第二十二篇 正在表达式 re模块
re模块******
就本质而言,正则表达式时一种小型的,高度专业化的编程语言,在python里,它内嵌在python中,并通过re模块实现。正则表达式模式被编译成一系列的字节码。然后用C编写的匹配引擎执行。
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
说白了,正则就是用来处理字符串的。
简言之,正则就是给字符串进行模糊匹配
正则的用途: 1. 模糊匹配 2. 应用场景如:一个文本里存了一堆身份证号,要找到北京市的且1990年后出生的人 这个例子可以不用正则也能实现,但是用正则实现更简单 举例正则就可以这么实现: ^110.......1990 + * 3. 还有一些场景,不用正则是实现不了。
字符串匹配:普通字符、元字符(特殊符号)。
1. 普通字符:大多数字符和字母都会自身匹配
hello = 'nihaoa alex teacher' # 之前也学过其他的处理字符串的方法,比如find,split,但是这些方法都是精确查找,完全匹配的方法,如果想实现模糊查找就完不成目标了,然而正则就可以解决这个问题。 print(hello.find('alex'))
2. 元字符:. ^ $ * + ? {} [] () | \
元字符给我们提供了很多模糊匹配的可能。
学正则其实就学这些元字符和6个方法。
findall(pattern, string, flags=0): pattern表示匹配的规则,string表示要在哪个字符串里进行匹配。
findall()会把所有匹配的结果都拿出来。
- 第一个元字符 点 .
点:是通配符,除了换行符\n不能替代之外,其他什么都可以代替,如数字,字母,特殊字符等等。
记住:一个点,只能代表一个字符,不能代表多个字符。
import re hello = 'nihaoa alex teacher,a24x,a234x' # 匹配出以a开头,以x结尾的字符 # 记住:一个点,只能代表一个字符,不能代表多个字符。 print(re.findall('a..x', hello)) # ['alex', 'a24x'] print(re.findall('a...x', hello)) # ['a234x'] # 如果有多个字符需要用.匹配,怎么简写呢?
[答】这个问题涉及到重复的问题,关于重复后面会有四个元字符来满足这个简写的功能。分别是 * + ? {}
- 第二个元字符:^
尖角号(^):表示以什么开头的意思。匹配字符串的开头,开头能匹配上,返回结果;开头匹配不上,就终止,返回空列表。
import re hello1 = 'nihaoa alex teacher,a24x,a234x' hello2 = 'alexawwxteacher,a24x,a234x' # ^:匹配以 某字符串 开头。
# 意思是,要去匹配hello1 和 hello2这两个字符串的开头,看他的开头是不是以 "a..x" 这样的四个字符串开头的
# 能匹配到,就返回匹配结果;没有匹配到就返回空列表 print(re.findall('^a..x', hello1)) # [] print(re.findall('^a..x', hello2)) # ['alex']
- 第三个元字符:$
美元符($):表示以什么字符串结尾的意思。匹配字符串的末尾。
import re hello1 = 'nihaoa alex teacher,a24x,a234x' hello2 = 'alexawwxteacher,a24x,a234x' hello3 = 'alexawwxteacher,a24x,a234x$' # $: 匹配以 某字符串结尾 # 意思是,要去匹配hello1 和 hello2这两个字符串的结尾,看他们的结尾是不是以 "a...x" 这样的五个字符串结尾的 print(re.findall('a..x$', hello1)) # [] print(re.findall('a...x$', hello2)) # ['a234x'] print(re.findall('a...x$', hello3)) # []
- 第四个元字符:*
-
*是按照星号紧挨着的字符去重复, 重复范围是0到无穷次。匹配的时候是按照最多的来匹配
import re hello = 'assddjkfdsdddddsdfdadffffffddd' # * 是匹配0到无穷次的内容 print(re.findall('d*', hello)) # 结果 ['', '', '', 'dd', '', '', '', 'd', '', 'ddddd', '', 'd', '', 'd', '', 'd', '', '', '', '', '', '', 'ddd', ''] # 预期的结果好像与我们的想想不一样,为什么? # 【答】因为 * 的匹配范围是[0,无穷大),所以第一个字符是a, 也算是匹配上了。 #上面的例子并不好,换一个 import re hello = 'dddfjakffdjkfddfderqerqeddddd' print(re.findall('^d*', hello)) # 结果 ['ddd'] # 与* 对应的有一个元字符,是 + 号
- 第五个元字符:+
+ 号匹配的范围是[1,无穷次),意思是匹配字符至少得有一个。
# 这个被匹配字符串都有x,看不出区别 print(re.findall("alex*", "asdhfalexxxx")) # ['alexxxx'] print(re.findall("alex+", "asdhfalexxxx")) # ['alexxxx'] # 下面两个例子,被匹配字符串没有x,就能看出区别了 print(re.findall("alex*", "asdhfale")) # 结果 ['ale'] # 解释:因为*的匹配范围是[0,无穷次),即使没有x,也算是匹配上了 print(re.findall("alex+", "asdhfale")) # 结果 [] # 解释:因为 + 的匹配范围是[1,无穷次),+ 号紧挨着的字符,在被匹配字符里必须至少有一个,才能匹配上
- 第六个元字符:?
?的匹配范围是[0,1],表示它可以匹配0次,或1次,只有这两个值。
print(re.findall("alex?", "asdhfalexxxx")) # ['alex'] print(re.findall("alex?", "asdhfale")) # ['ale']
- 第七个元字符:{}
{}的匹配范围是你自己定义的。
{0,}:相当于 *
{1,}:相当于 +
{0,1}:相当于 ?
{6}:相当于重复6次
{1,6}:可以重复1,2,3,4,5,6里面的任何一个
print(re.findall("alex{0,}", "asdhfalexxxx")) # ['alexxxx'] print(re.findall("alex{1,}", "asdhfalexxxx")) # ['alexxxx'] print(re.findall("alex{0,1}", "asdhfalexxxx")) # ['alex'] print(re.findall("alex{0,1}", "asdhfale")) # ['ale'] # 代表重复x6次 print(re.findall("alex{6}", "asdhfalexxxx")) # [] print(re.findall("alex{6}", "asdhfalexxxxxxxx")) # ['alexxxxxx'] print(re.findall("alex{1,6}", "asdhfalexxxxxxxxxx")) # ['alexxxxxx']
再看几个例子,总结一下
print(re.findall("a..in", "helloalvin")) # ['alvin'] print(re.findall("^a...n", "alvinhelloalvin")) # ['alvin'] print(re.findall("a...n$", "alvinhelloalvin")) # ['alvin'] print(re.findall("abc*", "abcccc")) # 贪婪匹配[0,+∞) # ['abcccc'] print(re.findall("abc+", "abcccc")) # 贪婪匹配[1,+∞) # ['abcccc'] print(re.findall("abc?", "abcccc")) # 匹配[0,1] # ['abc'] print(re.findall("abc{1,3}", "abccc")) #匹配[1,4] # ['abccc']
- 惰性匹配
注意:
有 * + ? 的都是贪婪匹配,也就就是尽可能多的匹配;
但是如果在 * +的后面加?可以使其变成惰性匹配,所谓惰性匹配,就是按照最少的去匹配
print(re.findall("alex*?", "helloalvinalexxxxxxx")) # ['ale'] # 解释:* 匹配范围是[0,+∞), 所以匹配上0次就可以算匹配成功了,*可以代表0了,所以匹配到ale就行了,后面就不匹配了 print(re.findall("alex+?", "helloalvinalexxxxxxx")) # ['alex'] # 解释:+ 匹配范围是[1,+∞), 所以匹配上1次就可以算匹配成功了,+可以代表1了,所以匹配到alex就行了,后面的x就不匹配了
- 第八个元字符:[ ] (********************的重要)
[ ]的学名叫字符集,[ ]字符集的作用: 或的作用
import re ''' []字符集的第1个作用:或的作用 ''' print(re.findall("x[yz]", "x")) # [] print(re.findall("x[yz]", "xy")) # ['xy'] print(re.findall("x[yz]", "xyuuu")) # ['xy'] print(re.findall("x[yz]", "xyuuxzuu")) # ['xy', 'xz'] print(re.findall("x[yz]", "xzzzyyzz")) # ['xz'] print(re.findall("x[yz]p", "xyzzpxzyzzp")) # [] print(re.findall("x[yz]p", "xyzzpxzpyzz")) # ['xzp'] print(re.findall("x[yz]p", "xypuuxzpuu")) # ['xyp', 'xzp'] print(re.findall("x[y,z]p", "xypuuxzpuu")) # ['xyp', 'xzp'] # []里面加个逗号(,), 没有特殊作用,与y z一样,就是个普通符合,构成了三种可以匹配的组合:xyp, x,p xzp print(re.findall("x[y,z]p", "xypuuxzpuu,pu")) # ['xyp', 'xzp'] print(re.findall("x[y,z]p", "xypuuxzpuux,pu")) # ['xyp', 'xzp', 'x,p']
1. [ ] 字符集里有特殊功能的特殊符号: -
- 的特殊意义:表示范围。
[ ] 字符集只有三个符号 - ^ \ 有特殊意义,其他符号都没有特殊意义。
# 记住:[]里面没有特殊符号,除了 - ^ \ print(re.findall("q[a*z]", "kssadfkq")) # [] 匹配不到,因为[]里至少还有一个字母需要匹配 print(re.findall("q[a*z]", "kssadfkqaaa")) # ['qa'] 前面讲过,*代表重复,但是放到[]字符集里,她就是个普通字符,没有其他特殊意义,构造三种组合 qa q* qz print(re.findall("q[a*z]", "kssadfkqaaaq**")) # ['qa', 'q*'] # 在[] 有特殊符号 - # 特殊意义:- 代表着范围,也就是a-z # 所以,下面的q后面随便跟一个a~z的字符,就能匹配到 print(re.findall("q[a-z]", "qu")) # ['qu'] # [a-z]也只代表一个字符,也就是可以是qa,qb,qc,qd,qe......qz等26个组合, 只要匹配到一个就停止匹配了 print(re.findall("q[a-z]", "quiuo")) # ['qu'] # [a-z]*:表示a-z 26个字母可以重复 print(re.findall("q[a-z]*", "quiuofdfafad")) # ['quiuofdfafad'] print(re.findall("q[a-z]*", "quiuofdfafad9")) # ['quiuofdfafad'] # print(re.findall("q[0-9]*", "quiuofdffafad9")) # ['q'] # 解释: # 对这个结果别意外, 虽然"quiuofdffafad9" q后面没有紧挨着的数字, # 但是 因为*的匹配范围是[0,+∞), 就是没匹配到的但也算匹配上了。所以结果是q print(re.findall("q[0-9]*", "quiuofdffqafad9")) # ['q', 'q'] print(re.findall("q[0-9]*", "quiuq89ofdffqafad9")) # ['q', 'q89', 'q'] print(re.findall("q[A-Z]*", "quiuq89ofdffqafad9")) # ['q', 'q', 'q']
2. [ ] 字符集里有特殊功能的特殊符号: ^
特别要注意的:[ ]字符集里的^ 与 上面讲的放在开头的^ 有天大的区别。
放在[ ]里的^ 的特殊意义:表示 非。 举例 q[^a-z] 表示 只要不是a-z里的都能匹配上
print(re.findall("q[^a-z]", "q123")) # ['q1'] print(re.findall("q[^a-z]", "qab")) # [] print(re.findall("q[^a-z]", "qz")) # [] print(re.findall("q[^a-z]", "quiuq89ofdffqafad9")) # ['q8'] # 需求:怎么把(2-1)提出来? print(re.findall("\([^()]*\)", "12+(34*6+2-5*(2-1))")) # ['(2-1)'] # 解释: ''' 元字符()是有特使意义的,如果要把()变成普通字符,要加个 斜杠\ 1. \( 表示以(开头, \) 表示以 )结尾 2. 中间得是没有()的, 才代表着最里层。所以要写给字符集[ ],字符集里写[^()]:表示非(),且是一个字符 3. 第一步和第二步已经匹配出来了以(开头,以)结尾,但是()里面有多少字符,都是啥你并不知道,所以要在[]外面加个 * 统配 '''
3. [ ] 字符集里有特殊功能的特殊符号: \ 转义付
\ 的特殊意义,也是最重要的一个:
(1)能让有功能的符号变为没功能(\后跟元字符,去重特殊功能, 比如 \.)
(2)也能让没功能的符号变为有功能(\后跟普通字符,实现特殊功能,比如 \d)
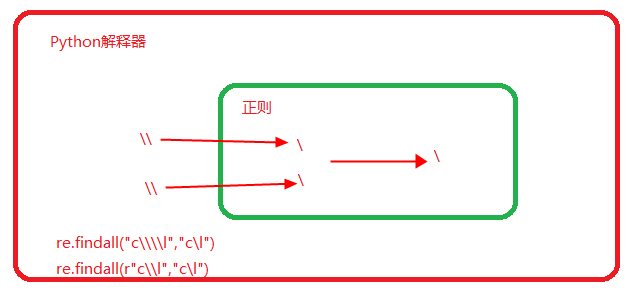
#### \ 让没有意义的字符,变得有意义#### \d: 匹配任何十进制数, \d 代表 [0 -9 ] 的任何一个数字,只代表一个数字,相当于 [0-9] \d+:匹配任何十进制数, \d+只代表多个数字组合在一起,相当于 [0-9]+ \D:匹配任何非数字字符, 相当于 [^0 - 9] print(re.findall("\d", "12+(34*6+2-5*(2-1))")) # ['1', '2', '3', '4', '6', '2', '5', '2', '1'] print(re.findall("\d+", "12+(34*6+2-5*(2-1))")) # ['12', '34', '6', '2', '5', '2', '1'] print(re.findall("\D+", "12+(34*6+2-5*(2-1))")) # ['+(', '*', '+', '-', '*(', '-', '))'] \s: 匹配任何空白字符,相当于[\t\n\r\f\v] \S: 匹配任何非恐怖字符,相当于[^\t\n\r\f\v] \S+:匹配任何非恐怖字符,字符可以组合在一起 # 可以取出空格 print(re.findall("\s", "hello wor ld!")) # [' ', ' ', ' '] print(re.findall("\s+", "hello world!")) # [' '] print(re.findall("\S", "hello world!")) # ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd', '!'] print(re.findall("\S+", "hello world!")) # ['hello', 'world!'] \w:匹配任何字母数字字符及下划线,相当于[a-zA-Z0-9_] \W:匹配任何非字母数字字符及非下划线,相当于[^a-zA-Z0-9_] print(re.findall("\w", "[a-zA-Z0-9_]")) # ['a', 'z', 'A', 'Z', '0', '9', '_'] print(re.findall("\w+", "[a-zA-Z0-9_]")) # ['a', 'zA', 'Z0', '9_'] print(re.findall("\W", "[a-zA-+Z0-9_]")) # ['[', '-', '-', '+', '-', ']'] print(re.findall("\W+", "[a-zA-+Z0-9_]")) # ['[', '-', '-+', '-', ']'] \b:匹配一个特殊字符边界,比如 空格,&,#,@等等 # 需求:匹配出一个 I print(re.findall("I\b", "I am LIST")) # [] # 分析:上面拿不到,看I前后的特点,是I后有个空格,所以就可以用\b来匹配这个特殊符号空格了。 print(re.findall("I\b", "I am LIST")) # [ ] # 为什么还是不行呢? # 匹配规则前面加个r,代表转义, r表示原生字符串,表示在Python这一层,里面的任何内容都不做转义了,就把\b代表空格的意思传给了re模块 print(re.findall(r"I\b", "I am LIST")) # [ ] # 匹配规则里加个\,也代表转义 # 在re模块匹配规则里,\\:等于去掉了\的特殊意义,就把\变成了要给普通的\字符,然后\b,就表示空格,传给re模块就是真正的空格了。 print(re.findall("I\\b", "I am LIST")) # 问题:上面\b已经都代表了空格,为啥还匹配不到呢? # 【答】1. 如果只在re模块里,\b就代表了空格,是没问题的 # 2. 但是,程序是要用Python解释器执行的,而\b在Python 解释器里是有特殊意义的,当Python执行到print(re.findall("I\b", "I am LIST"))的时候,\b就被python解释器解释成了Python的意思,而传给re模块就不再是空格了 # 3. 所以,要通过 r"I\b"告诉python解释器不转义 或者 "I\\b" 来转义 # 所以,总结一下,你想匹配的内容,是需要re模块能认识的才行。 # 再看个例子 # 需求:匹配一个 c\l, \是就是一个普通的字符 # 想匹配的是 c\l,首先在正则里面, 得是c\\l, 通过多加一个\把另一个正则 # 里的转义\ 进行转义,转义成一个普通的\. # 然而,程序是通过Python解释器解释的,那么也就是说python执行完该行程序# # 后,需要给re里面传个c\\l, 然后re才能 将c\\l 转义成 c\l这个普通字符。 # 所以re.findall("c\\l"),python解释器只给re传了一个\进入,即c\l是传给了re, # 而实际上,re需要\\,所以,re.findall("c\\\\l"),python解释器自己会先转义一下剩下了c\\l,这个再传给re,re里就变成了 c\\l, 然后re自己再转义一次,就变成了最终想要的 c\l的结果。 print(re.findall("c\\\\l","nihaos c\l")) # ['c\\l'] # 当然,这么写实在是太麻烦了,可以通过再前面加个r,告诉python解释器,这个不需要转义,然后直接传给re的就是c\\l了 print(re.findall(r"c\\l","nihaos c\l")) # ['c\\l'] # 当然,这里返回结果又有疑问了,我们要匹配的是c\l,可以返回结果是["c\\l"]呀,不对啊。 【答】其实,这是对的,因为匹配是再re里进行的,匹配成功并返回结果给python解释器这一层了,而传给python解释器又要进行python解释器这一次的转义,所以,看到的就是["c\\l"]. 重要的不是你看到了几个\,重要的是匹配成功了。
#### \ 让有意义的字符变得没意义#### # 下面的匹配规则里, . 可以代表任意字符,下面是匹配结果 print(re.findall("www.baidu", "www.baidu")) # ['www.baidu'] print(re.findall("www.baidu", "wwwobaidu")) # ['wwwobaidu'] print(re.findall("www.baidu", "www/baidu")) # ['www/baidu'] print(re.findall("www.baidu", "www\nbaidu")) # [] 因为. 不能匹配换行符 # 如果在匹配规则里的.前面加个\,即 \. 就让.代表任意字符的功能消失掉了,这个. 此时就代表一个普通的字符. print(re.findall("www\.baidu", "www.baidu")) # ['www.baidu'] # 所以这个是可以匹配出来的,因为被匹配字符串里有个. ,与匹配规则一致 # 而下面三个就无法匹配上了 print(re.findall("www\.baidu", "wwwobaidu")) # [] print(re.findall("www\.baidu", "www/baidu")) # [] print(re.findall("www\.baidu", "www\nbaidu")) # [] print(re.findall("www*baidu", "www*baidu")) # [] print(re.findall("www\*baidu", "www*baidu")) # ['www*baidu']
- 第九个元字符:|
| 管道符表示 或的意思,或 | 左边的一部分,或者|右边的一部分
[ ] 字符集 也有或的作用
print(re.findall(r"ka|b", "sdjkasf")) # ['ka'] print(re.findall(r"ka|b", "sdjka|bsf")) # ['ka', 'b'] print(re.findall(r"ka|bc", "sdjka|bsf")) # ['ka'] print(re.findall(r"ka|bc", "sdjka|bcsf")) # ['ka', 'bc']
- 第十个元字符:()
()表示分组
再学分组之前,先看下search()方法和findall()方法的比较
# search()方法: # 1. 在匹配字符串里,只要要到一个符合的结果就返回了,不会再继续往后找了;而且search()方法返回但是一个对象; # 2. 如果没有匹配到,就什么都不返回 # 3. 返回的对象里,group()方法可以提取出返回的值 # findall()方法:是把字符串里所有匹配到的字符串都放到一个列表里。 print(re.findall("\d+", "dfjad;fj123fjdfk33dfad3e23")) # ['123', '33', '3', '23'] print(re.search("\d{5}", "dfjad;fj123fjdfk33dfad3e23")) # None print(re.search("\d+", "dfjad;fj123fjdfk33dfad3e23")) # <_sre.SRE_Match object; span=(8, 11), match='123'> # 怎么从返回对象里提取出想要的值呢? print(re.search("\d+", "dfjad;fj123fjdfk33dfad3e23").group()) # 123
下面是分组的内容:
# print(re.findall("abc", "abcccc")) # ['abc'] print(re.findall("abc+", "abcccc")) # ['abcccc'] print(re.findall(r"abc+", "abcccc")) # ['abcccc'] # 无名分组 # 上面的+重复的只是紧挨着+的c这一个字符 # 但是现在想要让+重复abc这一个整体,就需要用到()进行分组了 print(re.findall(r"(abc)+", "abcccc")) # ['abc'] print(re.findall(r"(abc)", "abcccc")) # ['abc'] print(re.findall(r"(abc)+", "abcabcabcc")) # ['abc'] print(re.findall("(abc)+", "abcabcabcc")) # ['abc'] # 其实匹配出的结果是['abcabdabc'],但因为是分组的,默认优先只展示分组里的,而分组里只有一个abc,所以显示了一个有括号的一部分:['abc']
# 只出现一个abc,是因为分组了,默认只显示组内匹配的内容 print(re.findall("(?:abc)+", "abcabcabcc")) # ['abcabcabcc"] 去除了默认显示分组匹配的内容 print(re.findall("(abc)", "abcabcabcc")) # ['abc', 'abc', 'abc'] print(re.findall("(abc)", "abcdefabcessabcc")) # ['abc', 'abc', 'abc'] print(re.findall("(abc)", "abcabcabcc")) # ['abc', 'abc', 'abc'] #有名分组 # 有名分组 print(re.findall("(?P<name>\w+)","abcccc")) # ['abcccc'] print(re.findall("(?P<name>[a-z]+)","abcccc")) # ['abcccc'] print(re.findall("(?P<name>[a-z]+)","alex36wusir34xialv33")) #['alex', 'wusir', 'xialv'] print(re.findall("(?P<name>\d+)","alex36wusir34xialv33")) # ['36', '34', '33'] # 下面这个是固定写法 # 匹配规则里"(?P<name>真正的匹配内容)" print(re.search("(?P<name>[a-z]+)","alex36wusir34xialv33").group()) # alex print(re.search("(?P<name>\d+)","alex36wusir34xialv33").group()) # 36 print(re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group()) # alex36 # 去掉上面的?P<name>,结果并没有什么不同 print(re.search("[a-z]+","alex36wusir34xialv33").group()) # alex print(re.search("\d+","alex36wusir34xialv33").group()) # 36 print(re.search("[a-z]+\d+","alex36wusir34xialv33").group()) # alex36 # 那似乎?P<name>没有什么作用? # 对于真正要匹配的内容,的确是没有什么作用 # 那?P<name>的作用到底在哪里? # [答]是相当于把这个内容做了要给分组,每个匹配到的内容都可以通过name去拿了 print(re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group()) # alex36 # 上面是已经分组了,按照name分组了,匹配到的真正的信息是alex36, # 但如果只想取到alex,也就是只想拿到取出结果的name,也就是只想取分组的内容 print(re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group("name")) # alex print(re.search("(?P<name>[a-z]+)(?P<age>\d+)","alex36wusir34xialv33").group()) # alex36 print(re.search("(?P<name>[a-z]+)(?P<age>\d+)","alex36wusir34xialv33").group("age")) # 36
re模块下常用的方法
findall() 和 search()方法上面已经有例子了,不再重复
- re.findall(): 返回所有满足匹配条件的结果,放在列表里
- re.search() : 函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个对象
- 意义: 比如计算器程序的时候就比较有用
- re.search().group():通过调用group()方法可以提取出匹配的字符串;如果字符串没有匹配,则返回None; group返回匹配到的第一个,groups返回匹配到的全部
# 下面是个需要计算的表达式 (12+(34*6+2-5*(2-1)+(8+9-8*4)) # 都知道要先计算最里面的括号,但是这个表达式里最里面有2个括号,先计算哪一个? # 这时候就能用到search()的好处了,它只取第一个,然后计算出结果替换括号,如此 # 反复匹配,计算,替换,直到所有的括号都处理完成。
下面是re模块里还没介绍到的方法:
- re.match():同search,不过仅仅在字符串开始处进行匹配。
- match匹配成功了跟search一样,返回一个对象;
- match没匹配成功,什么都不返回。
print(re.match("\d+", "alex36wuser33xialv33")) # 什么都没返回,在命令行里演示最直观 # 解释:什么都没返回,因为,match仅仅匹配开头,而开头是a,所以啥都匹配不到
# 所以,match()方法完全可以被search()方法取代
- re.split():对字符串进行分割
# 按空格分割 print(re.split(" ","hello abc def")) # ['hello', 'abc', 'def'] # 空格要分开,有管道符|的也要分开 print(re.split("[ |]","hello abc|def")) # ['hello', 'abc', 'def'] print(re.split("[ab]", "abc")) # ['', '', 'c'] # 为什么会有空出现?看下面的例子 # 解释: # 首先会按照 "a" 分,abc里a的左变没有内容,就是一个空,a的右边是bc, 这样按照'a'分,就分成了两部分['','bc'] # 但是事还没完,因为是分割法是以a 或者 b分的,此时,再按b分,会把已经得到两部分['','bc']按照b再分, # 其中,空的一部分肯定没有b了,就分不了了,而bc中有b,可以分,其中b的左边没内容,就是'',右边只有'c' # 所以最后的结果是 ['', '', 'c'] # 按照a 或者 b 分 print(re.split("[ab]", "asdabcd")) # ['', 'sd', '', 'cd'] # 分割步骤: # 1. 按a分,得到['','sdabcd'] # 2. 第二部分还有a,再按a分一次,得到['','sd','bcd'] # 3. 再按b分,得到['','sd','','cd']
- re.sub(pattern, repl, string, count=0, flags=0):替换
- pattern:匹配的条件
- repl:需要替换成的内容
- string:被匹配字符串
- count:匹配次数
- flags:
# 需求,把字符串里所有的数字替换为A print(re.sub("\d", "A", "jsadfja432143jkjfadkn343413")) # jsadfjaAAAAAAjkjfadknAAAAAA print(re.sub("\d+", "A", "jsadfja432143jkjfadkn343413")) # jsadfjaAjkjfadknA print(re.sub("\d", "A", "jsadfja432143jkjfadkn343413",4)) # 4代表,匹配的次数,匹配次数够了,后面的就不再匹配和替换了 # jsadfjaAAAA43jkjfadkn343413
- re.subn():返回共匹配了多少次,返回结果是元组
print(re.subn("\d+", "A", "jsadfja432143jkjfadkn343413")) # ('jsadfjaAjkjfadknA', 2) print(re.subn("\d", "A", "jsadfja432143jkjfadkn343413")) # ('jsadfjaAAAAAAjkjfadknAAAAAA', 12)
- re.compile():compile()里只有一个参数,就是匹配规则
# compile:是编译的意思 a = re.compile("\d+") # 先把这个匹配规则编译好,供后面的匹配直接调用就可以了 print(a.findall("fajfdaj34124134fadjflkjadfj23")) # ['34124134', '23'] print(a.findall("民132nihakl4543na你啊打发343")) # ['132', '4543', '343'] # 所以,当匹配一次的时候,用compile()和不用compile()没有什么区别,但是如果需要多次匹配不同的字符串, # 如果都不用compile(),那每次匹配都会先编译一次规则,效率就会降低, # 而如果用compile()先把规则编译好,再之后的多次匹配里直接调用,那效率就高了
- re.finditer():与findall()方法一样,都是匹配全部字符串,区别在于:
- findall()匹配后返回的结果放在了列表里
- finditer()匹配后的结果放在了一个迭代器对象里,返回的是个地址
- finditer()与findall()相比有什么好处呢?
- 当处理的数据非常庞大的时候,findall()都存在列表里肯定会耗内存,而finditer()直接存在一个迭代器对象里,只有当需要用里面的数据的时候再一条一条的拿出来,节省内存
- 用next().group()方法可以一条条的取出数据
a = re.compile("\d+") b = a.finditer("fjadjf12323nfnnjfal123") print(b) # <callable_iterator object at 0x00D451D0> # 如何取出迭代器对象里的结果? # 用next().group()方法 print(next(b).group()) # 12323 print(next(b).group()) # 123 # print(next(b)) # <_sre.SRE_Match object; span=(6, 11), match='12323'>
- 匹配规则里还有分组时的两种情况:
- 1. 默认展示分组内符合匹配结果的内容
- 2.分组内加?: 可以去除默认规则
# 匹配规则里包含分组时,默认匹配结果只展示分组内的匹配结果 # 原理:程序认为,既然你分组了,那你肯定是最想看到分组里的匹配结果的,所以展示分组内的匹配结果 print(re.findall("www\.(baidu|163).com", "www.baidu.com")) # ['baidu'] print(re.findall("www.(baidu|163).com", "www.baidu.com")) # ['baidu'] print(re.findall("www.(baidu|163).com", "www.163.com")) # ['163'] # 如果不想只展示分组内的匹配结果,那么需要再分组内加上?:,来去除由默认规则,就会展示全部符合匹配规则的结果 print(re.findall("www.(?:baidu|163).com", "www.baidu.com")) # ['www.baidu.com'] print(re.findall("www.(?:baidu|163).com", "www.163.com")) # ['www.163.com']
关于模块导入的一点补充:

需求:把上面目录下的test.py导入到bin.py里
import sbsb # sbsb.py 是导入的文件,是一个相对路径,既然是相对路径,总是相对于谁存在的。那么他到底是相对谁而存在呢? # 相对路径最终是相对于当前路径(也就是bin的路径F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\bin.py 去掉bin.py # 这个文件名后,就变成当前路径了)继续拼接 # F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\sbsb.py ''' import 导入的原理: 1. import 干的第一件事是帮过你去找到文件,通过上面路径拼接的方法找到文件 ('F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\sbsb.py') 2. import 干的第二件事是把导入的文件test.py copy 出来执行一遍 ''' # 上面执行程序会报错

解决办法是:
from module import sbsb # from 做的工作,是生成这样一个相对路径, module/sbsb.py # 然后与当前路径拼接成文件的最终路径: F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\module\sbsb.py 这样执行就不会报上面 No module named 'sbsb' 这个错,但是却报了下面的错

因为在sbsb.py文件里,导入了cal 模块,见下图。

那报上面错误的根本原因是什么呢?
还记得上面说的吧,import导入首先会做的两件事: ''' 1. import 干的第一件事是帮过你去找到文件,通过上面路径拼接的方法找到文件 ('F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\module\sbsb.py') 2. import 干的第二件事是把导入的文件test.py copy 出来执行一遍 ''' 问题就出在做第二件事的时候,copy出sbsb.py文件在bin.py里执行的时候,sbsb.py首先是导入cal.py文件的,那也就是要先找cal.py的路径,最终拼成绝对路径。 记住了,相对路径前的绝对路径永远都是当前执行文件的绝对路径,甭管你套了多少次的导入,永远都是当前执行文件(bin)的路径。所以,最后拼的路径是: 'F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\cal.py' 这个路径当然找不到了,那怎么解决呢? 在sbsb.py文件里,把导入语句改写成: from module import cal
这样虽然解决了在bin.py文件下运行不保错的问题,但是如果在sbsb.py下运行,又会报错,因为此时sbsb.py变成了当前文件,运行时路径就被拼接成了:'F:\workspace\OldBoy\源码\课件与源码\python全栈3期-课件与源码\day23\module\module\cal.py' ,所以会报错。
备注
这个补充主要是为了说明,导入模块的原理:
1. 怎么识别当前路径与相对路径
2. 当前路径与相对路径的拼接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号