豆瓣top250影片爬取信息和数据可视化
一、项目简介
1.1 项目博客地址
https://www.cnblogs.com/venus-ping/
1.2 项目完成的功能与特色
利用爬虫对豆瓣评分top250的电影进行爬取,获取电影相关信息,并对获取到的数据进行数据分析。通过数据可视化,将数据具体化更加直观地了解电影信息。实现的模块功能有:
① 抓取top250电影的上映时间、国家、评分、类型、评价人数、导演、参演演员信息;
② 豆瓣top250电影评价人数统计柱状图
③ Top250电影导演作品数top10统计柱状图
④ Top250电影中评论top20统计柱状图
⑤ Top250电影类型数量占比饼图
⑥ Top250影片作品评分折线图
⑦ Top250影片华语电影类型数量圆形图
⑧ Top250影片作品上映年份统计柱状图
⑨ 2000年top250影片上映类型统计环形图
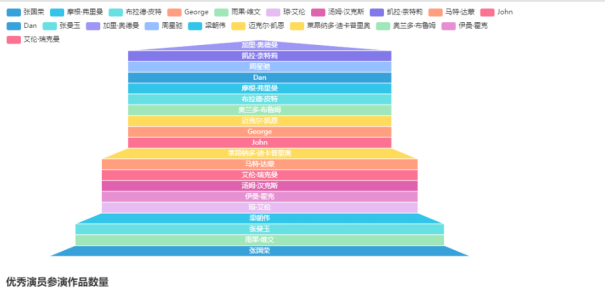
⑩ Top250影片优秀演员参演统计漏斗图
⑪ Top250影片词云图
⑫ 2019年评分最高华语电影top7 3D分析图
1.3 项目采用的技术栈
使用软件:Visual Studio Code、JetBrains PyCharm
采用技术:pyecharts、MongoDB、python第三方库
1.4 项目借鉴源代码的地址
python爬虫—豆瓣电影top250及数据可视化 https://www.jianshu.com/p/deaf10d4fd9b
1.5团队成员任务分配表
陈佳萍
对爬取到的top250影片信息,实现top10导演作品数量、华语电影类别比重、统计2000年上映影片类型比重,并绘制环形图、top250影片作品评分折线图
吴琳琳
将豆瓣top250数据爬取信息并保存在Mongodb中、分析豆瓣top250电影类型数量占比、top20电影评分柱状图、以及上映年份统计图
肖茹云
豆瓣评价人数top20电影、生成华语前七星级获分对比三维柱状图、生成词云图
二、项目的需求分析
针对影视作品越来越多,层次不穷,通过对豆瓣top250影片爬取和分析,更加直观选择观看影片。
三、项目功能架构图、主要功能流程图
1.1 功能架构图

图1 功能架构图
1.2 主要功能流程图
图2 爬虫爬取

图3 top10导演
图4 三维柱形图
图5 词云图
四、系统模块说明
1.1 系统模块列表
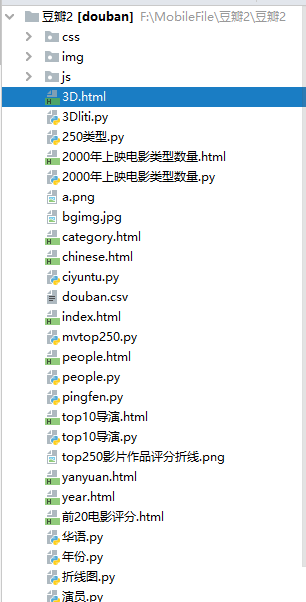
图6 项目结构图
1.2 各模块详细描述(名称,功能,运行截图,关键源代码)
1、mvtop250.py :实现对豆瓣top250的影片信息爬取
1) 构建递归循环,逐页爬取

2) 建立Mongodb连接,用于数据保存
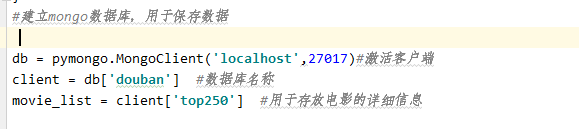
3) 抓取top250电影的上映时间、国家、评分、类型、评价人数
def get_movie_list(url,headers):
# 实例化soup对象, 便于处理
soup = requests.get(url,headers=headers) #向网站发起请求,并获取响应对象
response = BeautifulSoup(soup.text,'lxml')#利用xml html解析器,具有容错功能
lists = response.select('div.info')
#循环获取信息
for list in lists:
#获取链接, 也就是获取a链接中href对应的值;
sing_url =list.select('a')[0].get('href')
#获取影片名称
name =list.select('div.hd .title')[0].text
#导演及主演
type_list = list.select('div.bd p')[0].text.strip('').split('...')[-1].replace(' ','').split('/')
#上映时间
year =type_list[0]
#国家
country = type_list[1]
#影片所属类别
category = type_list[2]
#获取影片评分
star = list.select('div.bd .star .rating_num')[0].text.replace(' ','')
#获取引述
quote =list.select('div.bd .quote')[0].text
#获取评论人数
people_num = list.select('div.bd .star span:nth-of-type(4)')[0].text.split('人')[0]
get_detail_movie(sing_url,name,year,country,category,star,quote,people_num,headers)
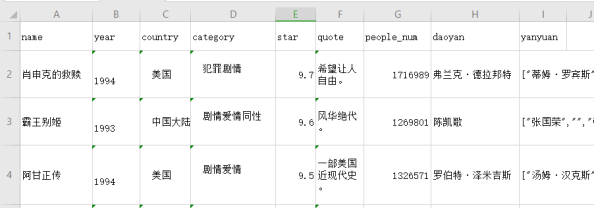
4) 抓取top250电影的执导导演、参演演员,并保存数据到mongodb中

我们将获取到影片信息数据保存到数据库中,以便后面对数据的分析,效果如下:
2、Top250影片华语电影类型数量
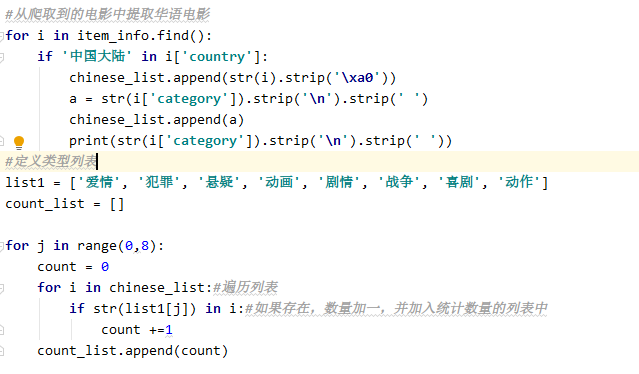

效果如下:
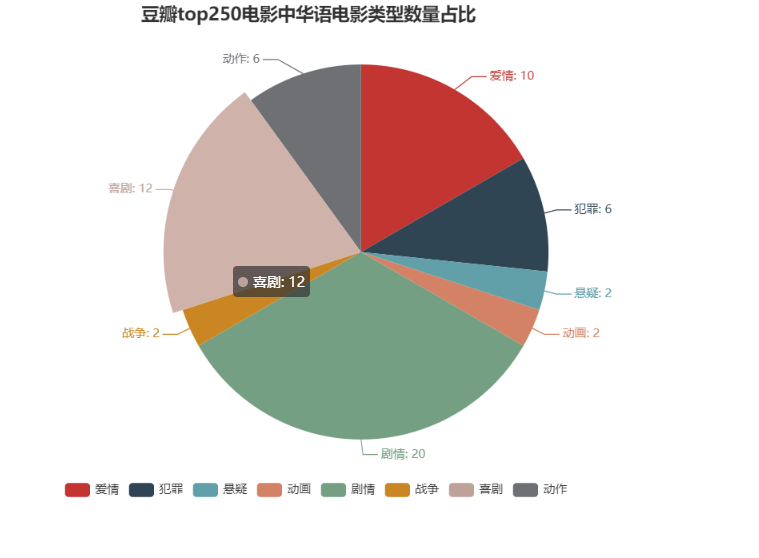
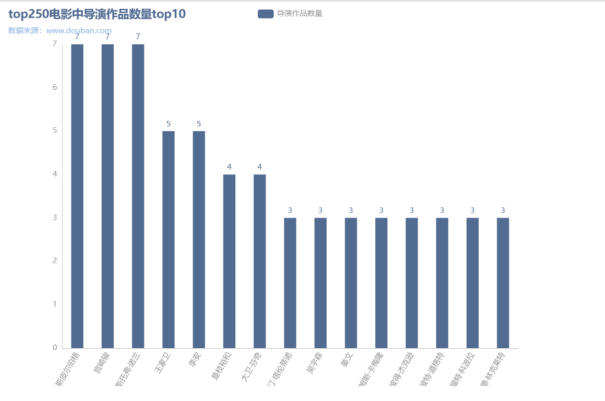
3、top10导演.py :对爬取到的信息进行分类整理,统计作品数前10的导演,以及数据可视化
1)统计所有导演数量
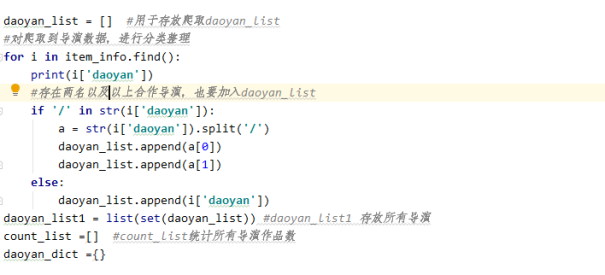
2)统计作品数前10导演
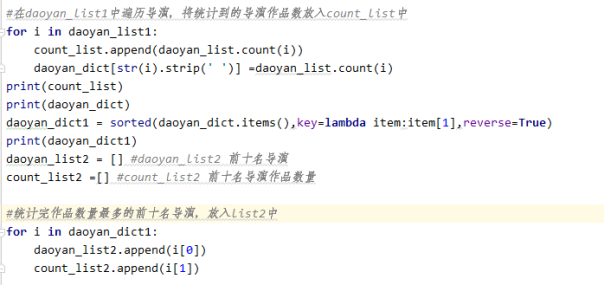
3)绘制柱状图
4)效果如下
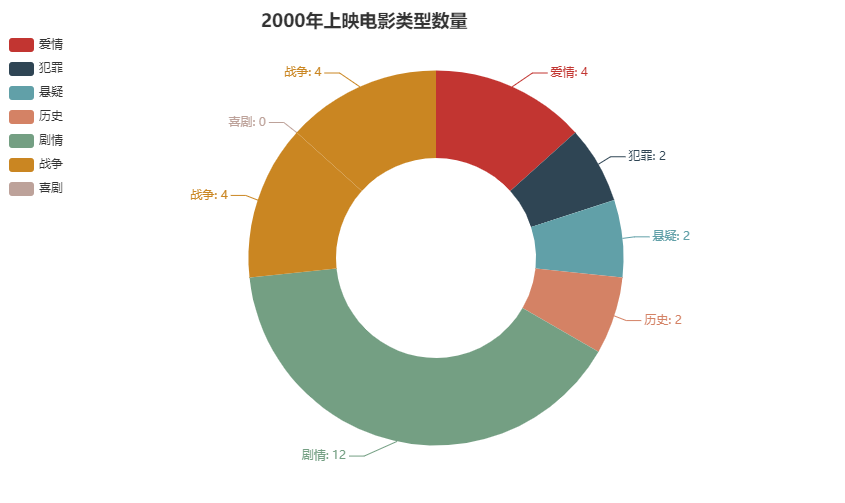
4、2000年上映影片类型比重
1)统计和提取2000年上映影片数量类型与华语上映电影类型相同,
2)绘制环形图

效果如下:
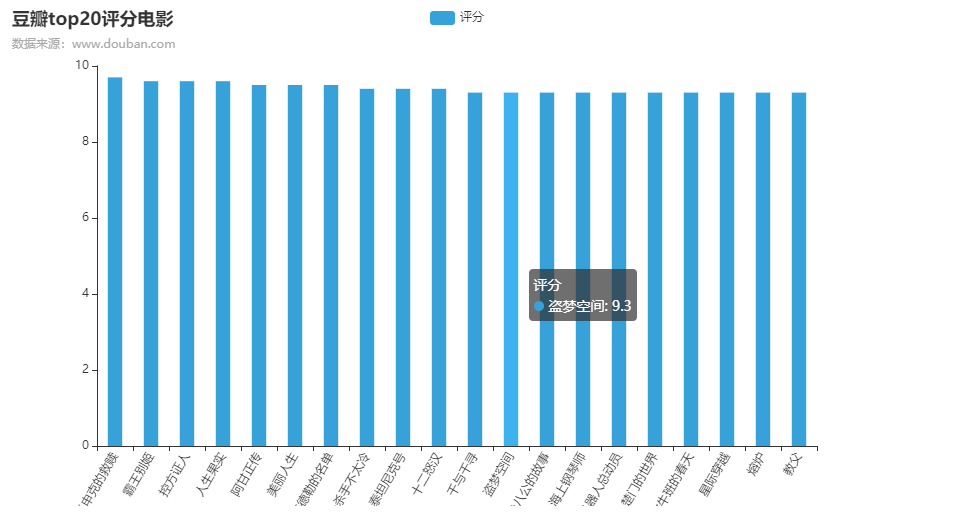
5、评论人数分析、以及Top250电影中评论top20统计图
1)对爬取的影片评论人数进行分析
2)绘制柱状图
效果如下:
1)豆瓣top20电影评论人数
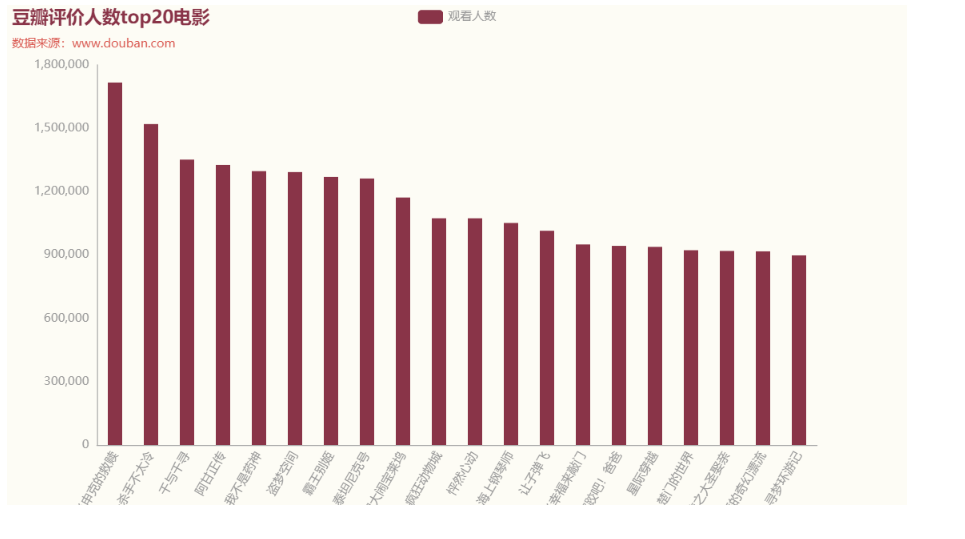
2)豆瓣top20评分情况
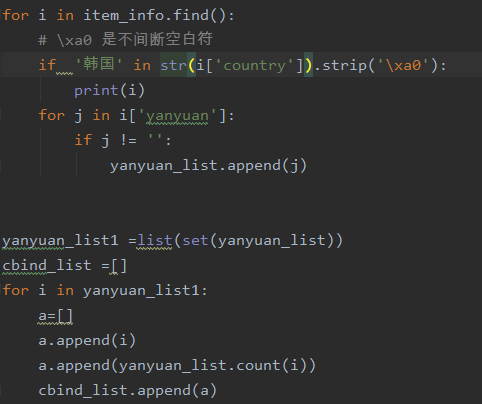
6、yanyuan.py:分析优秀演员参演作品数量
1)对获取到的演员列表进行分析
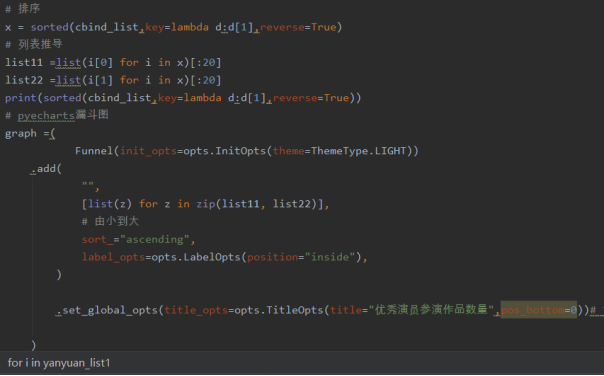
2)绘制漏斗图
效果如下:
7、作品上映年份统计以及折线图
1)作品上映年份统计
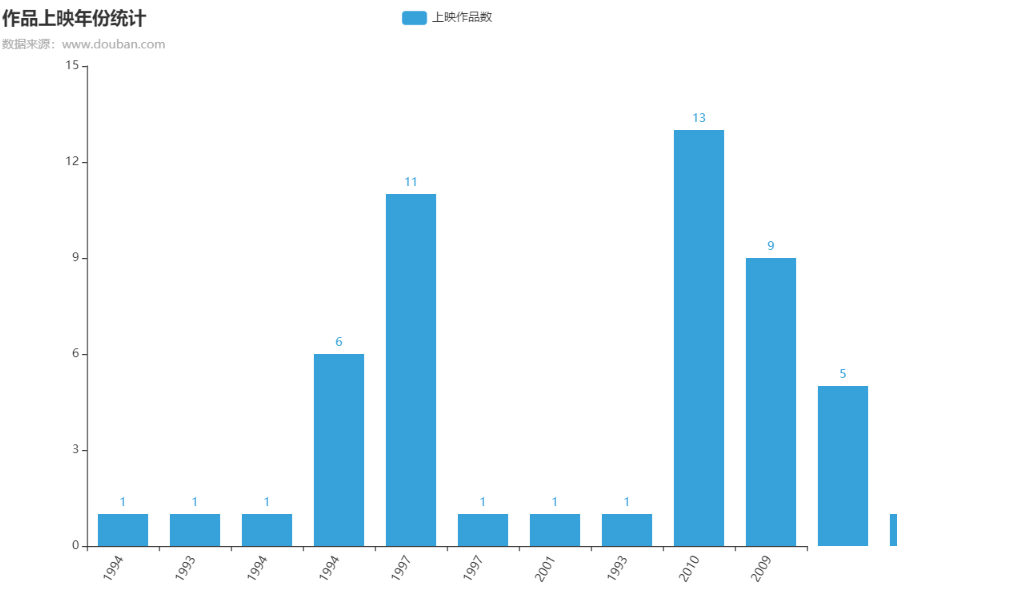
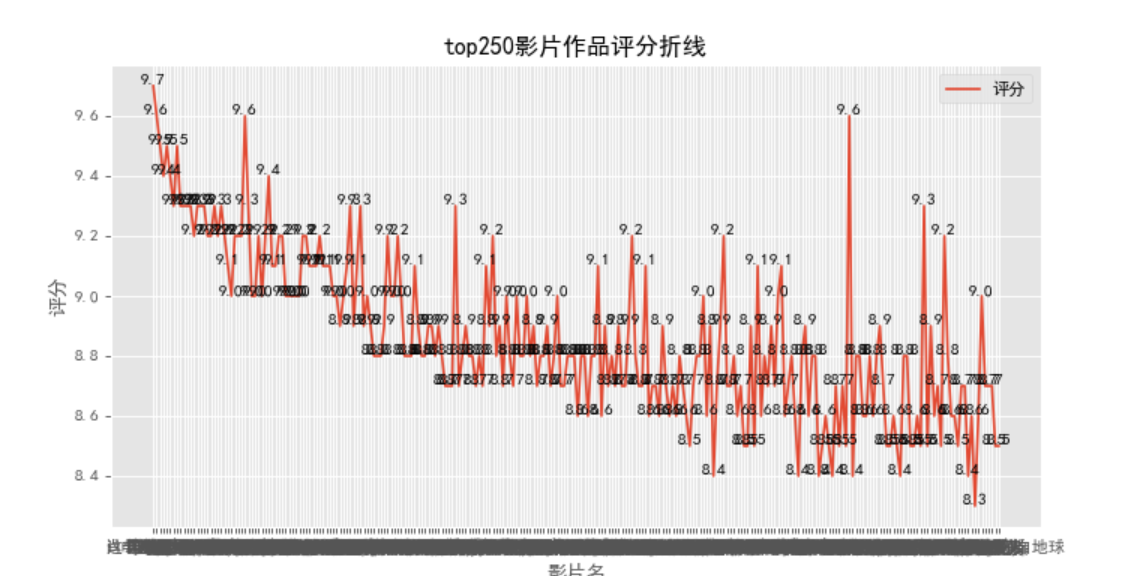
2)作品与评分折线图
根据爬取到的豆瓣影片信息生成的csv中读取数据生成折线图

8、top250影片词云图以及2019年评分最高华语电影top7 3D分析图
1)根据爬取到的豆瓣影片信息生成的csv中读取数据生成词云图

效果如下:

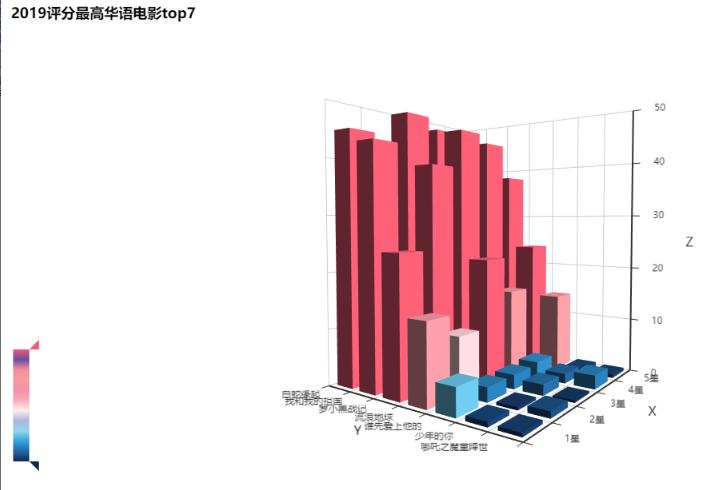
2)2019年评分最高华语电影top7 3D分析图
五、项目总结
5.1 特点
利用不同的技术,实现爬取,数据保存,数据可视化。使用mongodb存放数据,利用pyecharts包实现数据可视化。使用 render() 渲染生成html文件后,创建index文件将所有渲染的html文件进行连接。
在原有的基础上,添加top250影片中华语上映影片类型数量圆形图、2000年上映影片类型数量环形图、top250上映影片年份统计图以及影片作品评分折线图、top250中评分top20影片柱状图;
同时新增2019年评分最高华语电影top7 3D分析图。
5.2 不足之处
1.爬取数据数量有限。
2.数据量大,爬取速度慢。
3.无法识别链接重要程度,不能判断网页数据的价值程度。
4.使用Mongodb作为数据存储,而不是用MySQL
5.在设计生成年份统计图中,x轴的年份参数出现重复值,并且图形超出x轴;在设计折线图中,由于数量过多,x轴数量挤在一起,影响可读性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号