05 RDD编程
8.按字母顺序排序 sortBy(f)

9.按词频排序 sortByKey()

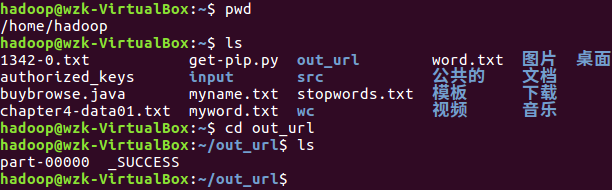
10.结果文件保存 saveAsTextFile(out_url)
代码:
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
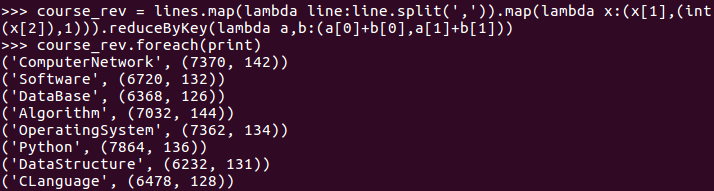
course_rev = lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1]))
course_rev.saveAsTextFile("file:///home/hadoop/out_url")
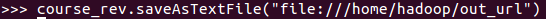
11. 词频结果可视化charts.WordCloud()
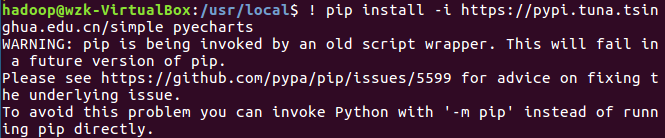
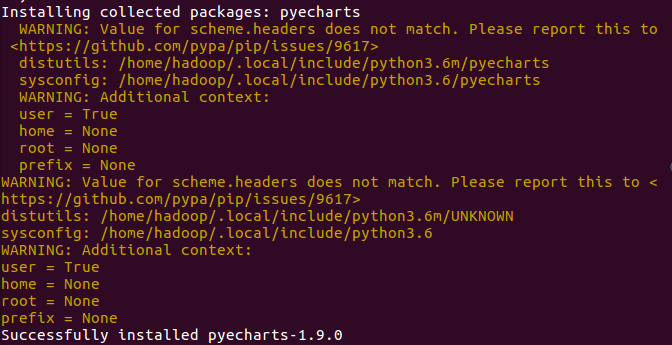
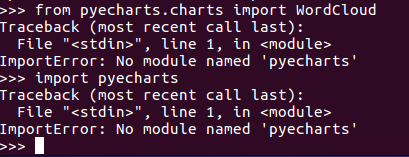
问题描述:1. pip在Ubuntu系统中不自带;
2. python自带版本2.7.1
3. python最新版本与pip不匹配(可能出现)
问题解决: 1. sudo apt-get install python3-pip
2. python3.6 -m pip install --upgrade pip
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 1
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.6 2
sudo update-alternatives --config python
12. 比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
二、学生课程案例分析
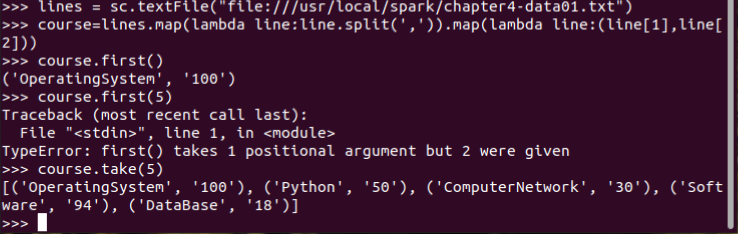
1.总共有多少学生?map(), distinct(), count()

2.开设了多少门课程?

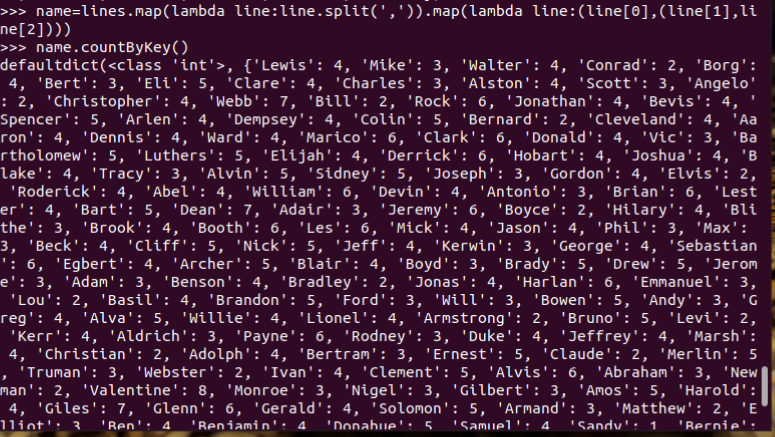
3.每个学生选修了多少门课?map(), countByKey()
4.每门课程有多少个学生选?map(), countByValue()

5.Tom选修了几门课?每门课多少分?filter(), map() RDD

6.Tom选修了几门课?每门课多少分?map(),lookup() list

7.Tom的成绩按分数大小排序。filter(), map(), sortBy()

8.Tom的平均分。map(),lookup(),mean()

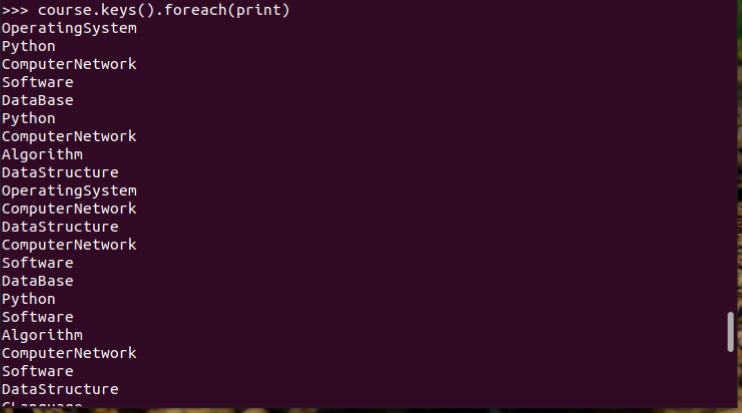
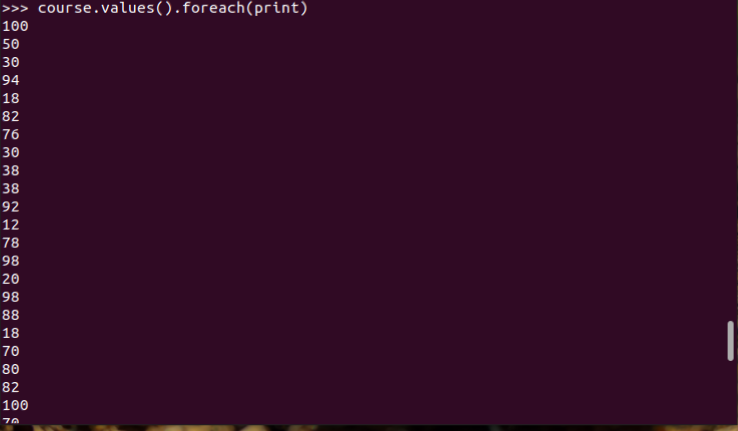
9.生成(课程,分数)RDD,观察keys(),values()
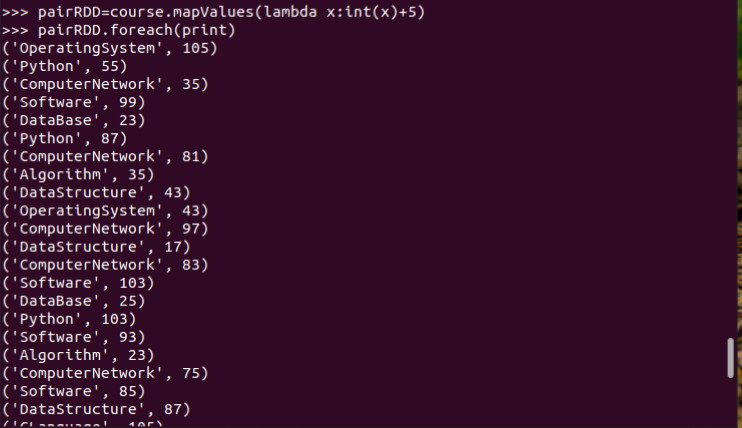
10.每个分数+5分。mapValues(func)
11.求每门课的选修人数及所有人的总分。combineByKey()

12.求每门课的选修人数及平均分,精确到2位小数。map(),round()

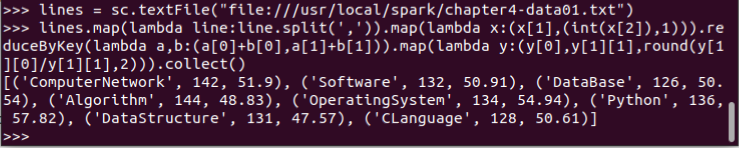
13.求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号