
前端存储 --- cookie & localStorage & sessionStorage & Web SQL & IndexDB & Cache Storage
应用缓存:是项目本身的缓存,比如一个js对象缓存的数据,或者状态管理机制如vuex和redux等进行应用数据存储,它们在页面刷新就会丢失。
离线缓存:应用在离线情况下也能快速访问的缓存资源,这里主要讲serviceWorker,大多数浏览器已经支持serviceWorker提供离线缓存。
本地缓存:cookie大小一般限制在4kb以下,而且cookie会随请求发送到后端,所以一般只将用户登录态或者权限验证放在cookie中,避免影响请求传输效率;localStorage和sessionStorage的大小一般均是在5mb以下,sessionStorage的生命周期是维持到页面窗口关闭,而localStorage存储在浏览器缓存中直到代码删除或者手动清除浏览器缓存,它们都不能跨域访问。
亲测手动清除浏览器缓存可以清除localStorage、sessionStorage和cookie。
localStorage是通过浏览器存储到本机机器上的磁盘中,生成.localstorage文件但其实是sqlit数据库文件。域内安全、永久保存,没有时间限制,即客户端或浏览器中来自同一域名的所有页面都可访问localStorage数据且数据除了删除否则永久保存,但浏览器之间的数据事相互独立的;
sessionStorage不是用来存储在客户端,而是存储在整个会话当中,即浏览器访问服务器这个过程,关闭当前浏览器窗口或停止服务器即断开会话,存储的数据会被删除。
一、localStorage和sessionStorage
localStorage和sessionStorage都具有相同的操作方法:setItem、getItem、removeItem、clear。
setItem 存储 value
.setItem( key, value) 将value存储到key字段。
localStorage.setItem("job", "basketballplayer");
setItem 存储 json对象
localStorage 和 sessionStorage也可存储Json对象,存储时,通过JSON.stringify()将对象转换为文本格式;读取时,通过JSON.parse()将文本转换回对象。
var user = { name:"james", job:"basketballplayer" } // 存储值:将对象转换为Json字符串 localStorage.setItem('user', JSON.stringify(user)); // 取值时:把获取到的Json字符串转换回对象 var userJsonStr = localStorage.getItem('user'); var userEntity = JSON.parse(userJsonStr); console.log(userEntity.name); // => james
getItem获取value
.getItem(key) 获取指定key本地存储的值。
localStorage.getItem("job");
removeItem删除key
.removeItem(key)删除指定key本地存储的值。
localStorage.removeItem("job");
clear清除所有的key/value
.clear() 清除所有的key/value
localStorage.clear();
二、Cookie(存储4k)
Cookie实际上是一个很小的文本文件,网站通过向用户硬盘中写入一个Cookie文件来标识用户。当用户下次再访问该网站时,浏览器会将Cookie信息发送给网站服务器,服务器通过读取以前写入的Cookie文件中的信息,就能识别该用户。
Cookie的两种形式:
(1)会话Cookie。临时性的,只在浏览器打开时存在,主要用来实现Session技术。
(2)永久Cookie。永久性的,保存在用户硬盘上并在有效期内一直可用。
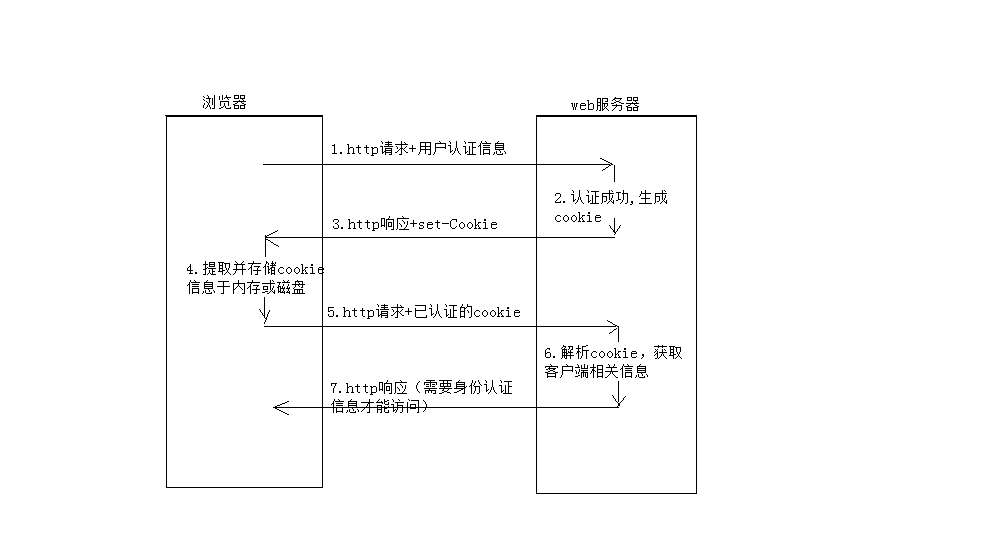
Set-Cookie: lu=Rg3vHJZnehYLjVg7qi3bZjzg; Expires=Tue, 15 Jan 2013 21:47:38 GMT; Path=/; Domain=.169it.com; HttpOnly
值得注意的是,从客户端读取Cookie时,包括maxAge在内的其他属性都是不可读的,也不会被提交。浏览器提交Cookie时只会提交name和value属性:
GET /spec.html HTTP/1.1 Host: www.example.org Cookie: name=value; name2=value2 Accept: */*
maxAge属性只被浏览器用来判断Cookie是否过期。当cookie过期时,浏览器在与后台交互时会自动筛选过期cookie,过期了的cookie就不会被携带了。
除了服务器发送给客户端(浏览器)的时候,通过Set-Cookie,浏览器自动创建或更新对应的cookie之外,还可以通过浏览器内置的一些脚本,比如javascript,去设置对应的cookie,对应实现是操作js中的document.cookie:
// 设置cookie document.cookie = "username=Bill Gates; expires=Sun, 31 Dec 2017 12:00:00 UTC; path=/"; // 读取cookie // document.cookie 会在一条字符串中返回所有 cookie,比如:'cookie1=value; cookie2=value; cookie3=value;' var x = document.cookie;
Cookie中的Path与domain
浏览器会将domain和path都相同的cookie保存在一个文件里
跨域问题
所谓浏览器的同源策略是指,协议,域名,端口相同。当一个浏览器的两个tab页中分别打开百度和谷歌的页面。浏览器的百度tab页执行脚本的时候会检查这个脚本是属于哪个页面的,即检查是否和当前页面地址同源,只有和百度同源的脚本才会被执行。 如果非同源,那么在请求数据时,浏览器会在控制台中报一个异常,提示拒绝访问。
浏览器是以HTTP请求模式获取请求资源,如:Http://www.baidu.com:8080/xxxx。其中HTTP是请求协议,www.baidu.com是域名,8080是端口号,请求的意思是使用HTTP协议模式,从域名为www.baidu.com的服务器上8080端口部署的服务下请求资源XXXX。
即当浏览器打开的tab满足同源策略后,可以在各个文件之间进行数据的相互存取操作,这样就可以不用反复进行重复的数据请求操作,如登录权限,获取用户信息等等。
localStorage和cookie不能跨域读取的(包括子域)
localStorage和cookie需要跨域的业务场景
www.baidu域名下面登录了,发现yun.baidu域名下面也自然而然登录了;淘宝登录了,发现天猫也登录了,淘宝和天猫是完全不一样的2个域名。
localStorage的跨域解决方案
如果两个页面的主域名相同,将document.domain属性值设置为根域名:
document.domain = 'a.com';
域名完全不相同的话,可以用postMessage和iframe相结合的方法。postMessage(data,origin)方法允许来自不同源的脚本采用异步方式进行通信:
data:要传递的数据,H5规范中提到该参数可以是Javascript的任意基本类型或可复制的对象,然而并不是所有浏览器支持任意类型的参数,部分浏览器只能处理字符串参数,所以在传递参数时需要使用JSON.stringify()方法对对象参数序列化。
origin:字符串类型的参数,指明目标窗口的源,协议+主机+端口号[+URL],URL会被忽略,所以可以不写。只是为了安全考虑,postMessage()方法只会将message传递给指定窗口,当然也可以将参数设置为"*",这样可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
a.com下页面通过iframe插入了b.com下的一个页面,a.com下页面代码如下,以下代码可以向b.com域下的页面发送数据:
var iframeWin = document.getElementsByTagName('iframe')[0].contentWindow; var obj = { name: 'a' }; iframeWin.postMessage(JSON.stringify({ key: "localstorage", data: obj }), "http://b.com");
b.com下页面代码如下,以下代码可以接收http://a.com域下页面发送的数据:
window.onmessage = function(event) { if (event.origin !== 'http://b.com') { return; } var payload = JSON.parse(event.data); localStorage.setItem(payload.key, JSON.stringify(payload.data)); };
cookie的跨域解决方案
cookie 一般都是由于用户访问页面而被创建的,可是并不是只有在创建 cookie 的页面才可以访问这个cookie。在默认情况下,出于安全方面的考虑,只有与创建 cookie 的页面处于同一个目录或在创建cookie页面的子目录下的网页才可以访问。那么此时如果希望其父级或者整个网页都能够使用cookie,就需要进行path(路径)的设置。
path表示cookie所在的目录, 如:
cookie1的path为/tag/;
cookie2的path为/tag/id/;
那么tag下的所有页面都可以访问到cookie1,而只有/tag/id/下的子页面能访问cookie2。 这是因为cookie2能让其path路径下的页面访问。
使用domain
domain表示的是cookie所在的域,默认是页面的地址,如网址为 http://www.haorooms.com/post/long_lianjie_websocket ,那么domain默认为www.haorooms.com。
如域A为love.haorooms.com,域B为resource.haorooms.com,那么在域A生产一个令域A和域B都能访问的cookie就要将该cookie的domain设置为.haorooms.com;
使用jsonp
使用nginx反向代理
三、Web SQL(可以在最新版的 Safari, Chrome 和 Opera 浏览器中工作)
Web SQL 是在浏览器上模拟数据库,可以使用JS来操作SQL完成对数据的读写。Web SQL 数据库 API 并不是 HTML5 规范的一部分,但是它是一个独立的规范。它类似于关系型数据库。
以下是它的三个核心方法:
openDatabase:这个方法使用现有的数据库或者新建的数据库创建一个数据库对象。
transaction:这个方法让我们能够控制一个事务,以及基于这种情况执行提交或者回滚。
executeSql:这个方法用于执行实际的 SQL 查询。
我们可以使用 openDatabase() 方法来打开已存在的数据库,如果数据库不存在,则会创建一个新的数据库,使用代码如下:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024); // 参数 // 数据库名称 // 版本号 // 描述文本 // 数据库大小 // 创建回调,会在创建数据库后被调用
在执行上面的创建表语句后,插入一些数据:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024); db.transaction(function (tx) { tx.executeSql('CREATE TABLE IF NOT EXISTS LOGS (id unique, log)'); tx.executeSql('INSERT INTO LOGS (id, log) VALUES (1, "W3Cschool教程")'); tx.executeSql('INSERT INTO LOGS (id, log) VALUES (2, "www.w3cschool.cn")'); });
读取数据库中已经存在的数据:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024); db.transaction(function (tx) { tx.executeSql('CREATE TABLE IF NOT EXISTS LOGS (id unique, log)'); tx.executeSql('INSERT INTO LOGS (id, log) VALUES (1, "W3Cschool教程")'); tx.executeSql('INSERT INTO LOGS (id, log) VALUES (2, "www.w3cschool.cn")'); }); db.transaction(function (tx) { tx.executeSql('SELECT * FROM LOGS', [], function (tx, results) { var len = results.rows.length, i; msg = " 查询记录条数: " + len + " "; document.querySelector('#status').innerHTML += msg; for (i = 0; i < len; i++){ alert(results.rows.item(i).log ); } }, null); });
完整实例:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024); var msg; db.transaction(function (tx) { tx.executeSql('CREATE TABLE IF NOT EXISTS LOGS (id unique, log)'); tx.executeSql('INSERT INTO LOGS (id, log) VALUES (1, "菜鸟教程")'); tx.executeSql('INSERT INTO LOGS (id, log) VALUES (2, "www.runoob.com")'); msg = '<p>数据表已创建,且插入了两条数据。</p>'; document.querySelector('#status').innerHTML = msg; }); db.transaction(function (tx) { tx.executeSql('SELECT * FROM LOGS', [], function (tx, results) { var len = results.rows.length, i; msg = "<p>查询记录条数: " + len + "</p>"; document.querySelector('#status').innerHTML += msg; for (i = 0; i < len; i++){ msg = "<p><b>" + results.rows.item(i).log + "</b></p>"; document.querySelector('#status').innerHTML += msg; } }, null); });
四、IndexDB
IndexedDB是浏览器提供的本地数据库, 允许储存大量数据,提供查找接口,还能建立索引。这些都是 LocalStorage 所不具备的。就数据库类型而言,IndexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库。
要想清理indexDB(浏览器数据库),无需代码,只要找到indexDB(浏览器数据库)在本机的存储位置,然后删除文件夹就可以了。
indexDB(浏览器数据库)本机(windows版本)存储文件夹在:C:\Users\ '当前的登录用户'\AppData\Local\Google\Chrome\User Data\Default\IndexedDB
IndexedDB 具有以下特点:
(1)键值对储存。 IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
(2)异步。 IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
(3)支持事务。 IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
(4)同源限制 IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
(5)储存空间大 IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
(6)支持二进制储存。 IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
IndexedDB包括以下对象:
数据库:IDBDatabase 对象
对象仓库:IDBObjectStore 对象
索引: IDBIndex 对象
事务: IDBTransaction 对象
操作请求:IDBRequest 对象
指针: IDBCursor 对象
主键集合:IDBKeyRange 对象
数据库:IndexedDB 数据库有版本的概念。同一个时刻,只能有一个版本的数据库存在。如果要修改数据库结构(新增或删除表、索引或者主键),只能通过升级数据库版本完成。
对象仓库:每个数据库包含若干个对象仓库(object store)。它类似于关系型数据库的表格。
数据记录:对象仓库保存的是数据记录。每条记录类似于关系型数据库的行,但是只有主键和数据体两部分。主键用来建立默认的索引,必须是不同的,否则会报错。主键可以是数据记录里面的一个属性,也可以指定为一个递增的整数编号。
索引:为了加速数据的检索,可以在对象仓库里面,为不同的属性建立索引。
事务:数据记录的读写和删改,都要通过事务完成。事务对象提供error、abort和complete三个事件,用来监听操作结果。
操作流程:
打开数据库:
var request = window.indexedDB.open(databaseName, version);
这个方法接受两个参数,第一个参数是字符串,表示数据库的名字。如果指定的数据库不存在,就会新建数据库。第二个参数是整数,表示数据库的版本。如果省略,打开已有数据库时,默认为当前版本;新建数据库时,默认为1。indexedDB.open()方法返回一个 IDBRequest 对象。这个对象通过三种事件error、success、upgradeneeded,处理打开数据库的操作结果。
error事件表示打开数据库失败:
request.onerror = function (event) { console.log('数据库打开报错'); };
success事件表示成功打开数据库:
var db; request.onsuccess = function (event) { db = request.result; // 通过request.result属性拿到数据库对象。 console.log('数据库打开成功'); };
如果指定的版本号,大于数据库的实际版本号,就会发生数据库升级事件upgradeneeded:
var db; request.onupgradeneeded = function (event) { db = event.target.result; // 通过target.result属性,拿到数据库实例。 }
新建数据库
新建数据库与打开数据库是同一个操作。如果指定的数据库不存在,就会新建。不同之处在于,后续的操作主要在upgradeneeded事件的监听函数里面完成,因为这时版本从无到有,所以会触发这个事件。通常,新建数据库以后,第一件事是新建对象仓库(即新建表):
request.onupgradeneeded = function (event) { db = event.target.result; var objectStore; if (!db.objectStoreNames.contains('person')) { // 新增一张叫做person的表格,主键是id objectStore = db.createObjectStore('person', { keyPath: 'id' }); } }
如果数据记录里面没有合适作为主键的属性,那么可以让 IndexedDB 自动生成主键:
var objectStore = db.createObjectStore( 'person', { autoIncrement: true } // 指定主键为一个递增的整数 )
新建对象仓库以后,下一步可以新建索引:
request.onupgradeneeded = function(event) { db = event.target.result; var objectStore = db.createObjectStore('person', { keyPath: 'id' }); // 三个参数分别为索引名称、索引所在的属性、配置对象(说明该属性是否包含重复的值) objectStore.createIndex('name', 'name', { unique: false }); objectStore.createIndex('email', 'email', { unique: true }); }
新增数据指的是向对象仓库写入数据记录,需要通过事务完成。
上面代码中,写入数据需要新建一个事务。新建时必须指定表格名称和操作模式("只读"或"读写")。新建事务以后,通过IDBTransaction.objectStore(name)方法,拿到 IDBObjectStore 对象,再通过表格对象的add()方法,向表格写入一条记录。写入操作是一个异步操作,通过监听连接对象的success事件和error事件,了解是否写入成功:
function add() { var request = db.transaction(['person'], 'readwrite') .objectStore('person') .add({ id: 1, name: '张三', age: 24, email: 'zhangsan@example.com' }); request.onsuccess = function (event) { console.log('数据写入成功'); }; request.onerror = function (event) { console.log('数据写入失败'); } } add();
读取数据也是通过事务完成。
function read() { var transaction = db.transaction(['person']); var objectStore = transaction.objectStore('person'); // objectStore.get()方法用于读取数据,参数是主键的值 var request = objectStore.get(1); request.onerror = function(event) { console.log('事务失败'); }; request.onsuccess = function( event) { if (request.result) { console.log('Name: ' + request.result.name); console.log('Age: ' + request.result.age); console.log('Email: ' + request.result.email); } else { console.log('未获得数据记录'); } }; } read();
遍历数据表格的所有记录,使用指针对象 IDBCursor:
function readAll() { var objectStore = db.transaction('person').objectStore('person'); // 新建指针对象的openCursor()方法是一个异步操作,所以要监听success事件 objectStore.openCursor().onsuccess = function (event) { var cursor = event.target.result; if (cursor) { console.log('Id: ' + cursor.key); console.log('Name: ' + cursor.value.name); console.log('Age: ' + cursor.value.age); console.log('Email: ' + cursor.value.email); cursor.continue(); } else { console.log('没有更多数据了!'); } }; } readAll();
更新数据要使用IDBObject.put()方法:
function update() { var request = db.transaction(['person'], 'readwrite') .objectStore('person') .put({ id: 1, name: '李四', age: 35, email: 'lisi@example.com' }); // put()方法自动更新了主键为1的记录 request.onsuccess = function (event) { console.log('数据更新成功'); }; request.onerror = function (event) { console.log('数据更新失败'); } } update();
IDBObjectStore.delete()方法用于删除数据:
function remove() { var request = db.transaction(['person'], 'readwrite') .objectStore('person') .delete(1); request.onsuccess = function (event) { console.log('数据删除成功'); }; } remove();
使用索引
索引的意义在于,可以让你搜索任意字段,也就是说从任意字段拿到数据记录。如果不建立索引,默认只能搜索主键(即从主键取值)。
假定新建表格的时候,对name字段建立了索引:
objectStore.createIndex('name', 'name', { unique: false });
现在,就可以从name找到对应的数据记录了:
var transaction = db.transaction(['person'], 'readonly'); var store = transaction.objectStore('person'); var index = store.index('name'); var request = index.get('李四'); request.onsuccess = function (e) { var result = e.target.result; if (result) { // ... } else { // ... } }
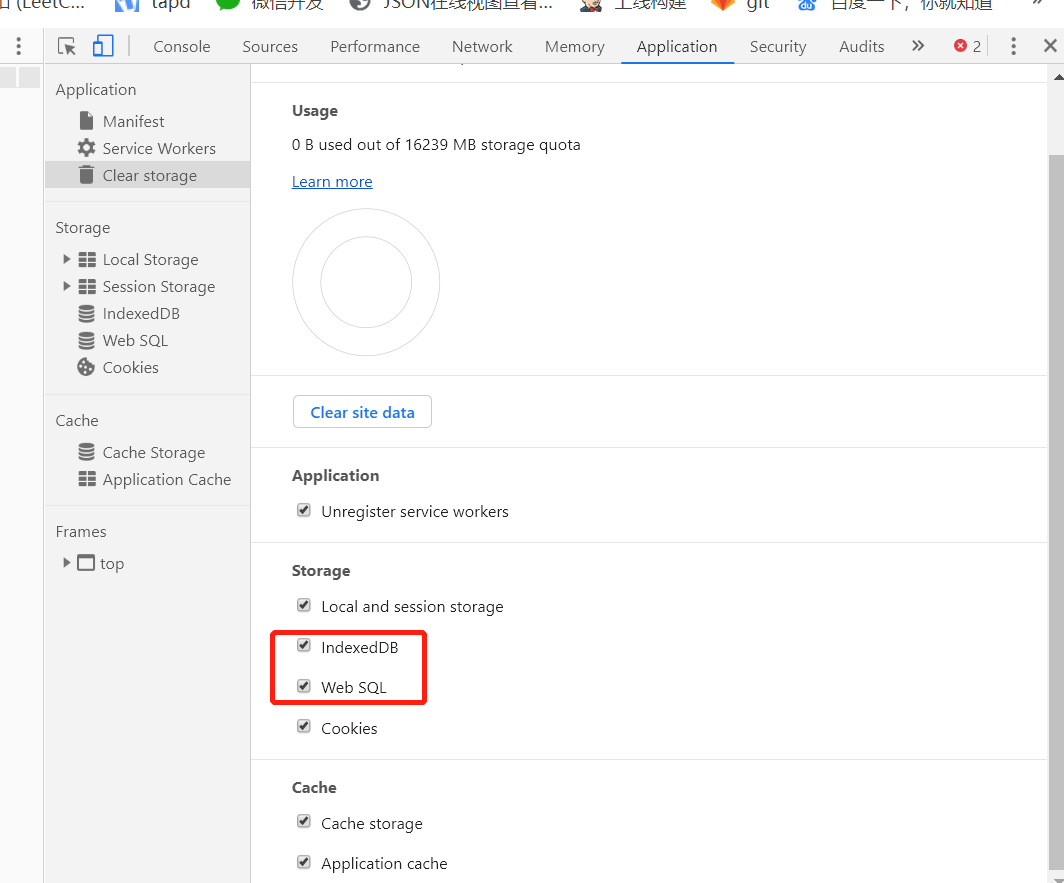
IndexDB和Web SQL可以用如下方式删除:
五、Cache Storage
Cache Storage和Service Worker可以实现无后端参与的纯前端的离线缓存。
首先了解下Service Worker吧。
直接请求的策略是web请求的做法,客户端发送请求,服务器返回数据,客户端再显示。在中间没有添加任何东西。那为何现在要在中间加一个Service Worker呢?主要是用户应付一些特殊场景和需求,如离线处理、消息推送等。而离线应用和消息推送正是目前native app相对于web app的优势所在。所以,Service Worker出现的目的是让web app可以和native app开始真正意义上的竞争。
我们平常浏览器窗口中跑的页面运行的是主JavaScript线程,DOM和window全局变量都是可以访问的。Service Worker和JavaScript跑的是完全不同的两个线程,因此Service Worker无论怎样也不会阻塞主JavaScript线程,也就是不会引起浏览器页面加载的卡顿的问题。由于Service Worker设计为完全异步,同步API(如XHR和localStorage)不能在Service Worker中使用。
除了上面的些限制外,Service Worker对我们的协议也有要求,就是必须是https协议的,但Service Worker在http://localhost或者http://127.0.0.1这种本地环境下的时候也是可以跑起来的。Service workers会大量使用Promise。
CacheStorage及Cache定义在Service Workers里。CacheStorage和Cache,是两个与缓存有关的接口,用于管理当前网页/Web App的缓存。CacheStorage管理着所有的Cache。CacheStorage主要功能无非就是增删改查(上面所有方法都返回Promise):
delete(),删除某个Cache;
open(),打开某个Cache(打开后才能修改Cache),若没有则新建一个;
keys(),得到所有Cache的名称;
has(),判断某个Cache是否存在。
// 删除名为`my-app`的Cache caches.delete('my-app').then(() => {console.log('Deleted.')}) // 打开名为`my-app`的Cache caches.open('my-app').then(cache => { // 操控cache })
Cache是一个类Map的数据结构对象。其键都是一个request(url),而值则是response。
.match(requestUrl, options),返回Promise,能得到requestUrl对应的response
.put(requestUrl, response),将requestUrl及其response保存在Cache里
.delete(requestUrl),从Cache里删除requestUrl及其response
.keys(),返回所有存在Cache的requestUrl
除了上述的基本方法外,Cache还提供.add(requestUrl),可以自动取得requestUrl对应的response,然后put进Cache里。
// 得到在Cache里某个url对应的response cache.match('/users').then(response => { // 操控response }) // 将`/user`及其response添加到缓存里 cache.add('/users').then(() => {console.log('Done.')})
demo:
Promise.all([ caches.open('c1').then(function(cache) { return cache.put('/hehe', new Response('aaa', { status: 200 })); }), caches.open('c2').then(function(cache) { return cache.put('/hehe', new Response('bbb', { status: 200 })); }) ]).then(function() { return caches.match('/hehe'); }).then(function(response) { return response.text(); }).then(function(body) { console.log(body); });
执行完后:

转自:https://www.cnblogs.com/xjy20170907/p/11772416.html

