

Java 操作 Hadoop 的 Mapreduce 数据处理
1.导入pom依赖
<properties> ...... <hadoop.version>3.1.2</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> ...... </dependencies>
2.基本使用
a.创建 test1.txt 文件用于统计
hello zhangsan
lisi nihao
hi zhangsan
nihao lisi
x xiaoming
b.创建 Mapper
/** * 这部分的输入是由mapreduce自动读取进来的 * 简单的统计单词出现次数<br> * KEYIN 默认情况下,是mapreduce所读取到的一行文本的起始偏移量,Long类型,在hadoop中有其自己的序列化类LongWriteable * VALUEIN 默认情况下,是mapreduce所读取到的一行文本的内容,hadoop中的序列化类型为Text * KEYOUT 是用户自定义逻辑处理完成后输出的KEY,在此处是单词,String * VALUEOUT 是用户自定义逻辑输出的value,这里是单词出现的次数,Long */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //这是mapreduce读取到的一行字符串 String line = value.toString(); String[] words = line.split(" "); for (String word : words) { //将单词输出为key,次数输出为value,这行数据会输到reduce中 context.write(new Text(word), new LongWritable(1)); } } }
c.创建 Reducer
/** * 第一个Text: 是传入的单词名称,是Mapper中传入的 * 第二个:LongWritable 是该单词出现了多少次,这个是mapreduce计算出来的,比如 hello出现了11次 * 第三个Text: 是输出单词的名称 ,这里是要输出到文本中的内容 * 第四个LongWritable: 是输出时显示出现了多少次,这里也是要输出到文本中的内容 * */ public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0; for (LongWritable num : values) { count += num.get(); } context.write(key, new LongWritable(count)); } }
d.使用
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; public class TestMain { private static final String HDFS_PREFIX = "hdfs://localhost:9527"; private static FileSystem fs; /** * 上传测试文件到HDFS文件系统 */ public static void doBeforeWork(String sourceFilePath, String inFile, String outDir) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", HDFS_PREFIX); // 对应 core-site.xml 中配置的端口 // 拿到操作HDFS的一个实例,并且设置其用户(由于windows权限问题"zwj"需替换为管理员账号) fs = FileSystem.get(new URI(HDFS_PREFIX),conf,"zwj"); FSDataOutputStream fout = fs.create(new Path(inFile), true); InputStream in = new FileInputStream(sourceFilePath); IOUtils.copyBytes(in, fout, 1024,true); //删除结果文件夹 fs.delete(new Path(outDir), true); } /** * 打印结果 */ public static void doAfterWork(String outFilePath) throws Exception { FSDataInputStream fin = fs.open(new Path(outFilePath)); IOUtils.copyBytes(fin, System.out, 1024,true); } /** * 运行 */ public static void run(String inFilePath, String outFilePath) throws Exception{ Configuration conf = new Configuration(); //如果是打包在linux上运行,则不需要写这两行代码 // //指定运行在yarn中 // conf.set("mapreduce.framework.name", "yarn"); // //指定resourcemanager的主机名 // conf.set("yarn.resourcemanager.hostname", "localhost"); Job job = Job.getInstance(conf); //使得hadoop可以根据类包,找到jar包在哪里 job.setJarByClass(TestMain.class); //指定Mapper的类 job.setMapperClass(WordCountMapper.class); //指定reduce的类 job.setReducerClass(WordCountReduce.class); //设置Mapper输出的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //设置最终输出的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定输入文件的位置 FileInputFormat.setInputPaths(job, new Path(inFilePath)); //指定输入文件的位置 FileOutputFormat.setOutputPath(job, new Path(outFilePath)); //将job中的参数,提交到yarn中运行 // job.submit(); try { job.waitForCompletion(true); //这里的为true,会打印执行结果 } catch (ClassNotFoundException | InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) { try { String sourceFilePath = "E:/tmp/test1.txt"; String inFile = "/mydir/test1.txt"; String inFileUrl = HDFS_PREFIX + inFile; String outDir = "/outdir"; String outDirUrl = HDFS_PREFIX + outDir; String outFileUrl = outDirUrl + "/part-r-00000"; doBeforeWork(sourceFilePath, inFile, outDir); run(inFileUrl, outDirUrl); doAfterWork(outFileUrl); }catch (Exception e){ e.printStackTrace(); } } }
e.注意:若运行后报 "HADOOP_HOME and hadoop.home.dir are unset." 异常,则需要客户端也配置 HADOOP_HOME 环境变量,并重启电脑
3.数据分区
a.创建 test2.txt 文件用于统计
张三 江西 打车 200 李四 广东 住宿 600 王五 北京 伙食 320 张三 江西 话费 50 张三 湖南 打车 900 周六 上海 采购 3000 李四 西藏 旅游 1000 王五 北京 借款 500 李四 上海 话费 50 周六 北京 打车 600 张三 广东 租房 3050
b.创建开销实体类
public class SpendBean implements Writable { private Text userName; private IntWritable money; private Text province; public SpendBean(Text userName, IntWritable money, Text province) { this.userName = userName; this.money = money; this.province = province; } /** * 反序列化时必须有一个空参的构造方法 */ public SpendBean(){} /** * 序列化的代码 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { userName.write(out); money.write(out); province.write(out); } /** * 反序列化的代码 * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { userName = new Text(); userName.readFields(in); money = new IntWritable(); money.readFields(in); province = new Text(); province.readFields(in); } public Text getUserName() { return userName; } public void setUserName(Text userName) { this.userName = userName; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } public Text getProvince() { return province; } public void setProvince(Text province) { this.province = province; } @Override public String toString() { return "[SpendBean]: userName[" + userName + "], money[" + money + "], province[" + province + "]"; } }
c.创建 Mapper
public class GroupUserMapper extends Mapper<LongWritable, Text, Text, SpendBean> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String val = value.toString(); String[] split = val.split(" "); //这里就不作字符串异常的处理了,核心代码简单点 String name = split[0]; String province = split[1]; String type = split[2]; int money = Integer.parseInt(split[3]); SpendBean groupUser = new SpendBean(); groupUser.setUserName(new Text(name)); groupUser.setMoney(new IntWritable(money)); groupUser.setProvince(new Text(province)); context.write(new Text(name), groupUser); } }
d.创建 Reducer
public class GroupUserReducer extends Reducer<Text, SpendBean, Text, SpendBean> { /** * 姓名 * @param key * @param values * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException { int money = 0;//消费金额 //遍历 Text province = null; for(SpendBean bean : values){ money += bean.getMoney().get(); province = bean.getProvince(); } //输出汇总结果 context.write(key,new SpendBean(key, new IntWritable(money), province)); } }
e.创建分区 Partition
public class ProvincePartitioner extends Partitioner<Text, SpendBean> { private static Map<String,Integer> provinces = new HashMap<>(); static { //这里给每一个省份编制一个分区 provinces.put("江西",0); provinces.put("广东",1); provinces.put("北京",2); provinces.put("湖南",3); provinces.put("上海",4); provinces.put("西藏",5); } /** * 给指定的数据一个分区 * @param text * @param spendBean * @param numPartitions * @return */ @Override public int getPartition(Text text, SpendBean spendBean, int numPartitions) { Integer province = provinces.get(spendBean.getProvince().toString()); province = province == null ? 6 : province; //如果在省份列表中找不到,则指定一个默认的分区 return province; } }
f.使用
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; import java.util.ArrayList; import java.util.List; public class TestMain { private static final String HDFS_PREFIX = "hdfs://localhost:9527"; private static FileSystem fs; /** * 上传测试文件到HDFS文件系统 */ public static void doBeforeWork(String sourceFilePath, String inFile, String outDir) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", HDFS_PREFIX); // 对应 core-site.xml 中配置的端口 // 拿到操作HDFS的一个实例,并且设置其用户(由于windows权限问题"zwj"需替换为管理员账号) fs = FileSystem.get(new URI(HDFS_PREFIX),conf,"zwj"); FSDataOutputStream fout = fs.create(new Path(inFile), true); InputStream in = new FileInputStream(sourceFilePath); IOUtils.copyBytes(in, fout, 1024,true); //删除结果文件夹 fs.delete(new Path(outDir), true); } /** * 打印结果 */ public static void doAfterWork(List<String> outFilePathList) throws Exception { for(String outFilePath : outFilePathList){ FSDataInputStream fin = fs.open(new Path(outFilePath)); IOUtils.copyBytes(fin, System.out, 1024,false); System.out.println("======================================================================="); } } /** * 运行 */ public static void run(String inFilePath, String outFilePath) throws Exception { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(TestMain.class); //设置jar中的启动类,可以根据这个类找到相应的jar包 job.setMapperClass(GroupUserMapper.class); //设置mapper的类 job.setReducerClass(GroupUserReducer.class); //设置reducer的类 job.setMapOutputKeyClass(Text.class); //mapper输出的key job.setMapOutputValueClass(SpendBean.class); //mapper输出的value job.setPartitionerClass(ProvincePartitioner.class);//指定数据分区规则,不是必须要的,根据业务需求分区 job.setNumReduceTasks(7); //设置相应的reducer数量,这个数量要与分区的大最数量一致 job.setOutputKeyClass(Text.class); //最终输出的数据类型 job.setOutputValueClass(SpendBean.class); FileInputFormat.setInputPaths(job,new Path(inFilePath));//输入的文件位置 FileOutputFormat.setOutputPath(job,new Path(outFilePath));//输出的文件位置 boolean b = job.waitForCompletion(true);//等待完成,true,打印进度条及内容 if(b){ //success } } public static void main(String[] args) { try { String sourceFilePath = "E:/tmp/test2.txt"; String inFile = "/mydir/test2.txt"; String inFileUrl = HDFS_PREFIX + inFile; String outDir = "/outdir"; String outDirUrl = HDFS_PREFIX + outDir; doBeforeWork(sourceFilePath, inFile, outDir); run(inFileUrl, outDirUrl); List<String> outFileUrlList = new ArrayList(); for (int i = 0; i < 7; i++) { outFileUrlList.add(outDirUrl + "/part-r-0000" + i); } doAfterWork(outFileUrlList); }catch (Exception e){ e.printStackTrace(); } } }
4.数据排序
a.创建 test3.txt 文件用于统计
张三 2980 李四 8965 王五 1987 小黑 6530 小陈 2963 小梅 980
b.创建开销实体类,实现 WritableComparable,重写 compareTo 方法
public class Spend implements WritableComparable<Spend> { private Text name; //姓名 private IntWritable money; //花费 public Spend(){} public Spend(Text name, IntWritable money) { this.name = name; this.money = money; } public void set(Text name, IntWritable money) { this.name = name; this.money = money; } @Override public int compareTo(Spend o) { return o.getMoney().get() - this.money.get(); } @Override public void write(DataOutput out) throws IOException { name.write(out); money.write(out); } @Override public void readFields(DataInput in) throws IOException { name = new Text(); name.readFields(in); money = new IntWritable(); money.readFields(in); } public Text getName() { return name; } public void setName(Text name) { this.name = name; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return name.toString() + "," + money.get(); } }
c.创建 Mapper
public class SortMapper extends Mapper<LongWritable, Text, Spend, Text> { private Spend spend = new Spend(); private IntWritable moneyWritable = new IntWritable(); private Text text = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" ");//这里就不做异常处理了,只写核心逻辑 String name = split[0]; int money = Integer.parseInt(split[1]); text.set(name); moneyWritable.set(money); spend.set(text, moneyWritable); context.write(spend,text); } }
d.创建 Reducer
public class SortReducer extends Reducer<Spend, Text, Text, Spend> { @Override protected void reduce(Spend key, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(), key); } }
e.使用
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; public class TestMain { private static final String HDFS_PREFIX = "hdfs://localhost:9527"; private static FileSystem fs; /** * 上传测试文件到HDFS文件系统 */ public static void doBeforeWork(String sourceFilePath, String inFile, String outDir) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", HDFS_PREFIX); // 对应 core-site.xml 中配置的端口 // 拿到操作HDFS的一个实例,并且设置其用户(由于windows权限问题"zwj"需替换为管理员账号) fs = FileSystem.get(new URI(HDFS_PREFIX),conf,"zwj"); FSDataOutputStream fout = fs.create(new Path(inFile), true); InputStream in = new FileInputStream(sourceFilePath); IOUtils.copyBytes(in, fout, 1024,true); //删除结果文件夹 fs.delete(new Path(outDir), true); } /** * 打印结果 */ public static void doAfterWork(String outFilePath) throws Exception { FSDataInputStream fin = fs.open(new Path(outFilePath)); IOUtils.copyBytes(fin, System.out, 1024,true); } /** * 运行 */ public static void run(String inFilePath, String outFilePath) throws Exception { Configuration config = new Configuration(); Job job = Job.getInstance(config); job.setJarByClass(TestMain.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(Spend.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Spend.class); FileInputFormat.setInputPaths(job,new Path(inFilePath)); FileOutputFormat.setOutputPath(job,new Path(outFilePath)); boolean b = job.waitForCompletion(true); if(b){ //success } } public static void main(String[] args) { try { String sourceFilePath = "E:/tmp/test3.txt"; String inFile = "/mydir/test3.txt"; String inFileUrl = HDFS_PREFIX + inFile; String outDir = "/outdir"; String outDirUrl = HDFS_PREFIX + outDir; String outFileUrl = outDirUrl + "/part-r-00000"; doBeforeWork(sourceFilePath, inFile, outDir); run(inFileUrl, outDirUrl); doAfterWork(outFileUrl); }catch (Exception e){ e.printStackTrace(); } } }
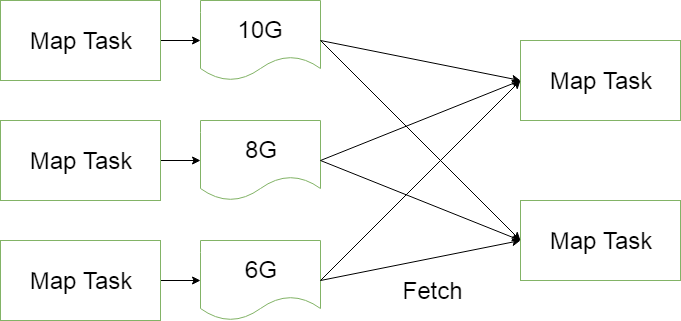
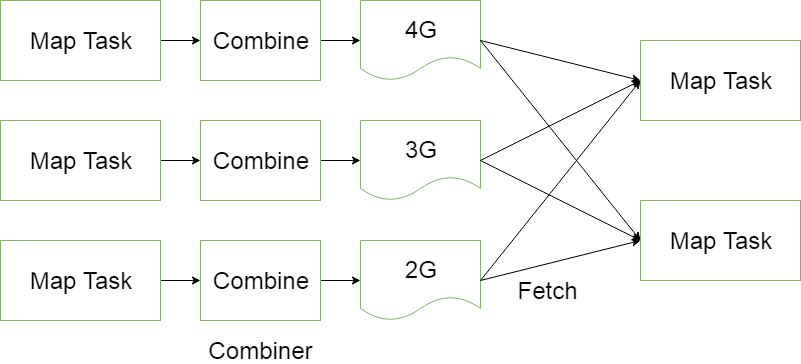
5.数据汇总(Combiner)
a.执行顺序:Mapper—Combiner—Reducer
b.作用:就是在各个map中预先进行一次,减少在reducer阶段的数据量,这样能提升很高的效率。
b.加入anjs中文分词依赖,用于分词(此依赖与Combiner无关)
<!-- anjs中文分词器 --> <dependency> <groupId>org.ansj</groupId> <artifactId>ansj_seg</artifactId> <version>5.1.1</version> </dependency>
c.创建 Mapper
public class StoryMapper extends Mapper<LongWritable, Text, Text, LongWritable> { private Text text = new Text(); private LongWritable longWritable = new LongWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString().trim(); //剔除空的一行 if(!StringUtils.isBlank(line)){ //分词的代码 Result parse = ToAnalysis.parse(line); List<Term> terms = parse.getTerms(); Iterator<Term> iterator = terms.iterator(); while (iterator.hasNext()){ Term term = iterator.next(); longWritable.set(1); text.set(term.getName()); context.write(text,longWritable); } } } }
d.创建 Reducer
public class StoryReducer extends Reducer<Text, LongWritable, LongWritable, Text> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { Iterator<LongWritable> iterator = values.iterator(); long num = 0; while (iterator.hasNext()){ LongWritable longWritable = iterator.next(); num += longWritable.get(); } context.write(new LongWritable(num),key); } }
e.创建Combiner
public class StoryCombiner extends Reducer<Text, LongWritable, Text, LongWritable> { private LongWritable longWritable = new LongWritable(); @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { Iterator<LongWritable> iterator = values.iterator(); long num = 0; while (iterator.hasNext()){ LongWritable longWritable = iterator.next(); num += longWritable.get(); } longWritable.set(num); context.write(key, longWritable); } }
f.使用
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; public class TestMain { private static final String HDFS_PREFIX = "hdfs://localhost:9527"; private static FileSystem fs; /** * 上传测试文件到HDFS文件系统 */ public static void doBeforeWork(String sourceFilePath, String inFile, String outDir) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", HDFS_PREFIX); // 对应 core-site.xml 中配置的端口 // 拿到操作HDFS的一个实例,并且设置其用户(由于windows权限问题"zwj"需替换为管理员账号) fs = FileSystem.get(new URI(HDFS_PREFIX),conf,"zwj"); FSDataOutputStream fout = fs.create(new Path(inFile), true); InputStream in = new FileInputStream(sourceFilePath); IOUtils.copyBytes(in, fout, 1024,true); //删除结果文件夹 fs.delete(new Path(outDir), true); } /** * 打印结果 */ public static void doAfterWork(String outFilePath) throws Exception { FSDataInputStream fin = fs.open(new Path(outFilePath)); IOUtils.copyBytes(fin, System.out, 1024,true); } /** * 运行 */ public static void run(String inFilePath, String outFilePath) throws Exception { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(TestMain.class); job.setMapperClass(StoryMapper.class); job.setReducerClass(StoryReducer.class); job.setCombinerClass(StoryCombiner.class);//设置Combiner job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path(inFilePath)); FileOutputFormat.setOutputPath(job,new Path(outFilePath)); boolean b = job.waitForCompletion(true); if(b){ //success } } public static void main(String[] args) { try { String sourceFilePath = "E:/tmp/test4.txt"; String inFile = "/mydir/test4.txt"; String inFileUrl = HDFS_PREFIX + inFile; String outDir = "/outdir"; String outDirUrl = HDFS_PREFIX + outDir; String outFileUrl = outDirUrl + "/part-r-00000"; doBeforeWork(sourceFilePath, inFile, outDir); run(inFileUrl, outDirUrl); doAfterWork(outFileUrl); }catch (Exception e){ e.printStackTrace(); } } }
6.参考文章:https://www.cnblogs.com/zhuxiaojie/p/7224772.html

