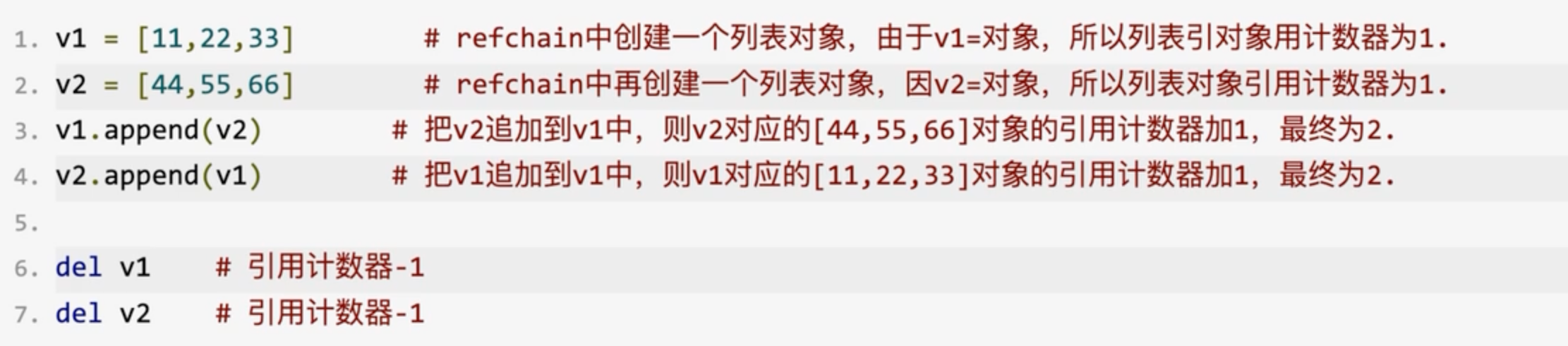
python中的垃圾回收机制是以引用计数器为主,标记清除和分代回收为辅的 + 缓存机制
1.引用计数器
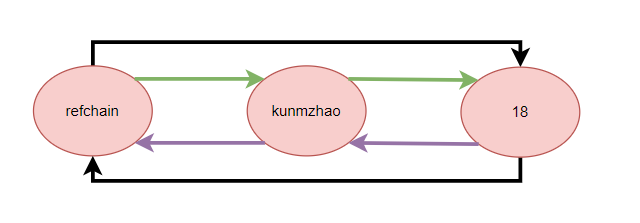
在python内部维护了一个名为refchain的环状双向链表,在python中创建的任何对象都会放在refchain中
name = "kunmzhao" age=18
在python中创建的对象,在底层是由C语言中的结构体存储的

在这些结构体中存储这上一个对象,下一个对象,对象类型和引用个数
1.1 引用计数
在python运行过程中,当我们创建一个对象的时候,会根据数据类型找到对应的结构体,创建对象,然后将对象添加在refchain中,并且引用计数为1.当对象被引用的时候就会+1,当对象被del的时候就-1
当一个对象的引用计数=0的时候,代表着这个对象就是垃圾,需要被回收,将对象从refchain中移除
1.2 循环引用问题
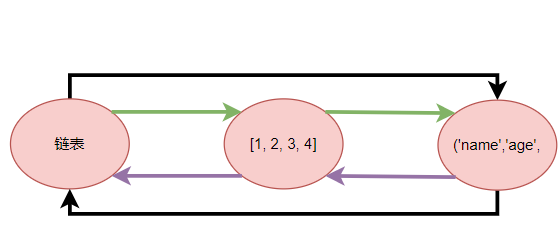
当两个列表互相嵌套的时候,就出现了循环引用,不解决的话就出现了内存泄漏
2.标记清除
标记清除的目的是为了解决引用计数中的循环引用问题
实现原理:在python内部再维护一个双线链表,用于存放可能存在循环引用的对象(列表,字典,元组,集合类型),在一定条件下出触发链表的全部扫描,检查是否有循环引用,如果存在,则将双方的引用计数-1,如果为0则进行垃圾及回收
3.分代回收
目的是为了优化标记清除,因为如果标记清除维护的链表很大,每次都遍历会非常消耗性能,为此分代回收维护了3个链表,3个链表代表着不同的扫描阈值,当达到阈值之后才会触发对应链表的扫描
-
-
1代:0代扫描10次,则1代扫描一次
-
4.缓存机制
频繁的申请和销毁内存是非常消耗时间的,为此又引入了缓存机制,包括缓存池和free_list
4.1缓存池
池的做法是预先缓存一些常见的对象比如-5到256的整型对象,和ASCII字符表等。当程序中定义了一个小的整型对象时,不需要从内存中申请内存,直接从池中获取即可
4.2 free_list
free_list的做法是将程序本来删除的对象,没有直接销毁而是放在一个名为free_list的数组中。后面当程序中重新创建一个相同类型的对象时,不必新开辟空间而是直接从free_list中获取对象,重新进行初始化并放入到refchain中去。
class Foo(object): name = 'kunmzhao' def __init__(self, name): self.name = name def send_msg(self): print(self.name) foo = Foo('kunmzhao') # 2324775989200 print(id(foo)) del foo
foo1 = Foo('Victor') # 2324775989200 print(id(foo1))

