栈溢出
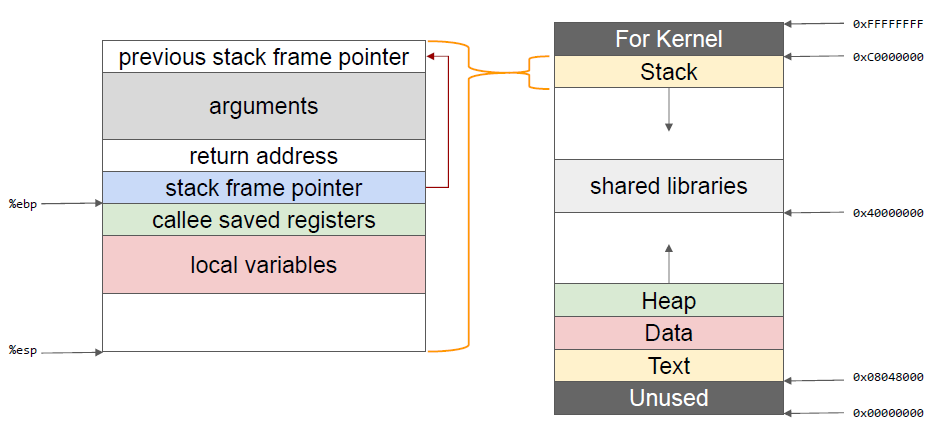
C语言函数调用栈
• 函数调用栈是指程序运行时内存一段连续的区域
• 用来保存函数运行时的状态信息,包括函数参数与局部变量等
• 称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶
• 在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态
• 函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大
栈帧结构概览
注意:再样本程序运行之前,一般需要修改程序为可执行文件(增加可执行权限),命令如下:
sudo chmod +x file(文件名)
函数状态主要涉及三个寄存器—— esp,ebp,eip。esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。ebp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。eip 用来存储即将执行的程序指令的地址,cpu依照eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
下面让我们来看看发生函数调用时,栈顶函数状态以及上述寄存器的变化。变化的核心任务是将调用函数(caller)的状态保存起来,同时创建被调用函数(callee)的状态。
首先将被调用函数(callee)的参数按照逆序依次压入栈内。如果被调用函数(callee)不需要参数,则没有这一步骤。这些参数仍会保存在调用函数(caller)的函数状态内,之后压入栈内的数据都会作为被调用函数(callee)的函数状态来保存。
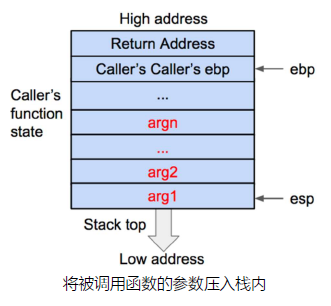
然后将调用函数(caller)进行调用之后的下一条指令地址作为返回地址压入栈内。这样调用函数(caller)的eip(指令)信息得以保存。
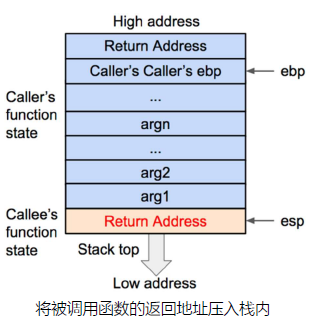
再将当前的ebp 寄存器的值(也就是调用函数的基地址)压入栈内,并将ebp 寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的ebp(基地址)信息得以保存。同时,ebp 被更新为被调用函数(callee)的基地址。
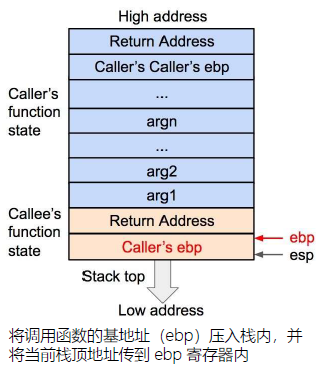
再之后是将被调用函数(callee)的局部变量等数据压入栈内。
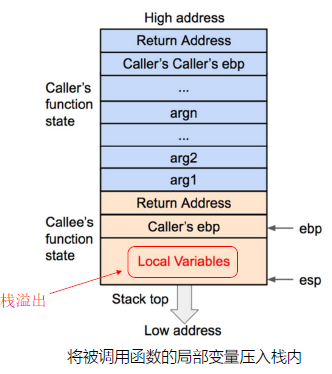
在压栈的过程中,esp 寄存器的值不断减小(对应于栈从内存高地址向低地址生长)。压入栈内的数据包括调用参数、返回地址、调用函数的基地址,以及局部变量,其中调用参数以外的数据共同构成了被调用函数(callee)的状态。在发生调用时,程序还会将被调用函数(callee)的指令地址存到eip 寄存器内,这样程序就可以依次执行被调用函数的指令了。
看过了函数调用发生时的情况,就不难理解函数调用结束时的变化。变化的核心任务是丢弃被调用函数(callee)的状态,并将栈顶恢复为调用函数(caller)的状态。
首先被调用函数的局部变量会从栈内直接弹出,栈顶会指向被调用函数(callee)的基地址。

然后将基地址内存储的调用函数(caller)的基地址从栈内弹出,并存到ebp 寄存器内。这样调用函数(caller)的ebp(基地址)信息得以恢复。此时栈顶会指向返回地址。
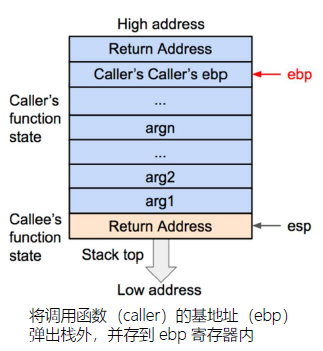
再将返回地址从栈内弹出,并存到eip 寄存器内。这样调用函数(caller)的eip(指令)信息得以恢复。至此调用函数(caller)的函数状态就全部恢复了,之后就是继续执行调用函数的指令了。
栈溢出原理
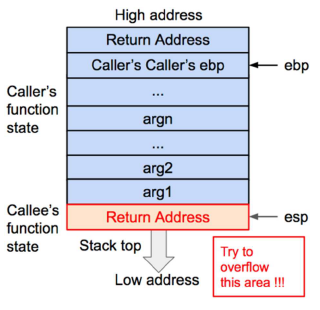
当函数正在执行内部指令的过程中我们无法拿到程序的控制权,只有在发生函数调用或者结束函数调用时,程序的控制权会在函数状态之间发生跳转,这时才可以通过修改函数状态来实现攻击。而控制程序执行指令最关键的寄存器就是eip,所以我们的目标就是让eip 载入攻击指令的地址。
函数调用结束时,如果要让eip 指向攻击指令,首先,在退栈过程中,返回地址会被传给eip,所以我们只需要让溢出数据用攻击指令的地址来覆盖返回地址就可以了。其次,我们可以在溢出数据内包含一段攻击指令,也可以在内存其他位置寻找可用的攻击指令。
缓冲区溢出
编写程序时没有考虑到控制或者错误控制用户输入的长度,本质就是向定长的缓冲区中写入了超长的数据,造成超出的数据覆写了合法内存区域
栈溢出
-
最常见、漏洞比例较高、危害最大的二进制漏洞
-
PWN题目中的基础
堆溢出
-
堆管理器复杂,利用花样繁多
-
常见的题型
data段溢出
-
攻击依赖于data段上存放了何种控制数据
栈溢出基本应用
纂改栈帧上的返回地址为程序中已有的后门函数(比如backdoor)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号