原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我
注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的。
爬虫目标网站:http://jandan.net/ooxx/ #如有侵权请联系我
代码如下
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 import urllib.request 4 import base64 5 import time 6 7 url_a = 'http://jandan.net/ooxx/'#网站前一部分 8 need = '20200217-'#后一部分 9 need_a = 147#后一部分的后一部分 10 11 12 def base(word):#base64编码 13 outcome = base64.b64encode(word.encode("utf-8"))#编码后 14 url = url_a + outcome.decode('utf-8') + '#comments' 15 web(url) 16 17 def web(url): 18 response = urllib.request.urlopen(url) 19 html = response.read().decode('utf-8') 20 a = html.find('<img src="//')#从这个下标开始 21 i = 0#用来区别文件名 22 while a != -1: 23 b = html.find('.jpg',a,a+250)#到这个下标为止 24 if b != -1: 25 c = 'http://' + html[a+12:b+4]#图片网址 26 name = 'picture\\' + str(i) + str(need_a) + '.jpg'#文件名 27 get_jpg(c,name) 28 else: 29 b = a + 12 30 a = html.find('<img src="//',b)#循环查找 31 i += 1 32 33 def get_jpg(address,filename): 34 get = urllib.request.urlopen(address)#打开新网址 35 jpg = get.read() 36 with open(filename,'wb') as f:#写入图片 37 f.write(jpg) 38 print("Succeed!") 39 40 while need_a >=100:#逐减 41 addition = need + str(need_a) 42 base(addition) 43 need_a -= 1 44 time.sleep(10)#停顿防止被反爬
效果图:
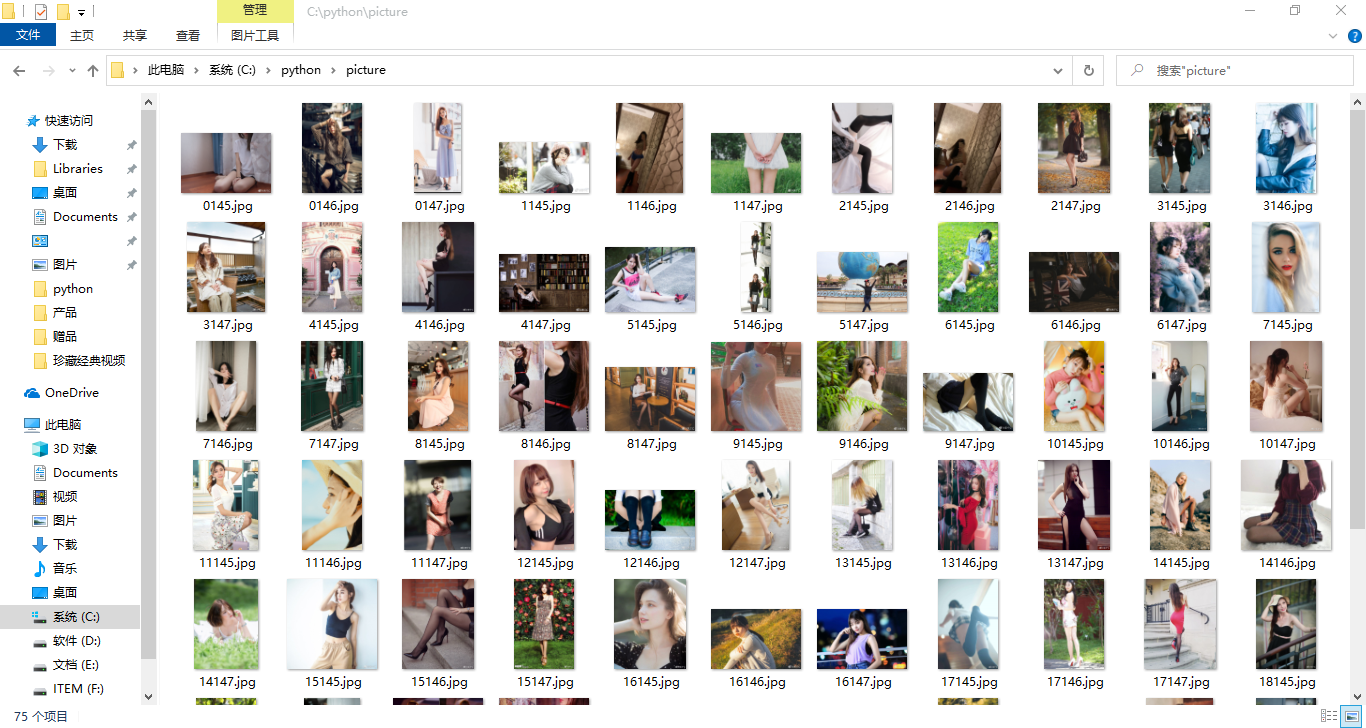
未经博主允许,不得转载

