05 Linear Regression
 线性回归,PyTorch构建模型的基本流程
线性回归,PyTorch构建模型的基本流程
Design Model
基本过程
- 准备数据集
- 通过继承nn.Module来设计模型
- 构造损失函数和优化器
- 训练周期(这里设定1000个周期)
a. 前馈计算\(\hat{y}\)
b. 计算损失
c. 反向传播
d. 更新
代码实现
import torch
# 准备数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModule(torch.nn.Module):
"""
首先要把模型定义为一个类, 定义的这个类都继承自Module父类
这个类最少包含两个函数, 一个构造函数__init__()和一个forward()
注意这里并没有单独做反馈的运算, 因为Module中会根据计算图自动实现Backward的过程
"""
def __init__(self):
# 构造函数, 初始化对象时默认调用的函数
super(LinearModule, self).__init__() # 调用父类的构造函数, 必需
self.linear = torch.nn.Linear(1, 1) # 类nn.Linear包含权重w和偏移b两个Tensor, 用这两个参数构造对象
'''linear由Linear实例化'''
def forward(self, x):
# 在前馈过程中所需要进行的运算
y_pred = self.linear(x) # 做w*x+b的运算
return y_pred
model = LinearModule()
criterion = torch.nn.MSELoss(size_average=False) # 利用MSE(继承自nn.Module, 会构建计算图)构造损失函数, 这里设定不求均值
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
"""
构造优化器, 实例化SGD类.
参数一的parameter函数会检查model的所有成员, 如果成员中有相应的权重就将其找出来
参数二设定学习率
"""
for epoch in range(1000):
y_pred = model(x_data) # 将x_data送入model计算$\hat{y}$
loss = criterion(y_pred, y_data) # 计算损失
print(epoch, loss) # loss是一个对象, print它时会自动调用__str__(), 不会产生计算图
optimizer.zero_grad() # 由于计算完梯度后, 其值会不断积累, 因此需要将梯度归零
loss.backward() # 反向传播
optimizer.step() # 根据梯度和设定的学习率更新权重
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([4.0]) # 测试输入
y_test = model(x_test)
print('y_pred=', y_test.item())
观察使用SGD优化器时的变化过程
import torch
import matplotlib.pyplot as plt
# 准备数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModule(torch.nn.Module):
"""
首先要把模型定义为一个类, 定义的这个类都继承自Module父类
这个类最少包含两个函数, 一个构造函数__init__()和一个forward()
注意这里并没有单独做反馈的运算, 因为Module中会根据计算图自动实现Backward的过程
"""
def __init__(self):
# 构造函数, 初始化对象时默认调用的函数
super(LinearModule, self).__init__() # 调用父类的构造函数, 必需
self.linear = torch.nn.Linear(1, 1) # 类nn.Linear包含权重w和偏移b两个Tensor, 用这两个参数构造对象
'''linear由Linear实例化'''
def forward(self, x):
# 在前馈过程中所需要进行的运算
y_pred = self.linear(x) # 做w*x+b的运算
return y_pred
model = LinearModule()
criterion = torch.nn.MSELoss(size_average=False) # 利用MSE(继承自nn.Module, 会构建计算图)构造损失函数, 这里设定不求均值
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
"""
构造优化器, 实例化SGD类.
参数一的parameter函数会检查model的所有成员, 如果成员中有相应的权重就将其找出来
参数二设定学习率
"""
epoch_list = []
loss_list = []
for epoch in range(1001):
y_pred = model(x_data) # 将x_data送入model计算$\hat{y}$
loss = criterion(y_pred, y_data) # 计算损失
print(epoch, loss.item()) # loss是一个对象, print它时会自动调用__str__(), 不会产生计算图
optimizer.zero_grad() # 由于计算完梯度后, 其值会不断积累, 因此需要将梯度归零
loss.backward() # 反向传播
optimizer.step() # 根据梯度和设定的学习率更新权重
loss_list.append(loss.item())
epoch_list.append(epoch)
plt.plot(epoch_list, loss_list, color="green")
plt.xlabel("epoch")
plt.ylabel("loss value")
plt.show()
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([4.0]) # 测试输入
y_test = model(x_test)
print('y_pred=', y_test.item())
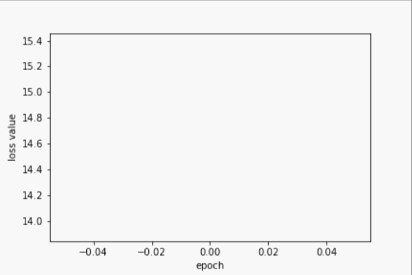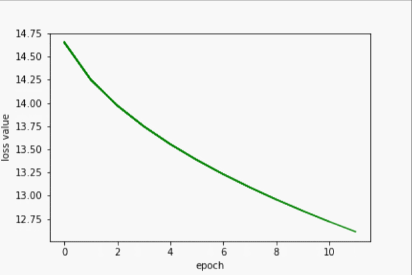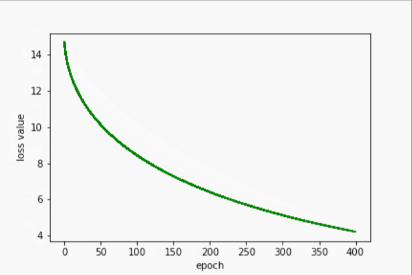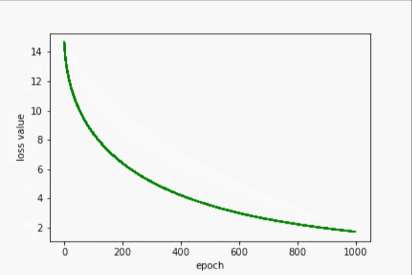
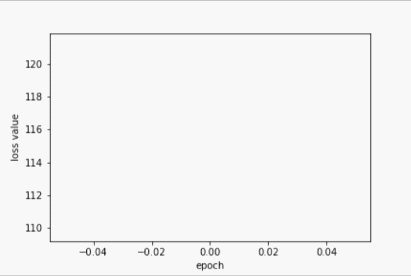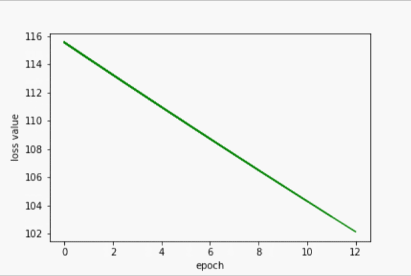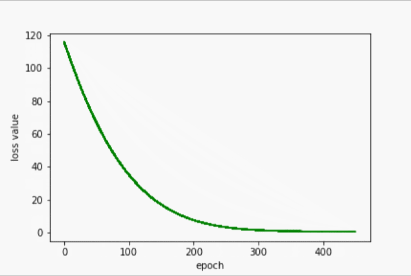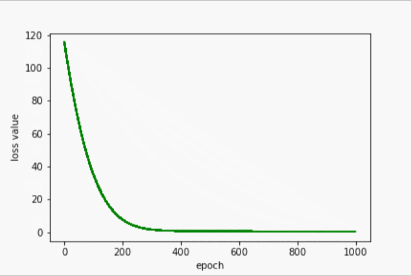
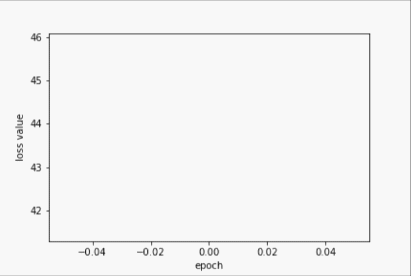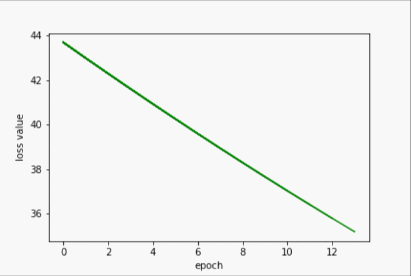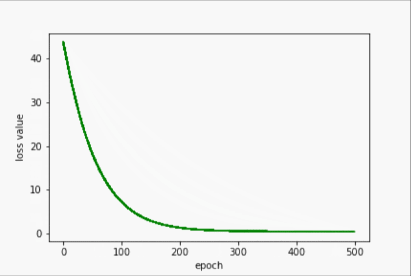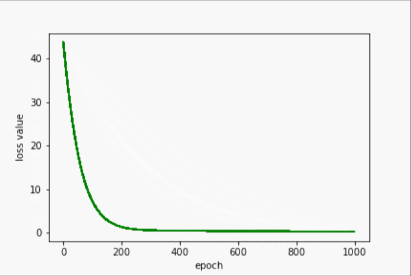
SGD
- 输出
w= 1.999812126159668
b= 0.000427166058216244
y_pred= 7.999675750732422
- 过程展示

Adagrad
- 输出
w= 1.305970549583435
b= 0.8834596276283264
y_pred= 6.107341766357422
- 过程展示
Adam
- 输出
w= 1.6004431247711182
b= 0.8861054182052612
y_pred= 7.287878036499023
- 过程展示
Adamax
- 输出
w= 1.6762775182724
b= 0.7182608246803284
y_pred= 7.423370838165283
- 过程展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号