大与逆向最大方法
2.基于统计
定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧 密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。
配合词典
主要统计模型为:N元文法模型(N-gram)、隐马尔科夫模型(Hidden Markov Model, HMM)
bigram、trigram
全切分方法,找出最优切分,优点在于可以发现 新词并且可以发现切分歧义。
3.基于理解
其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义 现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。
