0.储存引擎
mysql的功能大致分为两种,一个是连接客户端和提前检查SQL语句的功能,即数据库的前端部分,另一部分就是根据前台部分的指示,完成查询和文件操作的工作,即后台部分,也就是我们说的储存引擎
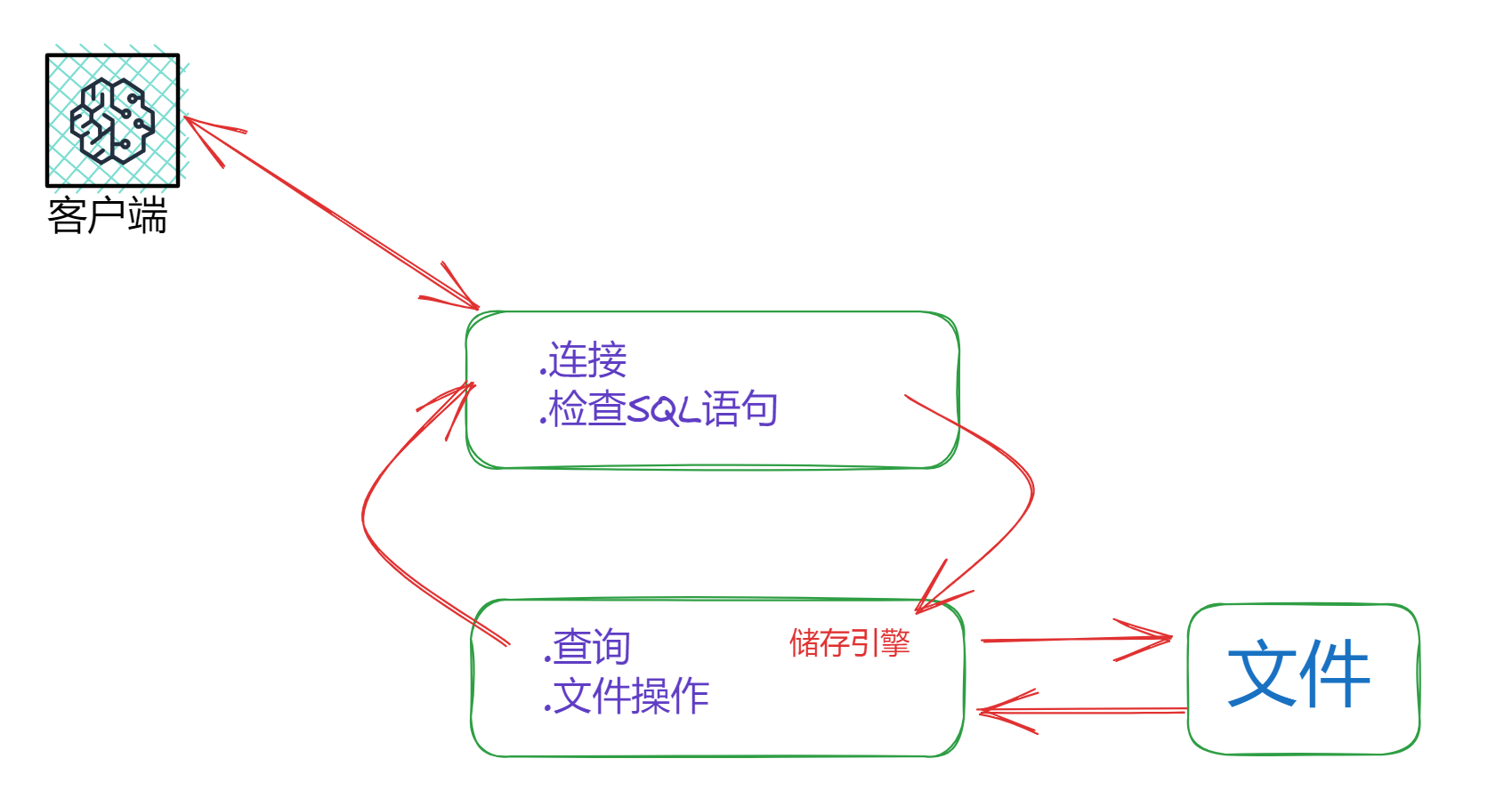
mysql中有多种储存引擎,每个表都可以独立指定储存引擎,以下是mysql中主要的储存引擎
| 储存引擎 | 特征 |
| MyISAM | 5.4版本以前的默认引擎,可以告诉运转,但是不支持事务 |
| InnoDB | 5.5版本以后的默认引擎,唯一一个支持事务的储存引擎 |
| CSV | 将数据的实体保存为CSV格式的文本文件,可以用excel直接打开 |
| MEMORY | 数据全部储存在内存中,处理速度非常快,主要作为临时工作区和其他表中提取的数据读取专用缓存使用 |
| ARCHIVE | 通过压缩来储存大量的数据,但是仅仅支持insert和select |
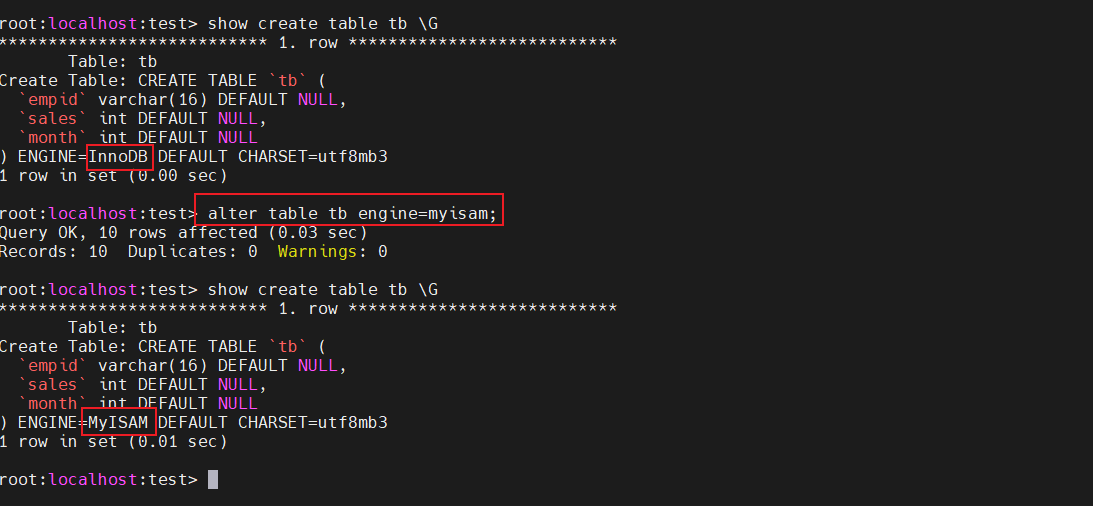
查看表的储存引擎
show create table 表名

修改储存引擎
表的储存引擎是可以修改的
alter table 表名 engine=引擎类型
也可以在创建表的时候指定储存引擎
CREATE TABLE table_name (
column1 datatype1 [constraints],
column2 datatype2 [constraints],
...
) ENGINE = storage_engine;
1.事务
事务:将多个操作作为单个逻辑工作单元处理
提交:将事务开始之后的处理结果反映到数据的操作叫做提交
回滚:不反应到数据库而是恢复为原来状态的操作叫做回滚
将多个操作步骤变成一个事务,任何一个步骤失败,则回滚到事务的所有步骤之前状态,大白话:要成功都成功;要失败都失败。
如转账操作,A扣钱。B收钱,必须两个步骤都成功,才认为转账成功
innodb引擎中支持事务,myisam不支持。
CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, `name` varchar(32) DEFAULT NULL, `amount` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
事务的具有四大特性(ACID):
-
原子性(Atomicity)
原子性是指事务包含的所有操作不可分割,要么全部成功,要么全部失败回滚。 -
一致性(Consistency)
执行的前后数据的完整性保持一致。 -
隔离性(Isolation)
一个事务执行的过程中,不应该受到其他事务的干扰。 -
持久性(Durability)
事务一旦结束,数据就持久到数据库
使用事务
start transaction; -- 开启事务 进行数据库的操作 commit; -- 提交 rollback; -- 回滚
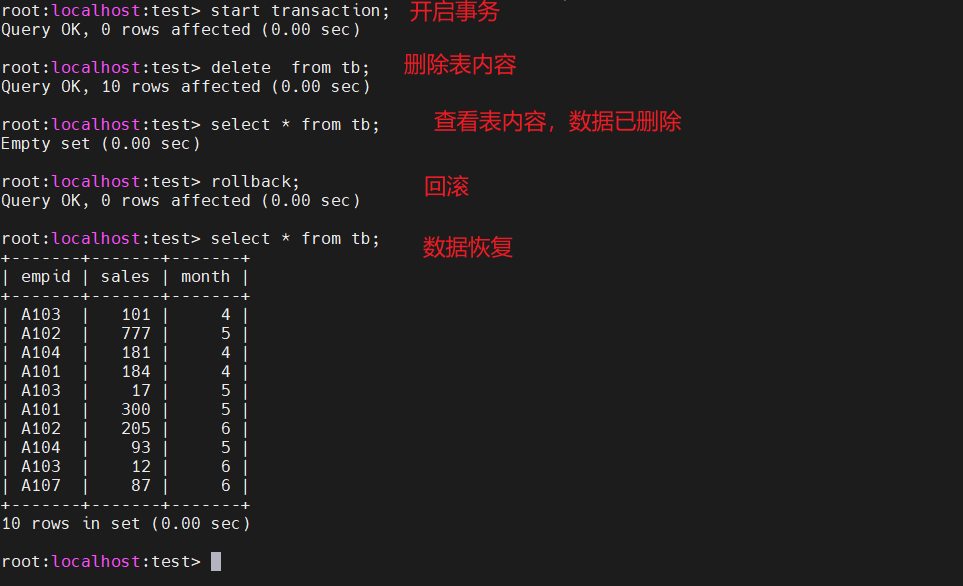
在上面的操作中如果使用commit代替rollback,则表中的数据就永久删除了
提示:
我们在对表做事务操作的时候,该表就会添加一把锁,在其他会话中可能会限制对该表的操作,关于锁我们下面继续探讨~~
python代码操作
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', charset="utf8", db='userdb') cursor = conn.cursor() # 开启事务 conn.begin() try: cursor.execute("update users set amount=1 where id=1")cursor.execute("update tran set amount=2 where id=2") except Exception as e: # 回滚 conn.rollback() else: # 提交 print("提交") conn.commit() cursor.close() conn.close()
自动提交功能
在mysql中执行命令,处理通常就会直接提交,也就说,所有的命令都会自动commit,在非innodb储存引擎中,不存在事务,所有的命令都会自动提交,这种自动提交的功能也被称之为自动提交功能
在默认的情况下,自动提交功能是开启的,但是储存引擎为innodb的情况下,如果执行start transaction,在执行commit之前是不会自动提交的,因此rollback才能回滚
用户可以强制关闭自动提交功能,在执行sql语句之后,不会自动提交,需要commit进行提交
注意:对于非innodb的储存引擎,自动提交功能会一直保持开启状态,及时手动关闭,也会自动提交
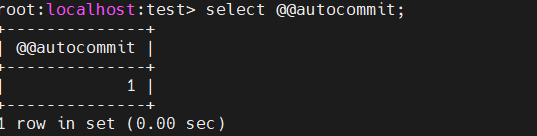
查看自动提交状态
select @@autocommit;
自动提交功能关闭
set autocommit=0
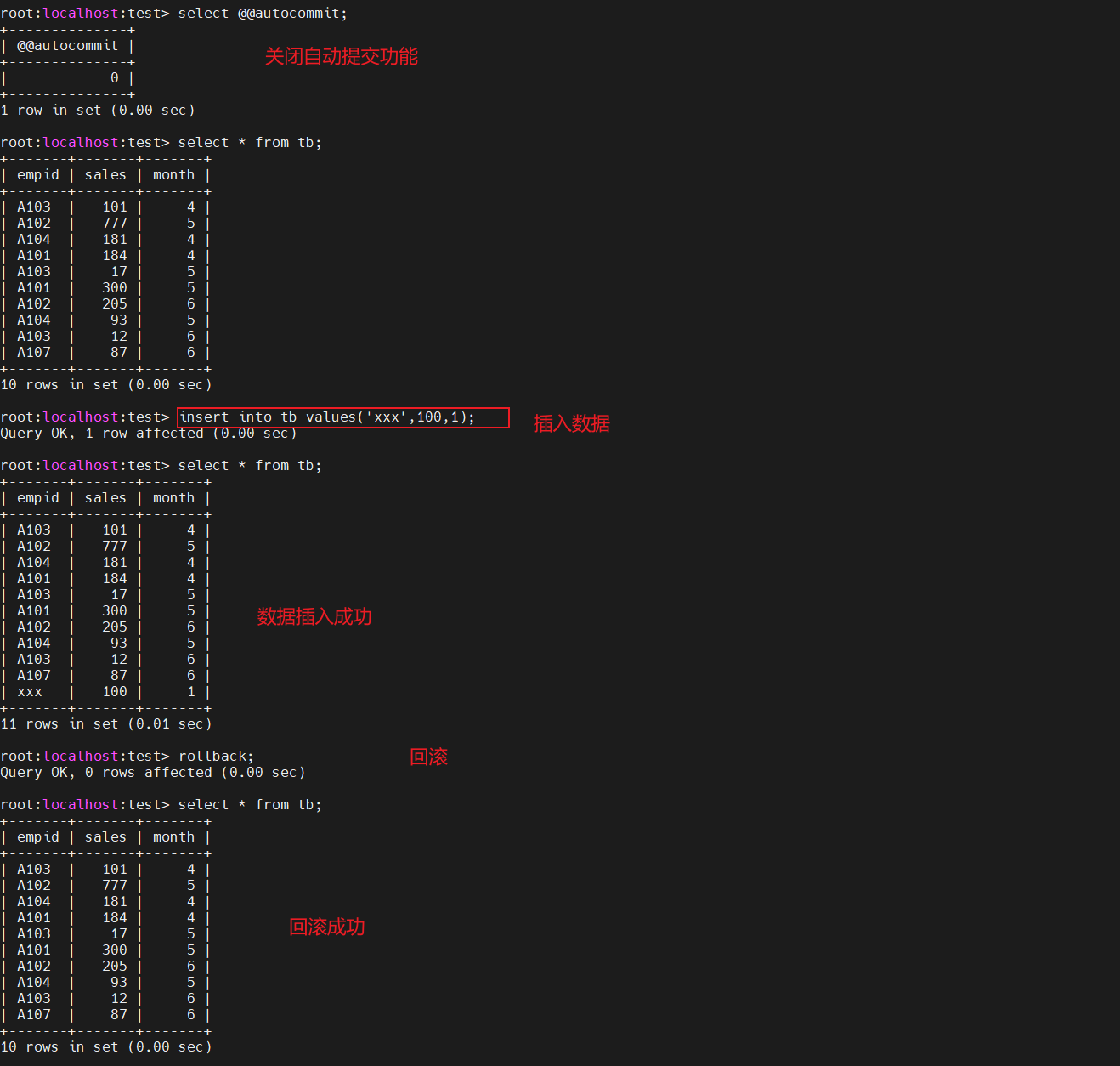
开启自动提交
set autocommit=1;
2.锁
在用MySQL时,不知你是否会疑问:同时有很多做更新、插入、删除动作,MySQL如何保证数据不出错呢?
MySQL中自带了锁的功能,可以帮助我们实现开发过程中遇到的同时处理数据的情况。对于数据库中的锁,从锁的范围来讲有:
- 表级锁,即A操作表时,其他人对整个表都不能操作,等待A操作完之后,才能继续。
- 行级锁,即A操作表时,其他人对指定的行数据不能操作,其他行可以操作,等待A操作完之后,才能继续。
MYISAM支持表锁,不支持行锁;
InnoDB引擎支持行锁和表锁。
即:在MYISAM下如果要加锁,无论怎么加都会是表锁。
在InnoDB引擎支持下如果是基于索引查询的数据则是行级锁,否则就是表锁。
所以,一般情况下我们会选择使用innodb引擎,并且在 搜索 时也会使用索引(命中索引)。
接下来的操作就基于innodb引擎来操作:
CREATE TABLE `L1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `count` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在innodb引擎中,update、insert、delete的行为内部都会先申请锁(排它锁),申请到之后才执行相关操作,最后再释放锁。
所以,当多个人同时像数据库执行:insert、update、delete等操作时,内部加锁后会排队逐一执行。
而select则默认不会申请锁。
2.1 排它锁
import pymysql import threading def task(): conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', charset="utf8", db='userdb') cursor = conn.cursor(pymysql.cursors.DictCursor) # cursor = conn.cursor() # 开启事务 conn.begin() cursor.execute("select id,age from tran where id=2 for update") # fetchall ( {"id":1,"age":10},{"id":2,"age":10}, ) ((1,10),(2,10)) # {"id":1,"age":10} (1,10) result = cursor.fetchone() current_age = result['age'] if current_age > 0: cursor.execute("update tran set age=age-1 where id=2") else: print("已售罄") conn.commit() cursor.close() conn.close() def run(): for i in range(5): t = threading.Thread(target=task) t.start() if __name__ == '__main__': run()
2.2 共享锁
共享锁( lock in share mode),可以读,但不允许写。
加锁之后,后续其他事物可以可以进行读,但不允许写(update、delete、insert)
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
3.数据库连接池
3.1 连接池创建
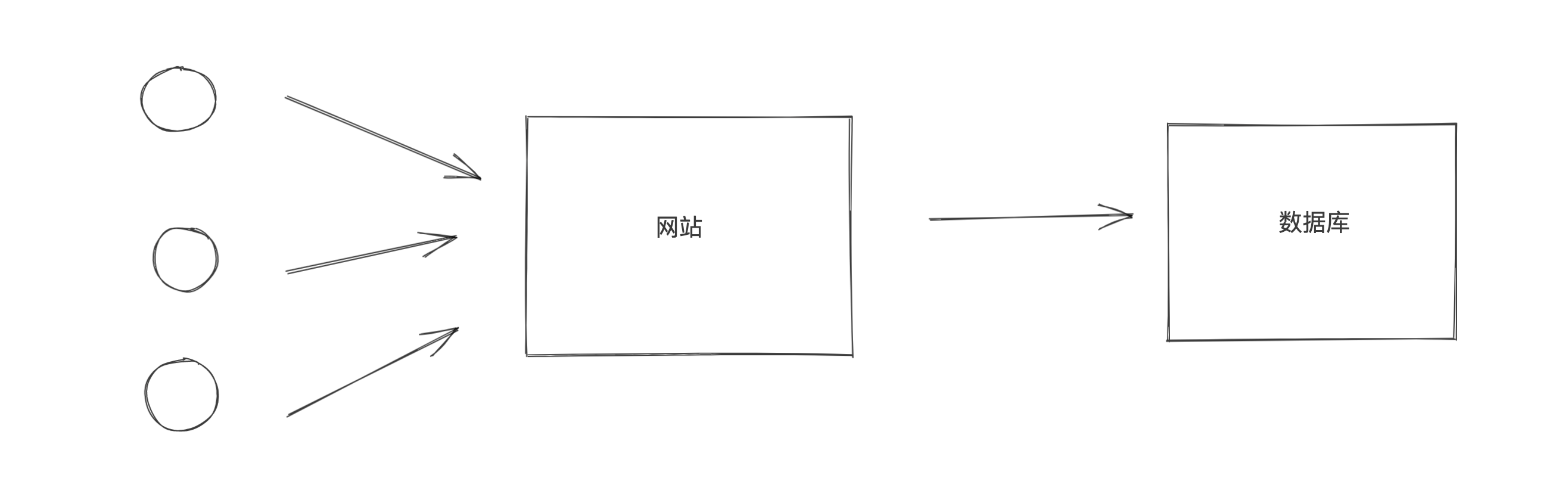
在操作数据库时需要使用数据库连接池。数据库池可以避免频繁的连接和断开数据库带来的损耗
pip install pymysql
pip install dbutils
import threading import pymysql from dbutils.pooled_db import PooledDB MYSQL_DB_POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=3, # 链接池中最多闲置的链接,0和None不限制 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。 # 如:0 = None = never, 1 = default = whenever it is requested, # 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='root123', database='userdb', charset='utf8' ) def task(): # 去连接池获取一个连接 conn = MYSQL_DB_POOL.connection() cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute('select sleep(2)') result = cursor.fetchall() print(result) cursor.close() # 将连接交换给连接池 conn.close() def run(): for i in range(10): t = threading.Thread(target=task) t.start() if __name__ == '__main__': run()
3.2 SQL工具类的使用
3.2.1 基于模块创建单例模式
# db.py import pymysql from dbutils.pooled_db import PooledDB class DBHelper(object): def __init__(self): # TODO 此处配置,可以去配置文件中读取。 self.pool = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=3, # 链接池中最多闲置的链接,0和None不限制 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='root123', database='userdb', charset='utf8' ) def get_conn_cursor(self): conn = self.pool.connection() cursor = conn.cursor(pymysql.cursors.DictCursor) return conn, cursor def close_conn_cursor(self, *args): for item in args: item.close() def exec(self, sql, **kwargs): conn, cursor = self.get_conn_cursor() cursor.execute(sql, kwargs) conn.commit() self.close_conn_cursor(conn, cursor) def fetch_one(self, sql, **kwargs): conn, cursor = self.get_conn_cursor() cursor.execute(sql, kwargs) result = cursor.fetchone() self.close_conn_cursor(conn, cursor) return result def fetch_all(self, sql, **kwargs): conn, cursor = self.get_conn_cursor() cursor.execute(sql, kwargs) result = cursor.fetchall() self.close_conn_cursor(conn, cursor) return result db = DBHelper()
3.2.2 基于上下文使用数据库池
如果你想要让他也支持 with 上下文管理。
# db_context.py import threading import pymysql from dbutils.pooled_db import PooledDB POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=3, # 链接池中最多闲置的链接,0和None不限制 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, host='127.0.0.1', port=3306, user='root', password='root123', database='userdb', charset='utf8' ) class Connect(object): def __init__(self): self.conn = conn = POOL.connection() self.cursor = conn.cursor(pymysql.cursors.DictCursor) def __enter__(self): return self def __exit__(self, exc_type, exc_val, exc_tb): self.cursor.close() self.conn.close() def exec(self, sql, **kwargs): self.cursor.execute(sql, kwargs) self.conn.commit() def fetch_one(self, sql, **kwargs): self.cursor.execute(sql, kwargs) result = self.cursor.fetchone() return result def fetch_all(self, sql, **kwargs): self.cursor.execute(sql, kwargs) result = self.cursor.fetchall() return result
4.索引
在数据库中索引最核心的功能就是:**加速查找**
4.1 索引的原理
索引的底层是基于B+Tree的数据结构存储的
据库的索引是基于上述B+Tree的数据结构实现,但在创建数据库表时,如果指定不同的引擎,底层使用的B+Tree结构的原理有些不同。
-
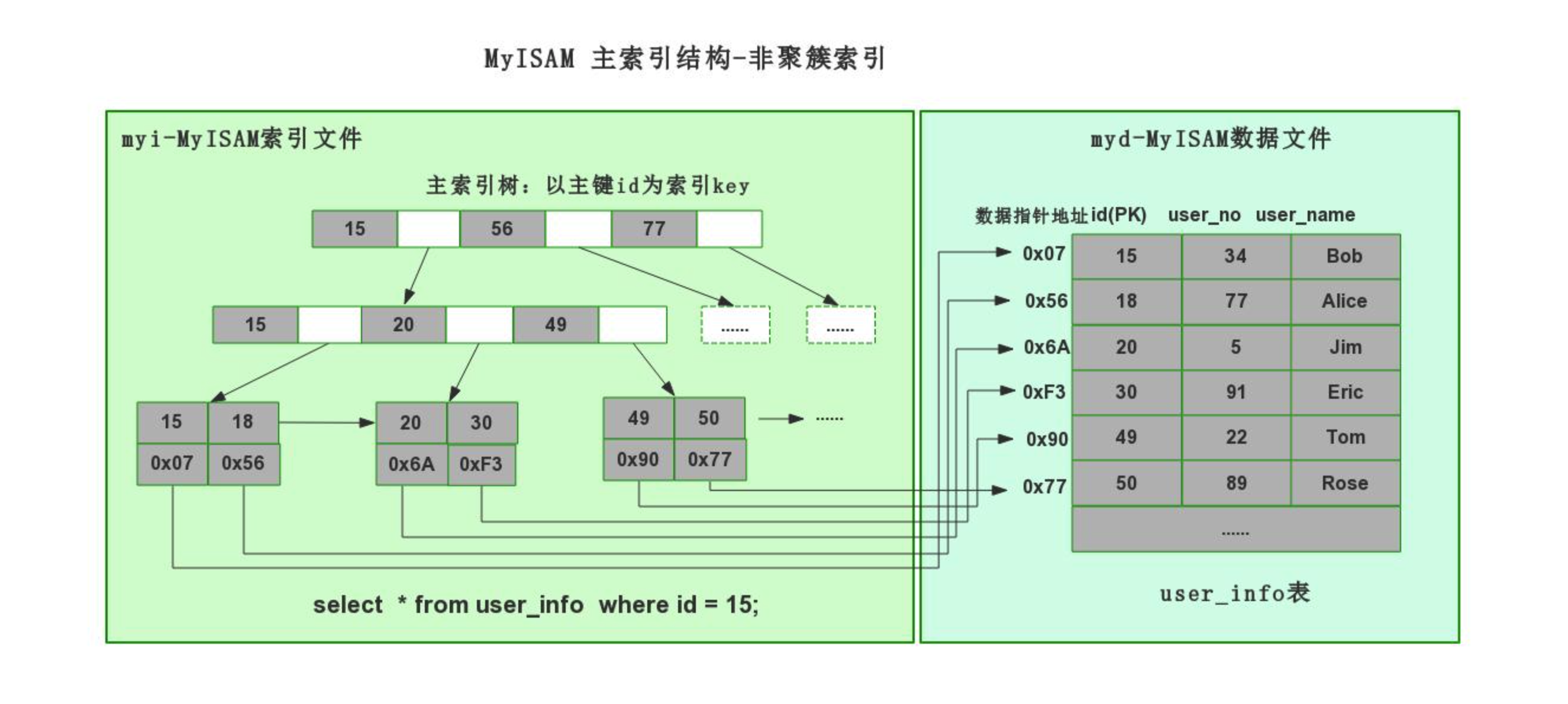
myisam引擎,非聚簇索引(数据 和 索引结构 分开存储)
-
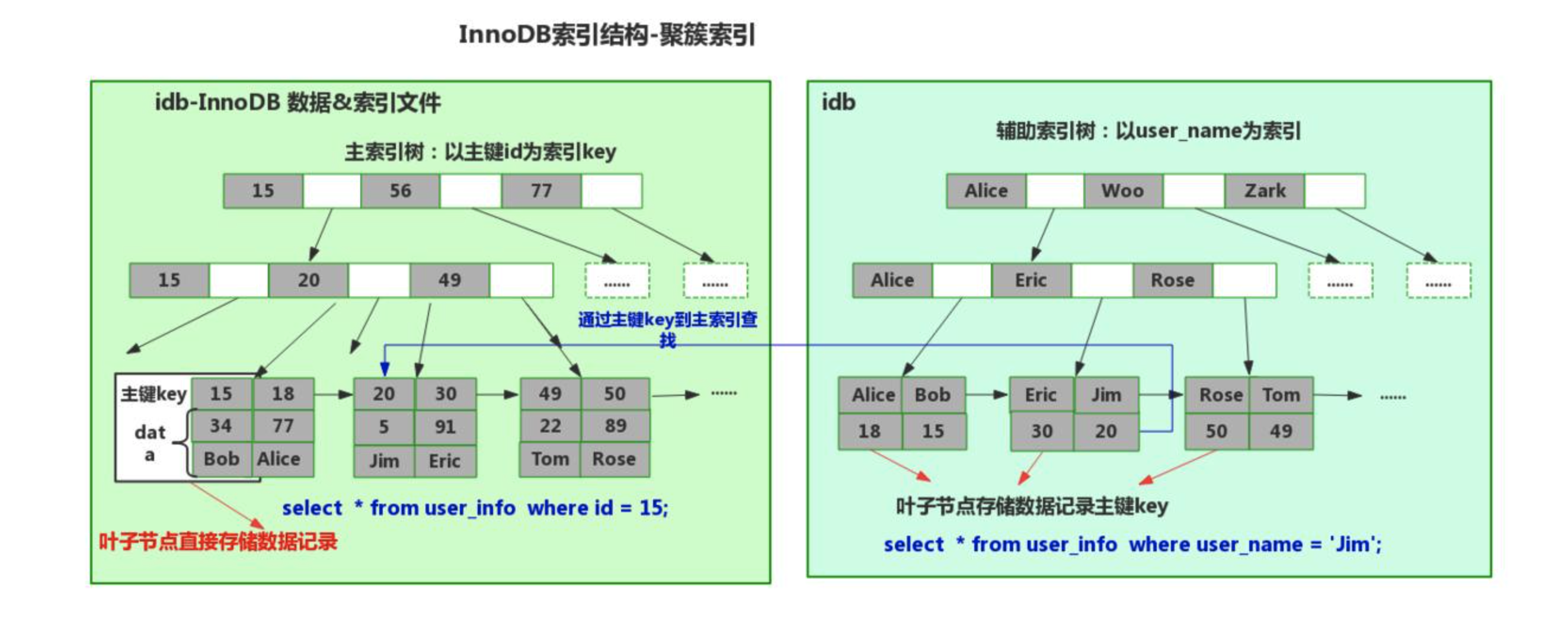
innodb引擎,聚簇索引(数据 和 主键索引结构存储在一起)
在企业开发中一般都会使用 innodb 引擎(内部支持事务、行级锁、外键等特点),在MySQL5.5版本之后默认引擎也是innodb
4.1.1 非聚簇索引(mysiam引擎)
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, age int )engine=myisam default charset=utf8;
4.1.2
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, age int )engine=innodb default charset=utf8;
4.2 常见的索引
**建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。**
开发过程中常见的索引类型有:
- 主键索引:加速查找、不能为空、不能重复。
create table 表名( id int not null auto_increment primary key, -- 主键 name varchar(32) not null );
- 唯一索引:加速查找、不能重复。
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, unique ix_name (name), -- 唯一索引 unique ix_email (email), );
- 普通索引:加速查找。
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, index ix_email (email), -- 普通索引 index ix_name (name),);
- 组合索引
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
- 添加索引
crearte index 索引名 on 表名(列名);
- 显示索引
show index from 表名
- 删除索引
drop index 索引名 on 表名
4.3 索引失效
会有一些特殊的情况,让我们无法命中索引(即使创建了索引),这也是需要大家在开发中要注意的。
- 类型不一样
select * from info where name = 123; -- 未命中 特殊的主键: select * from info where id = "123"; -- 命中
- 使用不等于
select * from info where name != "kunmzhao"; -- 未命中 特殊的主键: select * from big where id != 123; -- 命中
- or的使用
当or条件中有未建立索引的列才失效
select * from big where id = 123 or password="xx"; -- 未命中
- like的使用
select * from big where name like "%u-12-19999"; -- 未命中 select * from big where name like "wu-%-10"; -- 未命中 特别的: select * from big where name like "wu-1111-%"; -- 命中 select * from big where name like "wuw-%"; -- 命中
- 排序的使用
当根据索引排序时候,选择的映射如果不是索引,则不走索引
select * from big order by name asc; -- 未命中 select * from big order by name desc; -- 未命中 特别的主键: select * from big order by id desc; -- 命中
- 最左前缀原则, 如果是联合索引,要遵循最左前缀原则。
如果联合索引为:(name,password) name and password -- 命中 name -- 命中 password -- 未命中 name or password -- 未命中
5.函数
MySQL中提供了很多函数,为我们的SQL操作提供便利,例如:
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。
-
数据操作函数:
COUNT():计算符合条件的行数。SUM():计算某一列的总和。AVG():计算某一列的平均值。MAX():获取某一列的最大值。MIN():获取某一列的最小值。
-
日期和时间处理函数:
NOW():返回当前日期和时间。CURDATE():返回当前日期。CURTIME():返回当前时间。DATE():从日期时间值中提取日期部分。TIME():从日期时间值中提取时间部分。DATEDIFF():计算两个日期之间的天数差。
6.存储过程
存储过程,是一个存储在MySQL中的SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。
简单使用
- 创建存储过程
delimiter $$ -- 设置分隔符为$$ create procedure p1() BEGIN select * from d1; END $$ -- 保存储存过程 delimiter ; --将分隔符设置为;
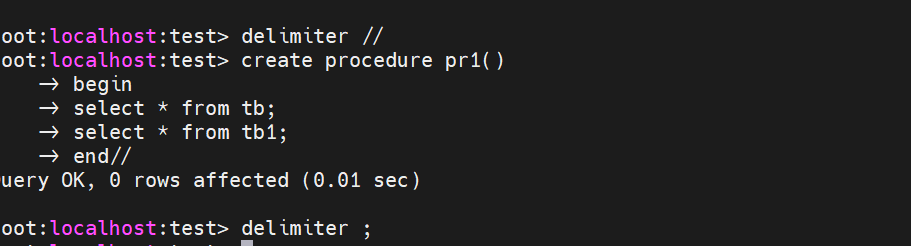
- 执行存储过程
call p1();
#!/usr/bin/env python # -*- coding:utf-8 -*- import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', db='userdb') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 执行存储过程 cursor.callproc('p1') result = cursor.fetchall() cursor.close() conn.close() print(result)
- 删除存储过程
drop procedure proc_name;
创建含有参数的过程
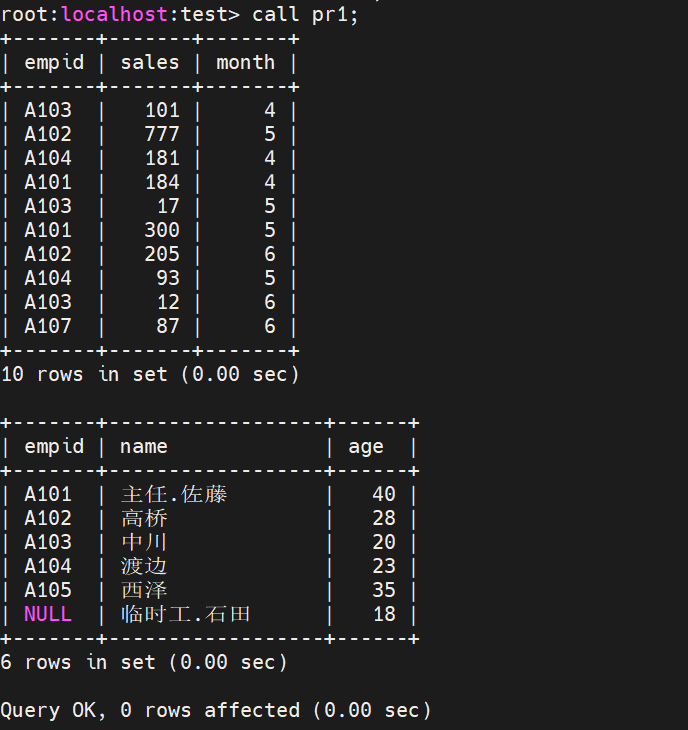
create procedure 储存过程名字(参数名 数据类型);
例如创建一个视图,可以显示大于等于指定值的记录的储存过程
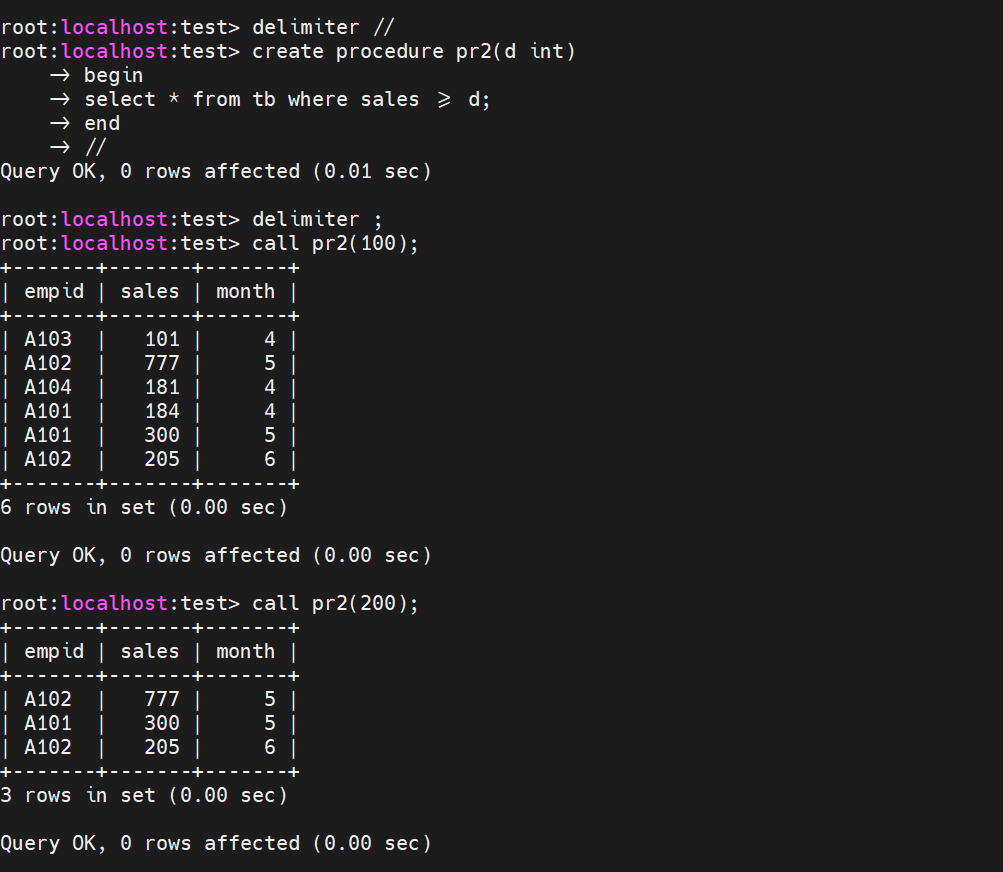
显示,删除储存过程
- 显示储存过程
show create procedure 储存过程名字;

- 显示所有的储存信息
SHOW PROCEDURE STATUS;
- 删除储存过程
drop procedure 储存过程名字;
储存函数
储存函数相比较于储存过程,唯一的不同点是储存函数在执行后会有一个返回值,定义的函数也可以类似mysql的内置函数一样使用(database(),sum()),也被称为用户自定义的函数
create function 储存函数名字(参数 数据类型) returns 返回值的数据类型
begin
SQL 语句
return 返回值
end
启用储存函数
默认情况下是不能使用储存函数的,这是因为储存函数可能对复制和数据的回复产生影响
show variables like 'log_bin_trust_function_creators';
开启储存函数
set global log_bin_trust_function_creators=1;
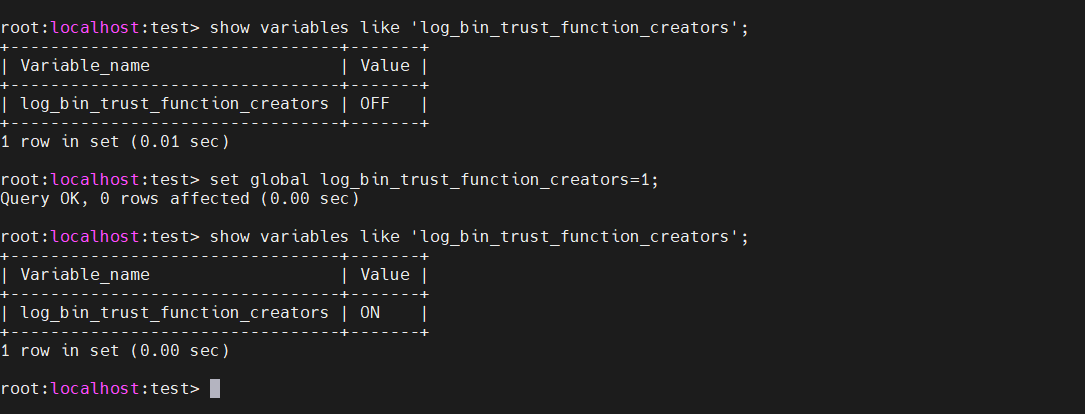
注意:以上方式在重启mysql的时候需要重新设置一次,如果希望永久修改,可以在配置文件中修改,同时储存函数的使用是需要权限的,root用户则有使用权限
储存函数的定义和使用
通过案例来进行介绍
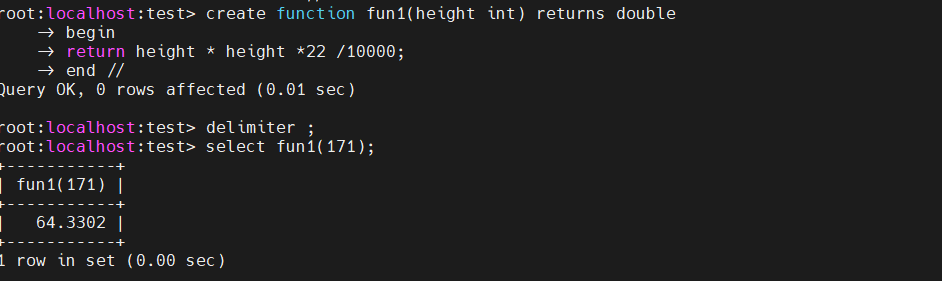
- 定义储存函数,实现 标准体重= 身高(cm)*身高(cm) *22/10000
调用函数delimiter // create function fun1(height int) returns double begin return height * height *22 /10000; end // delimiter ;
select fun1(171);
-
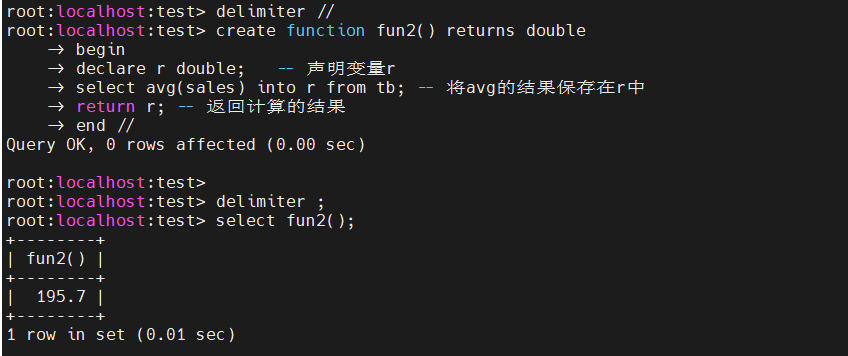
定义储存函数,实现计算记录的平均值
delimiter //
create function fun2() returns double begin declare r double; -- 声明变量r select avg(sales) into r from tb; -- 将avg的结果保存在r中 return r; -- 返回计算的结果 end //
delimiter ;执行函数
select fun2();
显示和删除储存函数
- 显示储存函数的内容
show create function 储存函数名字;

查看所有的函数
show function status;
- 删除储存函数
drop function 储存函数名字
触发器
触发器是一种对表执行某操作之后会触发执行其他命令的机制,例如创建一个触发器,当表的记录发生更新的时候,就以此为契机将更新的内容记录到另外一张表中
触发器常作为处理的记录或者处理失败时的备份
触发器被触发的时机
触发器会在对表执行操作之前或者之后执行
| before | 在对表进行处理之前执行 |
| after | 在对表进行处理之后执行 |
另外,对表处理之前和之后的列值可以通过以下方式取出来
| old.列名 | 对表进行处理之前的列值 |
| new.列名 | 对表处理之后的列值 |
但是根据命令的不同,有的列值是可以取出来的,有的则不然
| 命令 | 执行前 before | 执行后 after |
| insert | × | ○ |
| delete | ○ | × |
| update | ○ | ○ |
创建触发器
create trigger 触发器名字 before(或者after) delete(操作命令) on 表名 for each now
begin
使用更新前(old.列名)或者更新后(new.列名)的处理
end
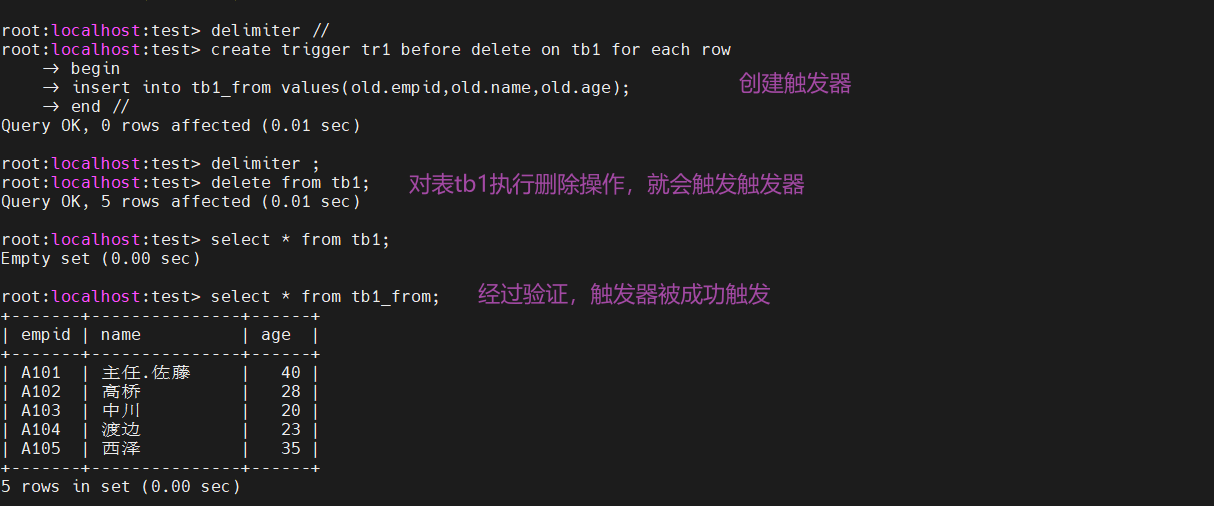
下面通过一个例子来感受触发器:当删除一个表中的记录时,就会将删除的记录添加到另外一张表中,用作以后的数据恢复
delimiter // create trigger tr1 before delete on tb1 for each row -- 对表tb1的删除操作前会触发该触发器 begin insert into tb1_from values(old.empid,old.name,old.age); -- 将删除的数据插入到tb1_from表中 end // delimiter ;
确认和删除触发器
- 确认触发器
触发器是会自动执行的,我们必须知道当前数据库存在的触发器!!!
show triggers;

- 删除触发器
drop trigger 触发器名
7. 视图
视图就是虚表,就是我们使用select查询之后获取的结果
从用户的角度看,视图和表没什么区别,视图也可以使用selec和update进行操作,在实际开发中,对于一些很重要不能做修改的数据,我们可以让管理员去直接操作表,准备一个视图来给低权限的人用于收集信息,保护基表,进一步保证数据的安全
7.1 使用视图
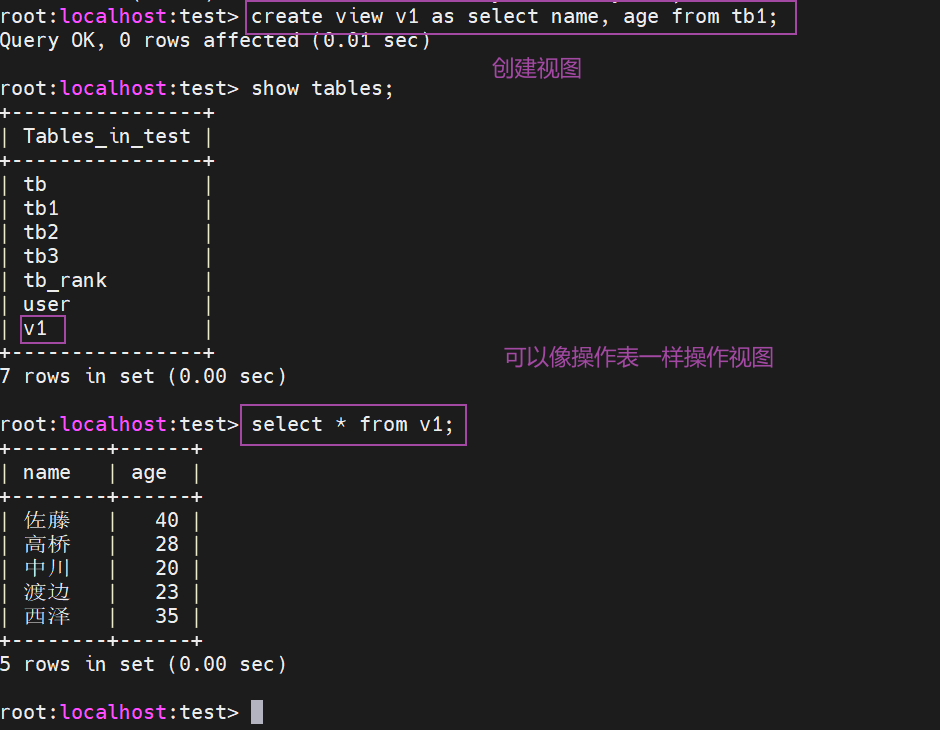
7.1.1 创建视图
create view 视图名 as select 列名 from 表名 where 条件
7.1.2 通过视图更新列的值
视图不仅是基表的一部分,也是基表数据的窗口,二者任意一方的修改,都会体现在另外一方上
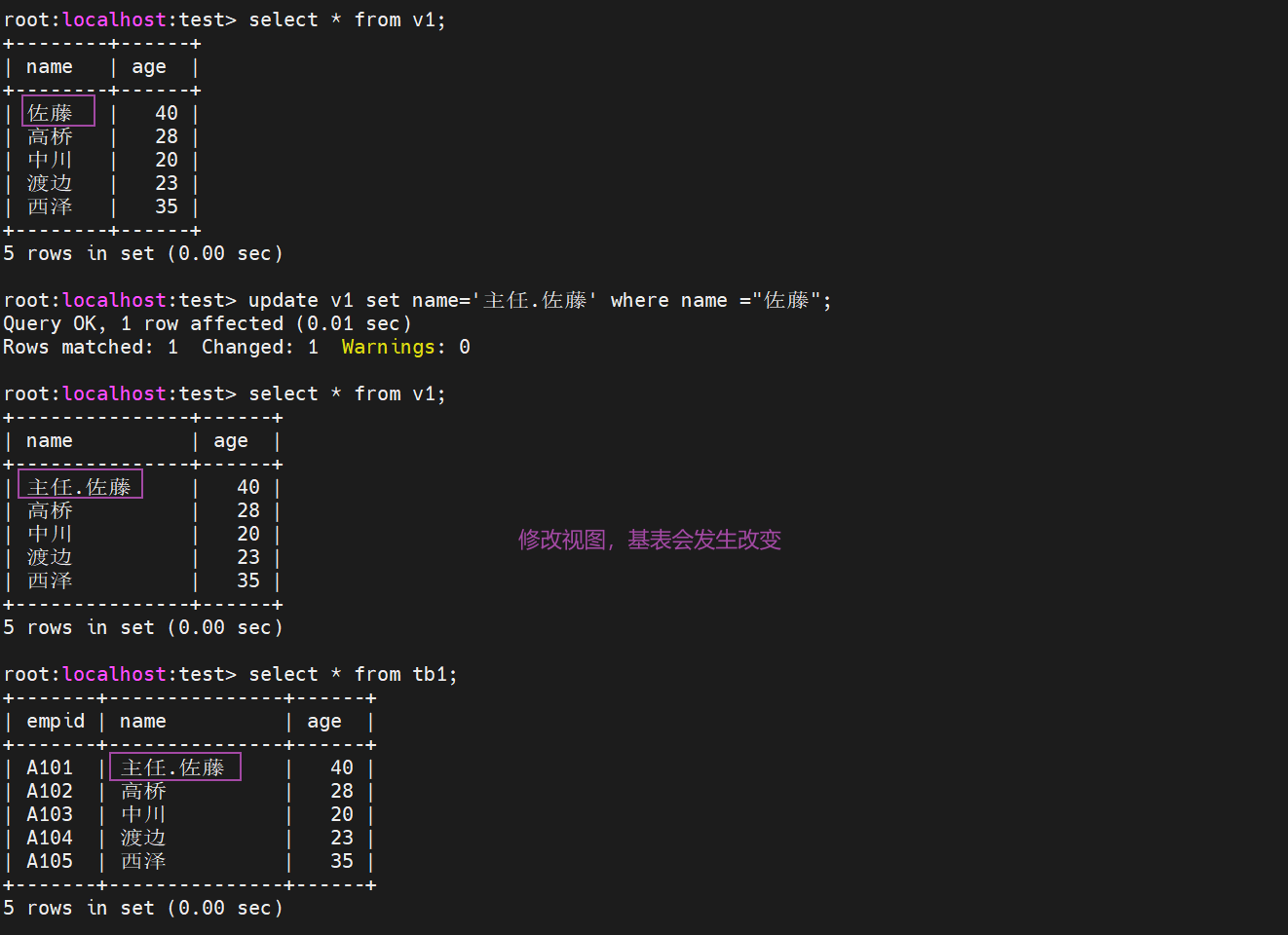
7.2 设置条件创建视图
所谓的设置条件创建视图就是在创建视图的时候通过where来限定条件
下面通过关联两张表,提取销售额度大于100万元的记录,并创建视图,包含员工号,销售额,和姓名的视图v2
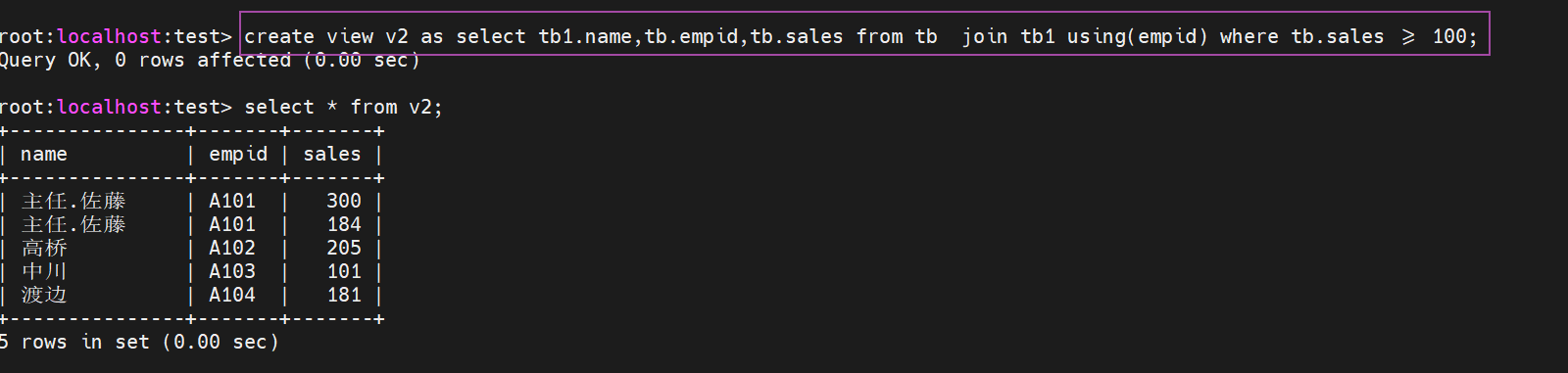
更新基表,查看视图的变化
更新基表,视图也会随之发生变化,当然这个变化的前提是满足where的条件
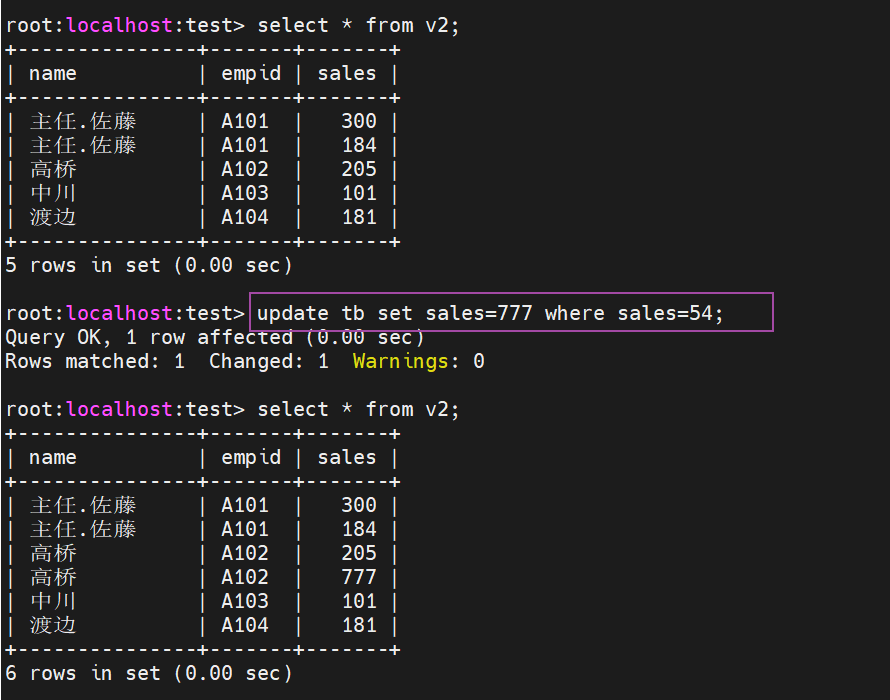
视图的确认
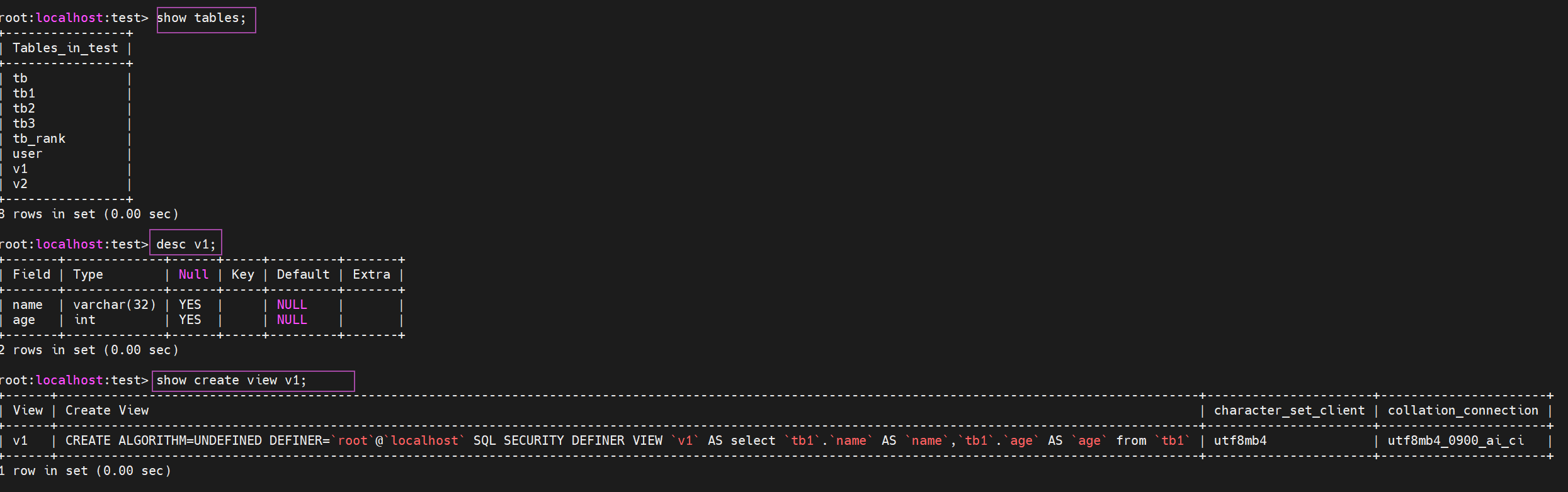
- 查看有哪些视图
show tables;
- 显示视图的列结构
desc 视图名;
- 显示视图的详情
show create view 视图名;
7.3 限制通过视图写入
对视图执行insert是有限制的,在使用了union,join,子查询的视图是无法执行insert和update的,但是对于单表创建的视图则是可以执行insert和update的
对于单表的修改操作在上面已经展示了,下面展示插入数据
在v1视图中插入一条新的数据,在基表中也成功的插入了一条数据
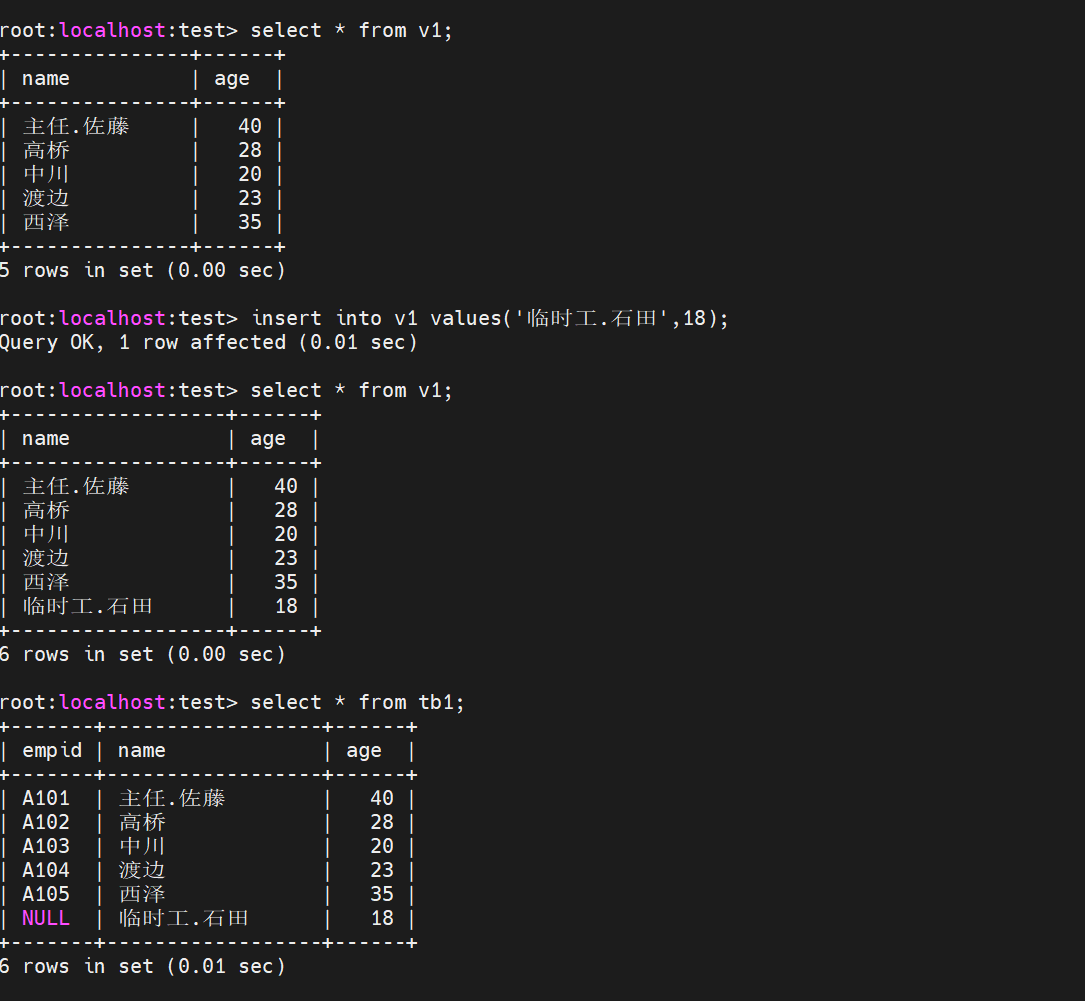
那么对于设置了条件的视图做修改会发生什么呢?
首先创建一个v3
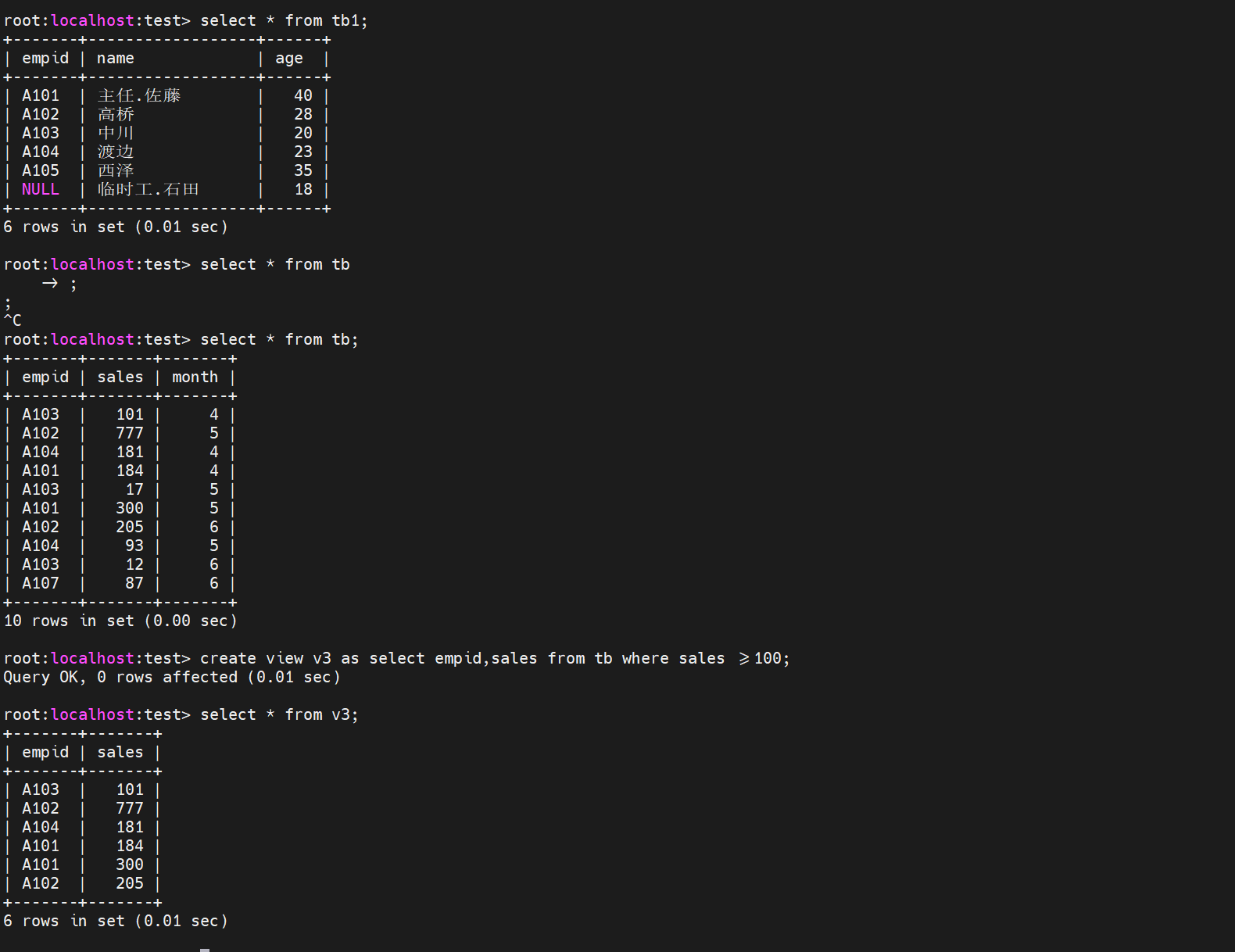
插入不符合条件的记录,插入销售额小于100万元的数值
会发现虽然视图中没有显示新插入的数值,但是在基表中却成功的插入了
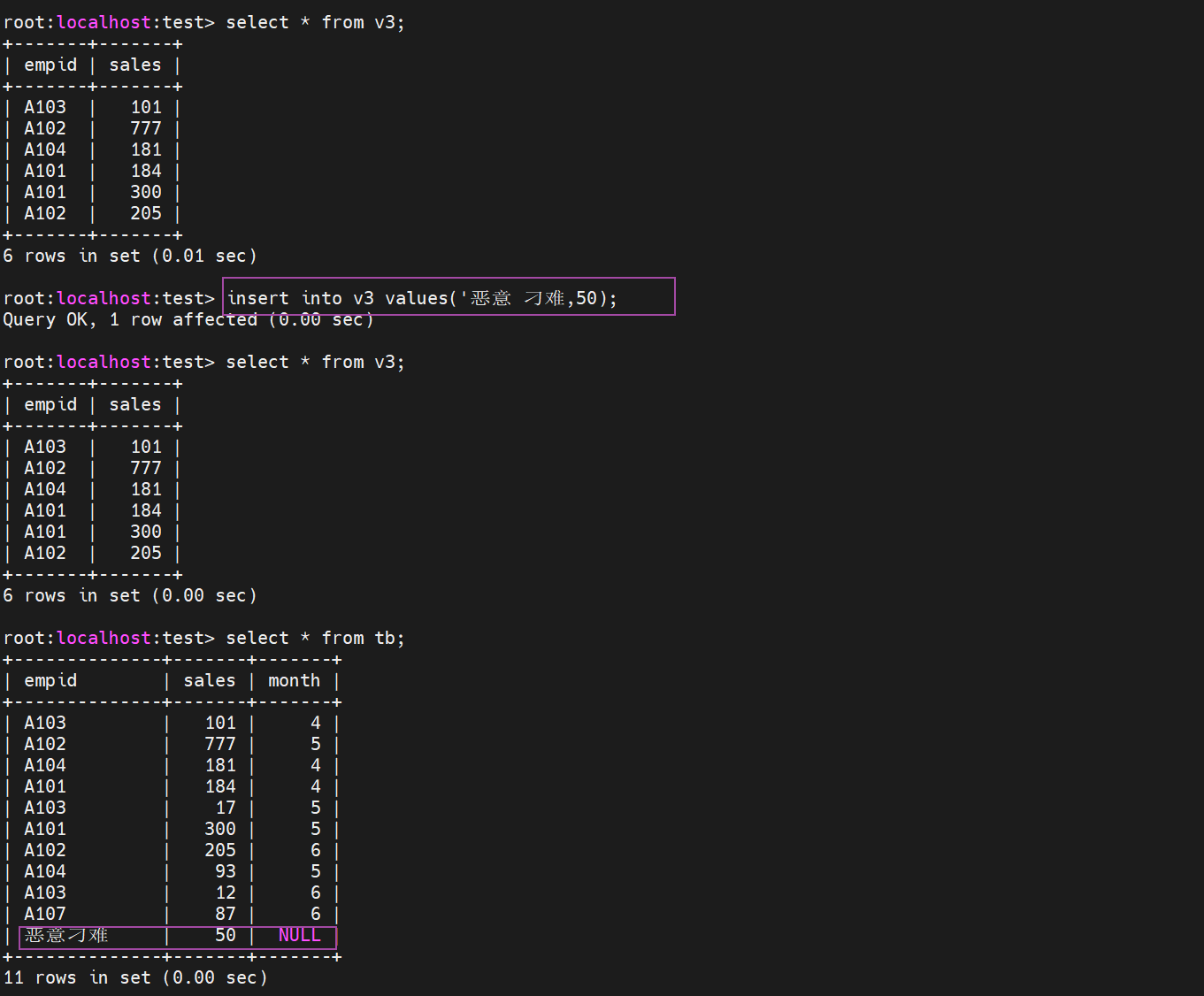
那么我们如何避免上面的问题呢?我们希望的是不匹配条件插入到视图的时候报错
只需要在创建视图的时候使用with check option
create view v4 as select empid,sales from tb where sales>100 with check option;

7.4 替换,修改和删除视图
- 替换
在创建视图的时候,如果视图已经存在是会报错的,我们可以使用or replace来替换可能存在的视图
create or replace view 视图名 as select 列名 from 表名 where 条件;
- 修改
alter view 视图名 as select 列名 from 表名
- 删除
drop view 视图名
8 使用文件进行交互
8.1 从文本文件中读取数据
当把大量的数据输入表中,可使用CSV格式的文件进行输入,
查看导入导出文件路径
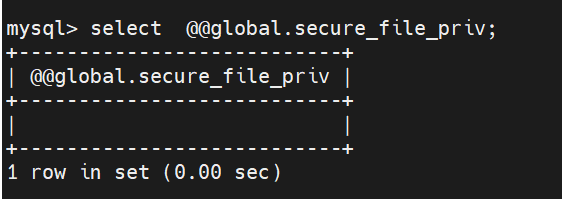
select @@global.secure_file_priv;
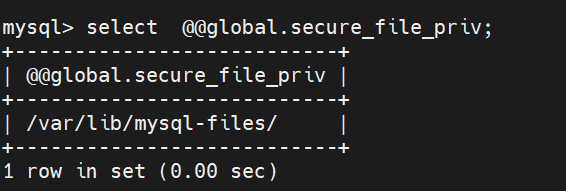
默认情况下,mysql只能导入或者导出文件找到指定目录中,如果我们希望可以允许导入导出任意路径下,可设置该值为空字符串,如果禁止该功能,可以设置为NULL
修改的话需要在mysql的配置文件中修改
ubuntu配置文件路径
/etc/mysql/mysql.conf.d/mysqld.cnf
在文件末尾追加
secure-file-priv = ""
然后重启mysql

修改之后
但是在实际操作中,尽管指向上述操作之后,还有可能会生成导入文件权限失败的问题,我这边就会将csv文件复制到/var/lib/mysql/,然后才会导入文件成功,如下面的案例
导入文件
load data infile '文件名' into table 表名 选项的描述;
除了CSV格式的文件以外,不用逗号分割的文本文件也能被读取,但是需要制定读取数据的格式,比如指定数据之间的分隔符,换行符或者从第几行开始读取
fields terminated by 分隔符(默认是\t) lines terminated by 换行符(默认是\n) ignore 最开始跳过的行 lines(默认是0)
t.csv
N551,佐佐木,37 N552,佐藤,41 N553,齐藤,31 N554,井上,43 N555,阿培,31
load data infile '/var/lib/mysql/t.csv' into table tb1 fields terminated by ',';
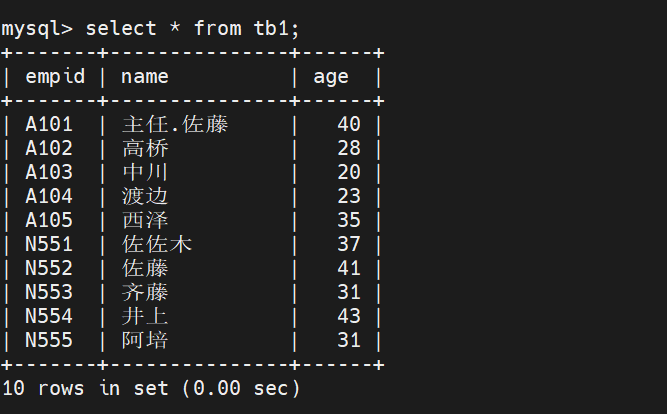
导出文件
将数据库的文件导出到csv文件中
select * into outfile '文件名' 选项的描述 from 表名
存在相同的问题,在设置 secure-file-priv = ""的情况下,导出的文件需要放在 /var/lib/mysql下
如
select * into outfile '/var/lib/mysql/tt.csv' fields terminated by ',' from tb1;
A101,主任.佐藤,40 A102,高桥,28 A103,中川,20 A104,渡边,23 A105,西泽,35 N551,佐佐木,37 N552,佐藤,41 N553,齐藤,31 N554,井上,43 N555,阿培,31
8.2从文本文件中读取SQL并执行
在执行复杂和冗长的SQL语句的时候,我们可以将SQL语句写入一个文本,提高工作效率
source 文本文件名;
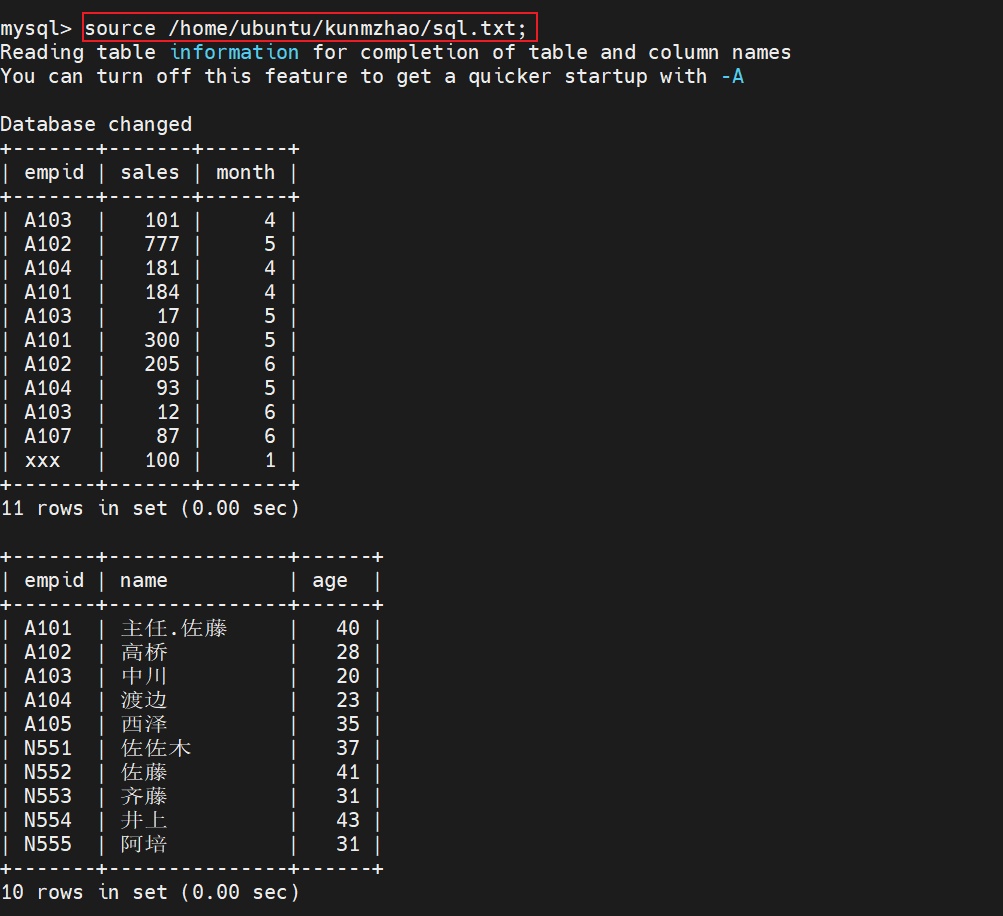
如创建文件sql.txt,内容如下
use test; select * from tb; select ( from tb;
执行命令
source /home/ubuntu/kunmzhao/sql.txt;
8.3备份和恢复数据库
对数据库的所有你内容执行导出的操作称之为转储,使用文件转储只有就可以在其他服务器上创建相同的数据库,常用作备份的操作
转储数据库
mysqldump -u 用户名 -p 密码 数据库名 > 输出文件的名字

恢复转储文件
mysqladmin -u root -proot create 数据库名
mysql -u 用户名 -p密码 数据库名<文件名 # 执行命令的前提是创建好数据库了
9.mysql的连接数问题
在web项目中,是伴随着大量并发请求的,其中很多请求涉及到大量的数据库查询操作,如何设置数据库,来避免连接失败导致的500错误呢
前端报错500
这种错误是由于django项目连接数据库时,数据库由于连接数量太多而拒绝连接的报错
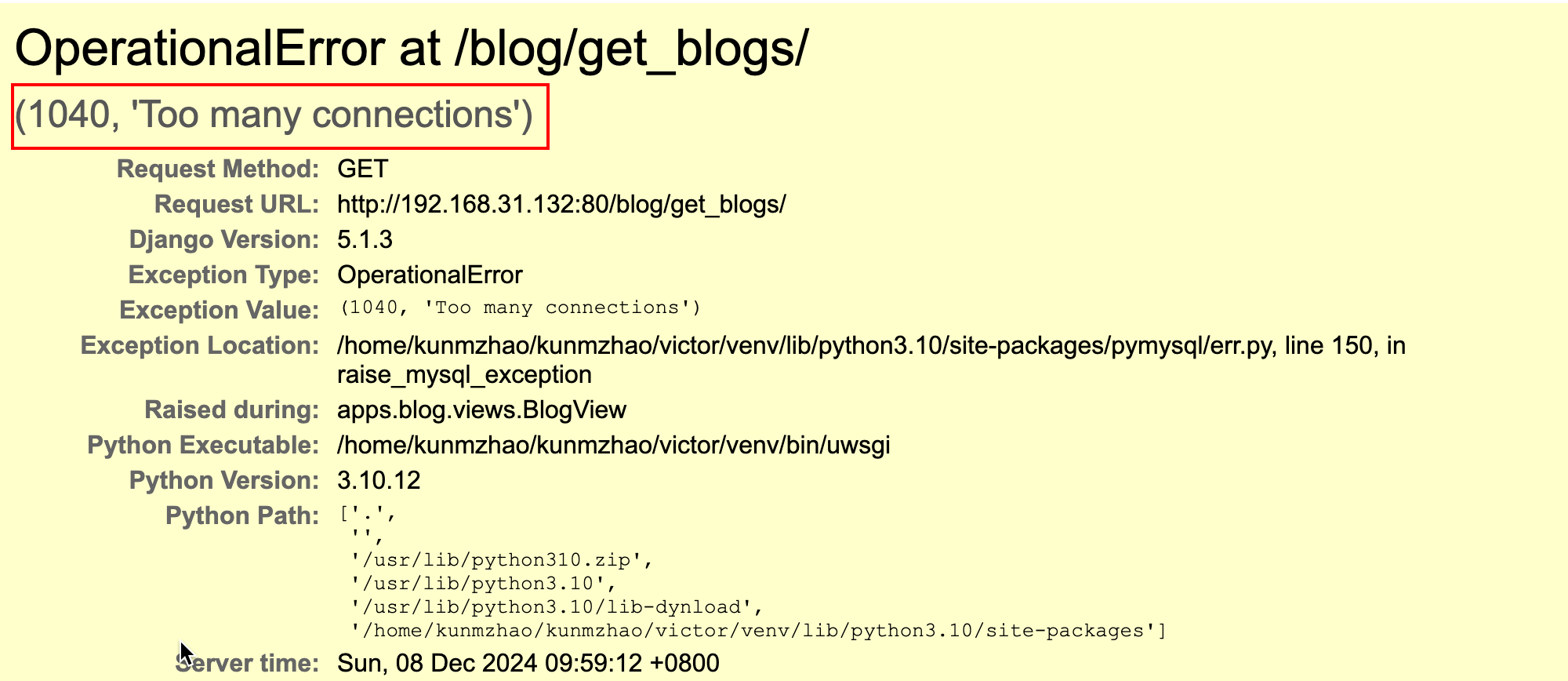
数据库最大连接数
指的是数据库支持同时最大的连接数量
查询sql命令
默认值是151
show global variables like "max_connections";
该数值也不是越大越好,如果 max_connections 设置得太低,可能会导致在高负载情况下拒绝新的连接请求;如果设置得太高,可能会消耗过多的服务器资源,导致性能下降。
设置sql命令
set global max_connections=200;
数据库历史最大连接数量
show gloal status like "max_used_connections";
该值是无法手动变更的
通常我们会根据 max_used_connections 来决定 max_connections的大小,网上都说的公式为
max_used_connections / max_connections > 80%
我们需要预留一些连接给管理员用于性能监控等,并且随着业务的变更,该数据也会动态修改
查看当前连接的进程
sql命令
show full processlist;
Id:线程的唯一标识符。User:执行查询的MySQL用户。Host:用户连接MySQL服务器的主机名和端口号(如果适用)。db:用户当前正在访问的数据库。Command:线程正在执行的命令类型(如Query、Sleep、Prepare等)。Time:线程已经处于当前状态的时间(以秒为单位)。对于长时间运行的查询,这个时间可能非常长。State:线程的当前状态,提供了关于线程正在做什么的更详细的信息(如Sorting result、Opening tables、Locked等)。Info:线程正在执行的SQL语句的完整文本(如果适用)。对于复杂的查询,这可能会很长,并且可能包含多个SQL语句(如果使用了存储过程或触发器)。
连接超时时间
MySQL服务器在自动关闭一个非交互式连接之前所等待的时间长度(以秒为单位)。非交互式连接通常是通过脚本或应用程序建立的连接,这些连接在没有活动(即没有发送任何查询或命令)一段时间后,可能会被MySQL服务器自动关闭。
查看sql 命令
show gloabl variables like "wait_timeout";
设置sql命令
set global wait_timeout = 3600;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号