

OOP课第一阶段总结
前三次OOP作业总结Blog
-
前言
-
作为第一次3+1的总结,这次题目集的难度逐渐升高,题量、阅读量和测试点的数量变化都很大,所以对我们的编程和理解能力提出了更高的要求。要求我们能够熟练的掌握正则表达式的使用和类与类之间的关系。在敲代码之前必须要先捋清楚自己的思路和想法。例如在第一次到第三次的题目集中,类的数量由三个增长到了十余个,如果没有合理的设计将会寸步难行。投入的时间也由最开始的4至5个小时到了后来的18至24小时。这个过程从主观来说非常的痛苦,但是好在并不是全无收获。
-
在这三周的时间里存在很多的问题,一开始根本不懂得数据如何去保存,也不知道类如何去使用。第一阶段的题目集中非常着重的考察了正则表达式的使用,这一特点在第三次题目集中尤为显著。这也意味着很多东西都需要从0开始,这个从无到有的过程才是对我们能力的训练。
-
在第三次题目集中测试点也增长到了前所未有的28个,情况非常的复杂,而且存在一个非常明显的现象。在题目集开放至第三天的时候,达到满分的只有寥寥几人,其余很多人都停留在了94、97分的阶段,300多人提交了一万多份答卷,而通过率却只有堪堪1%。造成这一现象的主要原因是一些特殊测试点的存在,比如“答案为空字符”、“空白卷”等测试点成为了学生去往满分的路上最大的拦路虎。这说明,在设计代码的时候,并没有考虑到一些非常极端的情况,这是一个很大的缺陷。为了解决这些问题,我们陷入了非常痛苦的循环之中:
不断地用额外的测试点进行调试
不断地询问别人遇到的问题
不断地修改已经提交了几十遍的代码
-
-
正文
-
第一次题目集
这次题目集难度倒是不高,但是对于接触面向对象编程不久的小萌新来说还是颇具挑战:
题目主干:
设计实现答题程序,模拟一个小型的测试,要求输入题目信息和答题信息,根据输入题目信息中的标准答案判断答题的结果。
其中需要处理的数据一共只有两个类型:
题目内容 "#N:"+题号+" "+"#Q:"+题目内容+" "#A:"+标准答案
答题信息 "#A:"+答案内容
这里需要使用正则表达式去分割各个信息的不同部分,并且储存起来
UML类图:
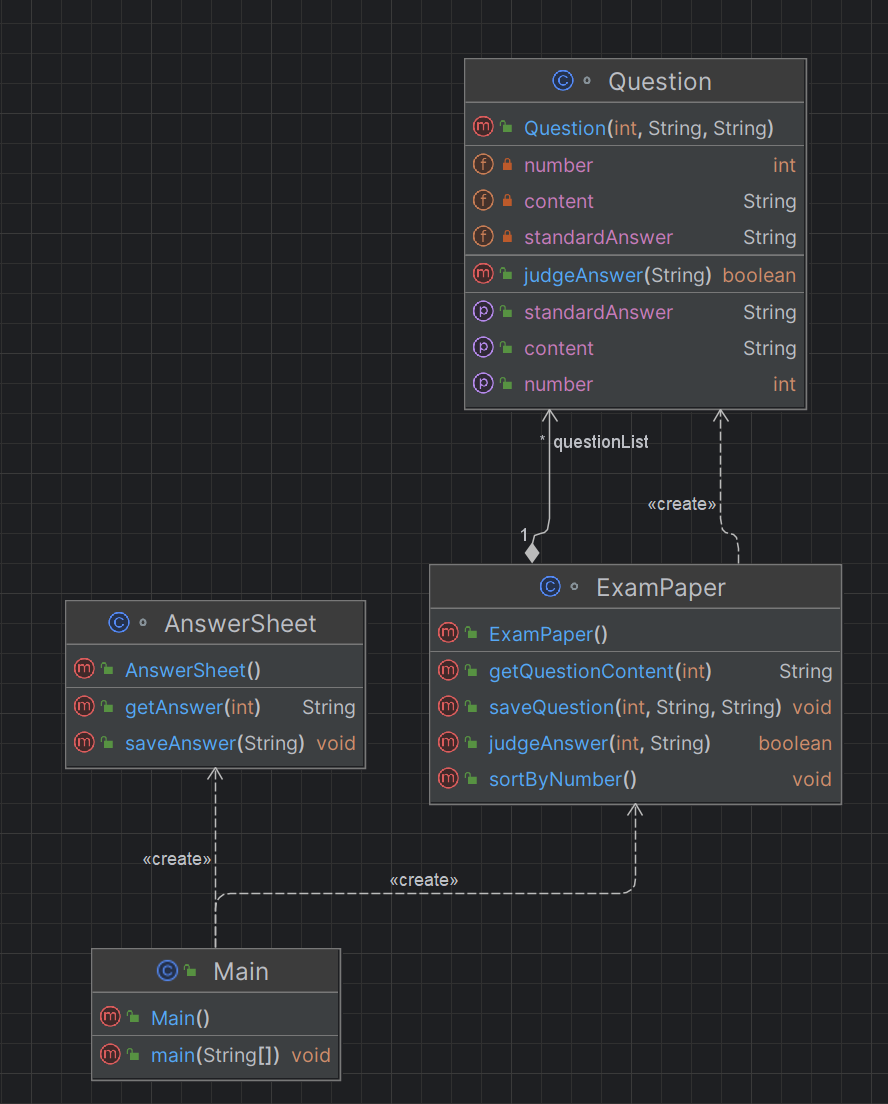
可以看到一共设计了三个类,分别是AnswerSheet,ExamPaper,Question。
简单展示一下题目集一的复杂度:
复杂度:
Method CogC ev(G) iv(G) v(G) AnswerSheet.AnswerSheet() 0 1 1 1 AnswerSheet.getAnswer(int) 0 1 1 1 AnswerSheet.saveAnswer(String) 0 1 1 1 ExamPaper.ExamPaper() 0 1 1 1 ExamPaper.getQuestionContent(int) 0 1 1 1 ExamPaper.judgeAnswer(int, String) 0 1 1 1 ExamPaper.saveQuestion(int, String, String) 0 1 1 1 ExamPaper.sortByNumber() 0 1 1 1 Main.main(String[]) 11 1 7 9 Question.Question(int, String, String) 0 1 1 1 Question.getContent() 0 1 1 1 Question.getNumber() 0 1 1 1 Question.getStandardAnswer() 0 1 1 1 Question.judgeAnswer(String) 0 1 1 1 从这个表格中可以看出Main的复杂度比较高,主要是因为数据的读入和输出都是在主函数里面完成的:
public class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int questionCount = Integer.parseInt(scanner.nextLine()); ExamPaper examPaper = new ExamPaper(); for (int i = 0; i < questionCount; i++) { String input = scanner.nextLine().trim(); String[] parts = input.split("#"); int number = Integer.parseInt(parts[1].split(":")[1].trim()); String content = parts[2].split(":")[1].trim(); String standardAnswer = parts[3].split(":")[1].trim(); examPaper.saveQuestion(number, content, standardAnswer); } AnswerSheet answerSheet = new AnswerSheet(); String answerInput = scanner.nextLine().trim(); while (!answerInput.equals("end")) { String[] answers = answerInput.split("\\s+"); for (String answer : answers) { answerSheet.saveAnswer(answer); } answerInput = scanner.nextLine().trim(); } examPaper.sortByNumber(); for (int i = 1; i <= questionCount; i++) { String questionContent = examPaper.getQuestionContent(i); String answer = answerSheet.getAnswer(i); System.out.println(questionContent + "~" + answer.replace("#A:","")); } for (int i = 1; i <= questionCount; i++) { String answer = answerSheet.getAnswer(i); boolean result = examPaper.judgeAnswer(i, answer.replace("#A:","")); System.out.print(result ? "true" : "false"); if(i>=1 && i!=questionCount){ System.out.print(" "); } } } } -
第二次题目集
第二次题目集我完成的不好,这是显而易见的,因为越来越多的数据需要处理,让我一个对数组的使用很是生疏的初学者较为棘手,所以这次题目及的代码就已经写成
一坨乱麻了,非常的难看。问题主要出现在对于试卷信息的处理上:
试卷信息
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值
由于这次添加了试卷信息,需要给出得分,题目分值和题目编号一一对应,正常来说需要使用到HashMap这样的映射关系,将题目编号和题目分值以映射的关系储存在一起,便可以通过题目编号寻找到相应的分值。但是当时我铁了心的要用List实现,后来发现非常的困难,但是我对于HashMap的使用非常的生疏,所以也没有及时的更改我的思路,导致最后的代码修修补补,毫无逻辑可言。
UML类图:
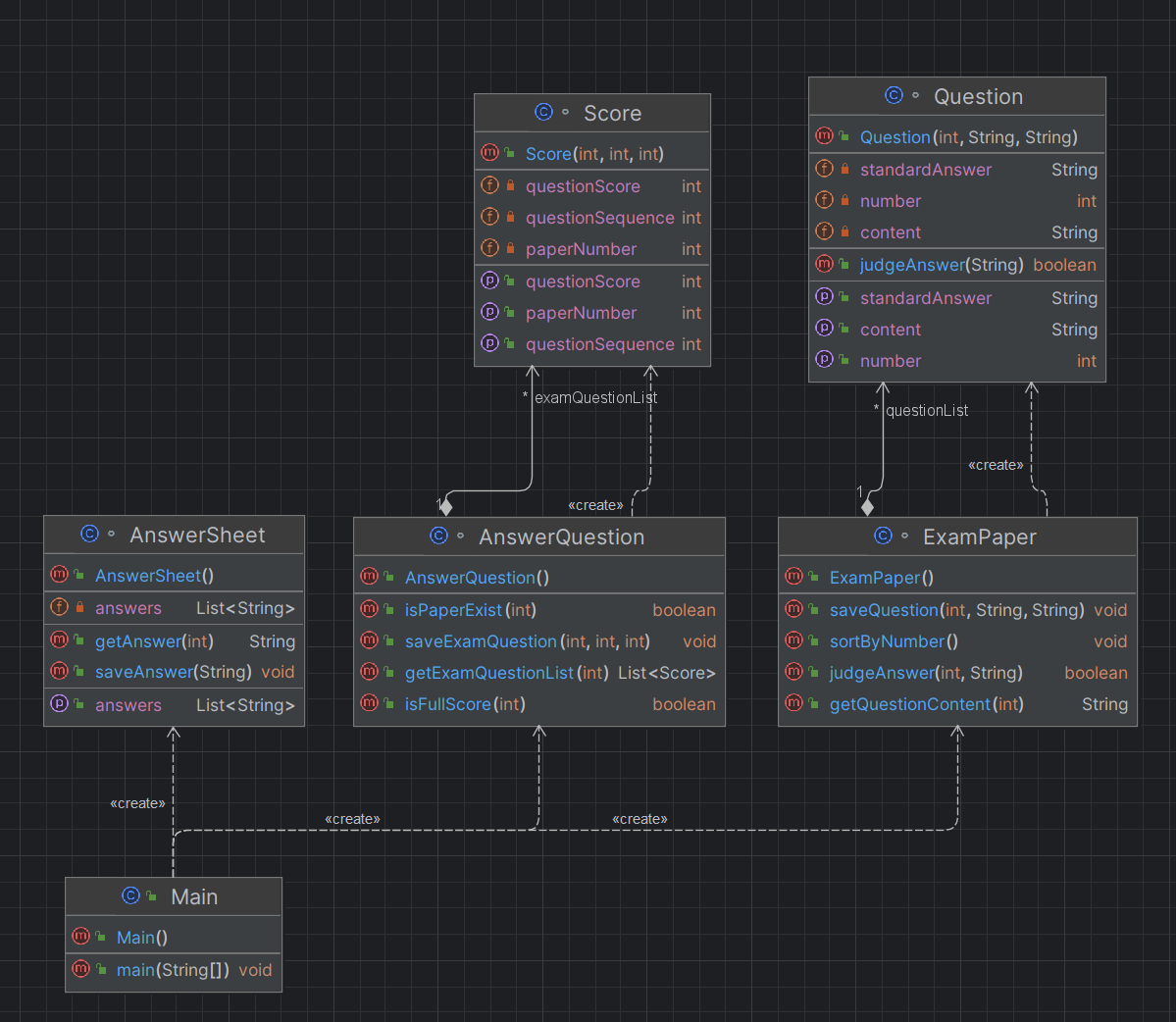
主函数非常的复杂,属于是剑走偏锋,两百多行的代码,主函数就占了半壁江山:
复杂度:
Class OCavg OCmax WMC AnswerQuestion 2.2 3 11 AnswerSheet 1.25 2 5 ExamPaper 1 1 5 Main 28 28 28 Question 1 1 5 Score 1 1 4 Method CogC ev(G) iv(G) v(G) AnswerQuestion.AnswerQuestion() 0 1 1 1 AnswerQuestion.getExamQuestionList(int) 3 1 3 3 AnswerQuestion.isFullScore(int) 3 1 3 3 AnswerQuestion.isPaperExist(int) 3 3 2 3 AnswerQuestion.saveExamQuestion(int, int, int) 0 1 1 1 AnswerSheet.AnswerSheet() 0 1 1 1 AnswerSheet.getAnswer(int) 1 2 2 2 AnswerSheet.getAnswers() 0 1 1 1 AnswerSheet.saveAnswer(String) 0 1 1 1 ExamPaper.ExamPaper() 0 1 1 1 ExamPaper.getQuestionContent(int) 0 1 1 1 ExamPaper.judgeAnswer(int, String) 0 1 1 1 ExamPaper.saveQuestion(int, String, String) 0 1 1 1 ExamPaper.sortByNumber() 0 1 1 1 Main.main(String[]) 72 5 27 29 Question.Question(int, String, String) 0 1 1 1 Question.getContent() 0 1 1 1 Question.getNumber() 0 1 1 1 Question.getStandardAnswer() 0 1 1 1 Question.judgeAnswer(String) 0 1 1 1 Score.Score(int, int, int) 0 1 1 1 Score.getPaperNumber() 0 1 1 1 Score.getQuestionScore() 0 1 1 1 Score.getQuestionSequence() 0 1 1 1 我看到这个数据的时候也是感觉到了非常的夸张,基本上成为了主函数战士,一个人把其他类的活干了一半。
还是看一下数据的输入部分吧:
数据输入:
while (true) { String input = scanner.nextLine().trim(); if (input.equals("end")) { break; } String[] parts = input.split("#"); String types = parts[1].split(":")[0].trim(); if (types.equals("N")) { int questionNumber = Integer.parseInt(parts[1].split(":")[1].trim()); String content = parts[2].split(":")[1].trim(); String standardAnswer = parts[3].split(":")[1].trim(); examPaper.saveQuestion(questionNumber, content, standardAnswer); } /*省略部分源码*/ }在这里使用了一个while循环来不断地读取每一行的数据,当遇到end的时候便直接退出循环。这段代码对数据的分割都是通过split完成的,而不是使用正则表达式,对于这道题来说,前者的功能堪堪够用,但是对于第三次题目集来说就有一点
狗骑吕布的感觉了。😰 -
第三次题目集
这是我需要着重来说明的一次题目集,经过前两次的进化,这次的题目已经来到了
惨无人道的地步,28个测试点等着我去击破。由于第二次题目集上糟糕的表现,我这次完全从头开始,设计好了每一个类承担的功能,但是主函数战士的我还是把主类写到了200行(哭)。本次题目集加入了很多功能:
学生信息 "#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名
答卷信息 "#S:"+试卷号+" "+学号+" "+"#A:"+试卷题目的顺序号+"-"+答案内容+...
删除题目信息 "#D:N-"+题目号
错误提示信息
错误格式判断
一开始我还是一如既往的使用split对数据进行分割处理,但是发现有着很大的漏洞:
错误格式判断怎么解决???
这下是真的逃不掉正则表达式的使用了,花了一个晚自习上网学习正则表达式的使用,然后才磕磕绊绊的开始写错误格式判断的代码,每写一次都要用很多个数据去测试我写的正则表达式是否存在漏洞:
错误格式判断:
String regexOfN = "省略"; String regexOfT = "省略"; String regexOfX = "省略"; String regexOfS = "省略"; String regexOfD = "省略"; boolean flag=input.matches(regexOfN)||input.matches(regexOfT)||input.matches(regexOfX)||input.matches(regexOfS)||input.matches(regexOfD);这么一点代码,却是整道题含金量最高的地方之一(个人观点),毕竟花费了非常多的时间去调试这段代码,也有很多测试点涉及到了这部分的功能。一共有12个测试点需要进行错误格式判断,几乎就是整道题一半的分值都被这段代码所左右了。
然后由于题目添加和很多新的数据信息,各个数据之间的关系也变得非常复杂,有一点
很恶心的地方是,在学生的答卷信息中的题号居然是试卷信息中的顺序号(人麻了,问题在于真的有学生不按照顺序答题吗)。其次对于使用List还是使用HashMap我思考了很久。显而易见的是,这道题目有很多地方使用后者是更方便的,因为信息中存在很多一一映射的关系,使用HashMap非常适合用来处理这样的关系,但是笔者可能比较倔强,前两个题目集用的是List那我就继续用,笔者的室友觉得这简直不敢相信会有多么复杂,但笔者就要证明List肯定没有问题。
用到的List:
ArrayList<AllAnswerSheet> allAnswerSheetArrayList=new ArrayList<>(); ArrayList<AnswerSheet> answerSheetArrayList=new ArrayList<>(); ArrayList<AllPaper> allPaperArrayList=new ArrayList<>(); ArrayList<Question> questionArrayList=new ArrayList<>(); /*省略部分源码*/UML类图:
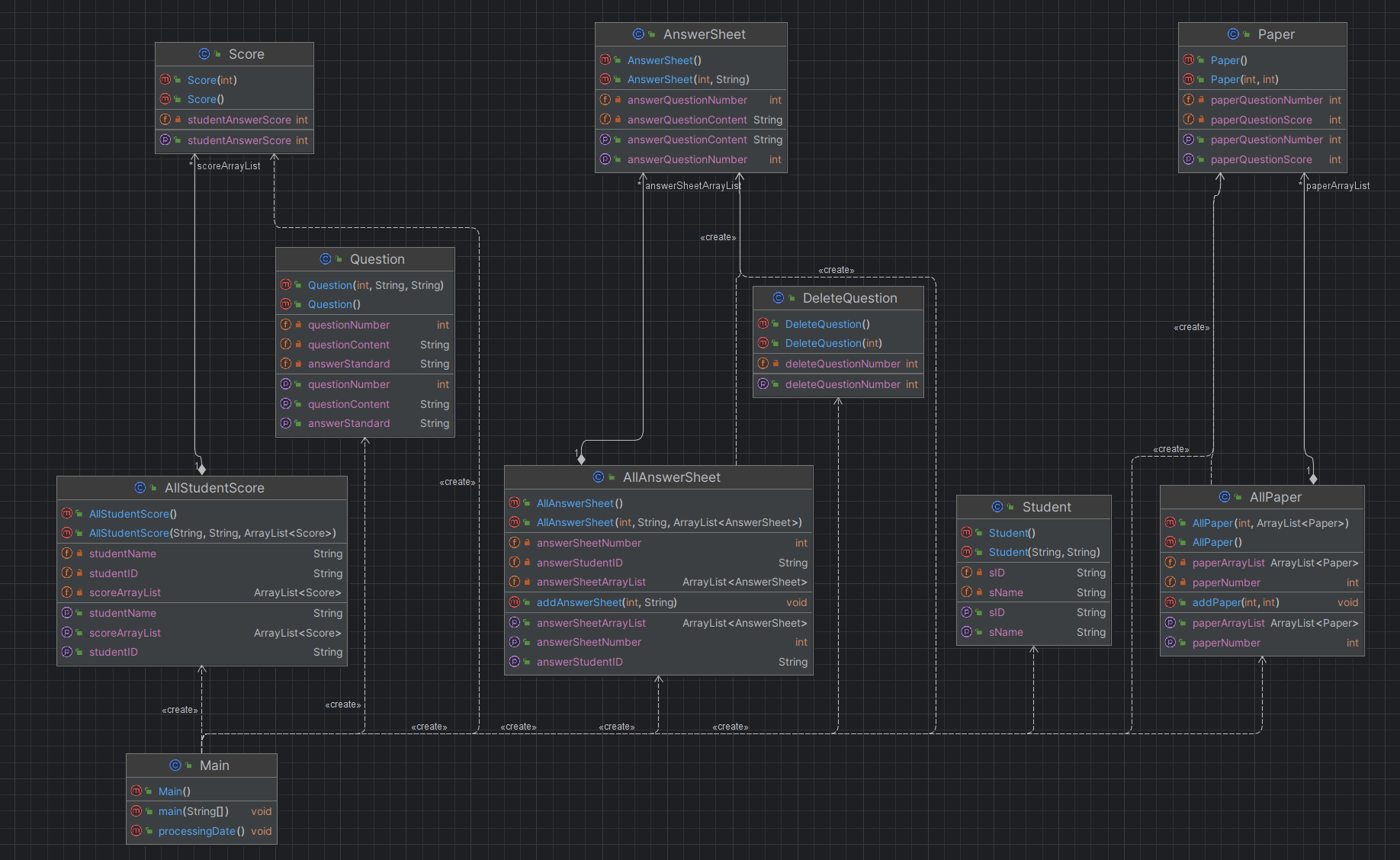
这次一共用到了十个类,但是实际上可以有更多,其中有一些类比较特殊,比如AllAnswerSheet和AnswerSheet,它们之间存在一种整体与部分之间的关系,前者用于储存所有学生的答题情况,后者用于储存单个学生对象的答题情况。
为什么要这样做呢?
主要是因为,每个学生的答题数量可能不一致。所以肯定不能以统一的格式去保留每个学生的答题情况,因此只能让每一个学生对象的答题情况先单独储存起来,再用一个数组去储存每一张答卷。效果有点类似于:
效果图:
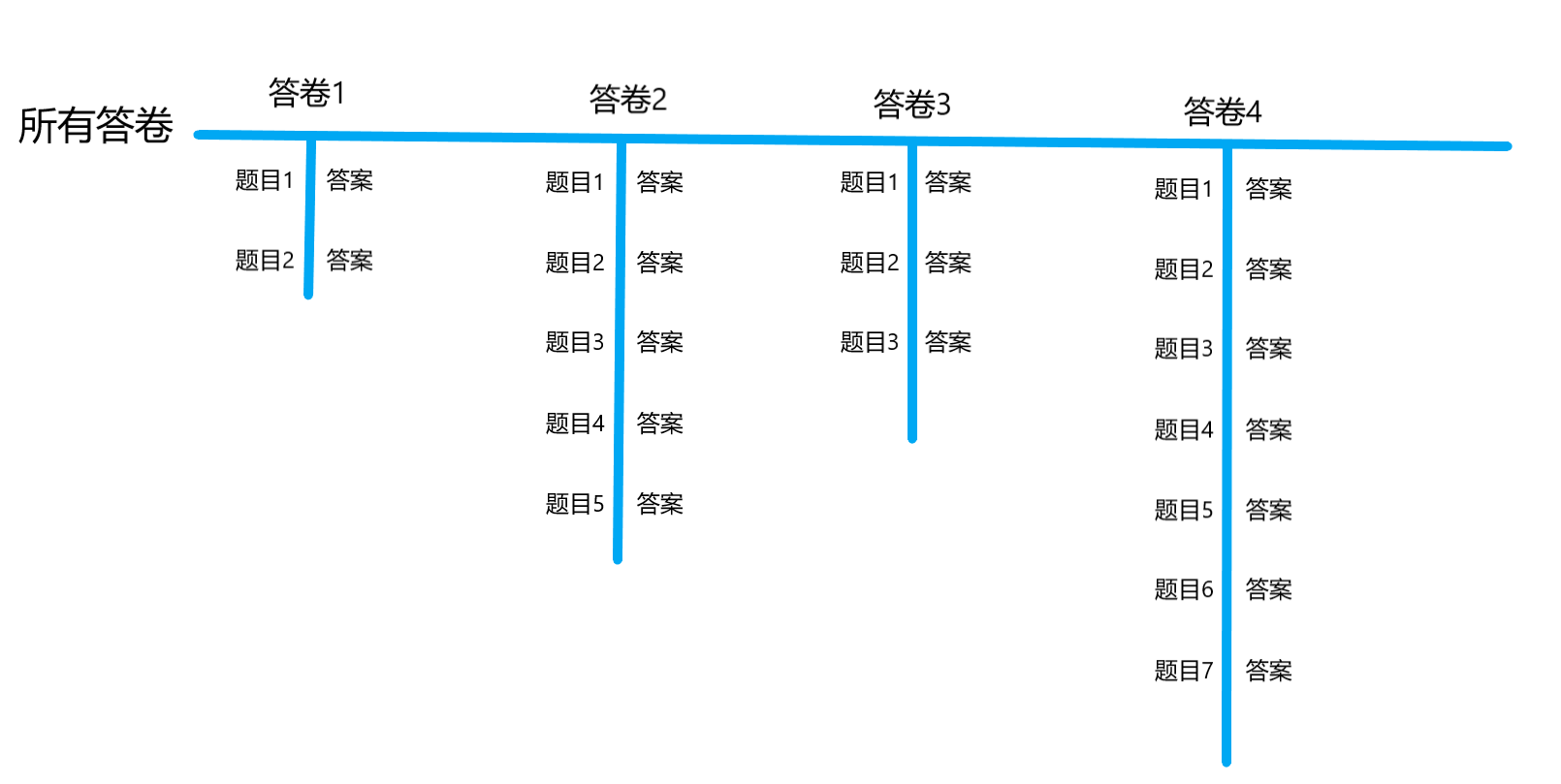
这样子就可以用两个List实现类似于HashMap的效果,并且可以处理每个学生答题数量不一致的情况。
------------------------------以下是一些投机取巧(可以略过)----------------------------------
-
在删除题目时,笔者直接将需要删除的题目的标准答案改成“???”,这样在遍历的时候当检测到标准答案为“???”的时候,就可以知道应该输出题目被删除的警示信息了。
-
依然是在删除题目时,笔者直接将删除的题目的题目内容改成“the question "+题号+" invalid~0”,这样当遇到第一条的情况时,我不需要写额外的输出,可以直接按照题目原有的顺序输出警示信息啦。
for(int i=0;i<deleteQuestionArrayList.size();i++){ for(int j=0;j<questionArrayList.size();j++){ if(questionArrayList.get(j).getQuestionNumber()==deleteQuestionArrayList.get(i).getDeleteQuestionNumber()){ questionArrayList.get(j).setQuestionContent("the question "+questionArrayList.get(j).getQuestionNumber()+" invalid~0"); questionArrayList.get(j).setAnswerStandard("???"); } } } -
在读入答题信息的时候,可能会遇到这样一种极端的情况:
极端情况:#S:1 20201103
答卷信息只有试卷号和学号,这样的话在保存题号以及答案的时候将会是空的,便会出现bug。所以,当检测到不存在任何一个答题的时候,就存入“#A:0-??”这样一段信息,由于题目号不可能为0,所以当遍历到这张答卷的时候直接就会输出答案不存在的警示信息。
Pattern pattern=Pattern.compile("#S:(\\d+) (\\w+)( #A:(\\w+)-(.*))*"); Matcher matcher=pattern.matcher(input); if(matcher.find()){} int answerNumber=Integer.parseInt(matcher.group(1)); String studentID= matcher.group(2); String[] answerParts; if(matcher.group(3)==null){ answerParts="#A:0-??".split("#A:"); }else answerParts=matcher.group(3).split("#A:"); for(int i=1;i<answerParts.length;i++){ String studentAnswer; if(answerParts[i].split("-").length>1){ studentAnswer=answerParts[i].split("-")[1].trim(); }else studentAnswer=""; //System.out.println(Integer.parseInt(answerParts[i].split("-")[0])); answerSheetArrayList.add(new AnswerSheet(Integer.parseInt(answerParts[i].split("-")[0]),studentAnswer)); }看到这里可能就觉得笔者耍了太多小聪明了,但是其实这里面的每一步都是为了解决一个极端情况(
呜呜呜)。-------------------------------以上是一些投机取巧(可以略过)---------------------------------
现在简单的来看一下第三次题目集的代码质量吧(
惨不忍睹):复杂度:
Class OCavg OCmax WMC AllAnswerSheet 1 1 9 AllPaper 1 1 7 AllStudentScore 1 1 8 AnswerSheet 1 1 6 DeleteQuestion 1 1 4 Main 25 49 50 Paper 1 1 6 Question 1 1 8 Score 1 1 4 Student 1 1 6 Package v(G)avg v(G)tot 1.88 113 Module v(G)avg v(G)tot pta3test 1.88 113 Project v(G)avg v(G)tot project 1.88 113 Method CogC ev(G) iv(G) v(G) AllAnswerSheet.AllAnswerSheet() 0 1 1 1 AllAnswerSheet.AllAnswerSheet(int, String, ArrayList ) 0 1 1 1 AllAnswerSheet.addAnswerSheet(int, String) 0 1 1 1 AllAnswerSheet.getAnswerSheetArrayList() 0 1 1 1 AllAnswerSheet.getAnswerSheetNumber() 0 1 1 1 AllAnswerSheet.getAnswerStudentID() 0 1 1 1 AllAnswerSheet.setAnswerSheetArrayList(ArrayList ) 0 1 1 1 AllAnswerSheet.setAnswerSheetNumber(int) 0 1 1 1 AllAnswerSheet.setAnswerStudentID(String) 0 1 1 1 AllPaper.AllPaper() 0 1 1 1 AllPaper.AllPaper(int, ArrayList ) 0 1 1 1 AllPaper.addPaper(int, int) 0 1 1 1 AllPaper.getPaperArrayList() 0 1 1 1 AllPaper.getPaperNumber() 0 1 1 1 AllPaper.setPaperArrayList(ArrayList ) 0 1 1 1 AllPaper.setPaperNumber(int) 0 1 1 1 AllStudentScore.AllStudentScore() 0 1 1 1 AllStudentScore.AllStudentScore(String, String, ArrayList ) 0 1 1 1 AllStudentScore.getScoreArrayList() 0 1 1 1 AllStudentScore.getStudentID() 0 1 1 1 AllStudentScore.getStudentName() 0 1 1 1 AllStudentScore.setScoreArrayList(ArrayList ) 0 1 1 1 AllStudentScore.setStudentID(String) 0 1 1 1 AllStudentScore.setStudentName(String) 0 1 1 1 AnswerSheet.AnswerSheet() 0 1 1 1 AnswerSheet.AnswerSheet(int, String) 0 1 1 1 AnswerSheet.getAnswerQuestionContent() 0 1 1 1 AnswerSheet.getAnswerQuestionNumber() 0 1 1 1 AnswerSheet.setAnswerQuestionContent(String) 0 1 1 1 AnswerSheet.setAnswerQuestionNumber(int) 0 1 1 1 DeleteQuestion.DeleteQuestion() 0 1 1 1 DeleteQuestion.DeleteQuestion(int) 0 1 1 1 DeleteQuestion.getDeleteQuestionNumber() 0 1 1 1 DeleteQuestion.setDeleteQuestionNumber(int) 0 1 1 1 Main.main(String[]) 0 1 1 1 Main.processingDate() 230 17 48 54 Paper.Paper() 0 1 1 1 Paper.Paper(int, int) 0 1 1 1 Paper.getPaperQuestionNumber() 0 1 1 1 Paper.getPaperQuestionScore() 0 1 1 1 Paper.setPaperQuestionNumber(int) 0 1 1 1 Paper.setPaperQuestionScore(int) 0 1 1 1 Question.Question() 0 1 1 1 Question.Question(int, String, String) 0 1 1 1 Question.getAnswerStandard() 0 1 1 1 Question.getQuestionContent() 0 1 1 1 Question.getQuestionNumber() 0 1 1 1 Question.setAnswerStandard(String) 0 1 1 1 Question.setQuestionContent(String) 0 1 1 1 Question.setQuestionNumber(int) 0 1 1 1 Score.Score() 0 1 1 1 Score.Score(int) 0 1 1 1 Score.getStudentAnswerScore() 0 1 1 1 Score.setStudentAnswerScore(int) 0 1 1 1 Student.Student() 0 1 1 1 Student.Student(String, String) 0 1 1 1 Student.getsID() 0 1 1 1 Student.getsName() 0 1 1 1 Student.setsID(String) 0 1 1 1 Student.setsName(String) 0 1 1 1 看完之后感觉整个人都不好了,这就是主函数战士的后果(
你是谁的部下)。但是还得接着看: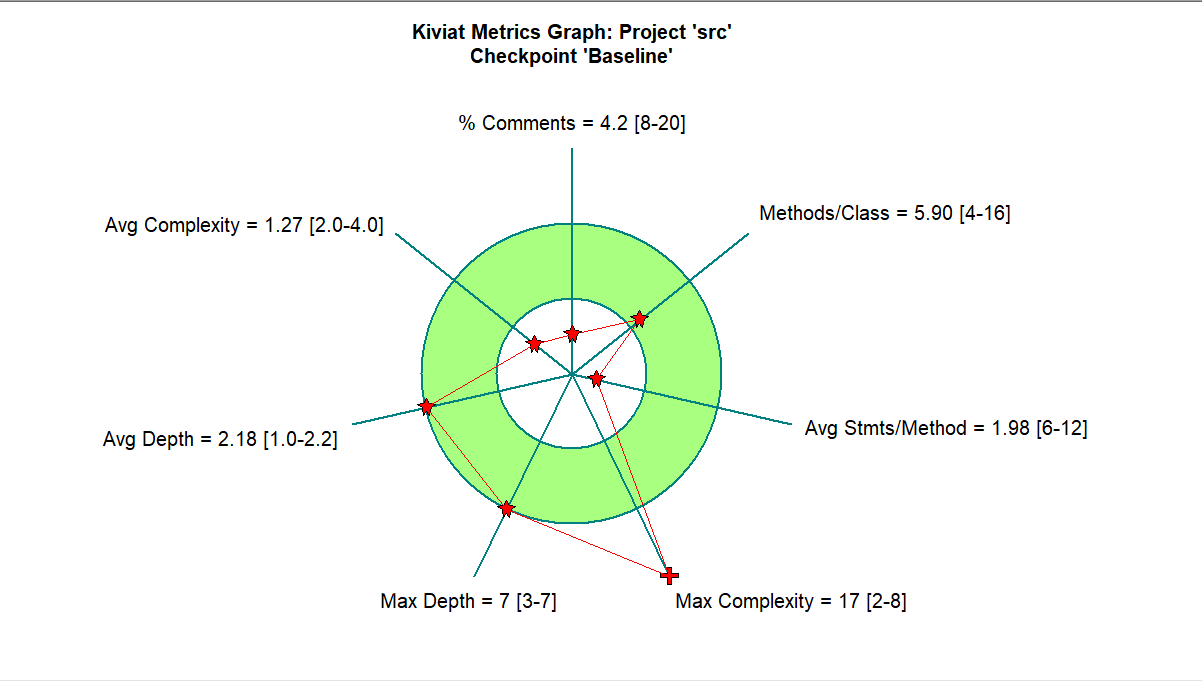
在官方对Kiviat图的介绍中:
Kiviat 图中的绿色环形区域即被测量维度的期望值,维度上的点则是测量得到的实际值。当一个维度上的点位于绿色环形区域中时表明这个维度的测量结果是符合期望的。
所以不得不说,这个期望值有点偏离过多。
-
-
-
总结
-
自我总结
这三次题目集的完成情况光从纸面成绩来看似乎
还算优良?简直烂的要命
这是笔者对自己的严厉批评。代码不规范,从每次的主函数复杂度就可以看得出来,主函数承担了太多它不该承担的功能。而且笔者发现自己还存在一个很严重的问题,我愿称之为:学习后移
解释:
“学习后移”指的是笔者总是在下一次题目集去解决上一次题目集出现的问题,因为在前一次题目集的时候可能掌握的东西较少,需要学习的东西较多,但是却无法在前一次题目集的时间内解决,只能留到下一次题目集接着学习然后再完成。让我的学习出现了滞后性。
这样就会造成一个比较严重的后果,每一次的代码都要大改,总是会出现很多不能在下一次题目集继续使用的代码,也就是复用性不高。而且写的代码质量也不高,看似拿到了满分却实则毫无章法。举个例子:
老板给员工A安排了一个种黄瓜的任务,经费1万。
员工A请挖掘机给这黄瓜种子挖了一排坑,花了九千。
只剩下一千作为以后浇水施肥的费用,半年后黄瓜长出来了,看着和正常的黄瓜看起来没什么区别,但是吃起来却酸涩无比。
所以笔者只能加倍的努力了,逃出这个学习后移的窘境,避免笔者的黄瓜吃起来
又酸又涩。最后,OO课的难度确实是前所未有的,这对我来说可能是一个很大的挑战,但是哪有前路一片坦荡的人生,磕磕碰碰没事,只要学到了就是值得。真的是让笔者切身的体会到了,什么叫做:
学而不思则罔,思而不学则殆
-
踩坑心得
-
真的是踩了一个巨大的坑啊,在题目集三中,最开始我是根据答卷信息去搜索题目的,写完之后发现有些测试点根本行不通。因为判题情况的顺序是根据试卷信息里面的顺序进行输出的,如果我依旧按照答卷信息写下去将会是一条不归路。所以我毅然决然把整个判题代码重新写了一遍,换成了根据试卷信息搜索题目。这样就顺利多了。
-
题目集三的最后一个测试点,我一直错了很久很久,到后面发现根本不是乱序输入的情况让我的输出结果错误,而是因为题目内容或者答案内部存在空格而错误的。但是我一开始又是根据空格进行分割,所以一直都对不了。
当时用的极端的测试样例:
#N:1 #Q:1+1= #A: 1 0 5 #T:2 1-5 #X:20201103 Tom #S:1 20201103 #A:1-1 0 5 #A:2-4 #S:2 20201103 #A:1- 5 #A:2-4 end当时把这个测试样例过了才拿到了满分。
正确的输出应该是:
alert: full score of test paper2 is not 100 points The test paper number does not exist 1+1=~5~false 20201103 Tom: 0~0
-
-
课程建议
- 题目有一些内容描述的不是很准确,但是在第三次题目集中这个问题就减少很多了。
- 希望之后的题目集可以另外给出特别极端的样例,给一个就行。
-
-
番外
- 写博客的时候typora是真的好用啊,比起博客网的编辑器真的是天渊之别啊。
- 什么,你说激活typora你花了89块?笔者只花了3.99,借助于什么都有的神奇某宝。
- 通过这个就可以学会如何写博客了:MarkDown语法
- 笔者非常正经,为了增加一些阅读的趣味性所以这篇博客可能存在一些笑点,不要嘲笑笔者(
哈哈哈)。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步