1.数据库管理
1.1 SQL语句
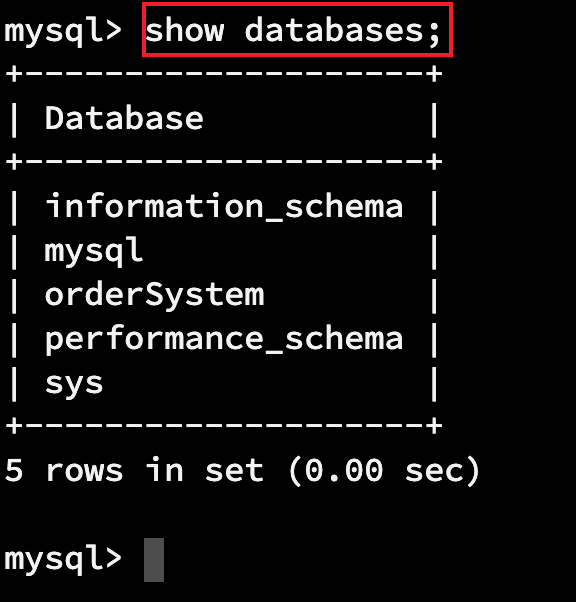
1.1.1 查看当前所有的数据库
show databases;
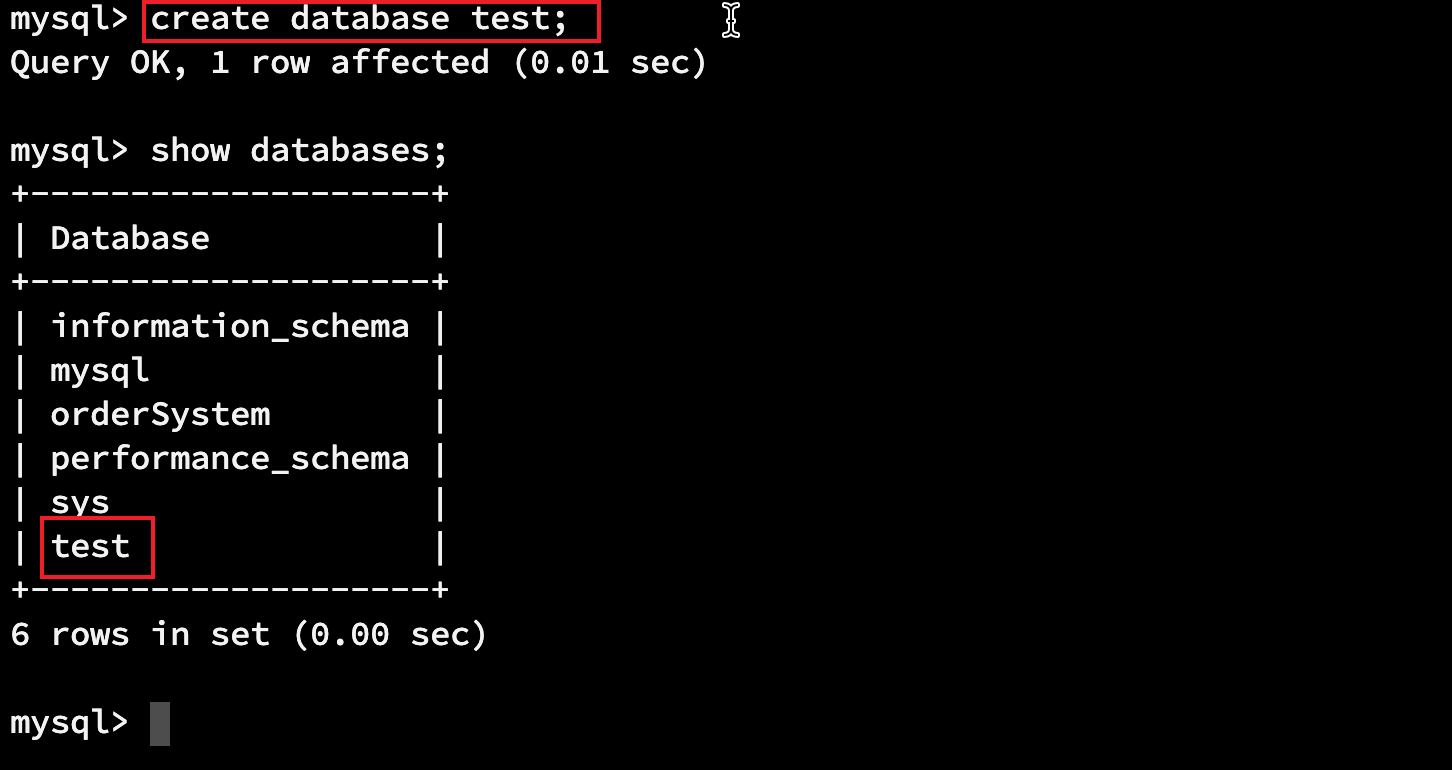
1.1.2 创建数据库
create database 数据库名; create databse 数据库名 default charset utf8 # 支持中文
8.0版本默认就是utf编码
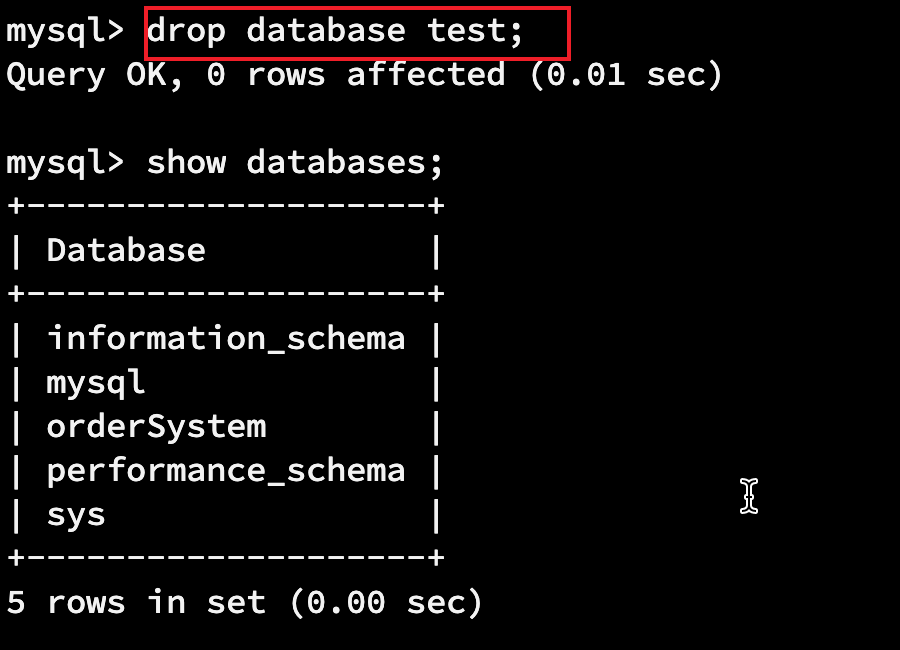
1.1.3 删除数据库
drop database 数据库;
1.1.4
use 数据库名

1.2 python操作
无论通过何种方式取链接mysql,本质上发送的指令是相同的,只是链接的方式和操作形式不同而已
要想通过python操作mysql,我们需要导入第三方模块
pip install pymysql

# encoding:utf-8 # author:kunmzhao # email:1102669474@qq.com import pymysql # 1.连接数据库 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', charset='utf8') cursor = conn.cursor() # 2. 查看数据库 cursor.execute("show databases") print(cursor.fetchall()) # 3.创建数据库 cursor.execute('create database test2 default charset utf8') conn.commit() cursor.execute("show databases") print(cursor.fetchall()) # 4.删除数据库 cursor.execute('drop database test2') conn.commit() cursor.execute("show databases") print(cursor.fetchall()) # 5.进入数据库 cursor.execute('use mysql') cursor.execute('show tables;') print(cursor.fetchall()) cursor.close() conn.close()
2.数据表管理
2.1 SQL语句
在操作数据表的时候首先需要进入对应的数据库
use 数据库名;
2.1.1 查看当前所有的表
show tables;

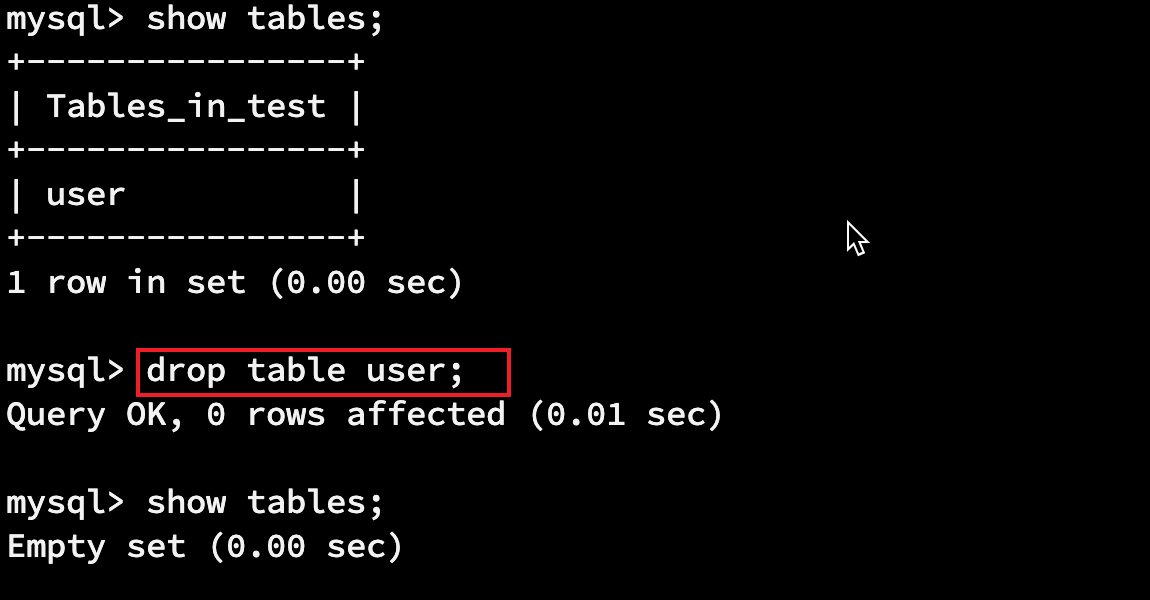
2.1.2 删除表
drop table 表名;
2.1.3 清空表
delete from 表名;

2.1.4 创建表
创建表必须要指定表名,列名称,列类型
create table 表名( 列名字 类型, 列名字 类型, 列名字 类型, ); create table user( id int primary key, -- 主键(不允许为空且唯一) name varchar(16) not null, -- 不能为空 age int default 18 -- 默认值为18
b varchar(16) unique -- 设置唯一
);
-
-
是否为空:代表以后该数据是否可以为空,默认为允许为空,not null指定不可为空
-
-
对于表中的连续编号,如果将数据全部删除,再次添加数据,自增不会从1开始,会基于之前的自增继续+1,如果希望删除数据之后自增从1开始,可以执行如下命令 alter table 表名 auto_increment=1; 当表中存在数据的时候,如果设置的编号比已经存在的值大,也是可以重新设置编号的初始值,而如果小,则不会生效
常见的列类型
-
int 表示有符号,取值范围:-2147483648 ~ 2147483647
int unsigned 表示无符号,取值范围:0 ~ 4294967295
int(5)zerofill 仅用于显示,当不满足5位时,按照左边补0,例如:00002;满足时,正常显示。 -
tinyint[(m)] [unsigned] [zerofill]有符号,取值范围:-128 ~ 127.
无符号,取值范围:0 ~ 255 -
bigint[(m)][unsigned][zerofill]有符号,取值范围:-9223372036854775808 ~ 9223372036854775807
无符号,取值范围:0 ~ 18446744073709551615 -
decimal[(m[,d])] [unsigned] [zerofill]准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 -
char(m)定长字符串,m代表字符串的长度,最多可容纳255个字符。
定长的体现:即使内容长度小于m,也会占用m长度
如果超过指定数量,则会报错(8.0的版本) -
varchar(m)变长字符串,m代表字符串的长度,最多可容纳65535个字节。
char类型为固定长度的字符串,在保存数据的时候,字符数量小于指定值则会用空格代替,在读取数据的时候则会删除空格,而varchar则不会填充空格
如果超过指定数量,则会报错(8.0的版本) -
texttext数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
一般情况下,长文本会用text类型。例如:文章、新闻等。 -
longtextA TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) -
datetimeYYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59) -
dateYYYY-MM-DD(1000-01-01/9999-12-31) -
timeHH:MM:SS('-838:59:59'/'838:59:59') -
timestampYYYY-MM-DD HH:MM:SS(1970-01-01 00:00:00/2037年)
MySQL还有很多其他的数据类型,例如:*set、enum、TinyBlob、Blob、MediumBlob、LongBlob 等*,详细见官方文档:https://dev.mysql.com/doc/refman/5.7/en/data-types.html
查看表结构
desc 表名

2.1.5 修改表
-
alter table 表名 add 列名 类型; alter table 表名 add 列名 类型 DEFAULT 默认值; alter table 表名 add 列名 类型 not null default 默认值; alter table 表名 add 列名 类型 primary key auto_increment;
-
删除列
alter table 表名 drop 列名;
-
修改列 类型 + 名称
alter table 表名 change 原列名 新列名 新类型;
- 修改列的数据类型
alter table 表名 modify 列名 数据类型;
- 修改列的位置
在使用add添加列的时候,默认会添加列到末尾,如果希望添加在最前面,可以使用first alter table 表名 add 列名字 数据类型 first; 如果希望将列添加到任意位置,则可以使用after alter table 表名 add 列名字 数据类型 after 已存在的列名;
-
修改列 默认值
alter table 表名 alter 列名 set default 1000;
-
删除列 默认值
alter table 表名 alter 列名 drop default;
-
添加主键
alter table 表名 add primary key(列名);
alter table 表名 add 列名 类型 primary key auto_increment;
-
删除主键
alter table 表名 drop primary key;
2.1.6 复制表
- 将表结构和记录都复制过来
create table 新表名 select * from 表名
- 仅复制表结构
create table 新表名 like 表名
2.2 python操作
import pymysql # 连接MySQL conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', charset="utf8") cursor = conn.cursor() # 1. 创建数据库 """ cursor.execute("create database db4 default charset utf8 collate utf8_general_ci") conn.commit() """ # 2. 进入数据库、查看数据表 """ cursor.execute("use db4") cursor.execute("show tables") result = cursor.fetchall() print(result) """ # 3. 进入数据库创建表 cursor.execute("use db4") sql = """ create table L4( id int not null primary key auto_increment, title varchar(128), content text, ctime datetime )default charset=utf8; """ cursor.execute(sql) conn.commit() # 4. 查看数据库中的表 """ cursor.execute("show tables") result = cursor.fetchall() print(result) """ # 5. 其他 drop table... 略过 # 关闭连接 cursor.close() conn.close()
3.数据行管理
数据行操作就是对数据表的内容进行增删改查,是学习mysql的重头戏,先简单学习,后续再深入学习
3.1 SQL语句
3.1.1 新增数据
insert into 表名(列名,列名,列名) values(对应值,对应值,对应值);
# 插入一条数据 insert into user (id,name,age) values(1,'zhangsan', 18); # 插入多条数据 insert into user (id,name,age) values(2,'lisi', 18),(3,'wangwu',20);
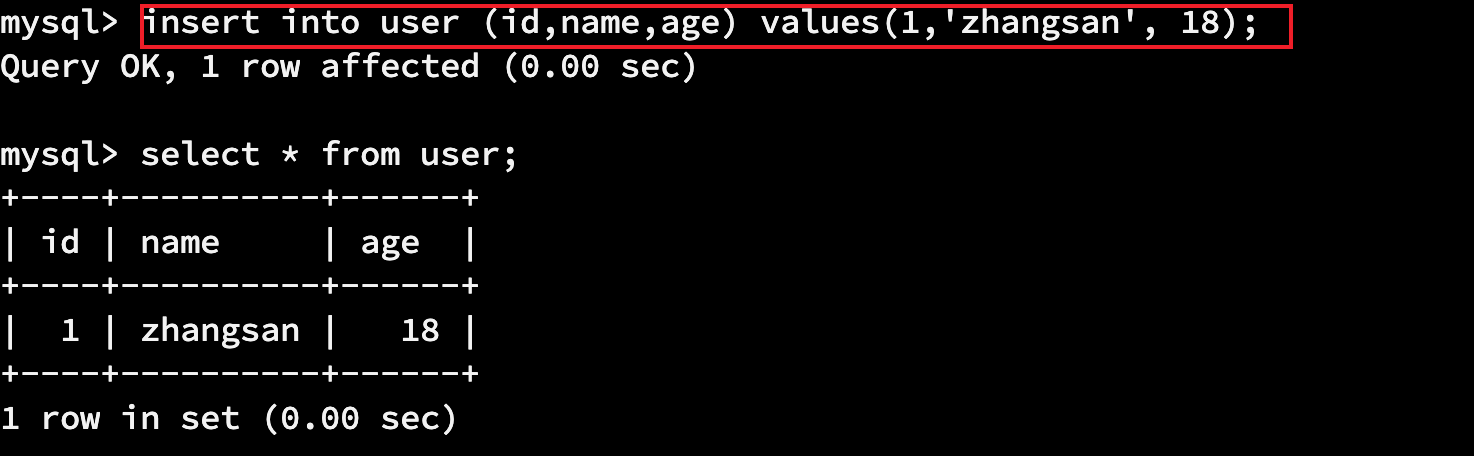
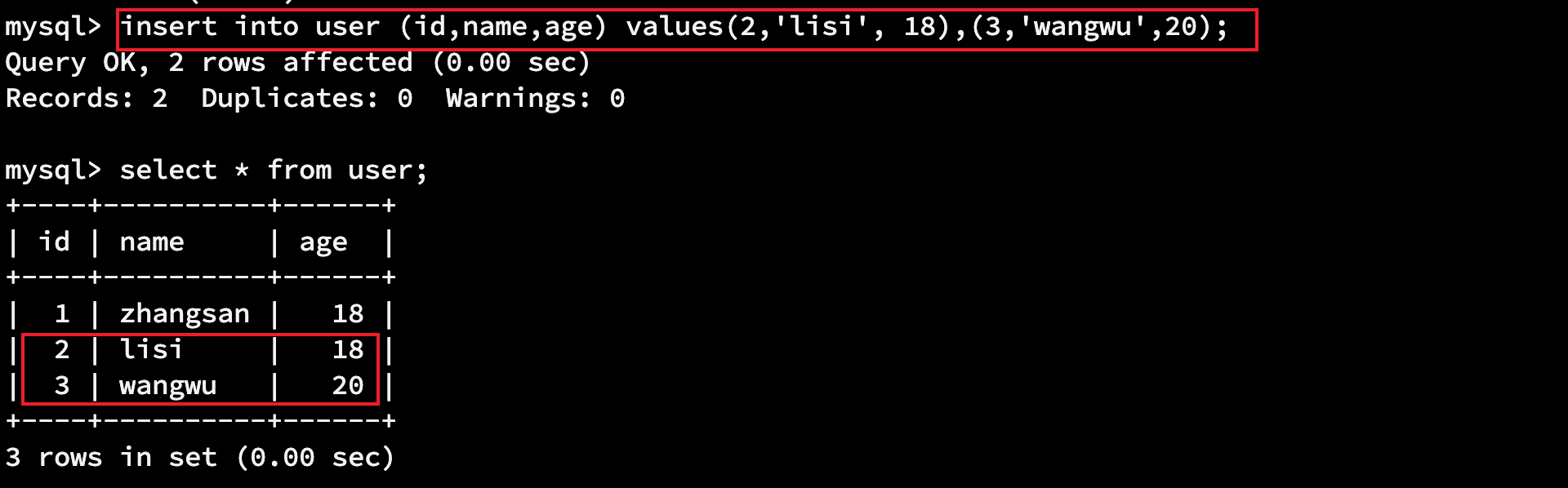
3.1.2 删除数据
delete from 表名 where 条件;
delete from user where name='zhangsan'; delete from user where id > 9; delete from user where name='zhangsan' and id < 6; delete from user where name='zhangsan' or id = 1;
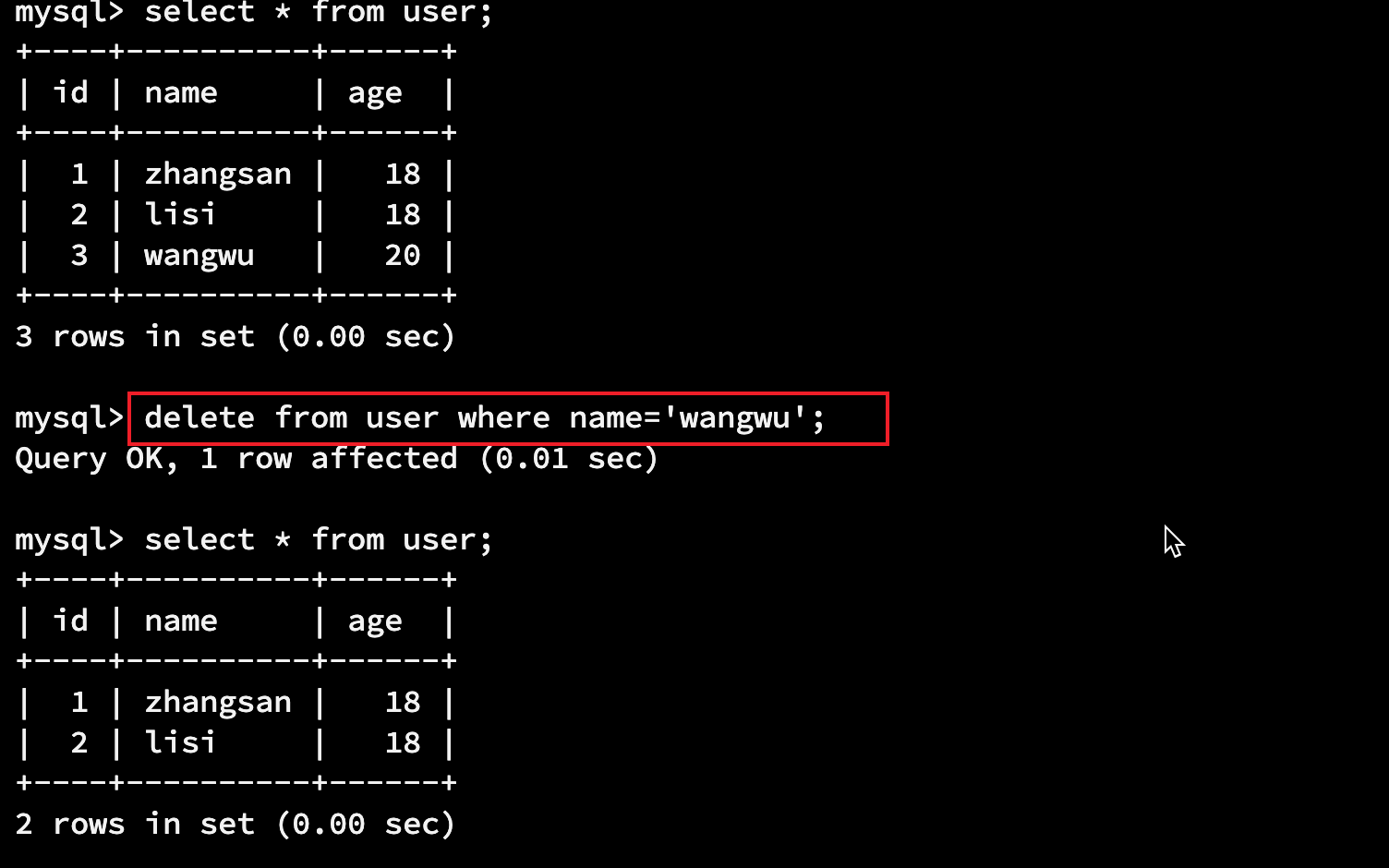
3.1.3 修改数据
update 表名 set 列名=值 where 条件;
update user set name='kunmzhao' where id = 1;
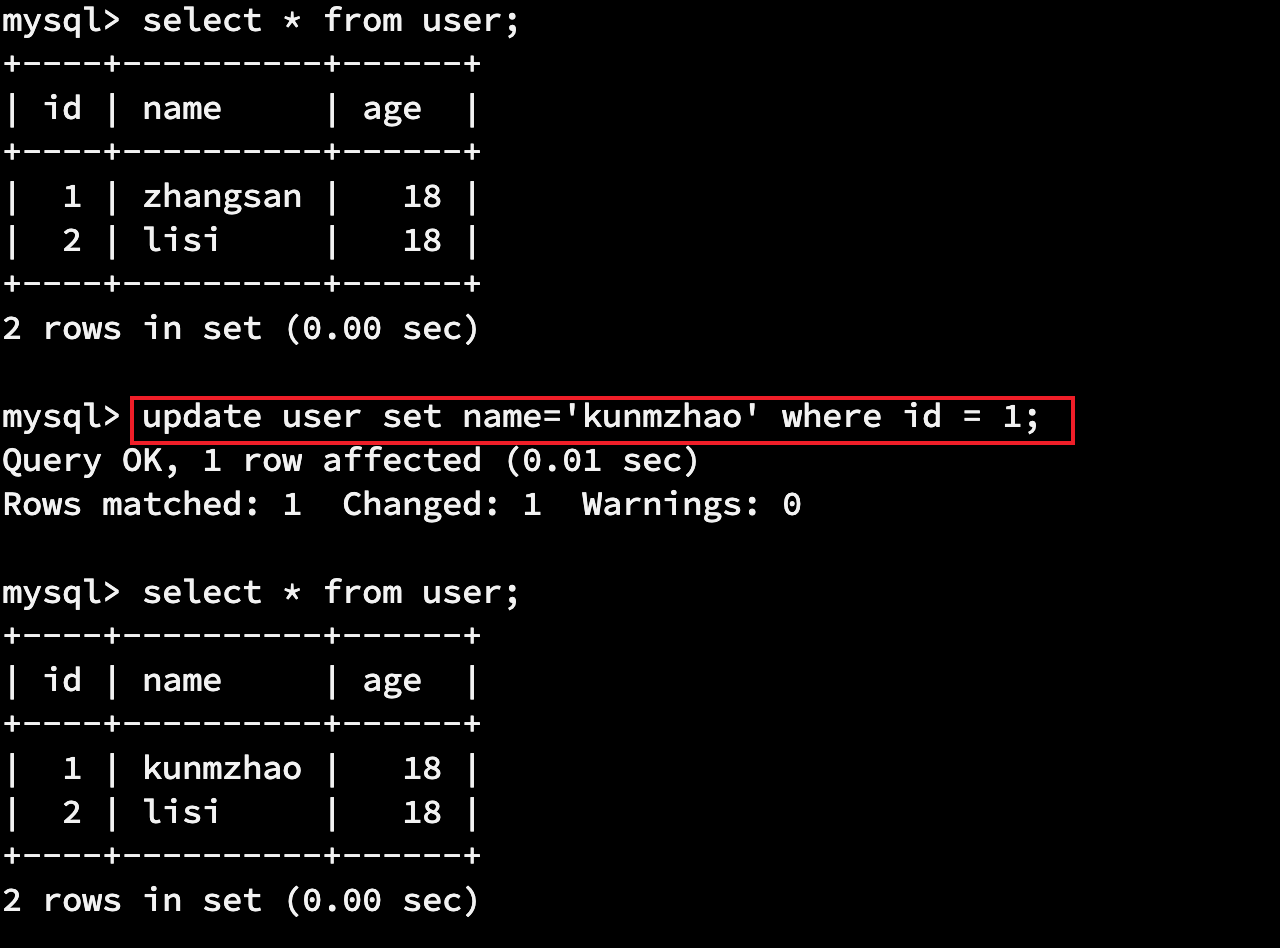
3.1.4查询数据
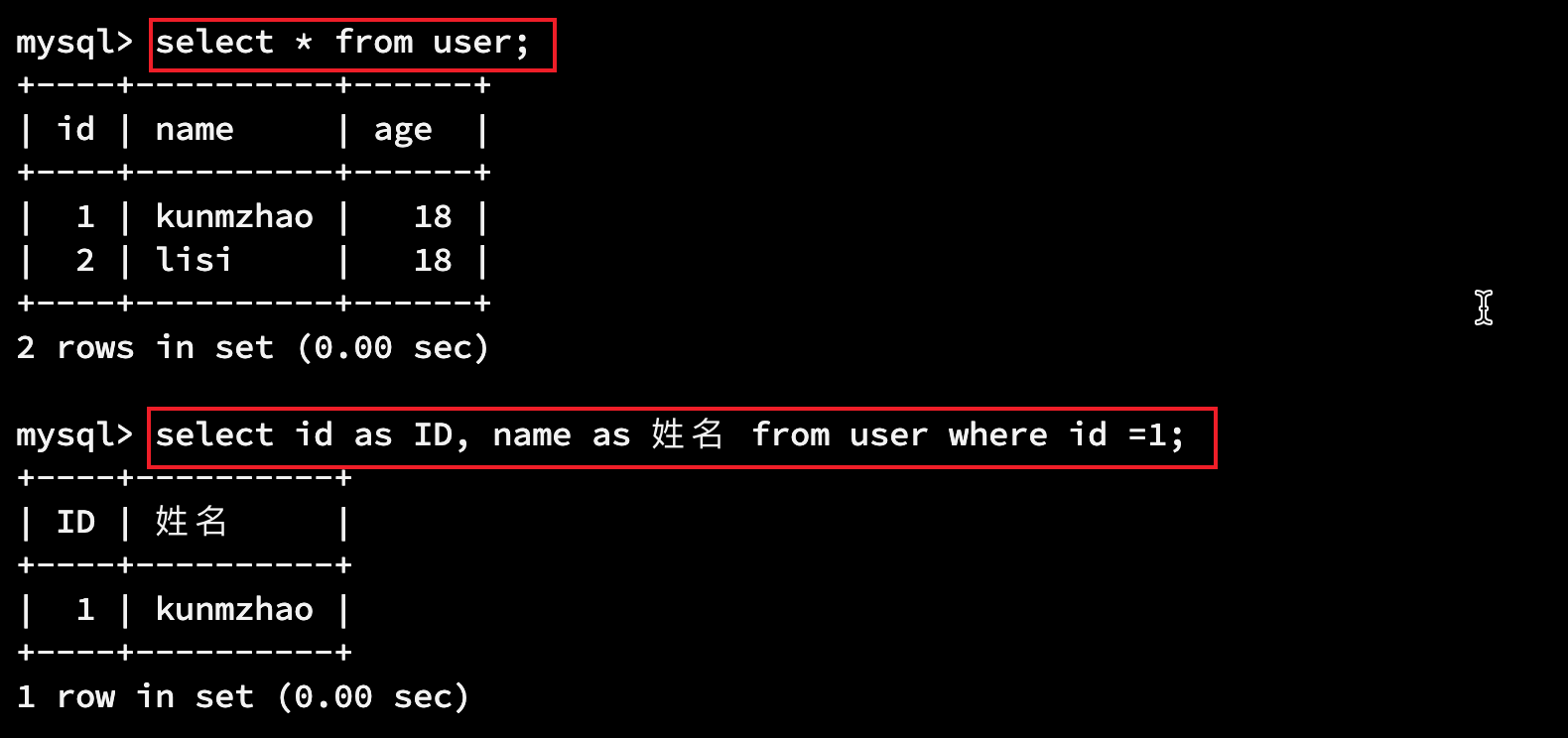
select * from 表名; select 列名,列名,列名 from 表名; select 列名 as 别名,列名,列名 from 表名; select 列名,列名,列名 from 表名 where 条件;
select * from user; select id as ID, name as 姓名 from user where id =1;
3.2 python操作
import pymysql # 连接MySQL,自动执行 use userdb; -- 进入数据库 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', charset="utf8", db='userdb') cursor = conn.cursor() # 1.新增(需commit) cursor.execute("insert into tb1(name,password) values('武沛齐','123123')") conn.commit() # 2.删除(需commit) cursor.execute("delete from tb1 where id=1") conn.commit() # 3.修改(需commit) cursor.execute("update tb1 set name='xx' where id=1") conn.commit() # 4.查询 cursor.execute("select * from tb where id>10") data = cursor.fetchone() # cursor.fetchall() print(data) # 关闭连接 cursor.close() conn.close()
3.3 查询数据进阶
3.3.1 条件
where
# 比较运算 select * from info where age > 30; select * from info where aid != 1; select * from info where between 2 and 4; -- id介于2-4之间 # 逻辑运算 select * from info where name='alex' and age=16; select * from info where name='alex' or age = 16; # 成员运算 select * from info where id in (1,4,6); select * from info where id not in (1, 4, 6); select * from info where id in (select id from depart); # 布尔运算 # select * from depart where id=5存在则整体进行查询,否则整体为空 select * from info where exists (select * from depart where id=5);
3.3.2 通配符
一般用于模糊搜素 使用关键字like
%:多个字符 ?:单个字符 #:单数字
select * from info where name like "%明%" -- 查询包含明的name select * from info where name like "明%" -- 查询包含明且以明开头的name select * from info where name like "%明" -- 查询包含明且以明结尾的name
3.3.3 映射
获取想要的列
select * from info; -- 获取info表的所有字段 select id,name from info; -- 获取info表的id,name字段 select id, name as 姓名 from info; -- 获取info表的id,name字段,并将name字段命名为姓名
3.3.4 排序
select * from info order by age asc; -- 按照年龄顺序排序 select * from info order by age desc; -- 按照年龄倒序排序 select * from info order by age asc,id desc; -- 优先按照age从小到大;如果age相同则按照id从大到小。
3.3.5 取部分
获取部分数据
select * from info limit 5; -- 获取前5条数据 select * from info limit 3 offset 2; -- 从位置2开始,向后获取前3数据
3.3.6 分组
select age,max(id),min(id),count(id),sum(id),avg(id) from info group by age; select depart_id,count(id) from info group by depart_id having count(id) > 2; -- 分组之后再进行条件筛选 select count(id) from info; select max(id) from info;
3.3.7 连表
多个表可以连接起来进行查询
union
通过union从多个表中提取记录合并显示,union就是将多个select的结果合并显示出来,可以联合多个表
select * from 表1 union select * from 表2 -- 会自动去重
select * from 表1 union all select * from 表2 -- 不会自动去重,将所有符合条件的记录显示出来

内连接 inner join
把不同的表中相匹配的记录提取出来的方式叫做内连接,内连接返回两个表中匹配的行,即仅返回满足连接条件的记录。只有在连接条件匹配的情况下,才会将两个表中的行组合起来。
显示所有的列信息
select * from 表1 inner join 表2 on 表1的列=表2的列
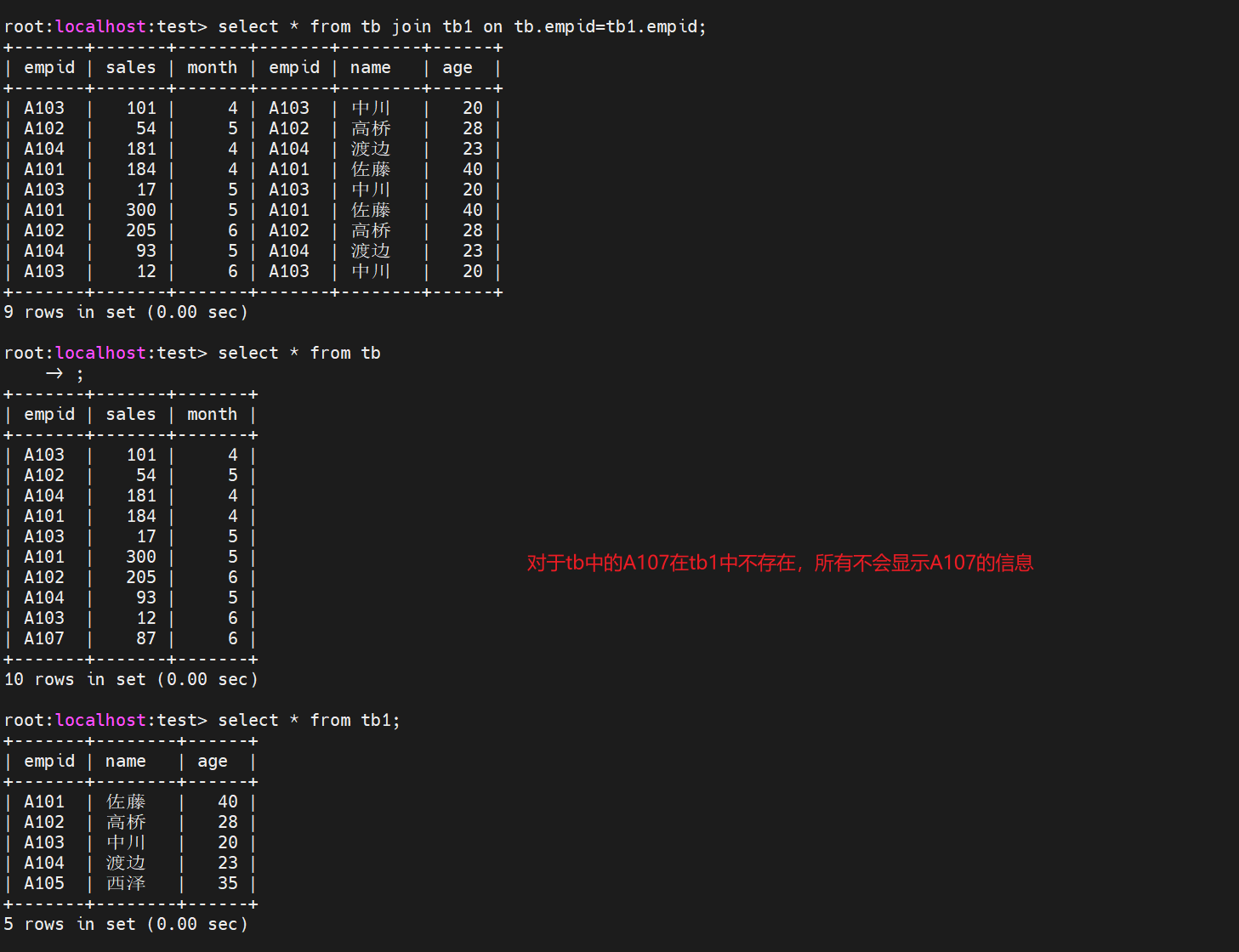
显示指定的列信息,在指定字段的时候需要指定表名
select 列名1, 列名2 from 表1 inner join 表2 on 表1的列=表2的列

通过as 也可以给表添加别名,对于表名特别长的时候,会特别好用,如下

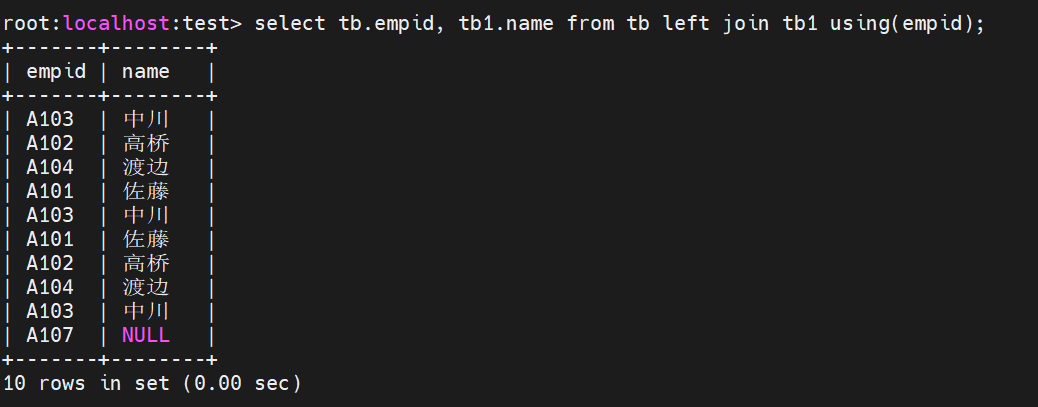
对于两张表中如果使用的关键键名字是一样的可以使用using来简写
select x.empid ,y.name, x.sales from tb as x inner join tb1 as y on x.empid=y.empid; 简写为 test> select x.empid ,y.name, x.sales from tb as x inner join tb1 as y using(empid);
对多张表进行连接
select 列名 from 表1 join 表2 on 连接条件 join 表3 on 连接条件

外连接 join
与内连接相对,即使连接键不匹配,外连接也会提取另一个表中的所有记录
左外连接 left join
显示左表的所有记录
右外连接 right join
显示右表的所有记录

注意:left join 和right join也可以写成left outer join 和right outer join
自连接
将表与其自身进行连接,因为是两个同名的表进行连接,所以连接的时候必须定义别名
select 列名 from 表名 as 别名1 join 表名 as 别名2;

假设有n条记录,通过自关联查询,会产生n^2的记录
那么自连接有什么作用呢?我们可以通过自连接进行排序,如计算每个人的年龄排名次序

遇到如下问题及解决方案

子查询
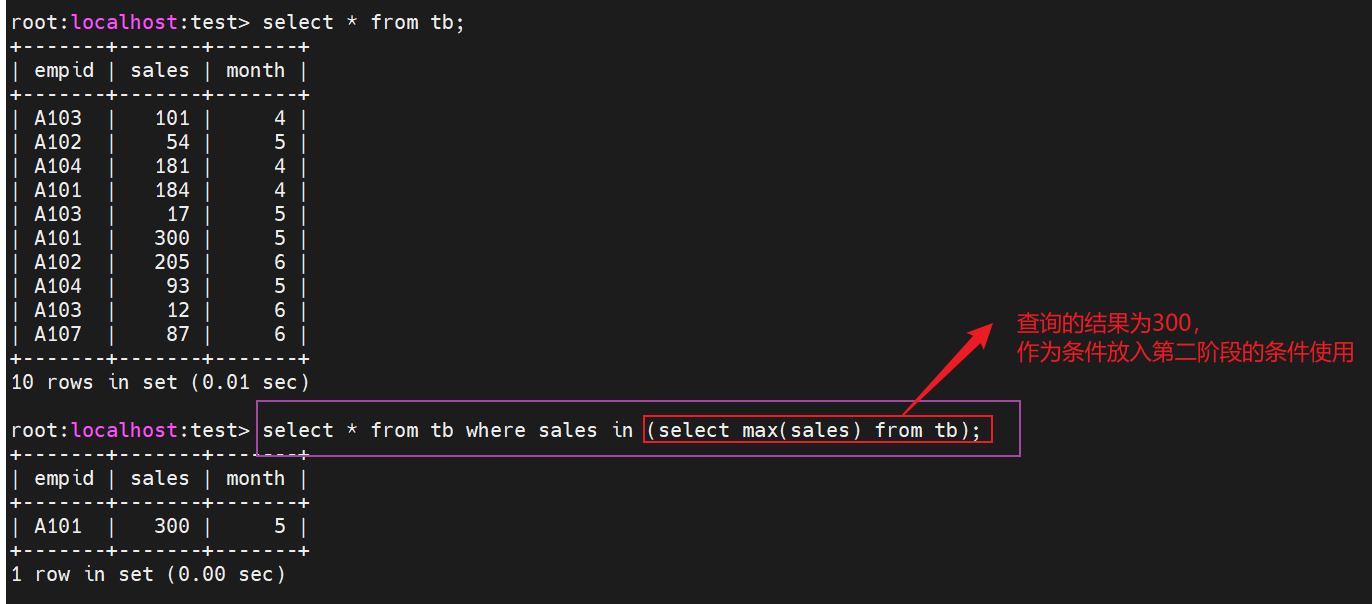
子查询可以完成两个阶段的处理,执行查询,然后使用检索到的记录进一步执行查询,对于第一步的查询必须使用()
如我们查询销售额最大的全部信息
如提取大于等于平均值的记录

使用in(返回列的子查询)
在第一阶段的子查询中返回符合条件的列,然后在第二阶段中提取包含该列的记录
select 显示的列 from 表名 where 列名 in (通过子查询select提取的列);
如显示销售额大于等于200万的员工姓名

使用exists,以存在的记录为对象
如:查询员工信息表上有销售额的员工记录
从表tb中提取有销售额的员工记录,然后从tb1中提取对应的记录

使用not exists,以不存在的记录为对象

使用子查询来进行排序,将tb按照销售额进行排名,思路是重新复制一个表,将tb表按照sales排序之后的结果插入到新的表中
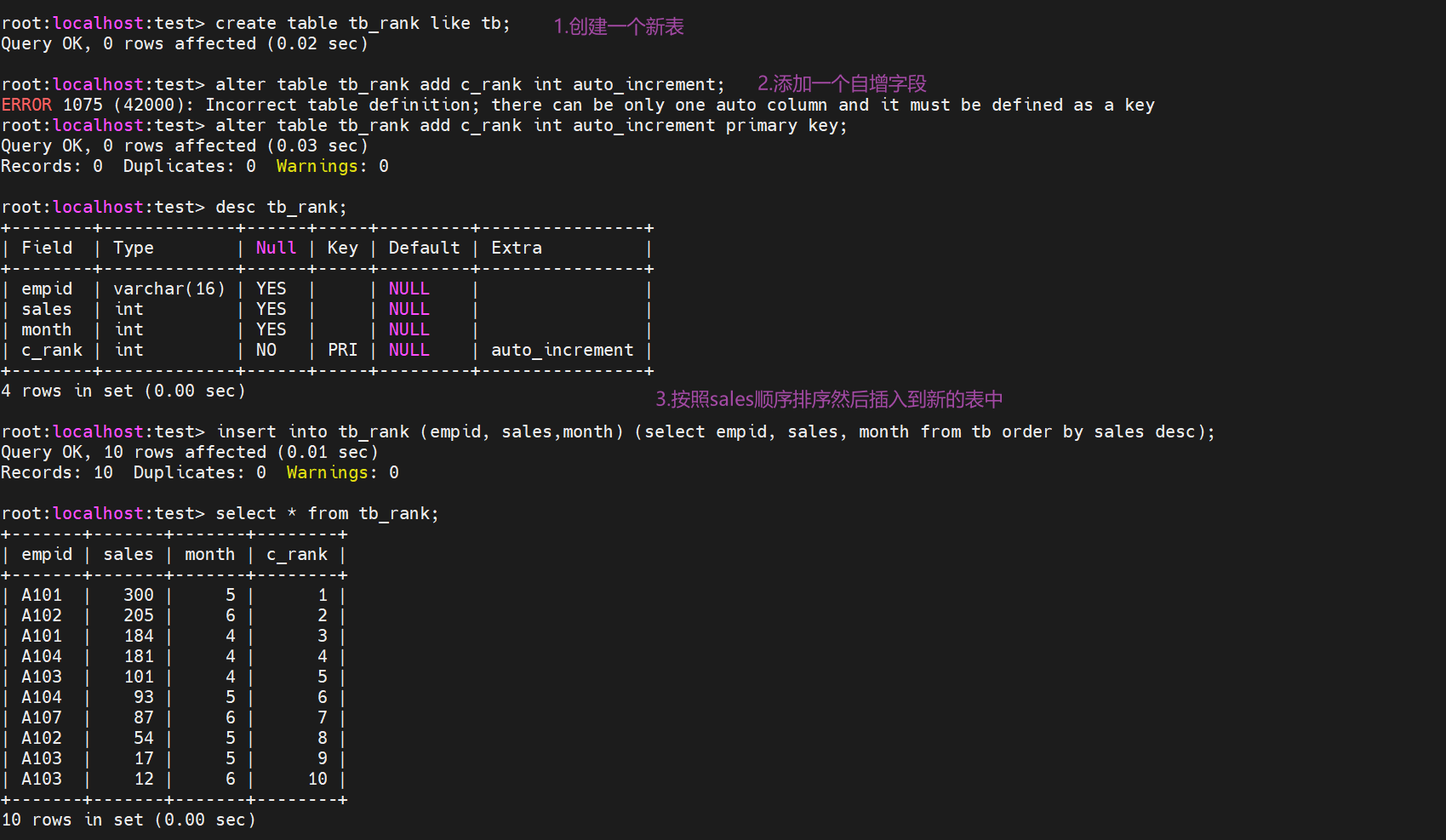
到目前为止SQL执行顺序:
- join
- on
- where
- group by
- having
- order by
- limit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号