


【算法】实现 strStr()的KMP 算法原理解析
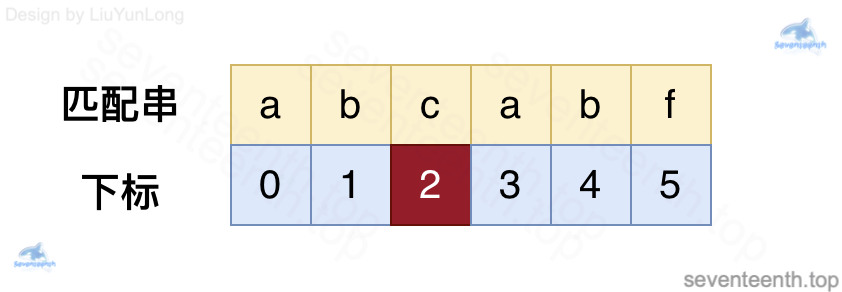
原字符串和匹配串如下:
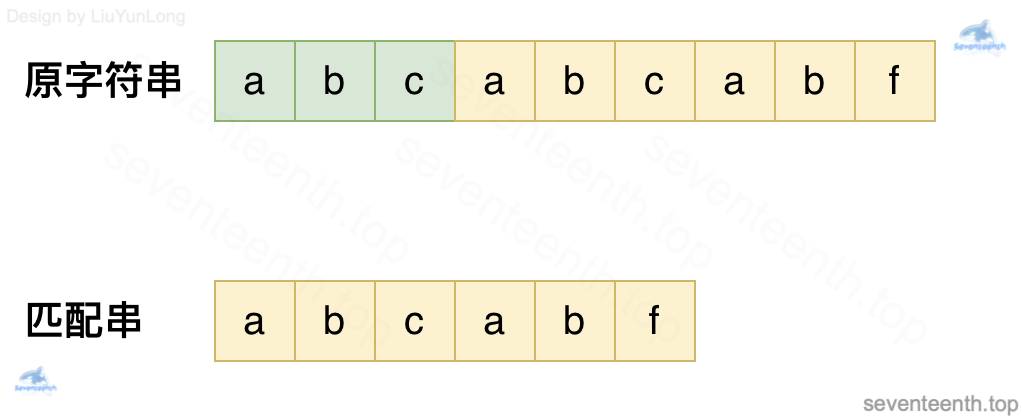
1. KMP 算法的效果
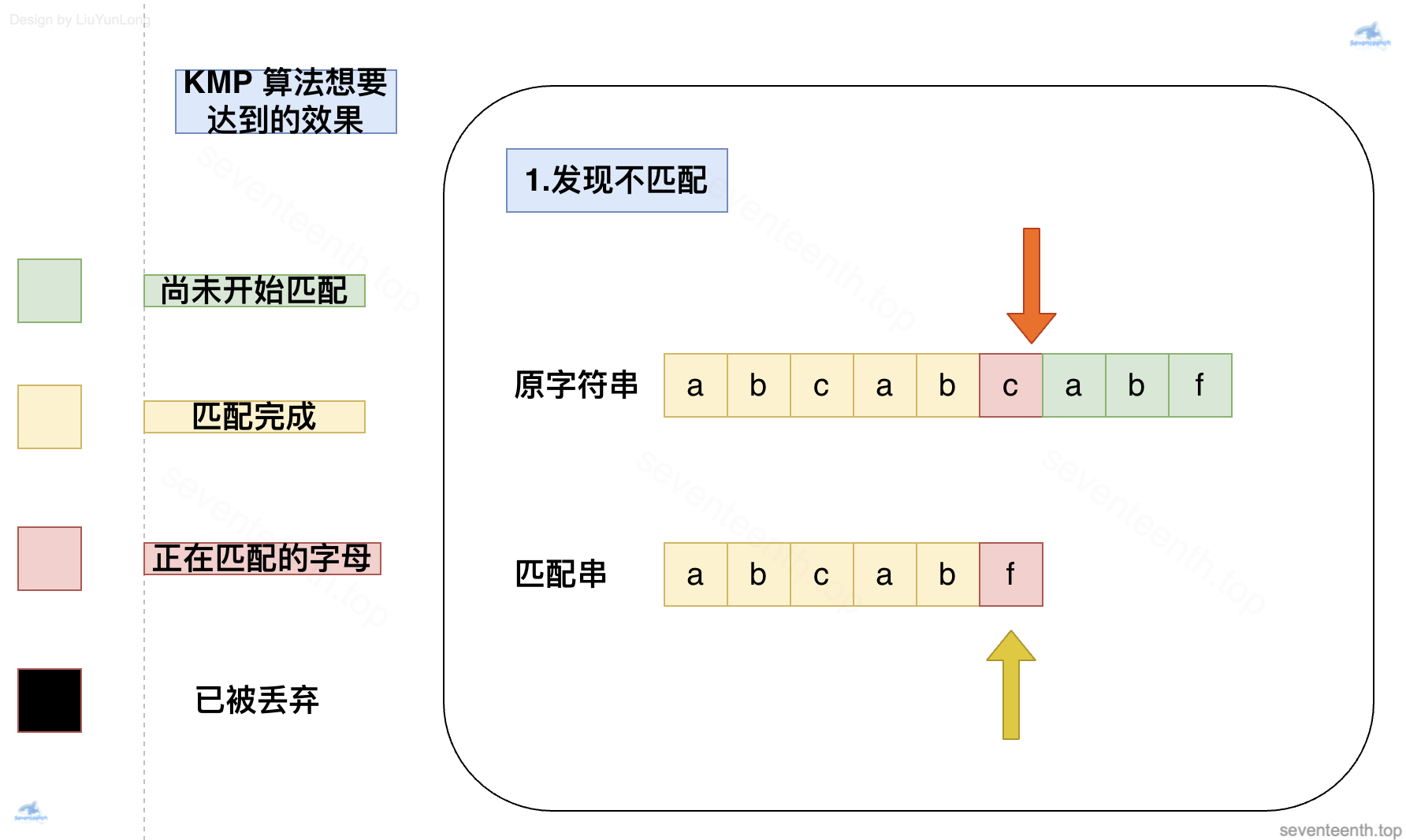
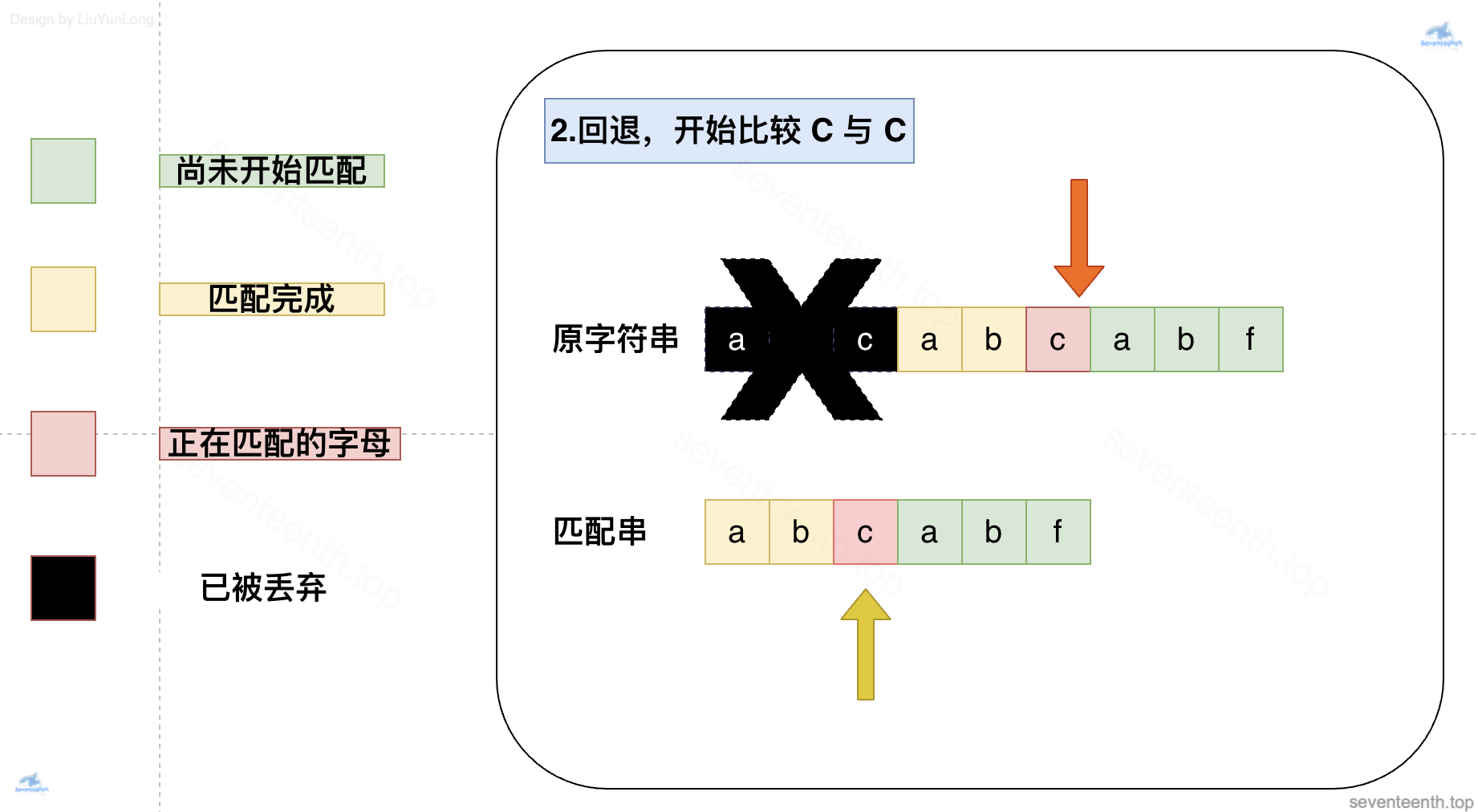
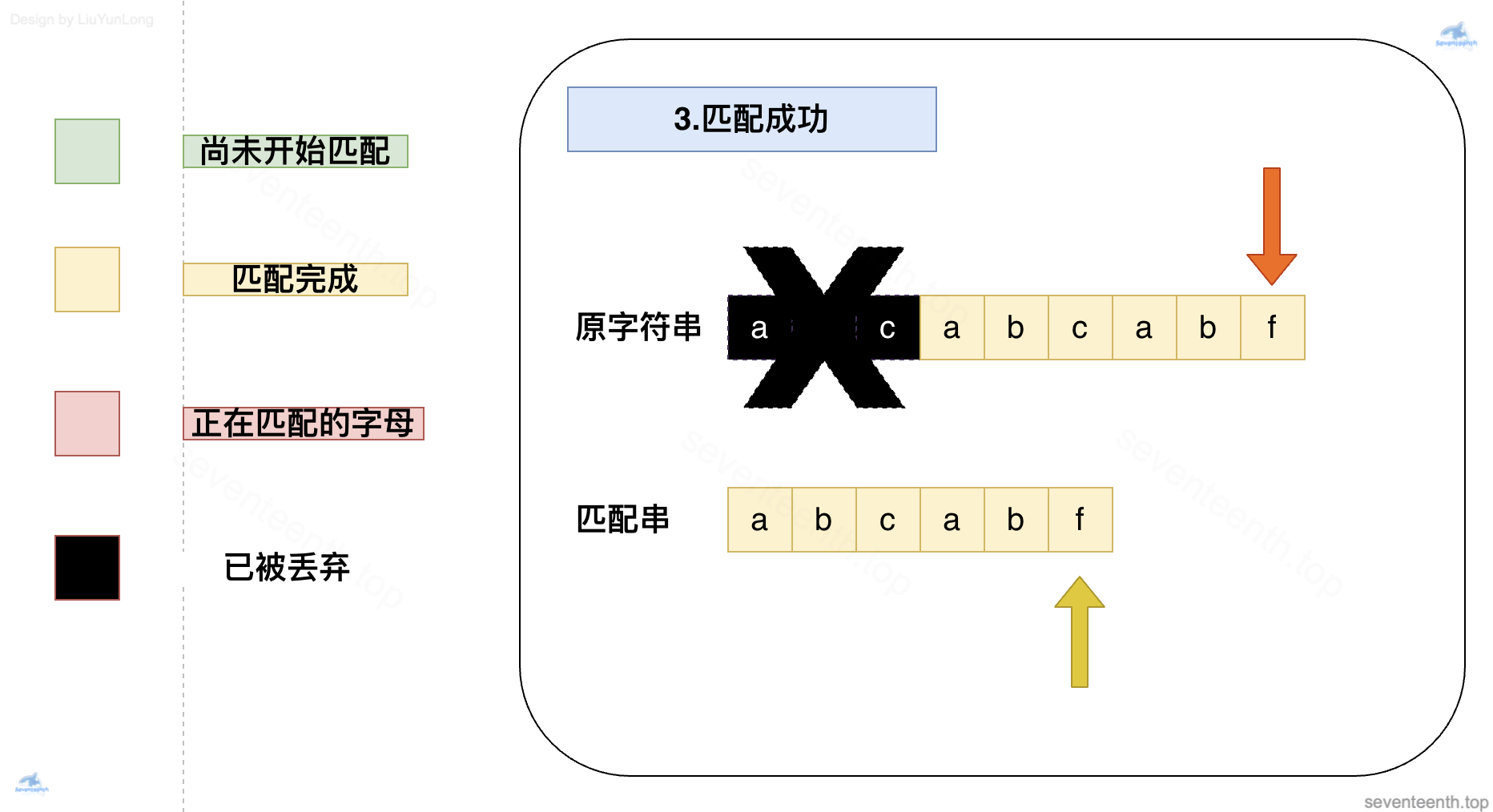
看起来就是简简单单的三个步骤,我们可以看出,其实 KMP 算法的关键,就在回退这个步骤。
2. 如何利用前缀表(next 数组)实现回退操作
在回退过程中我们使用到了 next 数组,那么 next 数组存放的是什么呢?
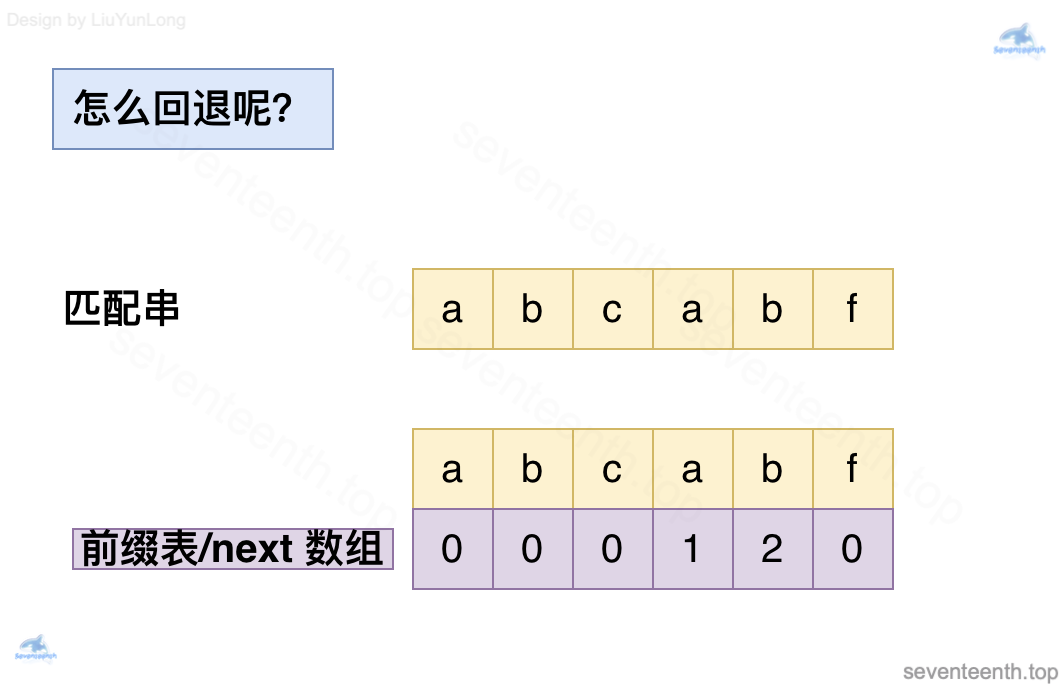
next 数组存放的是当前长度下的[最长相同前后缀]的长度
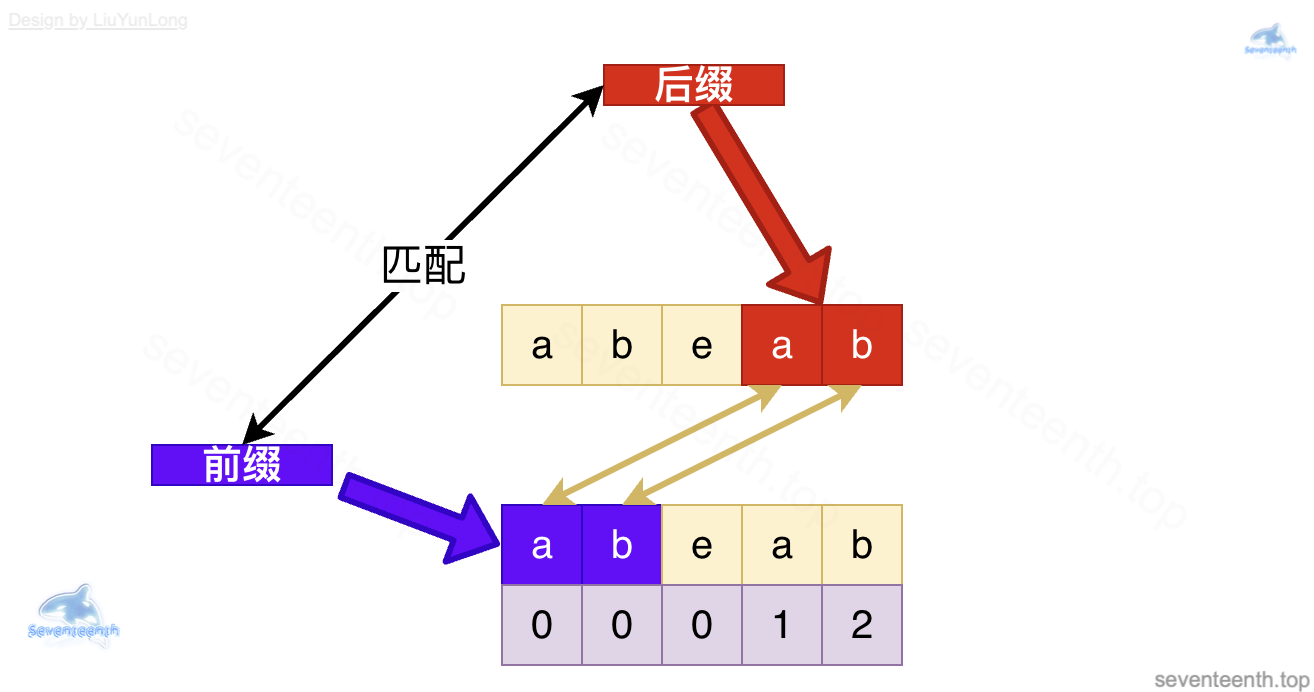
以 abcabf举例
- a时,最长前后缀长度是 0(前缀、后缀均不存在)
因为是缀。总长度就只有 1的话单独一个字母不算做缀
字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
- ab时,很显然长度也是 0(前缀为a,后缀为b,不存在相同前后缀)
- abc时,很显然长度也是 0(前缀为a、ab,后缀为c、bc,不存在相同前后缀)
- abca时, 最长相同前后缀长度就是 1了,是 a
- abcab时, 最长相同前后缀长度就是 2了,是 ab
- abcabf时,没有 最长相同前后缀了,长度是0
tips
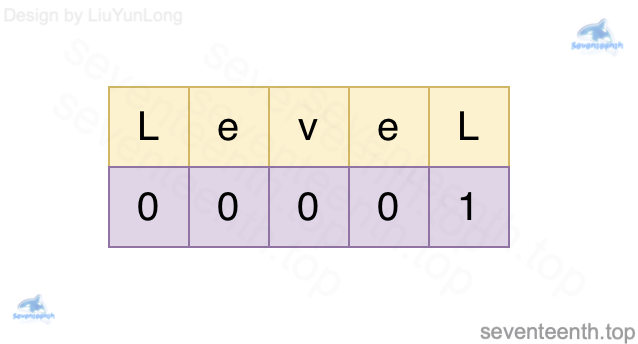
Le和 eL可是不能算相同前后缀的,这一点可能很多人都有误区。
下面的定义可以反复琢磨
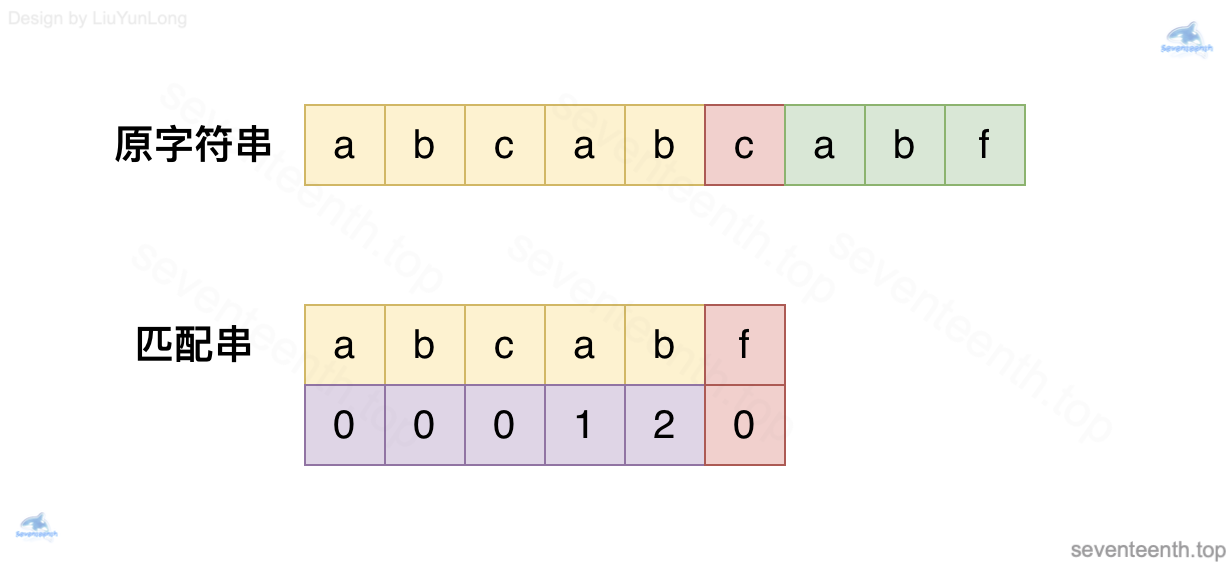
3. 深入了解 next 数组的运用
- 可以看到,现在已经匹配到
c与f,出现了第一个不相等的字母了
怎么回退呢?答案是找到上一个:因为上一个肯定是已经匹配完成的字母,我们找到它对应的 next 数组值来指导我们进行下一步操作
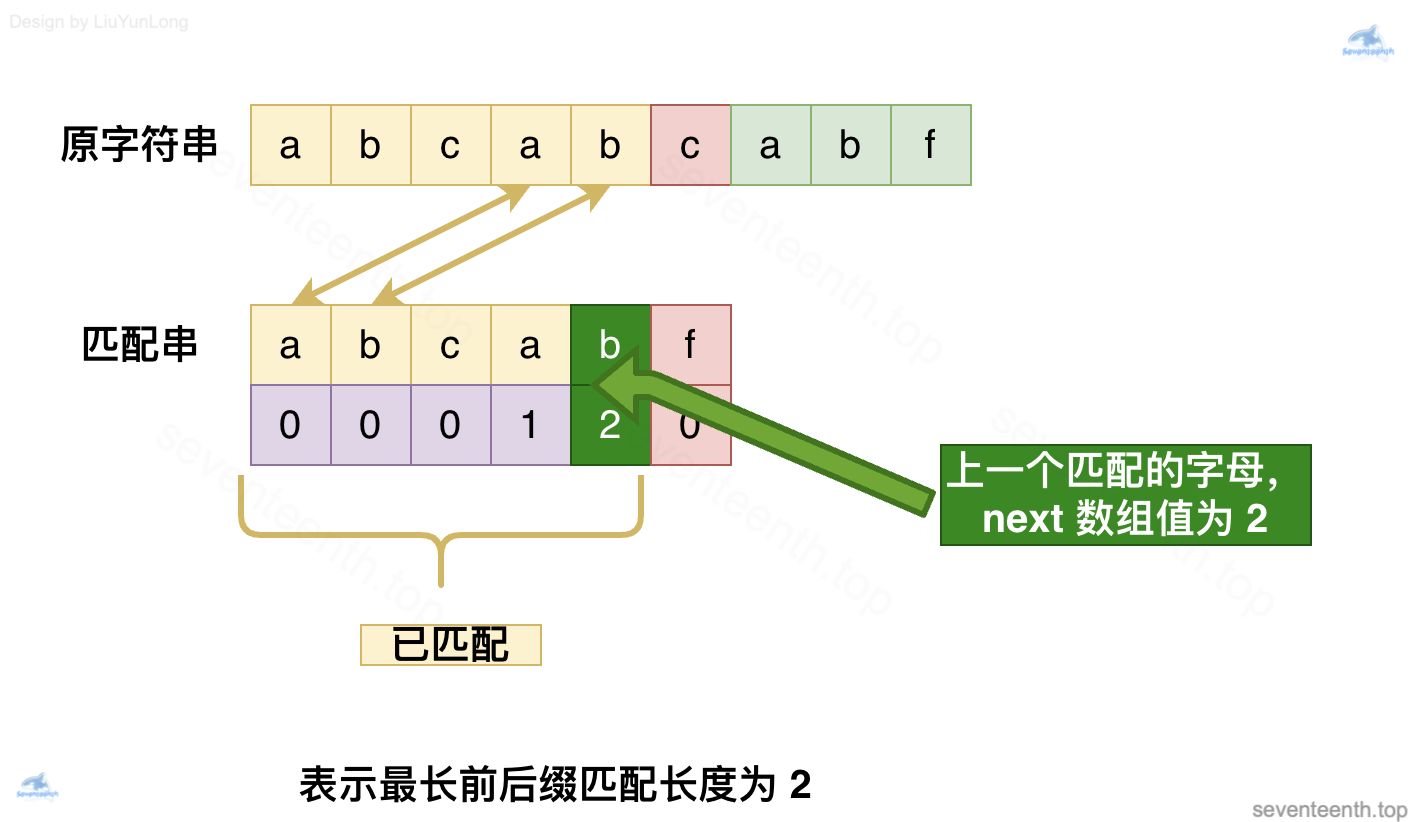
那么问题来了,现在 next 数组值 2代表什么呢?它想让我们干什么呢?
2表示当前已经匹配的子字符串 abcab的最长相同前后缀长度是 2,而我们数组下标是从 0️⃣开始的,如果我们按照 2的指示,正好可以跳转到下标 2 的位置(也就是字母C),开始下一次匹配。
前后缀起到了什么作用,怎么能确定 C 前面的字母已经匹配呢?
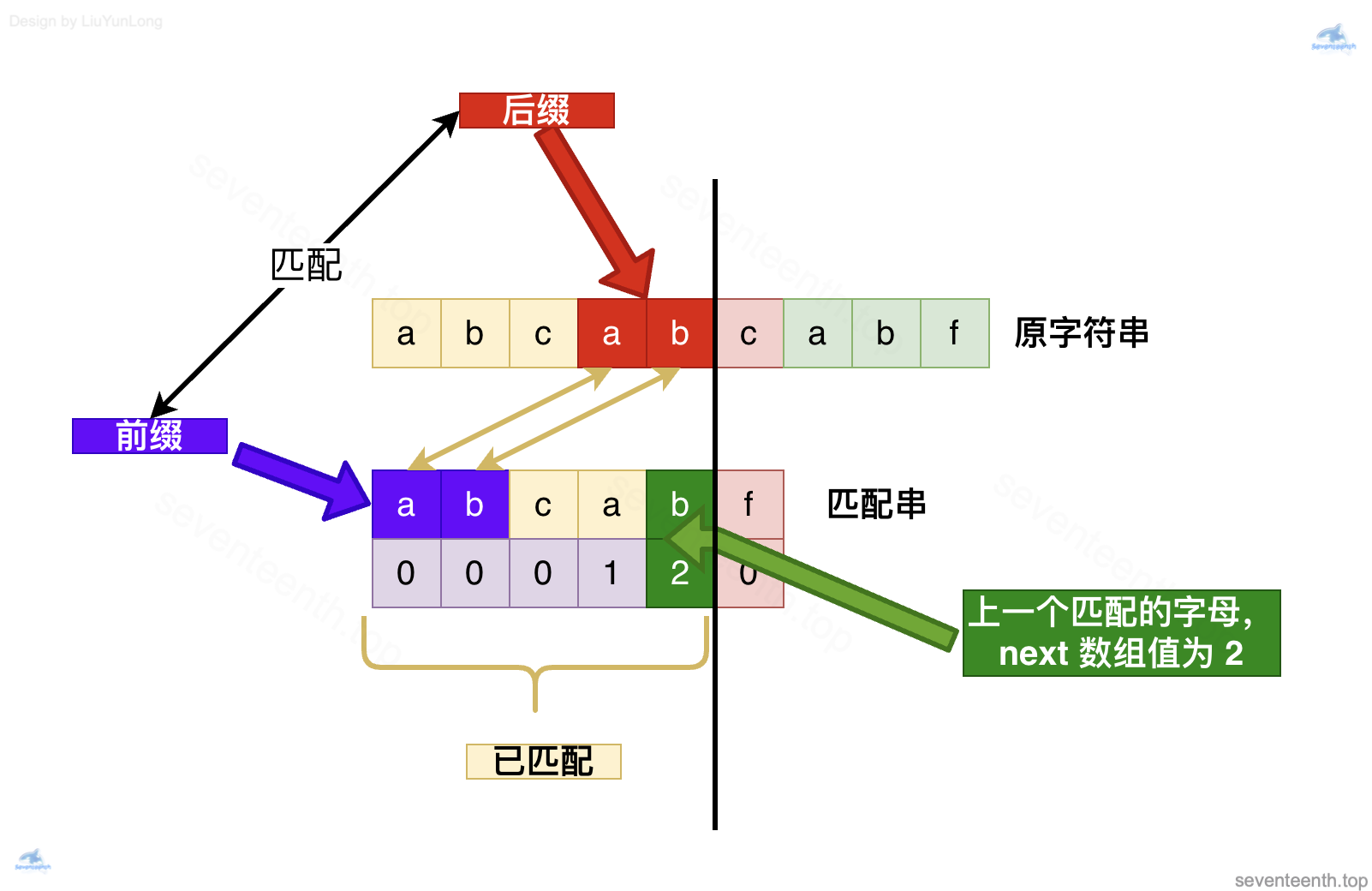
- 前缀的应用场景是匹配串;
- 而后缀的应用场景是原字符串;
!!!!next 数组记录的最长相同前后缀,在这里派上用场!!!!
我们也就确定了 C 前面的字母已经匹配,可以放心的匹配之后的字母了
前面的abc也就没有作用,不会再被考虑,被丢弃掉了
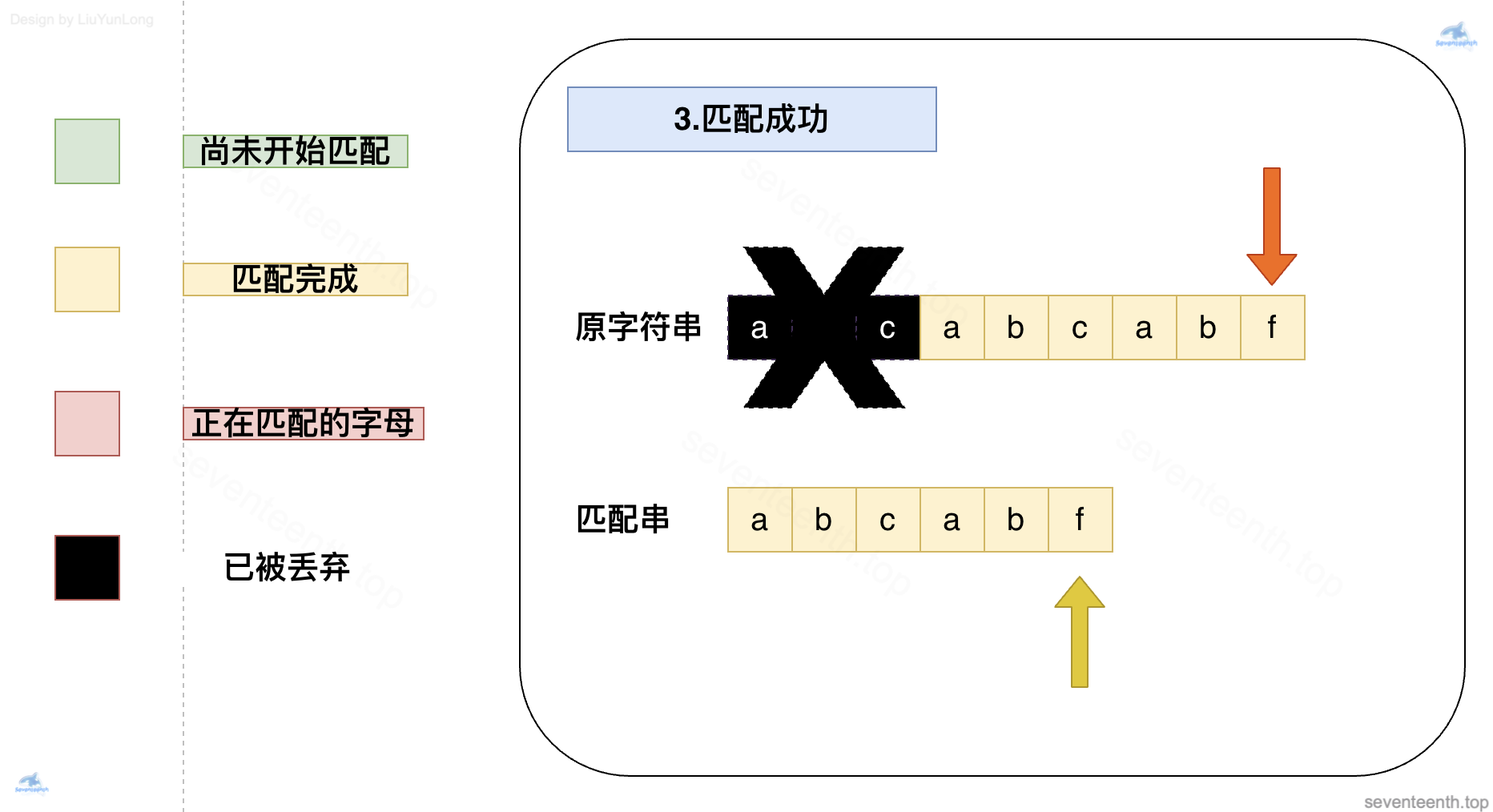
4. next 数组代码实现细节图
const m = needle.length; const next = new Array(m).fill(0); for (let rigth = 1, left = 0; right < m; right++) { // 定义好两个指针right与left // 在for循环中初始化指针right为1,left=0,开始计算next数组,right始终在left指针的后面 while (left> 0 && needle[right] !== needle[left]) { // 如果不相等就让left指针回退,若仍然needle[right] !== needle[left],就一直循环回退到0时就停止回退 left = next[left-1];// 进行回退操作;为何不直接退回0,可参考后续解析 } if (needle[right] == needle[left]) { left++; } next[right] = left; }
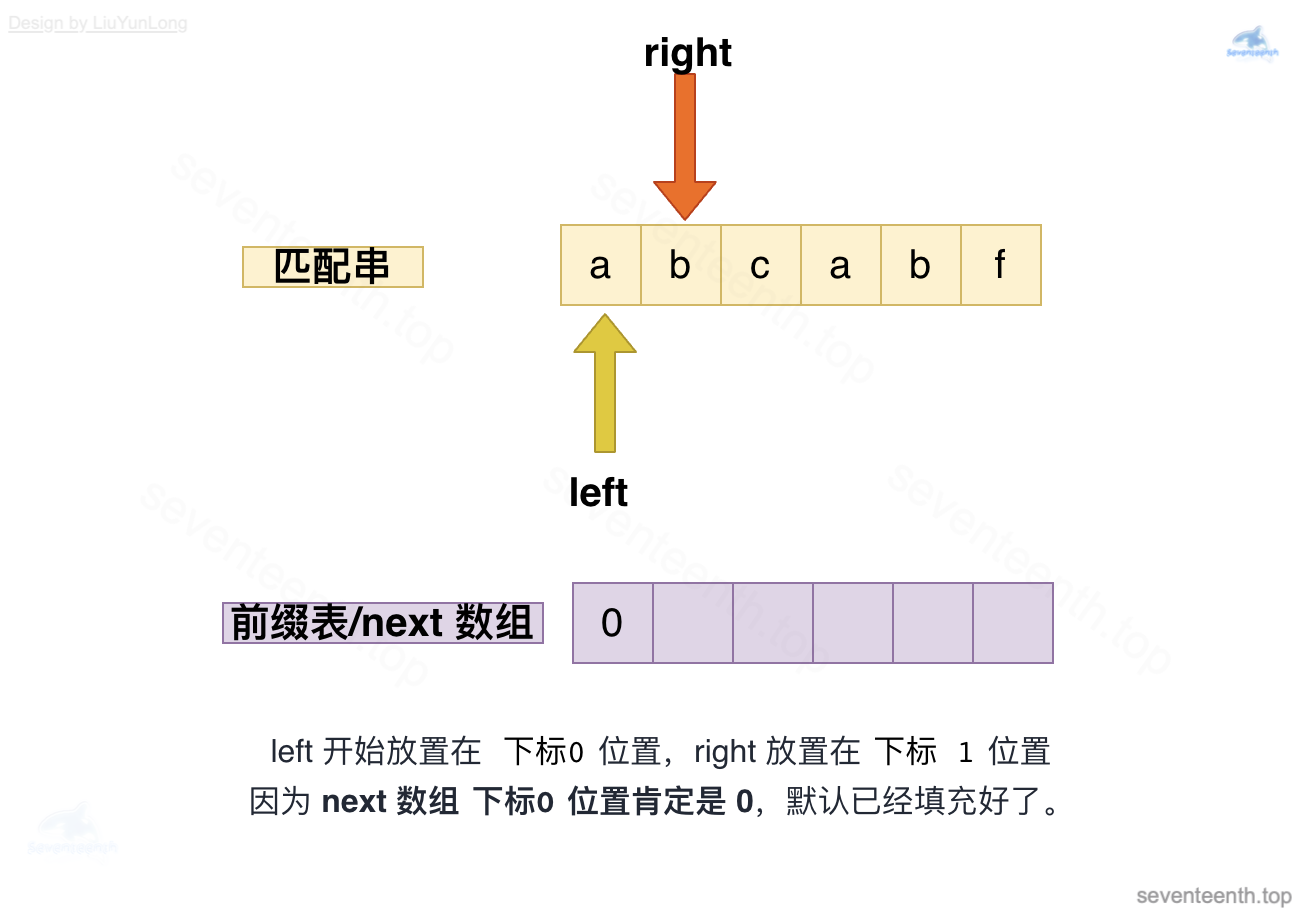
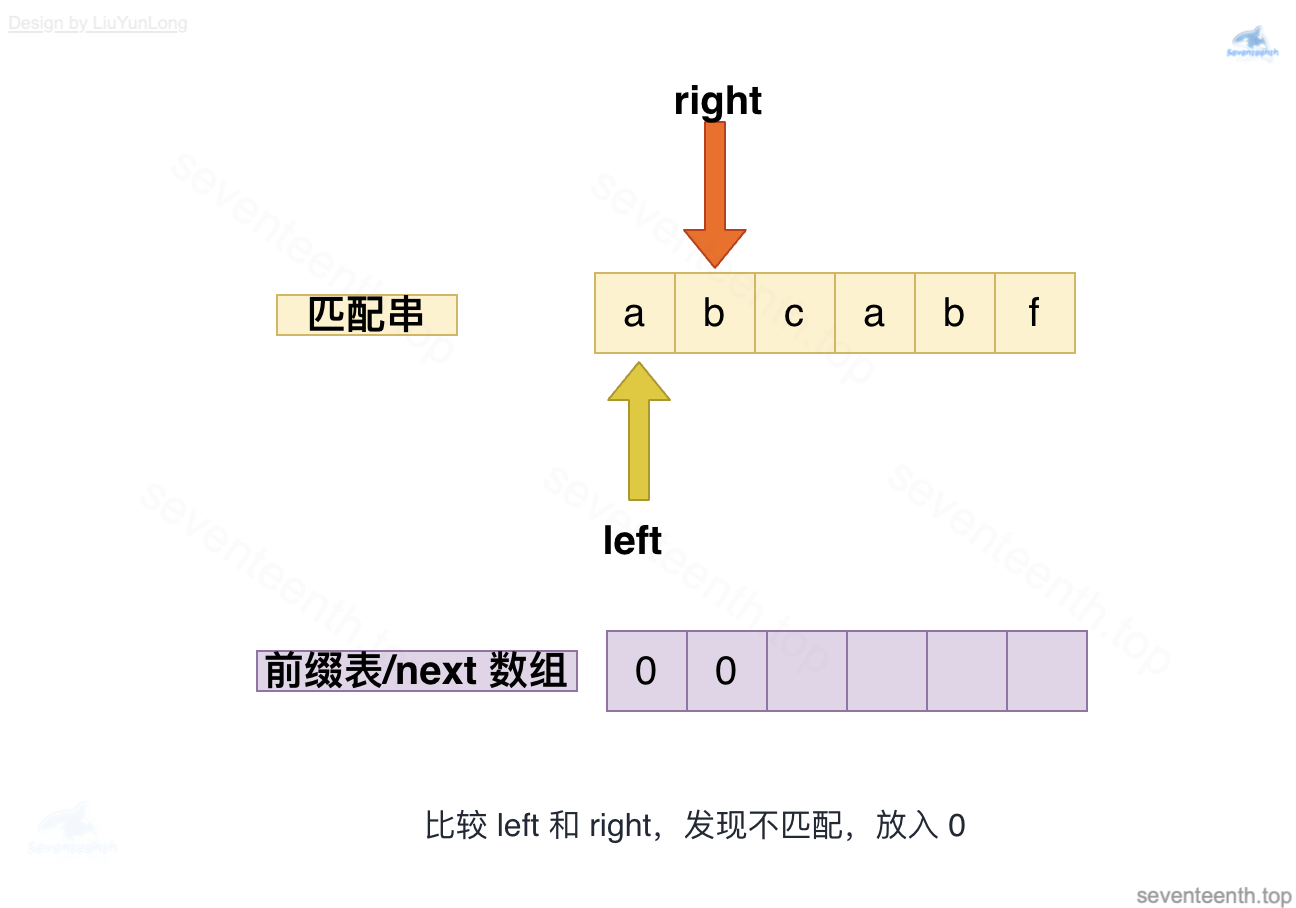
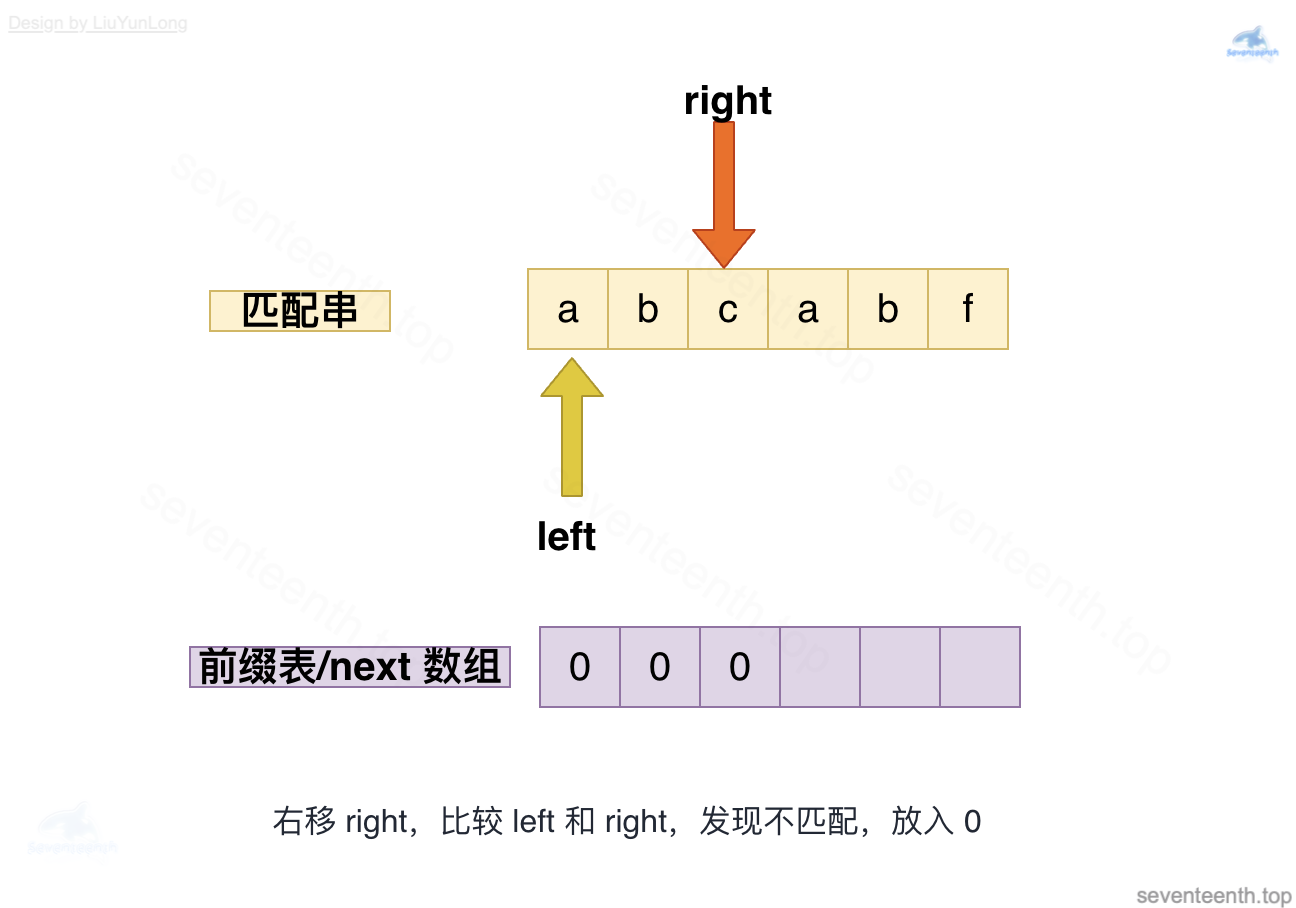
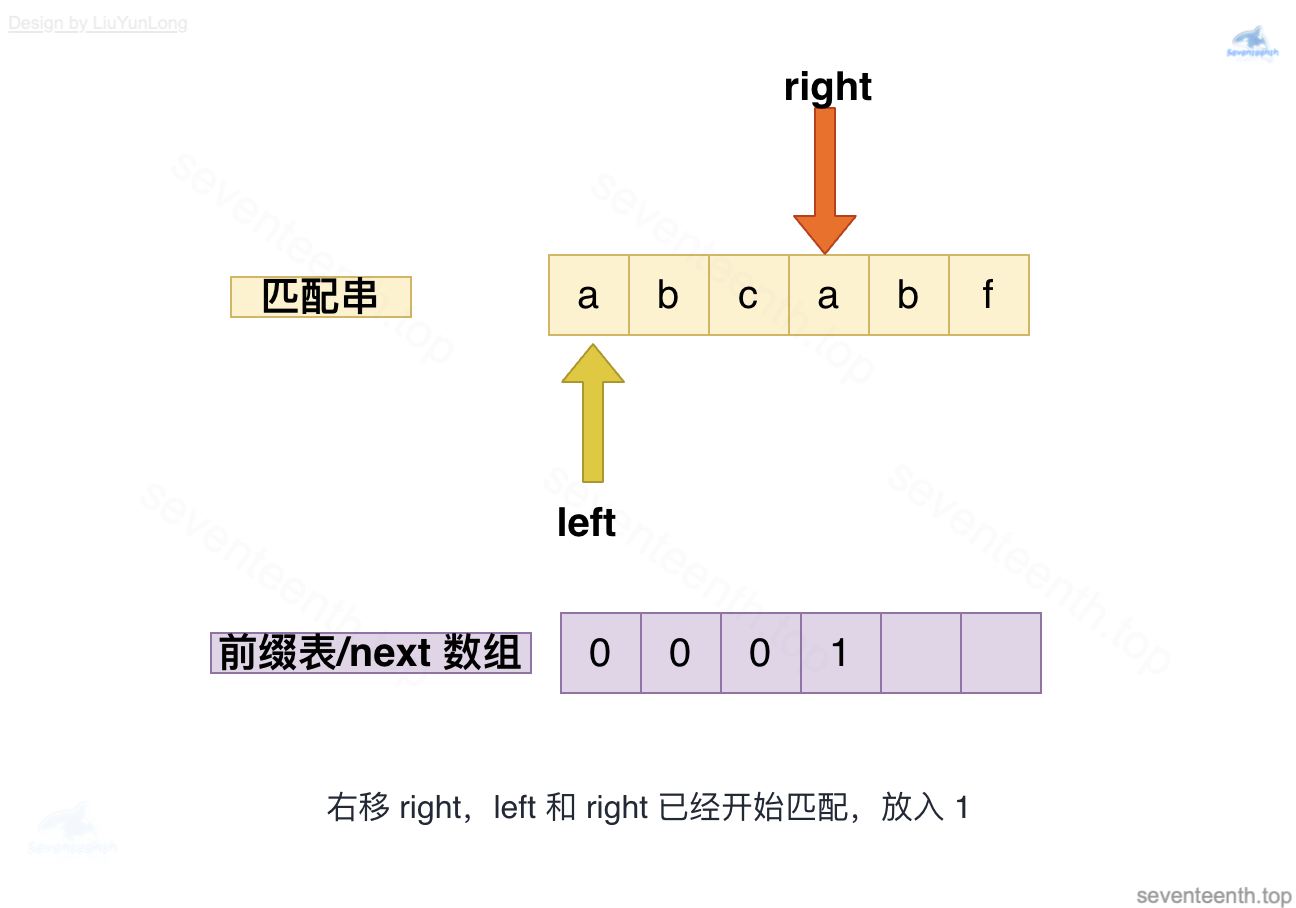
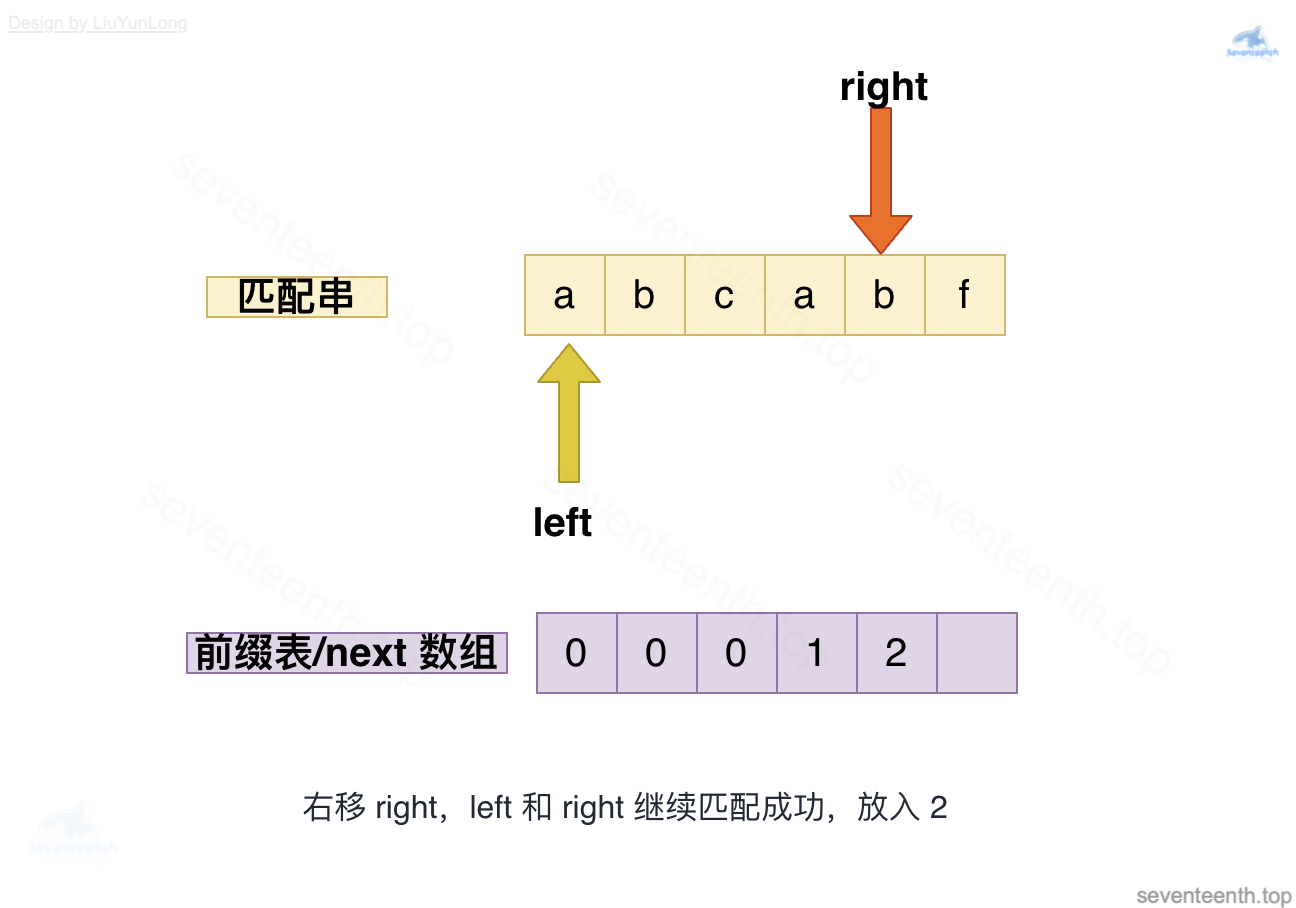
图中有错,此时left应指向b,left与right均指向b,匹配成功,放入2;
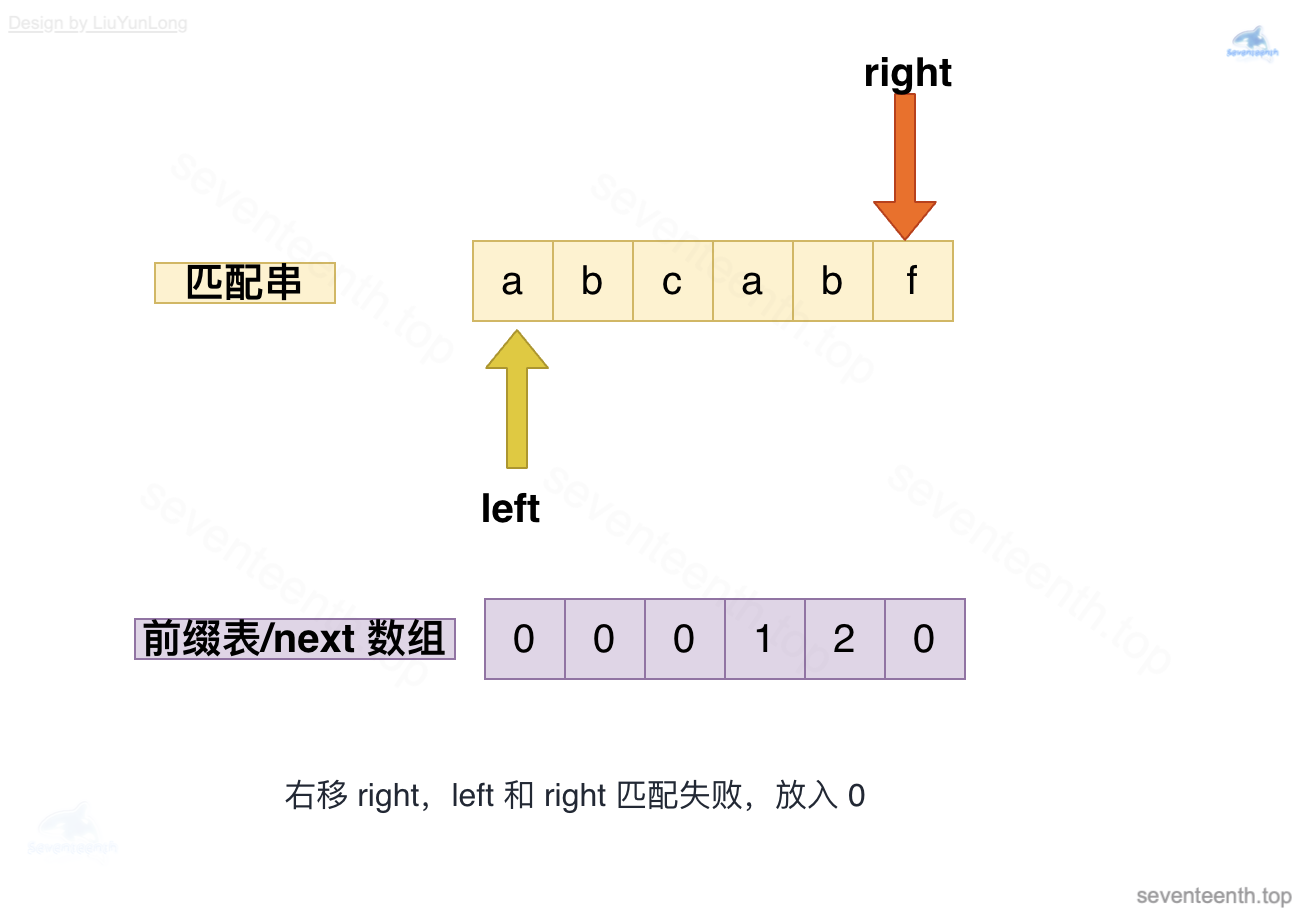
图中有错,此时left应指向c,left与right指向不匹配,回退到上一个left=next[left-1],即left为0,放入0。
问题:为什么回退是left = next[left - 1],为何不直接回退到0?
下图是正在进行 next 数组运算。
可以看到,当 left 指针指到 f,right 指针指到 e的时候,已经出现 f 不等于 e的情况。
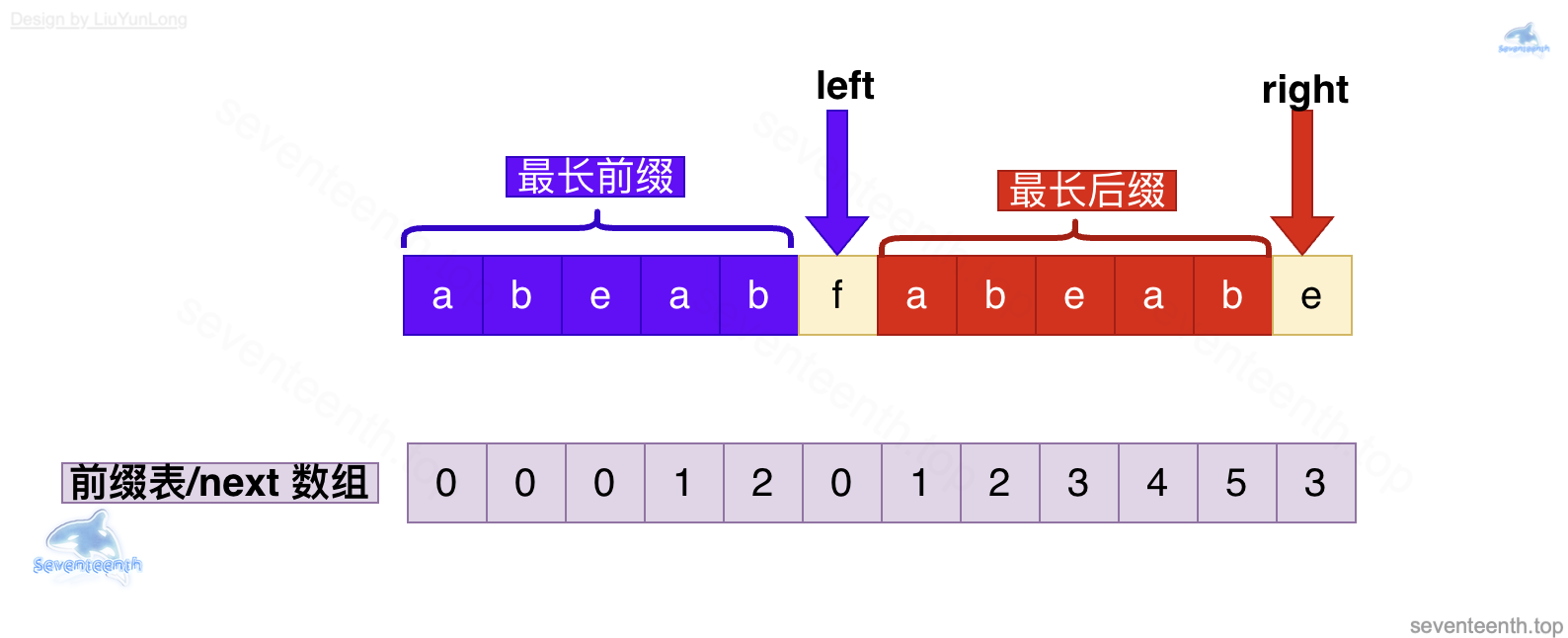
这时候我们的 left 指针应该怎么办呢?
left = next[left - 1];
最长前缀和最长后缀是最长相同前后缀,见图右半部分。
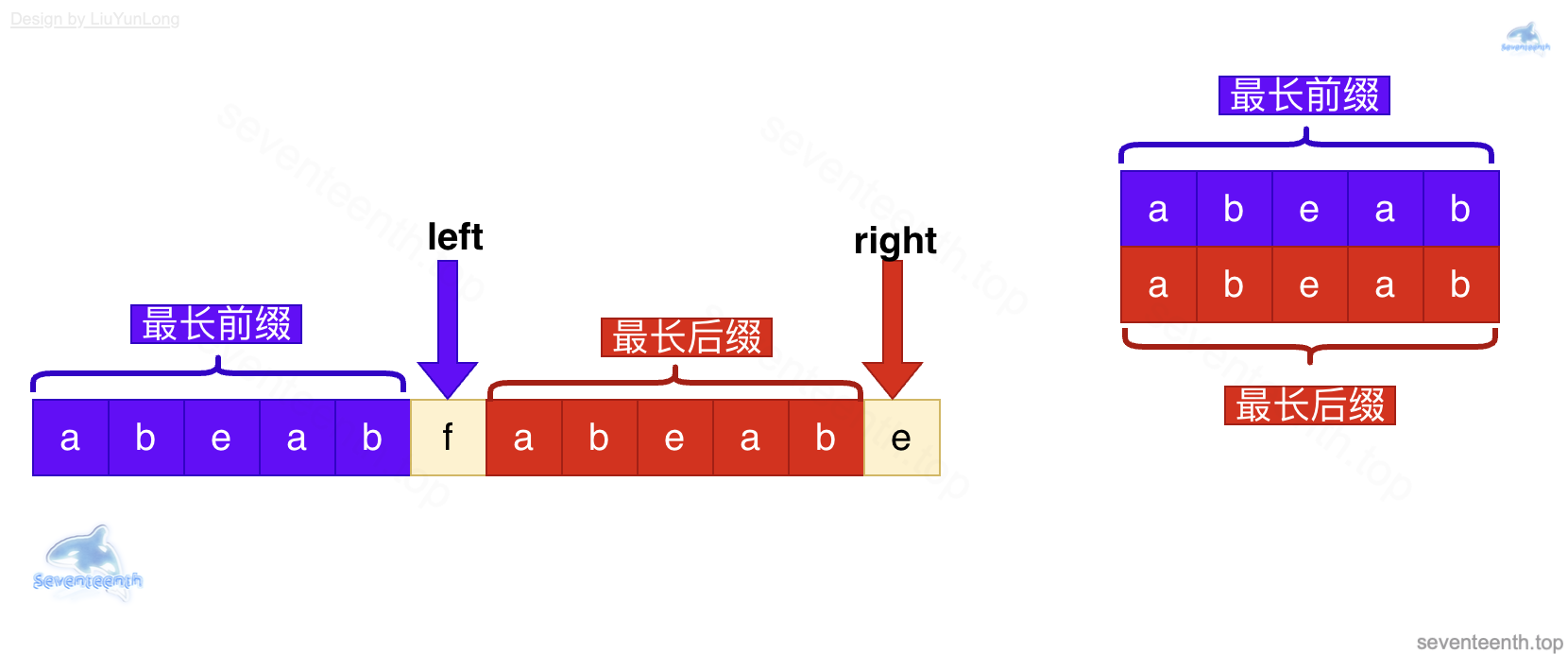
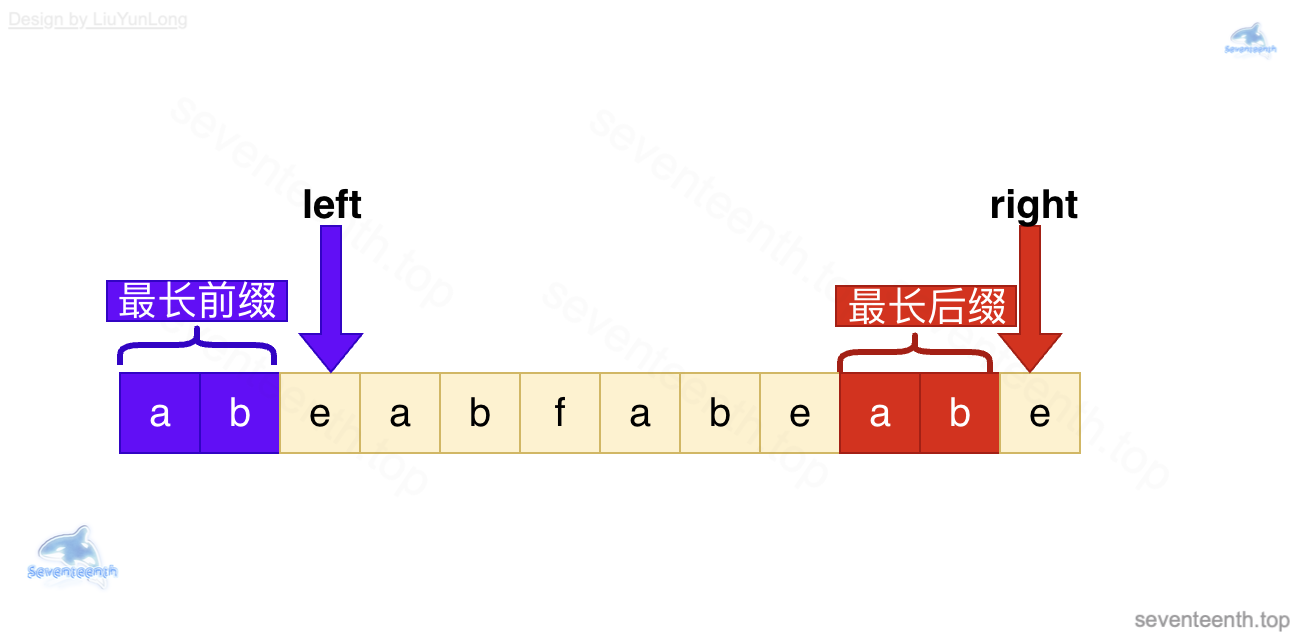
当前 left 指向的下标为 5
这时候,根据left = next[left - 1]的操作
left 指针并不会退回 0 的起点,而是根据最长相同前后缀的特点(下图)
让 left 退到 ab的位置
left = next[left - 1];
left 指针也就根据 next[5-1]所对应的 2 ,移动到了 下标为 2 的 e 的位置上
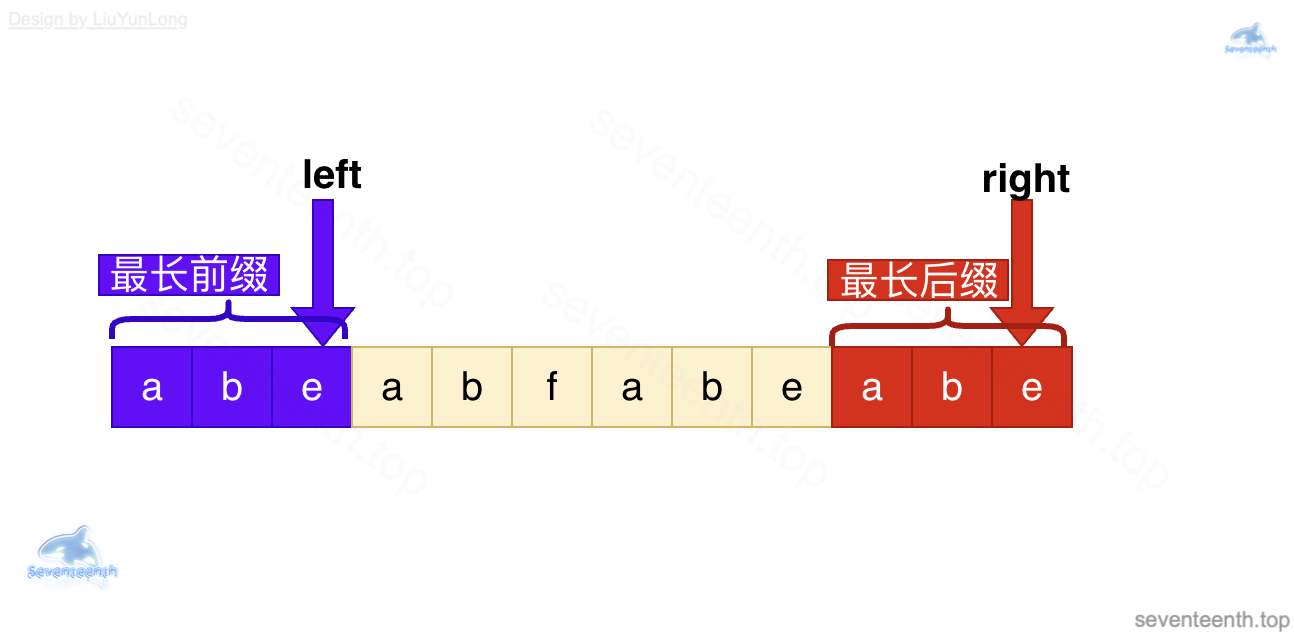
这时候,最长前缀变成 ab,最长后缀因为要和最长前缀保持一致,也缩水成了 ab。
接着将 left 指针指向的 e 和 right 指针指向的 e 进行对比,发现相等。
就更新了当前数组的 next 数组
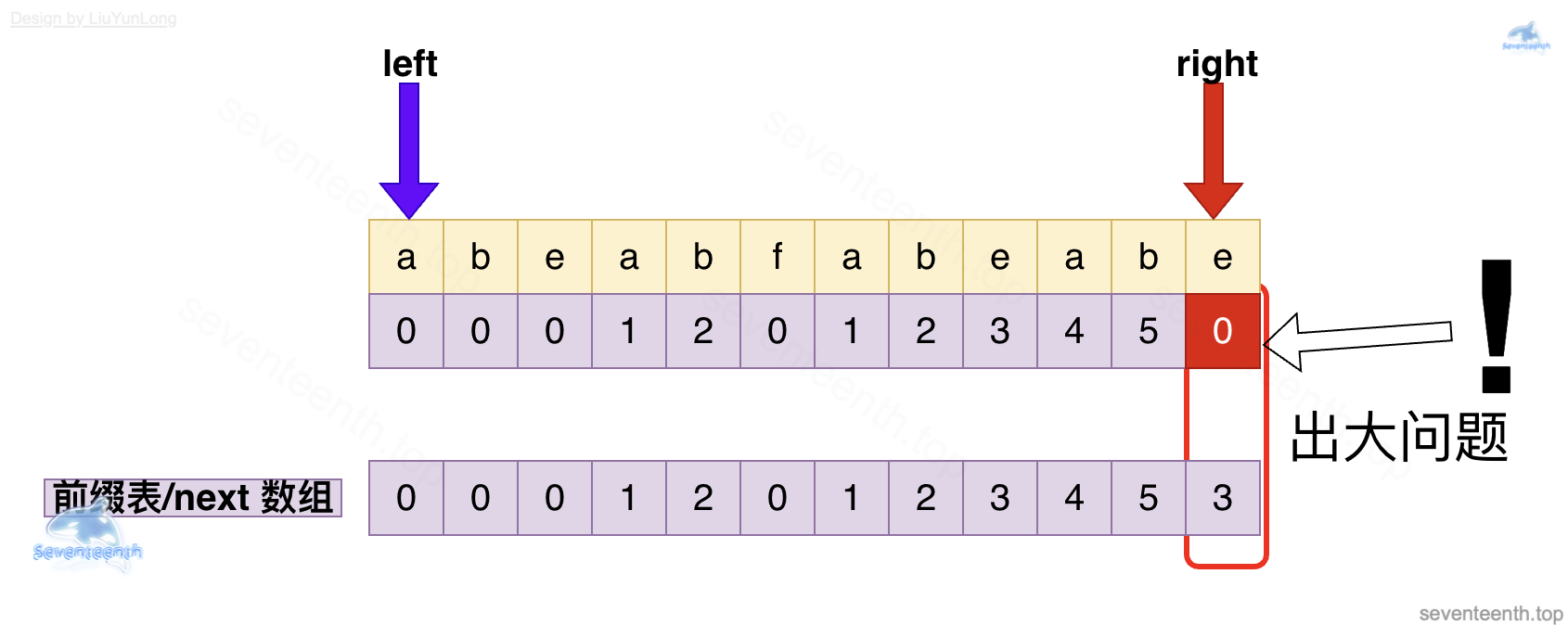
简单粗暴退回 让 left 退回 0 会发生什么?
答案是算法会出现错误

上图中 left 指针已经退回了 下标为 0 的元素,接下来将 left 指针指向的a 和 right 指针指向的 e 进行对比,不相等。
于是出现大问题——最长相同前后缀算错了!!!
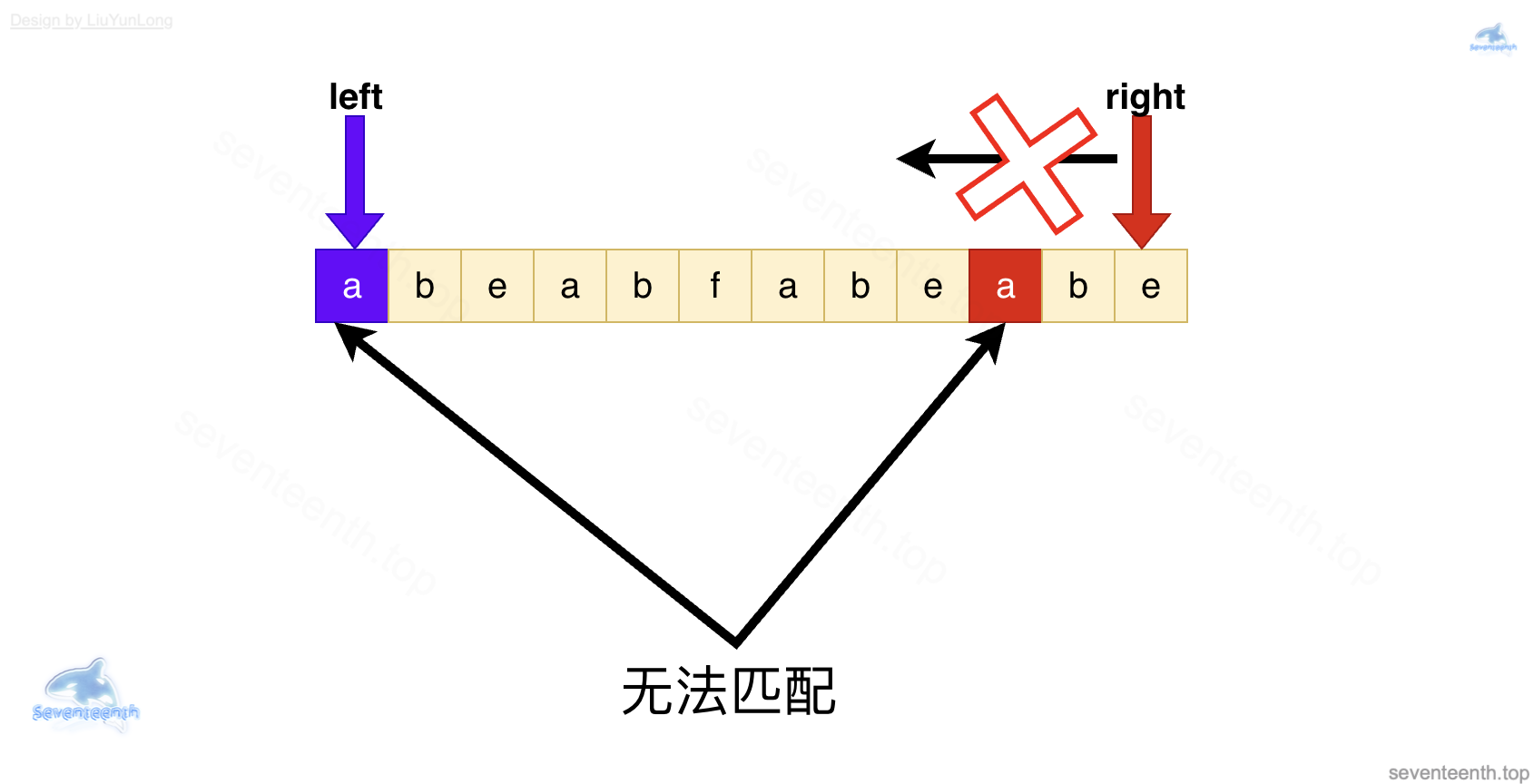
想要补救也根本不可能:
因为 right 指针不能往回走——也就不能让 a和 a匹配了。
总结
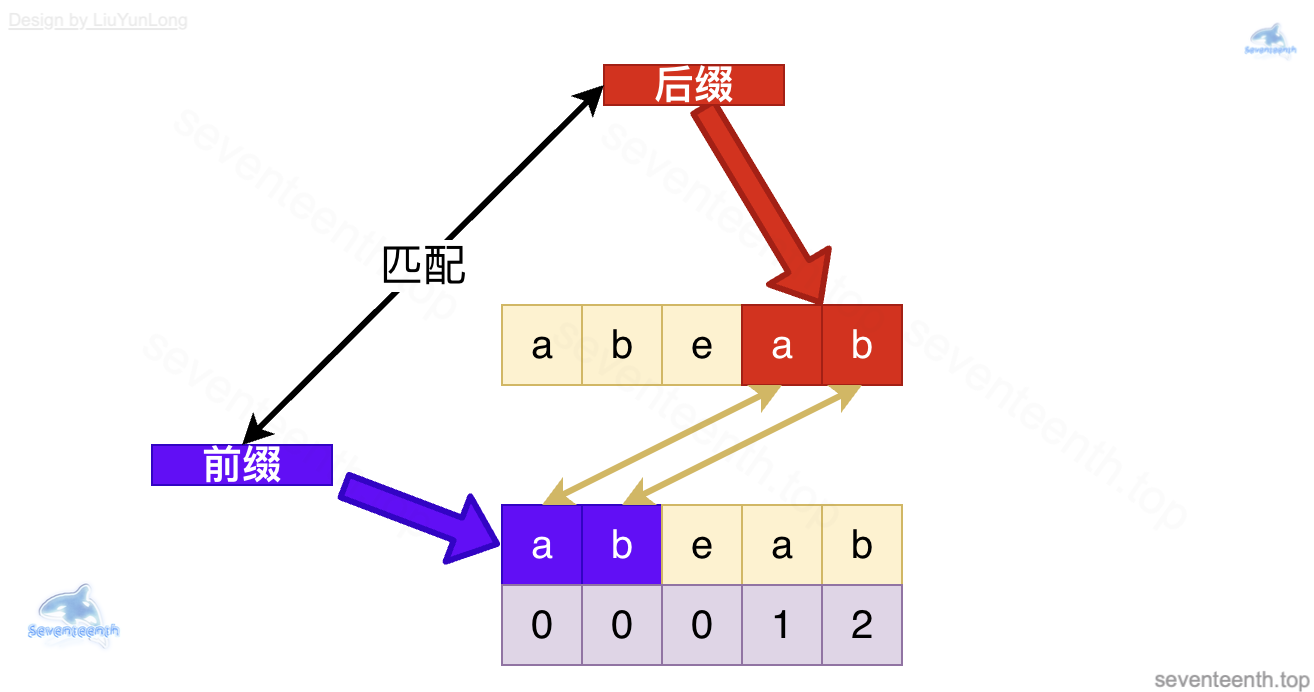
其实说到这里也就会发现,我们为什么能根据next 数组快速查找匹配串?
如何做到下图这样找到已经匹配完成的字母ab,从而直接判断 c与 c,而不是从头再开始比较呢?
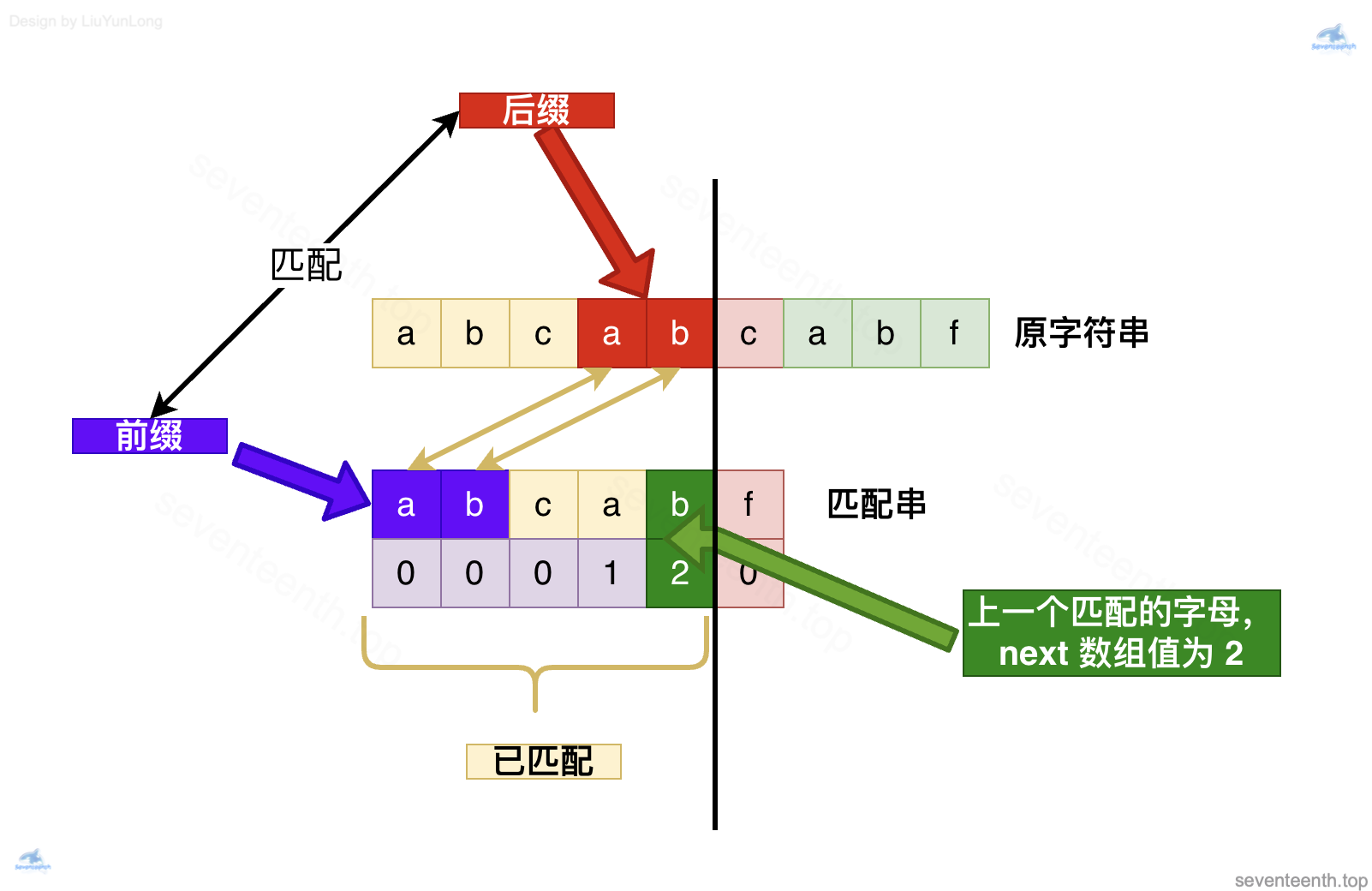
答案就是: next 数组的生成过程就是这样的,用到了同样的原理,为实现查找匹配串奠定了基础。
完整代码:
/** * @param {string} haystack * @param {string} needle * @return {number} */ var strStr = function(haystack, needle) { const haystackLen = haystack.length; const needleLen = needle.length; if(needleLen===0){ return 0; } //生成next数组 let next = Array.from({length:needleLen}).fill(0); for(let left=0,right=1;right<needleLen;right++){ while(left>0&&needle[left]!==needle[right]){ left=next[left-1]; } if(needle[left]===needle[right]){ left++; } next[right]=left; } //匹配原字符串 for(let matchLen=0,haystackIndex=0;haystackIndex<haystackLen;haystackIndex++){ while(matchLen>0&&haystack[haystackIndex]!==needle[matchLen]){ matchLen=next[matchLen-1]; } if(haystack[haystackIndex]===needle[matchLen]){ matchLen++; } if(matchLen===needleLen){ return haystackIndex-matchLen+1; } } return -1; };

