第三篇 数据结构
字符串、列表、字典是最常用的,要玩的溜溜溜的,要门儿清
一.字符串(String)
print("hello".capitalize()) # 首字母大写 print("hello".count('l')) # 统计某个字符出现的次数 print("hello".find('l')) # 找到第一个后就返回所在位置,不会继续往后找了 print("hello".find('m')) # 找不到的时候返回 -1 #返回 Hello 2 2 -1
# 用""中的字符串把后面的字符串拼接成一个
print("".join("hello Python")) print("😁".join("hello Python")) print("😁".join(["hello","Python"])) # 输出 hello Python h😁e😁l😁l😁o😁 😁P😁y😁t😁h😁o😁n hello😁Python
# string.strip(): 去掉前后空格,字符串中间的空格不会被去掉 print(" hello Python ".strip()) # 输出 hello Python
# string.split(): 指定以什么方式分隔字符,返回值是个列表 print("hello Python".split("l")) print("hello Python".split("y")) # 输出,注意分隔字符是不会成为返回值中的一部分的 ['he', '', 'o Python'] ['hello P', 'thon']
# string.replace().替换 , 第一个参数是被替换值,第二个参数是替换值 print("Hello Python".replace("Hello","你好")) # 输出 你好 Python
# 练习 # 把下划线分隔转化成驼峰风格 name = "damao_teach_python_long_long_year" # 预期:"DamaoTeachPythonLongLongYear" # 方法1:字符串用➕👌拼接 strSplit = name.split("_") newString = "" for word in strSplit: newString += word.capitalize() print(newString) # 方法2:字符串的join()方法 for word in strSplit: newString.join(word.capitalize()) print(newString) # 输出 DamaoTeachPythonLongLongYear DamaoTeachPythonLongLongYear
# 方法3:用生成式处理 b = "".join([word.capitalize() for word in name.split("_")]) print(b) # 输出 DamaoTeachPythonLongLongYear
二.列表(List)
# 1. 空列表的初始化 # 使用中括号[]初始化 a = [] # 使用函数类型初始化 b = list() # 2. 初始化有值的列表 c = [1,2,3] # d = list('a','b','c') # 这种方式初始化时,list())只能有一个参数 # 可以用下面的方式处理 e = list(("1","2","3")) # list()里的参数必须是一个可迭代的类型 # f = list(2) # 不是可迭代对象,不能这样定义 g = list("abc") # 字符串是可以循环遍历的,所以是可以这样定义的 # 3.列表的拼接 h = c + e + g print(h) # 4. extend()两个列表合并为一个,直接更改c c.extend(g) print(c) # 5. 在列表g 后面追加数据 # 在列表的最后一个位置插入,需要用append()方法 g.append("!") print(g) # 6.在列表第0个元素前插入数据, insert的第一个参数表示位置,插入位置在该位置之前 g.insert(0,"new") print(g) # 7. 获取下标是5的元素,返回被pop的元素 print(g.pop(3)) print(g) # 8.移除元素,找到对应的字符然后移除 g.remove("!") # 返回值是None,列表里大多数方法的返回值都是None print(g)
# 9. 反向列表中元素 x = [1,2,3,4] x.reverse() print(x) # [4, 3, 2, 1] # 10.对原列表进行排序 x.sort() print(x) # [1, 2, 3, 4]
练习: 对列表元素去重 data = [1,'a',2,'a',3,'b','c',2,'c',3]
# 方法1:用集合的方法去重 ''' 集合就有唯一性,集合里是无序的 ''' data = [1,'a',2,'a',3,'b','c',2,'c',3] print(list(set(data))) # 方法2: 使用in操作符判断元素是否在列表里 ''' 先有一个空列表 ''' newList = [] for element in data: if element in newList: continue else: newList.append(element) print(newList) # 方法3:使用=号判断元素是否在列表里,循环两个列表 newList = [] for element in data: for existElement in newList: if element == existElement: break else: newList.append(element) print(newList) # 方法4 使用 not in 操作符 newList = [] for y in data: if y not in newList: newList.append(y) else: continue print(newList)
三.集合(set)
# 1.集合的定义 ,是用{}定义的 a = {'a','b','c'} # print(a) # print(type(a)) b = {1,2,'c'} # print(a,b) # 取两个集合公共的部分:交集 print(a & b) # 取两个集合所有的内容 : 并集 print(a | b) # 取 第一个集合有,第二个集合没有的 , 或者 b 里有,a 没有 print((a-b) | (b-a)) print((a | b) - (a & b))
四.字典(Dict)
字典是无须的
# 1. 字典的初始化,使用{}, 字典里是以键值对方式存在的 a = {"a":1,"b":2,"c":3} print(a) # 2. 使用数据类型初始化一个空字典 b=dict() print(b) # 3. 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 # 使用fromkeys,其序列需要是一个可迭代对象 b = b.fromkeys('bcd', 1) print(b) # {'b': 1, 'c': 1, 'd': 1} c = dict() c = c.fromkeys(['aa','bb','cc'],2) print(c) # {'aa': 2, 'bb': 2, 'cc': 2} # 4. 合并两个字典,只要键是一样的,就会被覆盖 # 合并两个字典,直接更改a b.update(a) print(b) # 5. 设置默认值,如果key存在则不从新赋值。 b.setdefault('a', 2) # 如果key a已经存在了,就不会重新被赋值了 b.setdefault('e', 5) # 如果key e 不存在,就会重新赋值 print(b) # 6. 但是,可以强制重新赋值的 b['a'] = 999 print(b) b['f'] = 998 print(b) # 7. 插入值,或者 b['new']=-999 print(b) # 8.获取 print(b['c']) print("---") # 9.移除元素 print(b.pop('b')) print(b) print(50 * "*") # 10.遍历字典 for i in b: print(i, b[i]) # 遍历,获取字典的key for i in b.keys(): print(i) # 遍历,获取字典的值 for i in b.values(): print(i) # 遍历,既想取Key, 又想取值,用items for k, v in b.items(): print(k, v)
#练习 # 用字典表示学生与数学,语文,英语成绩,并计算平均分 students = { "name":"xiaoming", "math":66, "yuwen":90, "english":100 } print(students) # 计算平均分 print((students['math']+students['yuwen']+students['english'])/3)
练习:读取文件内容,并统计单词出现的个数
The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
# 打开文件 with open("python") as file: text = file.read() # 将文件切分成行,返回结果是一个列表,没一行组成列表里里的一个元素 text = text.split("\n") file.close() result = {} # 1. 遍历文件,取出每一个元素,这里的一个元素就是一样文字 for line in text: for character in [',','.','!','*','-']: # 把特殊字符去掉 line = line.replace(character,"") # 把一行字符用空格分隔成一个个单词 for word in line.split(" "): word = word.lower() if word in result: # 如果word 在字典里,value值+1 result[word] += 1 else: # 如果不存在,将key的默认值设置为1 result.setdefault(word,1) print(result)
五. 元组
# 1. 元组的定义和初始化 a = (1,2,'a') print(type(a)) # 2. 元组的遍历 for i in a: print(i) for i in range(len(a)): print(a[i]) # 3. 元组的值不允许修改 # 4. 将 a 元组的值分别赋值给b,c,d b,c,d = a print(b,c,d)
六.生成式(Comprehensions)
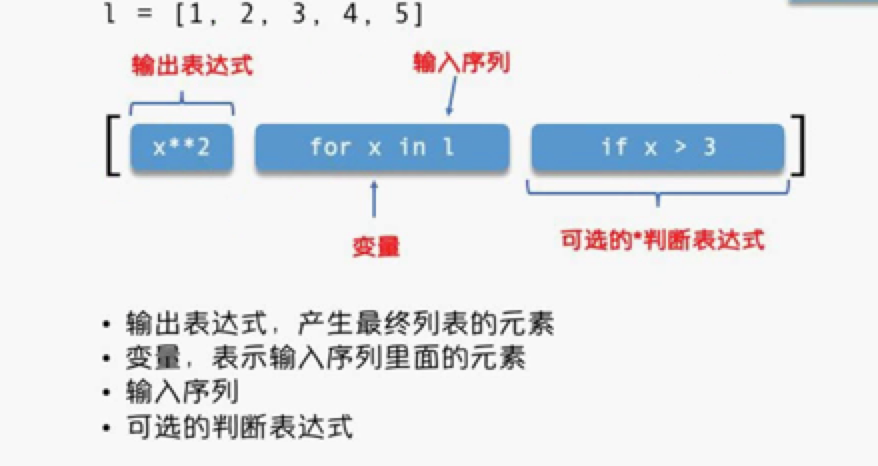
l = [1,2,3,4,5,6,7] ''' x**2: 输出表达式 for x in l:输入序列 if x > 2: 可选的判断表达式 ''' a = [x**2 for x in l if x>3] print(a) # 输出 [16, 25, 36, 49]
练习:将下面四个代码补充完整
1. [(x,y) for x in [1,2,3] for y in [3,1,4] if x != y] 2. [str(round(pi,i)) for i in range(1,6) ] 3. [[row[i] for row in matrix] for i in range(2)] 4. {x:x **2 for x in (2,4,6)}
解题
第一题:生成式里的x,y都能取到值,直接就可以运行,添加个打印结果,就可以看到最终输出 a = [(x,y) for x in [1,2,3] for y in [3,1,4] if x != y] print(a) # 输出 [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)] 第二题: 首先需要了解round()函数,round() 方法返回浮点数x的四舍五入值。 分析题意,输出的是当1=1,2,3,4,5的时候,pi的四舍五入值, 那么pi的值是不知道的, 就补充pi的值即可 pi = 3.14159278934 b = [str(round(pi,i)) for i in range(1,6) ] print(b) #输出 ['3.1', '3.14', '3.142', '3.1416', '3.14159'] 第三题: 分析题意,当i是0,1的时候,输出row[0],row[1]在matrix中的值, 根据row[i]可以推断这是一个列表,那么matrix的元素应该也是由列表组成 这是一个嵌套的生成式 matrix=[[1,2],[3,4],[5,6]] c = [[row[i] for row in matrix] for i in range(2)] print(c) #输出 [[1, 3, 5], [2, 4, 6]] 第四题: 需要的x值都有,可以直接执行 d = {x:x **2 for x in (2,4,6)} print(d) # 输出 {2: 4, 4: 16, 6: 36}
# 练习 有1,2,3,4 个数字,能组成多少互不相同且不重复的三位数?都是多少? a = [1,2,3,4] result = [ "{0}{1}{2}".format(i,j,k) for i in a for j in a for k in a if i!=k and i !=j and k !=j] print(result) print(len(result)) result1 = [ i*100+j*10+ k for i in a for j in a for k in a if i != j and i !=k and j != k] print(result1) print(len(result1)) #输出 [123, 124, 132, 134, 142, 143, 213, 214, 231, 234, 241, 243, 312, 314, 321, 324, 341, 342, 412, 413, 421, 423, 431, 432] 24

 浙公网安备 33010602011771号
浙公网安备 33010602011771号