操作系统——内存管理学习笔记

操作系统——内存管理
Basic memory management
Base and Limit register
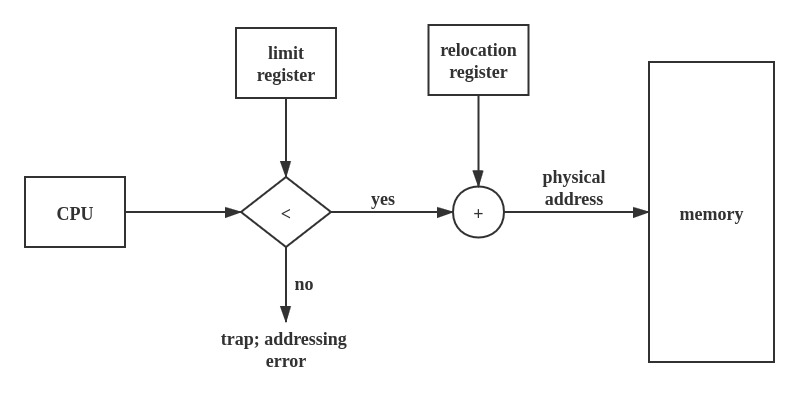
将上图这块称为MMU
Swapping
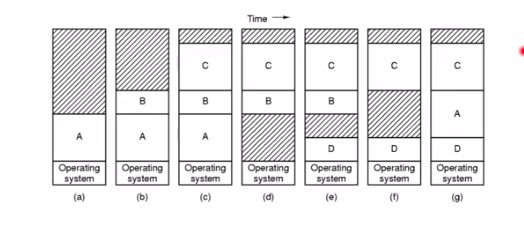
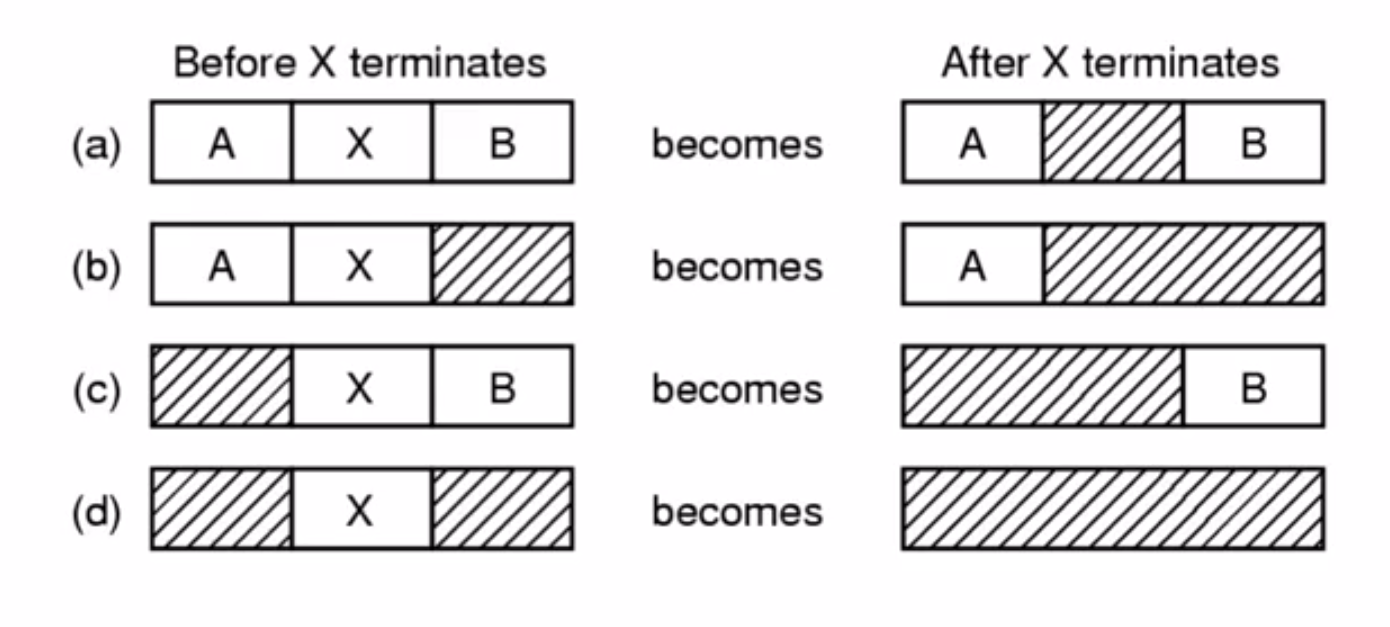
操作系统中的内存是动态分配的,如图所示:
- A进程启动,占用一部分内存
- B进程启动,占用一部分内存
- C进程启动,占用一部分内存
- A进程结束,又会将之前A占用的内存释放
- 随后又启动D进程,占用掉一部分内存
- B进程结束,释放掉B占用的内存
- 再启动A,这时又会划分给A一部分内存
这些动态的对内存的规划,就要用到swap交换内存,所以一般在linux系统中对交换分区的分区大小是和内存大小一致,或者内存的两倍,就是为了保证交换分区足够大,且高效。
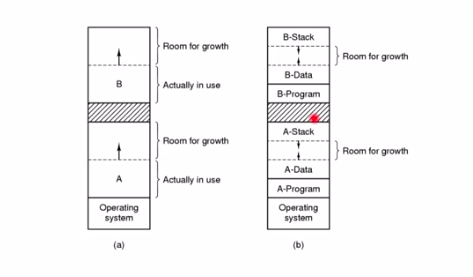
如b图,在程序A中,代码段存在A-Program中,是相对固定的大小。数据段A-Data挨着代码段,当new数据的时候数据段就会增长。在这个进程的地址空间的高端地址会放一个A-Stack,当每次调用一个函数,就会压入A-Stack中(压入栈的叫栈帧),当从函数退出的时候就会弹栈。当数据段和栈碰在一起的时候就溢出了。
Virtual memory
Memory Management with Bit Maps
Memory Management with Linked Lists
-
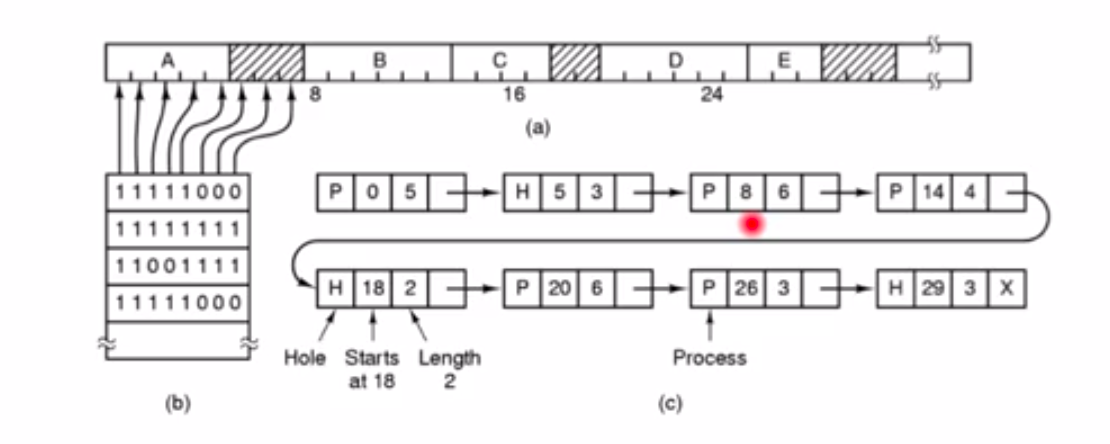
用Bit Map管理内存
如图(b),A、B、C、D、E表示进程,阴影表示未被分配的内存区域。将内存划分为一个一个的小块,如A进程占用了5个小块。在操作系统的内存中维护一张表map,表中每一个bit对应内存中的一个小块。入A进程与表的第一行的对应,如果该小块内存被占用就用1来表示,如果未被占用就用0来表示。这样维护一张Bit Map就可以管理内存。
-
拉一张链表来管理内存
如图(c),链表中一个结点有四个数据:第一个为P/H,如果是P则表示是进程在使用这块内存(Process),如果是H,则表示这块内存未被分配(Hole)。第二个为起始位置,表示这个结点所表示的这块内存的起始位置。第三个表示长度,表示这个结点所表示的内存所占用的长度。第四个指示下一个结点。
当进程所使用的内存被收回后,应该维护这个链表使得保持一致,不可能出现两个Hole连在一起,当一个进程被释放内存后,如果左右有Hole,应该将其合在一起,改变起始位置和长度。
Virtual Memory Paging
当运行一个占用内存很大的进程时,由于物理内存不够用就需要用到虚拟内存。把physical内存分成块,一会儿让这个进程的这部分用,一会儿让另外一部分用。这样就会产生一个类似于swap的从内存和硬盘里的转化的过程。

这里的MMU(Memory management unit)是将虚拟地址转化为实际的物理地址,转化的过程比最开始的那个复杂。首先得知道你要访问的内存在不在物理内存里面,如果不在physical memory里面,就把你要访问的地址在内存中找个地方加载进来,然后才再去访问它。把不存在的地址加载进内存这件事需要硬件来做,也需要操作系统(操作系统的一个功能——请求分页,用来支持虚拟内存的一个功能)来做。
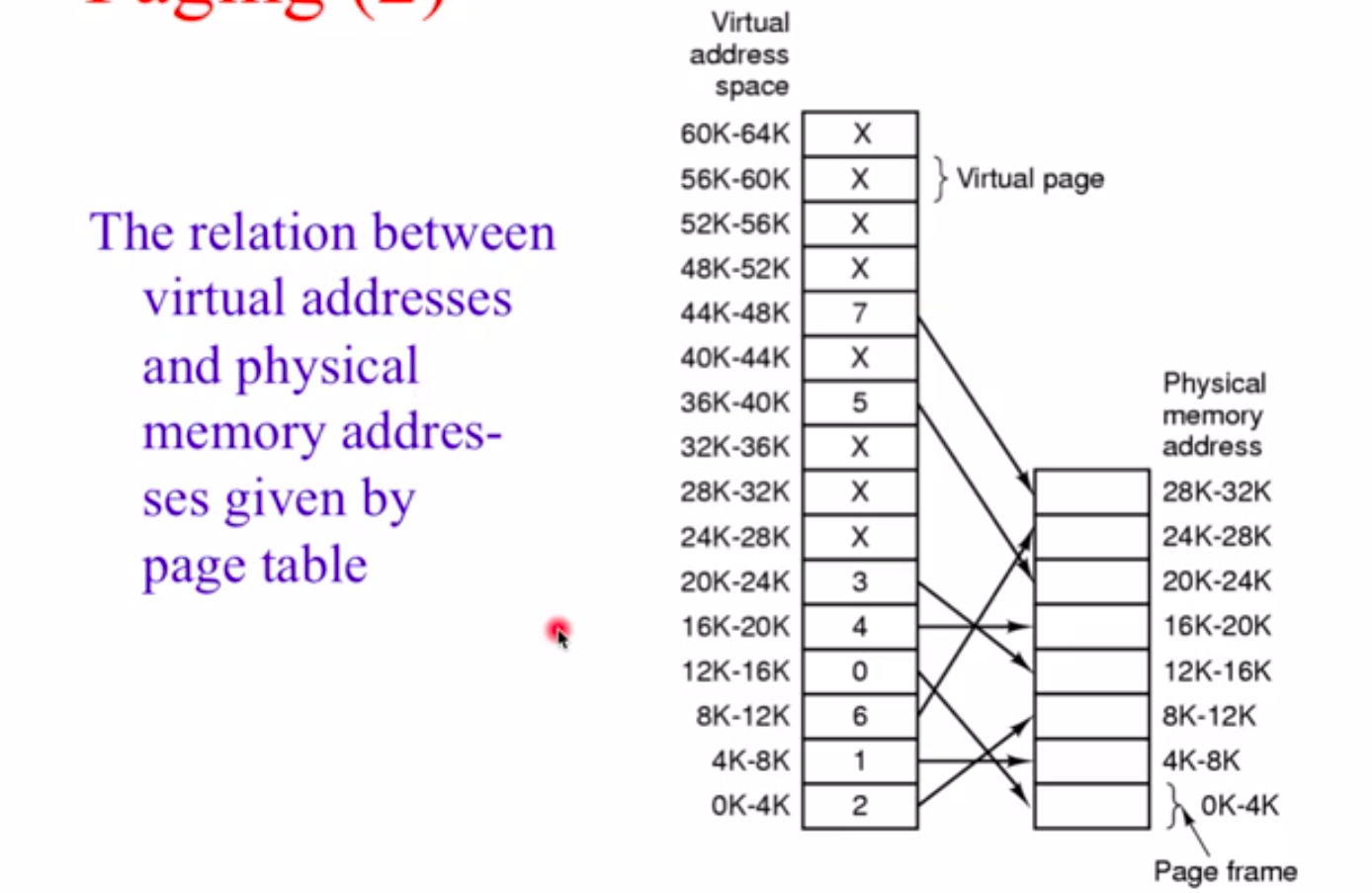
要知道这个进程里的哪些页在内存里面,哪些不在,如果在,在内存的什么地方,就需要用到虚拟内存里面用到的一个技术——分页(Paging)。MMU会和分页结合起来完成这个虚拟内存。
分页,就是把内存分成固定大小的页帧,把进程里面访问的空间也分成一个一个的页,每个页对应一个页帧,每一个页帧在物理内存可以是不连续的,但是有一个办法可以知道页到页帧之间的转换,这个机制就叫页表(页表存放在操作系统里面)。每个进程都有一个PCB,PCB里有一个数据结构就指向这个进程的页表,每个进程要运行都要一个页表,每个进程的页表都是不一样的。
Address Translation Architecture
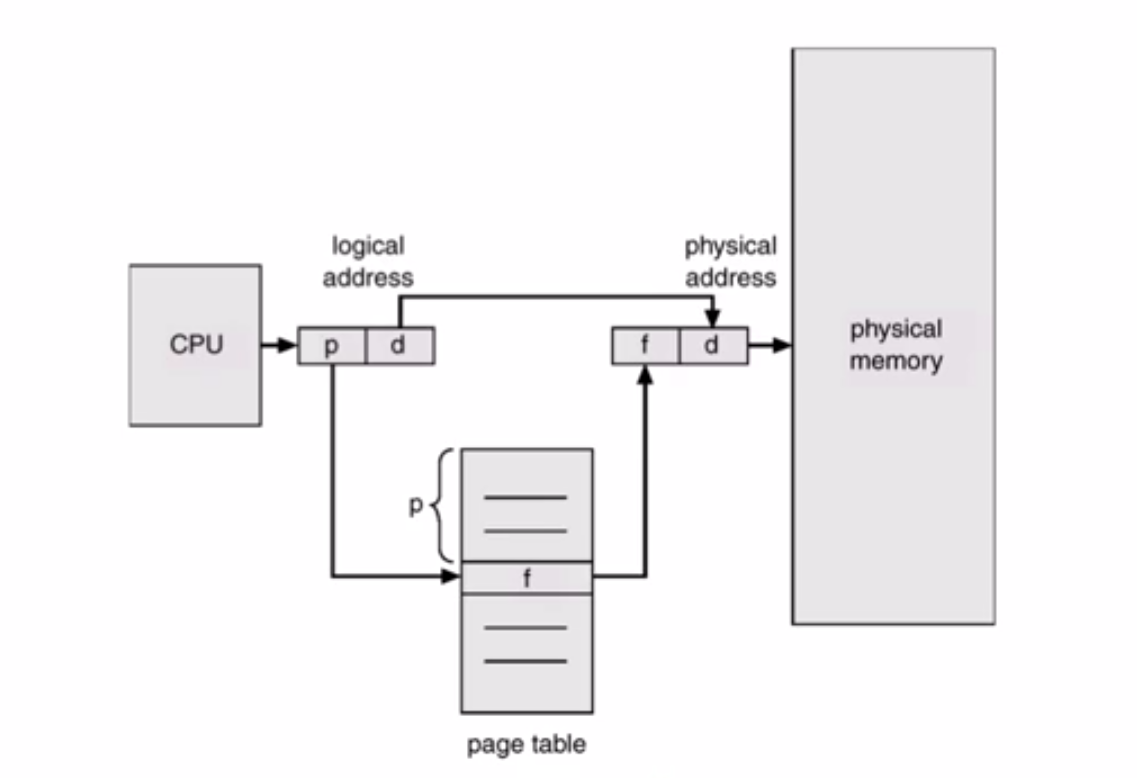
logical address也就是虚拟地址,是一个二进制数,低位d表示偏移量直接拿过去,拿到高位(就是p,页帧的编号),在page table中把p作为下表找到对应的f,和刚刚的d拼到一块就是物理地址。
这张page table是操作系统在加载这个进程的时候建起来的,把这个进程需要用到的页都加载进这个表。
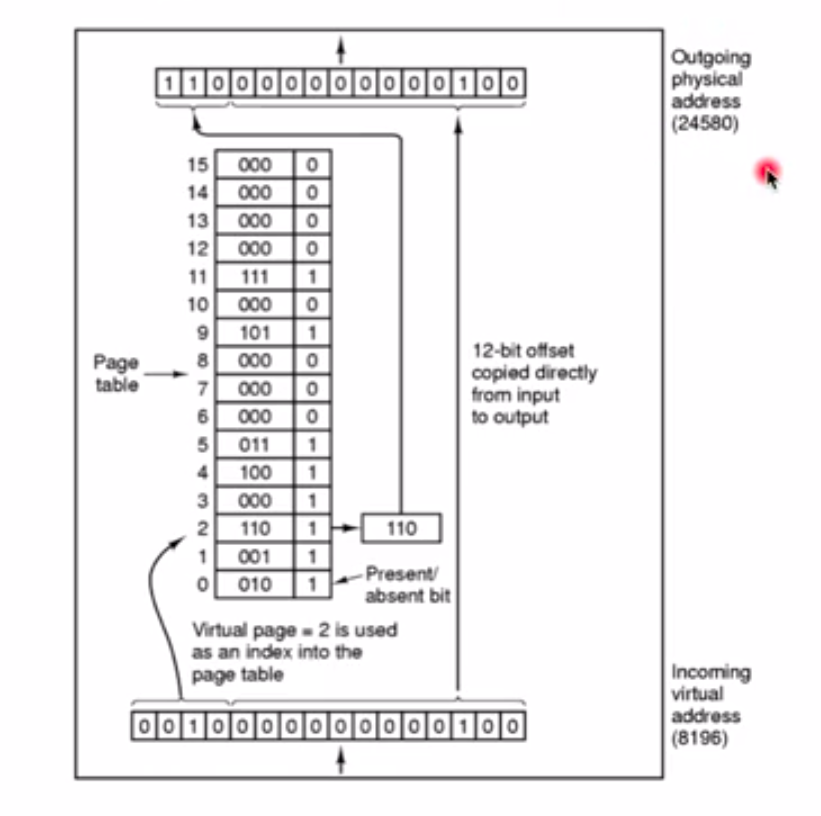
缺页中断:page table里的f并不是都建好,它是建了一部分,所以有可能会出现:用逻辑地址p查表发现f没有,也就是说要访问的物理页不在内存里面,这个时候就会产生缺页中断。就会跑到操作系统里,操作系统就会找到一块内存,然后把要访问的页从磁盘里面放到内存里面,然后把这个地址填上,重新执行这条指令。
下图是一个MMU,下面是逻辑地址,上面的是物理地址。实际的page table并不是和图中一样只有两部分,Present/absent表示这一项所对应的物理地址在或者不在,1表示在,0表示不在,不在就会产生缺页中断。
Internal operation of MMU with 16 4KB pages
实际图中偏移量的比特决定了页面的大小,比如下图的偏移量是12个bits,所以页面大小为4Kb(12个bit,就是2^12 = 1024*4,1 kb = 1024 bit,所以就是4kb了),如果是13个bits,那就就要double一下,即8Kb。
由于页表也在内存中,所以这种方式需要访问两次内存:第一次查表找到实际的物理地址,第二次访问真正的内存。所以在时间上会稍慢一些。
上面的方案是查的时候先有一个页帧的编号,再有一个偏移量,但这时候进程的页表会很大,很多时候页表中很多项都没有加载到内存里面,那些项在操作系统内存中占着,但是没有数据,没有对应关系,占的空间会很大。所以将页表分为二级页表。
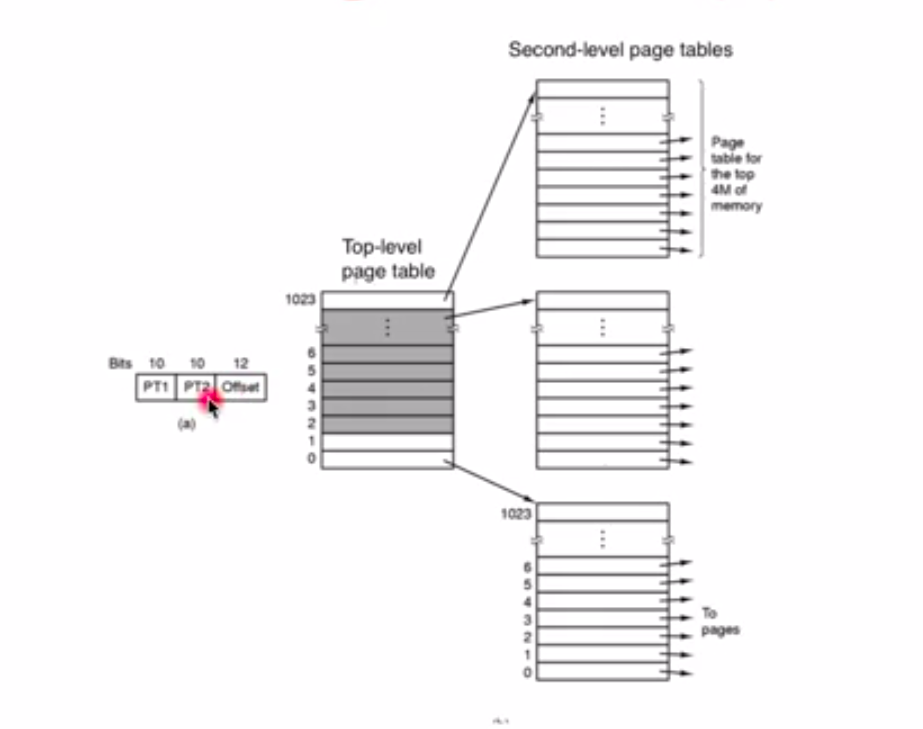
二级页表的PT1是页目录(Top-level page table)的下标,用它可以找到页表的位置,再用PT2在找到的页表中找到页帧,再结合偏移量offset找到physical memory。
PT1对应的页表在内存中的位置可以是空的,所以Second-level page table里的某些表可以不放在内存里面,也就是用Top-level page table里的一项代替Second-level page table里的一张表,减少了内存的大小。当然还可以分成三项、四项......但是这样的话所访问内存的次数就会增加,所以是用时间换取空间。
Typical page table entry
下图是一个典型的页表项,表示一个页表项可以存什么信息。
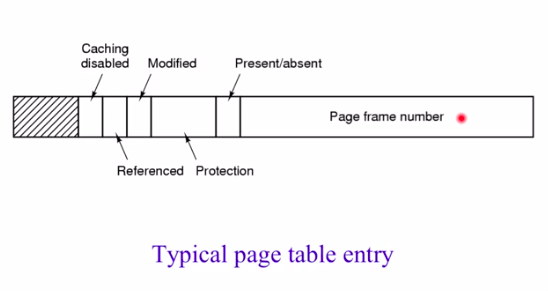
- Present/absent:占一个bit位,如果是0表示这一页在内存中不存在,如果是1表示在内存中存在
- Page frame number:如果Present/absent为1,则表示这一页的页帧,如果为0,则表示这一也在swap分区(硬盘中)中的位置。
- Protection:保护位,保存一些保护信息,表明这个页的权限信息,比如:只读的、读写的......
- Modified:如果物理页帧做过修改,就将这个位置位。
- Referenced:每次对这个页面访问的时候,就会置这个位,用来表示这个页面有没有被访问过
- Caching disabled:是否允许cache这个页
TLBs——Translation Lookaside Buffers
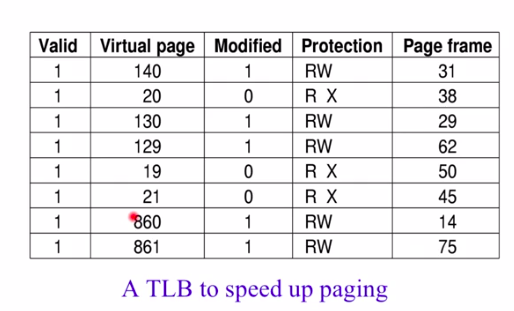
为了提高效率,在MMU的这一套硬件系统里加了一个cache(TLB),在一个进程中第一次通过逻辑页查找,查到页帧(Page frame)、Protection、Modified,然后将其存到这个TLB中,等下次访问这个逻辑页的时候就不用去查表,直接在TLB中就可以返回页帧,以达到加速查找。TLB中还有一项Valid,如果为0则表明这一项是无效的,是1才是有效的。
可以看出这一张TLB中所有的Virtual page是针对一个进程的,所以当出现进程切换,这整个TLB的内容全就无效了,因为不同进程的对应关系也不同。所以进程切换的开销很大。进程也因为这个TLB所以越跑越快,因为整个表建立好后就快速了。
Inverted Page Tables
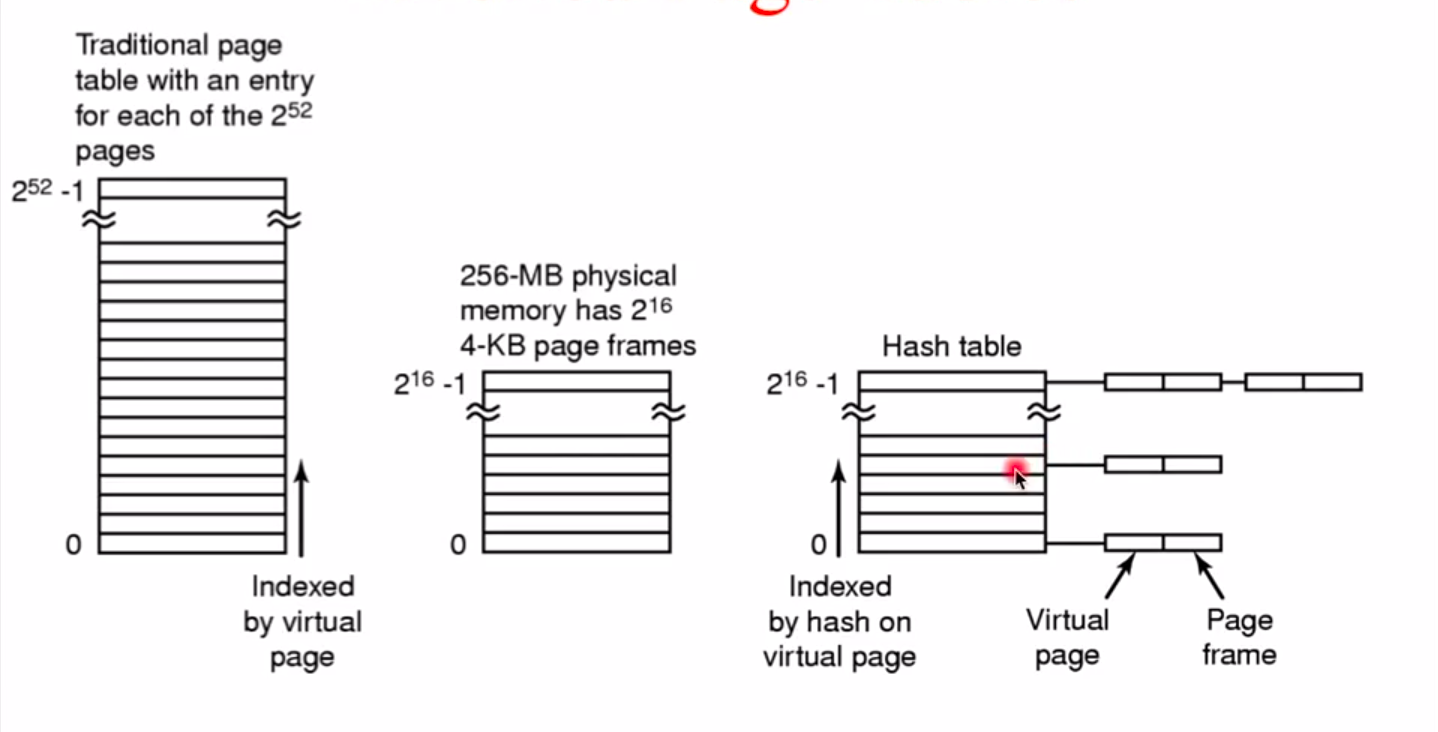
原来的是根据逻辑页去查找实际的物理页,最左边的图,表中有2^52个页,根据逻辑地址去找,找到某一项。这样的话,这样的页表是针对每个进程都有这样一个页表,这样一个页表中可能大部分的项都是空的。
反向页表,假如只要256MB的物理地址,就有2^16个4KB大小的page frames(页帧),那么就看这么多物理的页帧到底是哪个虚拟的页或者哪个进程在用的,把Virtual page做一个hash得到一个hash值,hash的范围就这个物理的页帧的范围里面,得到hash值后就能找到一个列表,这个列表里面就对应了一个Virtual page和physical page 的对应关系。如果hash出来这个值找到了一个链表(至于为什么是链表,是为了解决hash冲突),那就找到了这个物理页和逻辑页的对应关系,如果没找到就说明这个逻辑页不存在。
Page replacement algorithms
Optimal Page Replacement Algorithm
最优的页面替换算法就是能看到未来,被替换的页面是内存中未来被使用最少的页面,但这种算法虽然是最优的,却是不可实现的,因为未来是无法预知的。这个算法可以用来评估其他的算法。
Not Recently Used Page Replacement Algorithm
- Each page has Reference bit,Modified bit
- bits are set when page is referenced, modified。当这个页面被访问的时候就将referenced位置1,当这个页面被修改的时候就将Modified置1。
- 这两个位也可能被清。比如后台运行的page Demain的程序,周期扫描这个页表,当发现某些被modified,就尝试把这些页回写到磁盘里,然后将Modified清0。
- 有时候也会定期的把reference清0,配合页面替换算法,清的时间是知道的,当下次查这个reference的时候发现又被置1,说明至少在清的时间到再次查的时间里被访问过。
- Page are classified(分类)
- not referenced,not modified
- not referenced,modified(这里做一个解释:有可能被访问且修改后,referenced被清0了,但modifies没有被清,也就是没写到磁盘里去)
- referenced,not modified
- referenced,modified
- NRU removes page at random
- from lowest numbered non empty class
- 就是按上面分的类,从低到高替换(非空的)。
FIFO Page Replacement Algorithm
比较简单,就是维护一个LinkedList,按页面进入内存的顺序将这写页面链接起来,每次替换的时候替换掉最先进入到内存的页面,这种虽然简单但并不实用。
Second Chance Page Replacement Algorithm
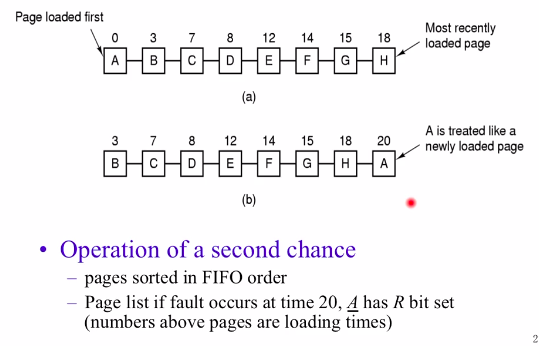
基于前面的FIFO Page Replacement Algorithm,A页面是最先进入到内存的页面,当需要替换页面的时候找到A,然后检查A的Referenced位,如果被置1,则将A放到队尾并将Referenced清0,若此时的队头是B,且B的R位没有被置则将其替换。
等到再次轮到A的时候,发现A的R位没有被置就说明在这段时间里A没有被访问过。这就相当于给了A第二次机会,所以叫Second Chance Page Replacement Algorithm。
The Clock Page ReplacementAlgorithm
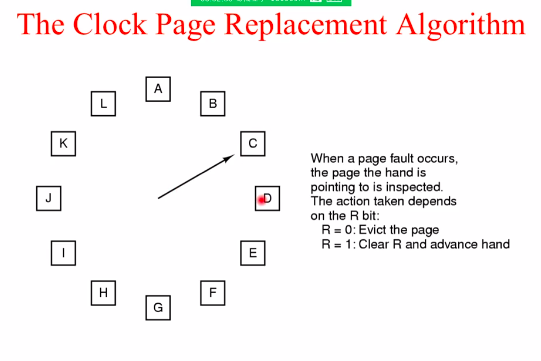
用一个指针指向一个页面,当发生缺页需要替换的时候先判断指针指向的页的R位是否为1,如果为1则清0,将指针挪到下一个页面上,再判断如果为1继续清0挪指针呢,如果为0则将其替换。不同于Second Chance的是没有维护一个以时间为标准的队列,但也给了第二次机会。
Least Recently Used(LRU)
这个算法是每次替换的都是很长时间未被使用的页面,一种可能的实现方法就是维护一个链表,但每次访问内存都要更新这个链表开销过大。还有一种方法上就是给page table加一项count,每次访问这个页面就给count++,通过这个count来表示这个页面被访问的次数。
Simulating LRU in Software (1)

一个数组,当访问页面x的时候,将第x行全部置为1,第x列全部置为0,按此顺序模拟0、1、2、3、2、1、0、3、2、3,可以观察到到d图时第0行已经全部变为0,说明当一个页面很久不被访问的时候会由于其他页面被访问而将其所在行的“1”一列一列的全部置为0,由此可以根据某个页面所在行的大小判断是否替换这个页面。
可能会有这个疑问:如果访问完页面a,然后一直访问页面b,那么多次访问过b后,a也是很久没有访问,但其所在行加起来还是很大。这个属于理解错误,如果一直访问同一个页面那根本就不用用到页面替换算法啊,页面替换是当要访的页面不在内存中产生缺页的时候才用的,一直访问同一个页面那最多发生一次页面替换,之后这个页面肯定已经存在与内存中了。
Simulating LRU in Software (2)

在第一个时间里针对0-5的页面的R位是101011,在下面第一个列图中表示出来,表示在这段时间里页面0、2、4、5被访问,下一个周期的访问情况为110010,将前面的记录情况向右平移一位,将最新的加到最前面。这样五个周期下来,(e)图表示了这五个周期里这6个页面被访问的情况。
如果把每个页面的bit pattern当作一个二进制数来看,这个数越大就说明这个页面最近被访问的越多,每次最近一个周期被访问的情况被放到最前面,表示某次被访问的情况是随着时间的推移,它的权重也慢慢降低的。
The Working Set Page Replacement Algorithm
工作集:一个进程当前正在使用的页面的集合称为它的工作集。设集合w(k,t),在任一时刻t,都存在一个集合w,它包含所有最近k次内存访问所访问的页面。这个集合w(k,t)就叫工作集。
横轴为k
现在来看一个基于工作集的页面替换算法,基本思路就是:找出一个不在工作集中的页面并替换掉它。

扫描所有页面检查R位,如果为1,则说明这次缺页中断发生的时候该页面正在被使用,所以可以将上次使用的时间切换为当前的实际时间,这个页面在当前的时钟滴答周期中被访问过,那么它就应该出现在工作集中,并且不应该被删除。
如果R为0,且生存时间(即当前实际运行时间减去上次使用时间)大于x,那就说明已经有超过x的时间没有使用这个页面了,那它就不应该出现在工作集里,所以将其移除。
如果R为0,且生存时间小于x,那就说明x时间段内这个页面至少使用过一次,但是要记录生存时间最长的页面,也就是“上次使用时间”最小的页面,也就是站在现在这个时间使用最早的页面。如果扫描完整个页表却没有一个合适的被淘汰的页面,那就淘汰生存时间最长的页面。
WSClock Page Replacement Algorithm
当缺页中断发生后,需要扫描整个页表才能确定淘汰的页面,因此基本的工作集算法是比较费时的。有一种基于时钟算法的改进算法,并且使用了工作集信息,成为WSClock(工作集时钟)算法。
与时钟算法一样,所需的数据结构是一个以页框为元素的循环表。最初,该表是空的。当装入第一个页面后,把它加入到该表中。随着更多的页面的加入,他们形成一个环。每个表项包含来自基本工作集算法的上次使用时间,以及R位(已标明)和M位(未标明)。
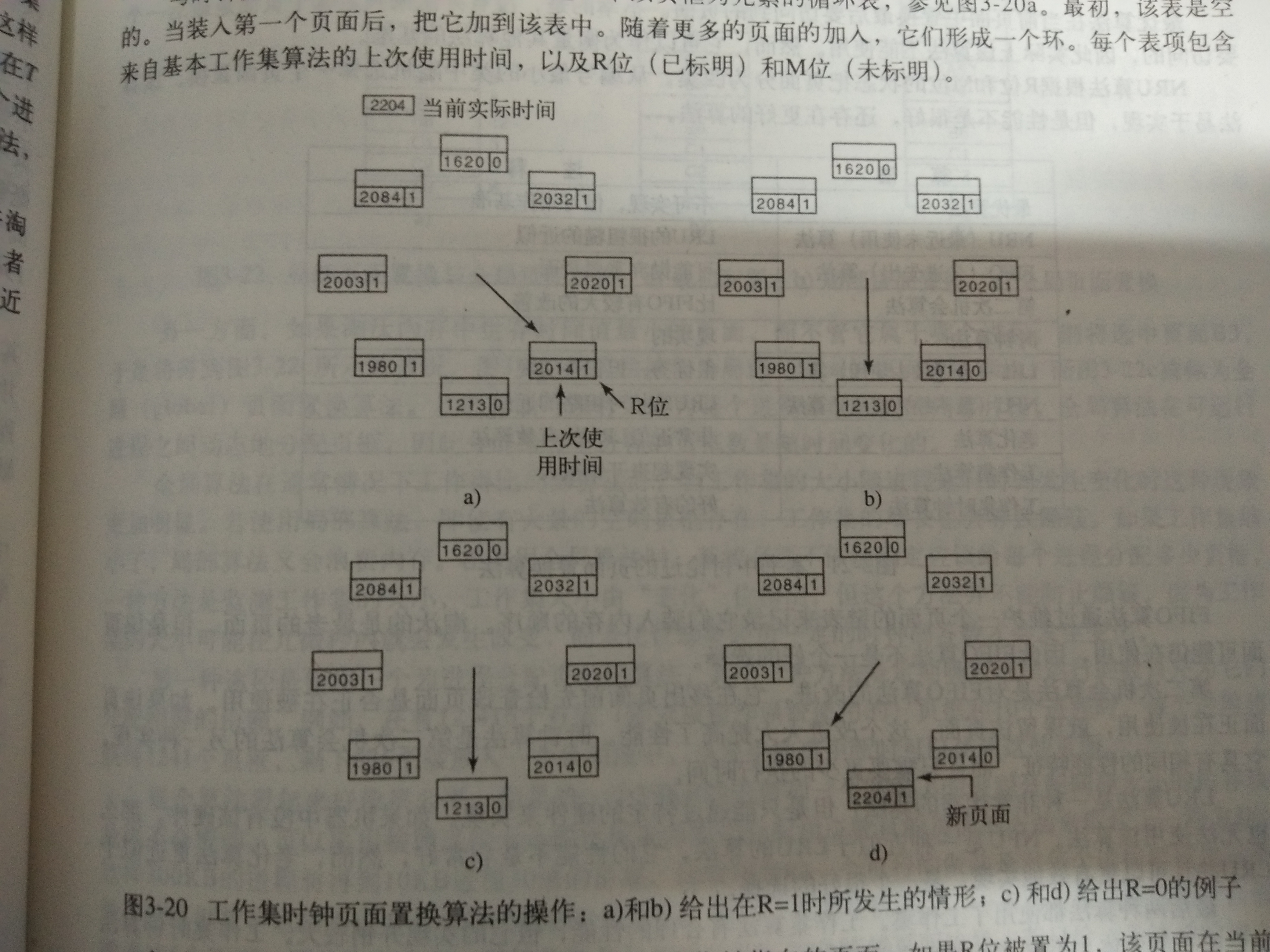
与时钟算法一样,每次缺页中断的时候,首先检查指针指向的页面。如果R位为1,则该页面在当前的时钟滴答中被使用过,则不适合淘汰,将其置0,指针指向下一个页面。并重复该算法。
如果R=0,当页面的生存时间大于x并且该页面是干净的(干净,个人理解就是没有修改过),他就不在工作集中,并且在磁盘上有一个有效的副本。申请此框,并把新页面放在其中。如果此页面被修改过就不能立即申请页框,因为这个页面在磁盘上没有有效的副本。为了避免由于调度写磁盘操作引起的进程切换,指针继续向前走,算法继续对下一个页面操作。比较,有可能存在一个旧的且干净的页面可以立即使用。
页面置换算法小结
| 算法 | 注释 |
|---|---|
| 最优算法 | 不可实现,但可以用作基准 |
| NRU(最近未使用)算法 | LRU的很粗糙的近似 |
| FIFO(先进先出)算法 | 可能抛弃重要页面 |
| 第二次机会算法 | 比FIFO有较大改善 |
| 时钟算法 | 现实的 |
| LRU(最近最少使用)算法 | 很优秀,但很难实现 |
| NFU(最不经常使用)算法 | LRU的相对粗略的近似 |
| 老化算法 | 非常近似LRU的有效算法 |
| 工作集算法 | 实现起来开销很大 |
| 工作集时钟算法 | 好的有效算法 |
Modeling Page Replacement algorithms

(a)图是FIFO with 3 page frames
(b)图是FIFO with 4 page frames
如图,横轴上0、1、2、3、0、1、4、0、1、2、3、4是页面的访问顺序,竖轴是已经存在的物理的页,(a)图中,先访问第0页,内存中没有,所以产生缺页中断,最下面用P标识,类似于一个堆栈,每当访问一个新的页面就向下压栈,访问第1页,内存中也没有,向下压栈,产生缺页中断,用P标识,以此类推,一致向下压栈,最下面的会被挤出去......当8次访问第0页时,内存中已经存在第0页,所以不会产生缺页中断。
(b)图同理(a)图,但不同的是b图中有4个物理的页,通过观察发现,(a)图中三个物理的页产生了9次缺页中断,而(b)图中4个物理的页却产生了10次缺页中断。事实并没有像预想的一样物理的页越多产生的缺页中断越少。这就叫Belady's Anomaly。
要避免Belady's Anomaly的产生,就要保证物理页多的里面放入的内容是物理页少的里面内容的超集(也就是物理页少的里面的内容是物理页多的里面的内容的子集),这样,物理页越多产生的缺页就越少。图中的FIFO算法很明显并不能保证这个前提。例如第8次访问页面a图里是4、1、0,b图里是0、4、3、2.
Stack Algorithm
要保证上述的前提,引入了stack算法
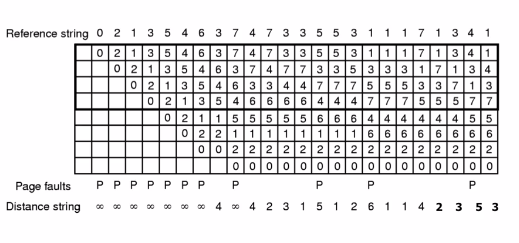
前面的Reference string是访问页,下面的8个框是可以存放的堆栈页,上面四个实框是真正的物理页,每次访问一个页面的时候就往里面压栈,到第5次访问第5页的时候相当于把0从物理页挤出去了,但还存在于堆栈页中,当第8次访问第3页时,3还在里面,就把堆栈中的3提前,不产生缺页中断,然后继续类推,到第14次访问第5页的时候,5在堆栈页中,但已经出了物理页,所以会产生缺页中断,但还是同样的将5提前,原来5上面的压栈压下去。下面的P表示产生了缺页。Distance string表示的是当前访问的页在上次访问内存后在堆栈中的第几个,比如第14次访问的第5页,在第13次访问完后,第5页在5个,所以第14次的Distance string就等于5,如果上次访问内存后堆栈页中没有这次访问的页就将Distance string等于无穷。
Probability density function
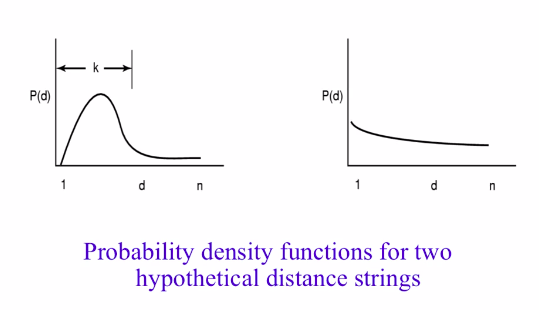
pdf表示概率密度函数,横轴为distance string,纵轴表示等于这个distance string的有多少个
The Distance String
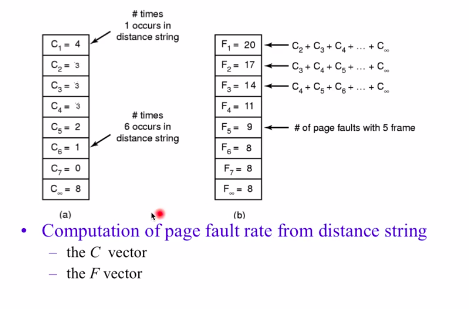
用distance string计算页面出错率。左边的C1就表示distance string等于1的有几个,C2同理表示distance string等于2的有几个。右边的F1表示C2+C3+...+C无穷,同理F2 = C3+C4+...+C无穷。
因此可以看出F1表示当有一个物理页时候的缺页次数,F2表示当有2个物理页时候的缺页次数。因为F1表示的是C2到C无穷的累加和,而C2又表示distance string=2时候的个数,distance string=2的就表示当前访问的页在堆栈页的第二个,如果物理页只有一个那就说明不在物理页中,即会产生缺页,C3、C4......C无穷类似。即Fx表示当有x个物理页时候的缺页次数。
Segmentation
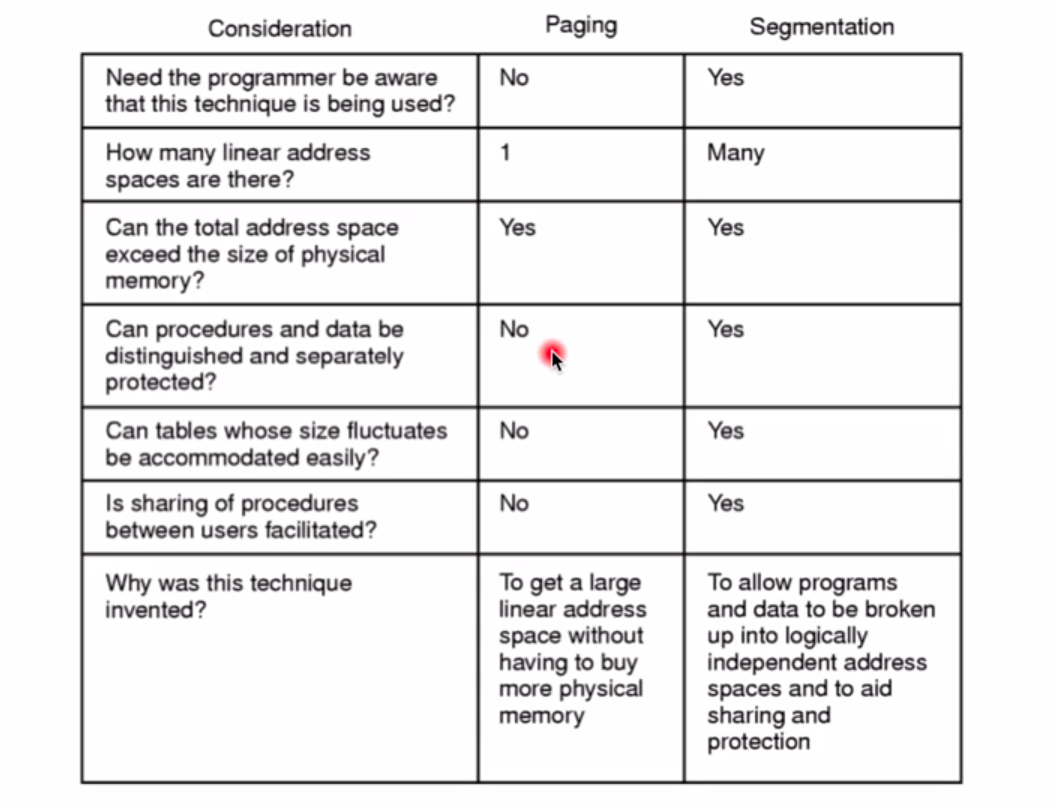
分段和分页的一些对比
Implementation of Pure Segmentation
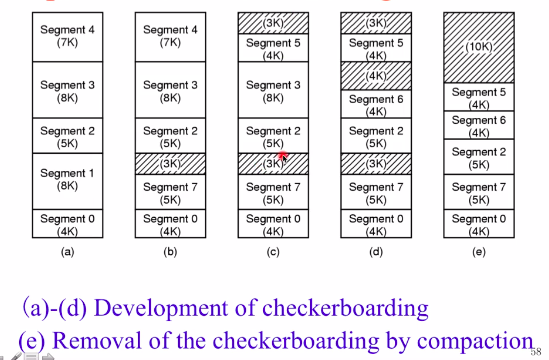
Segmentation with Paging:MULTICS
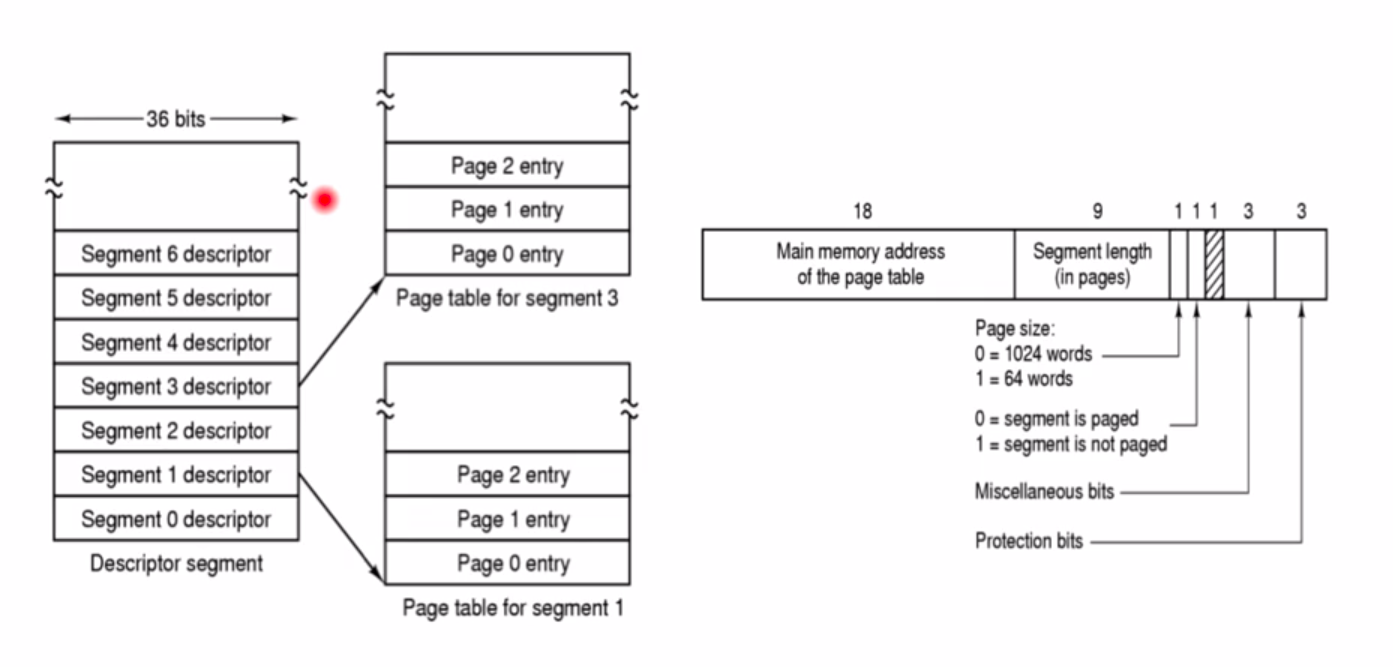
段页式,在段里分页。前面分页是一个进程一个页表,现在这种分段是一个段一个页表。
段的描述字descriptor的结构如图右所示,18个bit位的Main memory address of the page table,用来表示这个段的页表在内存中的地址;9个bit位的Segment length表示段的长度,以页为单位,就是这个段有多少个页;1个bit位的Page size,表示页的大小,1024个或64个words;还有表示段是否启动分页的位,如果没启动就是纯分段,启动了就是段页式。
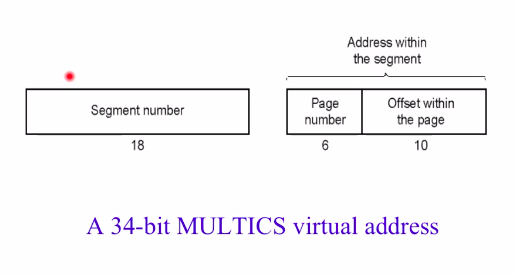
上图是一个34个bit位的虚拟地址,根据18个bit的段号去查表(就是上面的上面那个图的最左边那个表),找到段的页表,根据后面6个bit的页号,在页表中找到具体的物理页的位置(页帧),最后根据10个bit的页内偏移就可以找到真正的物理地址。
为了加速查找,同样引入了TLB。

TLB中Segment number和Virtual page配合可以找到Page frame,Protection位表示读写权限,Age表示老化程度,因为TLB中的项是有限的,当需要淘汰掉某些项的时候,就根据项的老化程度,越大说明在TLB中时间越久。is this entry used表示这个项在不在内存里面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号