

JavaScript 字符串方法
01、charAt()
charAt() 方法返回字符串中指定索引处的字符。第一个字符的索引为 0,第二个字符为 1,依此类推。
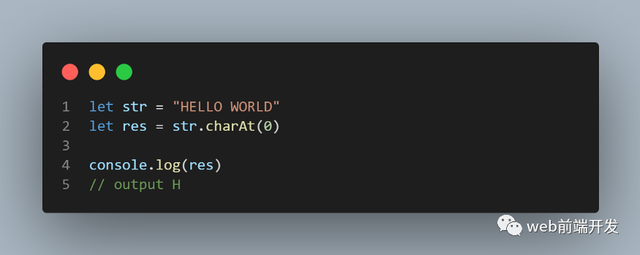
02、charCodeAt()
charCodeAt() 方法返回字符串中指定索引处字符的Unicode。
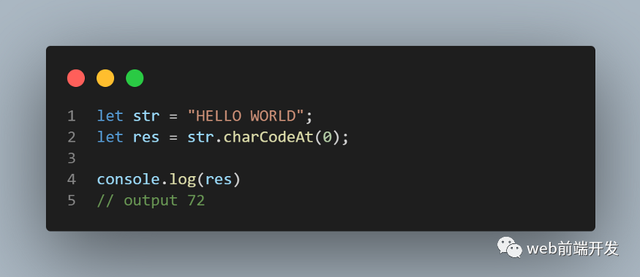
03、concat()
concat() 方法用于连接两个或多个字符串。此方法不会更改现有字符串,而是返回一个包含连接字符串文本的新字符串。

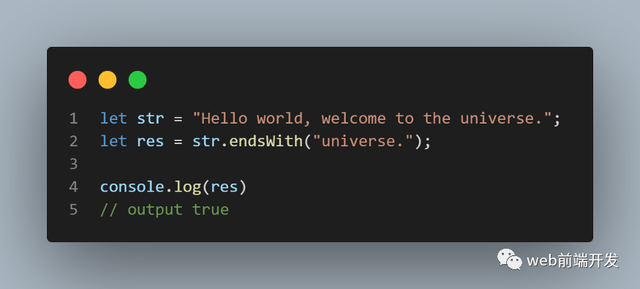
04、endsWith()
EndsWith() 方法确定字符串是否以指定字符串的字符结尾。如果字符串以字符结尾,则此方法返回 true,否则返回 false。
05、fromCharCode()
fromCharCode() 方法将 Unicode 值转换为字符。这是String对象的静态方法,语法始终是String.fromCharCode()。

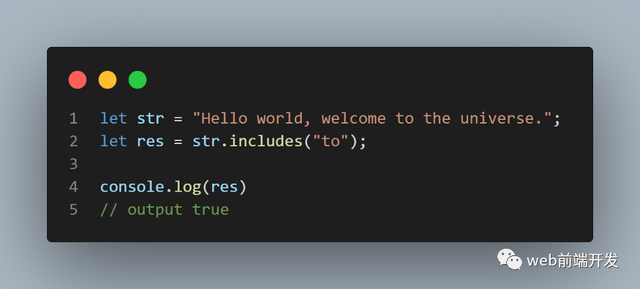
06、include()
include() 方法确定字符串是否包含指定字符串的字符。
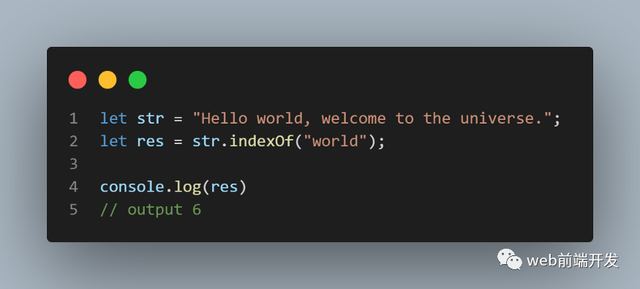
07、indexOf()
indexOf() 方法返回指定值在字符串中第一次出现的位置。如果要搜索的值从未出现,则此方法返回 -1。
08、lastIndexOf()
lastIndexOf() 方法返回指定值在字符串中最后一次出现的位置。从结尾到开头搜索字符串,但返回从开头开始的索引,位置 0。

09、localeCompare()
localeCompare() 方法比较当前语言环境中的两个字符串。区域设置基于浏览器的语言设置。如果 str1 在 str2 之前排序,则返回 -1 ,如果两个字符串相等,则返回 0, 如果 str1 在 str2 之后排序,则返回 1。

10、match()
match() 方法根据正则表达式在字符串中搜索匹配项,并将匹配项作为 Array 对象返回。

matchAll()方法返回一个正则表达式在当前字符串的所有匹配
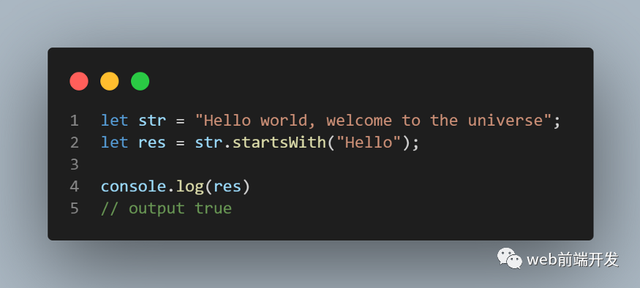
11、startsWith()
startsWith() 方法确定字符串是否以指定字符串的字符开头。
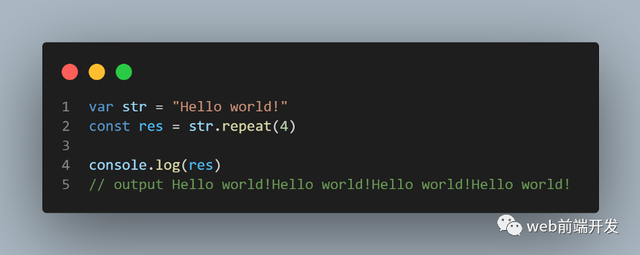
12、repeat()
repeat() 方法返回一个新字符串,其中包含调用它的字符串的指定副本数。
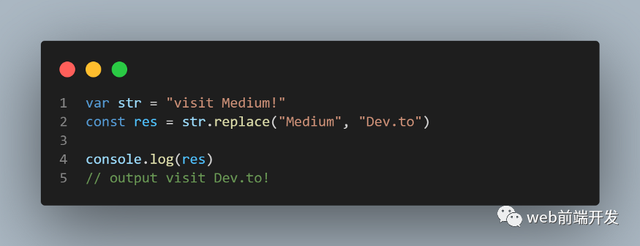
13、replace()
replace() 方法在字符串中搜索指定值或正则表达式,并返回替换指定值的新字符串。
replaceAll()
字符串的实例方法replace()只能替换第一个匹配。ES2021 引入了replaceAll()方法,可以一次性替换所有匹配。
'aabbcc'.replaceAll('b', '_')
// 'aa__cc'
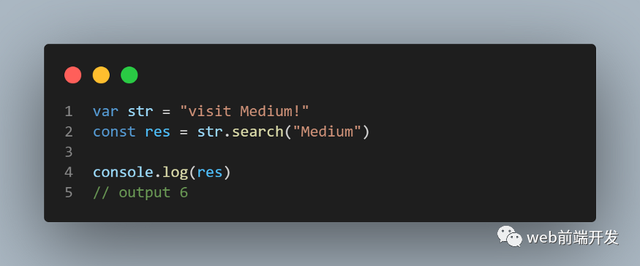
14、search()
search() 方法在字符串中搜索指定值,并返回匹配的位置。
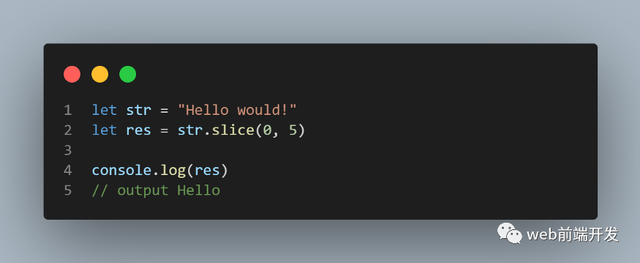
15、slice()
slice() 方法提取字符串的一部分并在新字符串中返回提取的部分。
16、split()
split() 方法用于将字符串拆分为子字符串数组,并返回新数组。

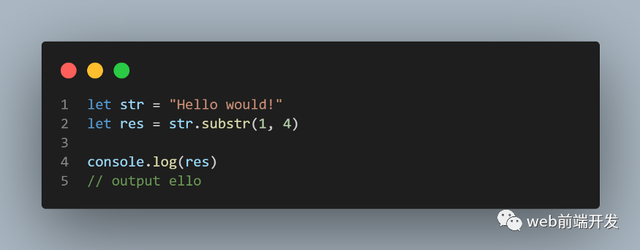
17、substr()
substr() 方法提取字符串的一部分,从指定位置的字符开始,并返回指定数量的字符。
18、substring()
substring() 方法从字符串中提取两个指定索引之间的字符,并返回新的子字符串。

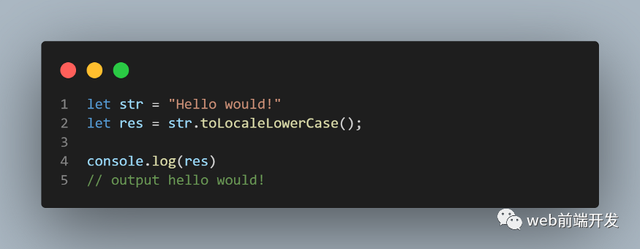
19、toLocaleLowerCase()
toLocaleLowerCase() 方法根据主机的当前语言环境将字符串转换为小写字母。
20、toLocaleUpperCase()
toLocaleUpperCase() 方法根据主机的当前语言环境将字符串转换为大写字母。

21、toLowerCase()
toLowerCase() 方法将字符串转换为小写字母。它不会更改原始字符串。
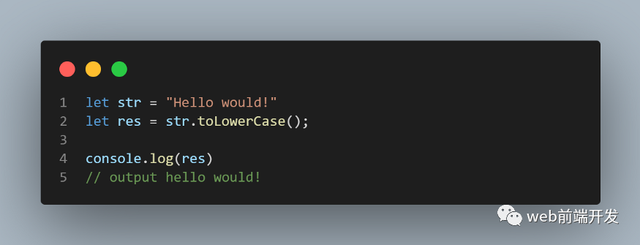
22、toUpperCase()
toUpperCase() 方法将字符串转换为大写字母。它不会更改原始字符串。
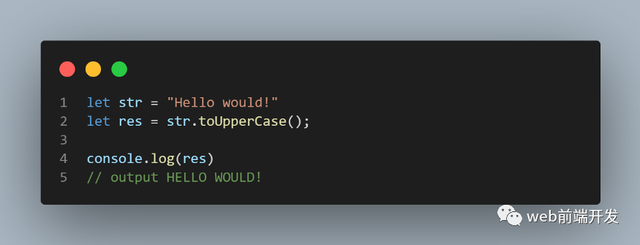
23、trim()
trim() 方法从字符串的两侧删除空格。它不会更改原始字符串。
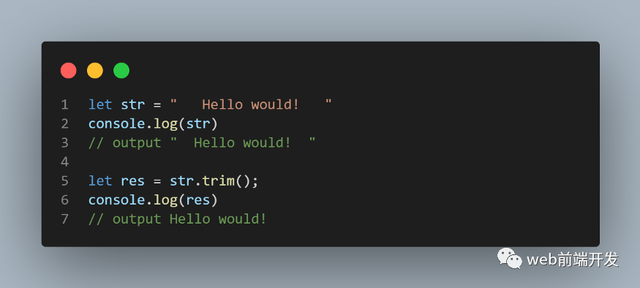
trimStart(),trimEnd()
ES2019 对字符串实例新增了trimStart()和trimEnd()这两个方法。它们的行为与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。它们返回的都是新字符串,不会修改原始字符串。
const s = ' abc '; s.trim() // "abc" s.trimStart() // "abc " s.trimEnd() // " abc"
上面代码中,trimStart()只消除头部的空格,保留尾部的空格。trimEnd()也是类似行为。
除了空格键,这两个方法对字符串头部(或尾部)的 tab 键、换行符等不可见的空白符号也有效。
浏览器还部署了额外的两个方法,trimLeft()是trimStart()的别名,trimRight()是trimEnd()的别名。
24.实例方法:at()
at()方法接受一个整数作为参数,返回参数指定位置的字符,支持负索引(即倒数的位置)。
const str = 'hello'; str.at(1) // "e" str.at(-1) // "o"
如果参数位置超出了字符串范围,at()返回undefined。
该方法来自数组添加的at()方法,目前还是一个第三阶段的提案,可以参考《数组》一章的介绍。
25.实例方法:padStart(),padEnd()
ES2017 引入了字符串补全长度的功能。如果某个字符串不够指定长度,会在头部或尾部补全。padStart()用于头部补全,padEnd()用于尾部补全。
'x'.padStart(5, 'ab') // 'ababx' 'x'.padStart(4, 'ab') // 'abax' 'x'.padEnd(5, 'ab') // 'xabab' 'x'.padEnd(4, 'ab') // 'xaba'
上面代码中,padStart()和padEnd()一共接受两个参数,第一个参数是字符串补全生效的最大长度,第二个参数是用来补全的字符串。
如果原字符串的长度,等于或大于最大长度,则字符串补全不生效,返回原字符串。
'xxx'.padStart(2, 'ab') // 'xxx' 'xxx'.padEnd(2, 'ab') // 'xxx'
如果用来补全的字符串与原字符串,两者的长度之和超过了最大长度,则会截去超出位数的补全字符串。
'abc'.padStart(10, '0123456789') // '0123456abc'
如果省略第二个参数,默认使用空格补全长度。
'x'.padStart(4) // ' x' 'x'.padEnd(4) // 'x '
padStart()的常见用途是为数值补全指定位数。下面代码生成 10 位的数值字符串。
'1'.padStart(10, '0') // "0000000001" '12'.padStart(10, '0') // "0000000012" '123456'.padStart(10, '0') // "0000123456"
另一个用途是提示字符串格式。
'12'.padStart(10, 'YYYY-MM-DD') // "YYYY-MM-12" '09-12'.padStart(10, 'YYYY-MM-DD') // "YYYY-09-12"26.实例方法:trimStart(),trimEnd()
26.实例方法:normalize()
许多欧洲语言有语调符号和重音符号。为了表示它们,Unicode 提供了两种方法。一种是直接提供带重音符号的字符,比如Ǒ(\u01D1)。另一种是提供合成符号(combining character),即原字符与重音符号的合成,两个字符合成一个字符,比如O(\u004F)和ˇ(\u030C)合成Ǒ(\u004F\u030C)。
这两种表示方法,在视觉和语义上都等价,但是 JavaScript 不能识别。
'\u01D1'==='\u004F\u030C' //false '\u01D1'.length // 1 '\u004F\u030C'.length // 2
上面代码表示,JavaScript 将合成字符视为两个字符,导致两种表示方法不相等。
ES6 提供字符串实例的normalize()方法,用来将字符的不同表示方法统一为同样的形式,这称为 Unicode 正规化。
'\u01D1'.normalize() === '\u004F\u030C'.normalize() // true
normalize方法可以接受一个参数来指定normalize的方式,参数的四个可选值如下。
NFC,默认参数,表示“标准等价合成”(Normalization Form Canonical Composition),返回多个简单字符的合成字符。所谓“标准等价”指的是视觉和语义上的等价。NFD,表示“标准等价分解”(Normalization Form Canonical Decomposition),即在标准等价的前提下,返回合成字符分解的多个简单字符。NFKC,表示“兼容等价合成”(Normalization Form Compatibility Composition),返回合成字符。所谓“兼容等价”指的是语义上存在等价,但视觉上不等价,比如“囍”和“喜喜”。(这只是用来举例,normalize方法不能识别中文。)NFKD,表示“兼容等价分解”(Normalization Form Compatibility Decomposition),即在兼容等价的前提下,返回合成字符分解的多个简单字符。
'\u004F\u030C'.normalize('NFC').length // 1
'\u004F\u030C'.normalize('NFD').length // 2
上面代码表示,NFC参数返回字符的合成形式,NFD参数返回字符的分解形式。
不过,normalize方法目前不能识别三个或三个以上字符的合成。这种情况下,还是只能使用正则表达式,通过 Unicode 编号区间判断。
27.String.fromCodePoint()
ES5 提供String.fromCharCode()方法,用于从 Unicode 码点返回对应字符,但是这个方法不能识别码点大于0xFFFF的字符。
String.fromCharCode(0x20BB7) // "ஷ"
上面代码中,String.fromCharCode()不能识别大于0xFFFF的码点,所以0x20BB7就发生了溢出,最高位2被舍弃了,最后返回码点U+0BB7对应的字符,而不是码点U+20BB7对应的字符。
ES6 提供了String.fromCodePoint()方法,可以识别大于0xFFFF的字符,弥补了String.fromCharCode()方法的不足。在作用上,正好与下面的codePointAt()方法相反。
String.fromCodePoint(0x20BB7) // "𠮷" String.fromCodePoint(0x78, 0x1f680, 0x79) === 'x\uD83D\uDE80y' // true
上面代码中,如果String.fromCodePoint方法有多个参数,则它们会被合并成一个字符串返回。
注意,fromCodePoint方法定义在String对象上,而codePointAt方法定义在字符串的实例对象上。
28.String.raw()
ES6 还为原生的 String 对象,提供了一个raw()方法。该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法。
String.raw`Hi\n${2+3}!`
// 实际返回 "Hi\\n5!",显示的是转义后的结果 "Hi\n5!"
String.raw`Hi\u000A!`;
// 实际返回 "Hi\\u000A!",显示的是转义后的结果 "Hi\u000A!"
如果原字符串的斜杠已经转义,那么String.raw()会进行再次转义。
String.raw`Hi\\n` // 返回 "Hi\\\\n" String.raw`Hi\\n` === "Hi\\\\n" // true
String.raw()方法可以作为处理模板字符串的基本方法,它会将所有变量替换,而且对斜杠进行转义,方便下一步作为字符串来使用。
String.raw()本质上是一个正常的函数,只是专用于模板字符串的标签函数。如果写成正常函数的形式,它的第一个参数,应该是一个具有raw属性的对象,且raw属性的值应该是一个数组,对应模板字符串解析后的值。
// `foo${1 + 2}bar` // 等同于 String.raw({ raw: ['foo', 'bar'] }, 1 + 2) // "foo3bar"
参照:
https://es6.ruanyifeng.com/#docs/string-methods#String-fromCodePoint
https://baijiahao.baidu.com/s?id=1710433412934742935&wfr=spider&for=pc


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界
2021-02-05 VUE中使用lodash的debounce和throttle方法
2021-02-05 html中如何移除video下载按钮
2021-02-05 【Vuex】在vue组件中访问vuex模块中的getters/action/state