技术博客:Azure 认知服务
Azure 认知服务
1.概述
微软认知服务(Microsoft Cognitive Services)集合了多种智能API以及知识API,使每个开发人员无需具备机器学习的专业知识就能接触到 AI。借助这些API,可以将看、听、说、搜索、理解和加速决策的能力嵌入到应用中,并且能理解和解读我们通过自然交流方法所传达的需求,使开发者可以开发出更智能,更有吸引力的产品。
Azure 认知服务中的服务目录可分为五大主要支柱类别:视觉、语音、语言、Web 搜索和决策。
视觉API
| 服务名称 | 服务说明 |
|---|---|
| 计算机视觉 | 使用计算机视觉服务,你可以访问用于处理图像并返回信息的高级算法。 |
| 自定义视觉服务 | 通过自定义视觉服务可以生成自定义图像分类器。 |
| 人脸 | 使用人脸服务可访问高级人脸算法,从而实现人脸属性检测和识别。 |
| 表单识别器(预览版) | 表单识别器从表单文档中识别并提取键值对和表数据;然后输出结构化数据,包括原始文件中的关系。 |
| 墨迹识别器(预览版) | 使用墨迹识别器可以识别和分析数字墨迹笔划数据、形状和手写内容,并输出包含所有已识别实体的文档结构。 |
| 视频索引器 | 使用视频索引器从视频中提取见解。 |
语音API
| 服务名称 | 服务说明 |
|---|---|
| 语音服务 | 语音服务将支持语音的功能添加到应用程序。 |
| 说话人识别 API(预览版) | 说话人识别 API 为说话人识别和验证提供算法。 |
语言API
| 服务名称 | 服务说明 |
|---|---|
| 语言理解 LUIS | 使用语言理解服务 (LUIS),应用程序可以理解用户以自己的语言表达的内容。 |
| QnA Maker | 通过 QnA Maker,可以从半结构化内容生成问答服务。 |
| 文本分析 | 文本分析提供对原始文本的自然语言处理,用于情绪分析、关键短语提取和语言检测。 |
| 文本翻译 | 文本翻译近乎实时地提供基于机器的文本翻译。 |
搜索API
| 服务名称 | 服务说明 |
|---|---|
| 必应新闻搜索 | 必应新闻搜索返回确定与用户查询相关的新闻文章列表。 |
| 必应视频搜索 | 必应视频搜索返回确定与用户查询相关的视频列表。 |
| 必应 Web 搜索 | 必应 Web 搜索返回确定与用户查询相关的搜索结果列表。 |
| 必应自动建议 | 通过必应自动建议,可向必应发送部分搜索查询词,并取回建议的查询列表。 |
| 必应自定义搜索 | 借助必应自定义搜索,可以为关注的主题创建定制的搜索体验。 |
决策API
| 服务名称 | 服务说明 |
|---|---|
| 异常探测器(预览版) | 使用异常检测器可以监视并检测时序数据中的异常。 |
| 内容审查器 | 内容审查器监视可能的冒犯性、不可取和危险内容。 |
| 个性化体验创建服务 | 个性化体验创建服务可让你选择要显示给用户的最佳体验,并从其实时行为中学习信息。 |
在我们的项目中,主要使用到的是语言API中的文本分析,用于处理用户上传到服务器的已填好的表单,通过处理OCR识别出来的JSON文件,整合相关字段的文本内容和位置信息,使用此API以确定文本所对应的实体,比如名字、地址、邮箱、电话号码等,以便于进一步实现表单的自动生成和模型预测。此API可以有效识别文本中的实体并将其分类为名字、地址、日期/时间、数量等, 已知实体也可以在 Web 上识别并链接到更多信息,其智能化的特性使本项目减少了在表单tag时的繁琐操作,可以很好的优化用户体验。
2.文本分析API
文本分析 API 是一种基于云的服务,它对原始文本提供高级自然语言处理,并且包含四项主要功能:情绪分析、关键短语提取、命名实体识别和语言检测。
情绪分析:通过在原始文本中分析有关积极和消极情绪的线索,使用情绪分析确定客户如何看待你的品牌或主题。 此 API 针对每个文档返回介于 0 和 1 之间的情绪评分,1 是最积极的评分。分析模型已使用 Microsoft 提供的大量文本正文和自然语言技术进行预先训练。 对于选定的语言,该 API 可以分析和评分提供的任何原始文本,并直接将结果返回给调用方应用程序。
关键短语提取:自动提取关键短语,以快速识别要点。 例如,针对输入文本“The food was delicious and there were wonderful staff”,该 API 会返回谈话要点:“food”和“wonderful staff”。
命名实体识别:识别文本中的实体并将其分类为人员、地点、组织、日期/时间、数量、百分比、货币等。 已知实体也可以在 Web 上识别并链接到更多信息。
语言检测:可以检测输入文本是用哪种语言编写的,并以多种语言、变体、方言和一些区域/文化语言报告请求中提交的每个文档的单一语言代码。 语言代码与表示评分强度的评分相搭配。
😀本项目具体涉及到的是命名实体识别,对于其他类型API的使用未做深入分析,感兴趣的可以自行探索~(在线体验网站亲测好用)
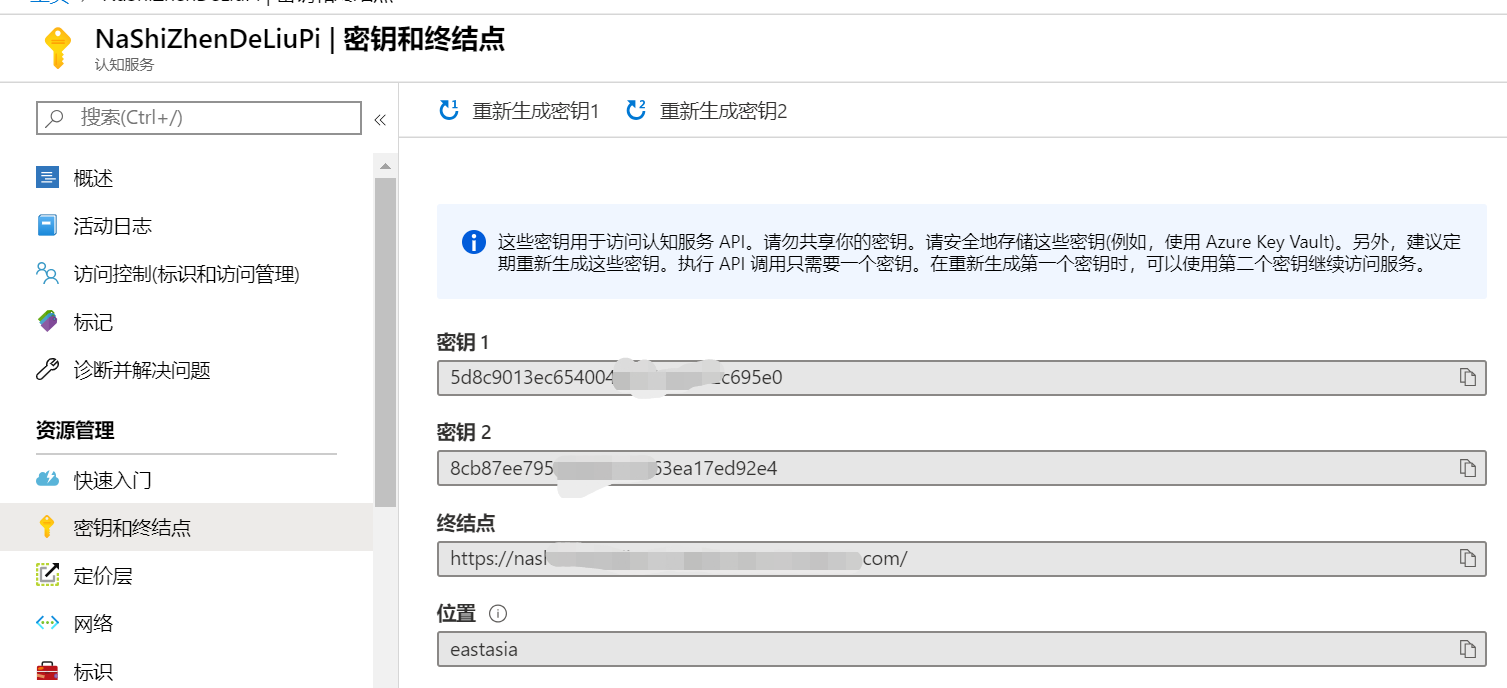
2.1Azure资源获取
文本分析资源的密钥和终结点是调用此API的必备条件,因此需要为其创建 Azure 资源。 然后获取生成的密钥,以便对请求进行身份验证。团队开发中我们使用的是同一个Azure账户,创建资源后即可在Azure门户中查找到相关密钥和终结点。
subscription_key = "<paste-your-text-analytics-key-here>"
endpoint = "<paste-your-text-analytics-endpoint-here>"
如无Azure账号,也可免费获取在七天内有效的试用密钥。 注册之后,它将在 Azure 网站上提供。
2.2规划请求
请求中需包含原始非结构化文本形式的 JSON 数据(输入必须是JSON),架构十分简单,包括以下列表中描述的元素:
| 元素 | 有效值 | 选项 | 使用情况 |
|---|---|---|---|
id |
数据类型为字符串,但实际上文档 ID 往往是整数。 | 必选 | 系统使用你提供的 ID 来构建输出。为请求中的每个 ID 生成语言代码、关键短语和情绪分数。 |
text |
非结构化原始文本,最多 5,120 个字符。 | 必选 | 对于语言检测,可以使用任何语言来表示文本。 对于情绪分析、关键短语提取和实体标识,此文本必须使用支持的语言。 |
language |
支持语言的 2 字符 ISO 639-1 代码 | 不定 | 需要情绪分析、关键短语提取、实体链接;语言检测为可选。 排除语言检测不会有任何错误,但没有它会削弱分析。 语言代码应对应你提供的 text。 |
示例:
documents = {"documents": [
{"id": "1", "text": "Microsoft was founded by Bill Gates and Paul Allen on April 4, 1975, to develop and sell BASIC interpreters for the Altair 8800."}
]}
2.3发布请求
对文本分析 API 的调用为 HTTP POST/GET 调用,可以用任何语言表示,和团队开发语言一致,在这里我们使用Python(Python 3.7)实现该调用。将此请求发布到注册期间建立的终结点,并追加所需的资源:命名实体识别,即将 /text/analytics/v2.1/entities 追加到文本分析基终结点,形成语言检测 URL)
entities_url = endpoint + "/text/analytics/v2.1/entities"
使用请求库将文档发送到 API。 将订阅密钥添加到 Ocp-Apim-Subscription-Key 标头,并发送带 requests.post() 的请求。
headers = {"Ocp-Apim-Subscription-Key": subscription_key}
response = requests.post(entities_url, headers=headers, json=documents)
entities = response.json()
2.4处理响应
调用此API时数据不会存储在帐户中,会立即返回结果,输出将会根据 ID 以单个 JSON 文档的形式返回,因此需要在本地流式处理或存储响应。返回样例:
{
"documents" : [
{
"id" : "1",
"entities" : [
{
"name" : "Microsoft",
"matches" : [
{
"wikipediaScore" : 0.49897989655674446,
"entityTypeScore" : 1.0,
"text" : "Microsoft",
"offset" : 0,
"length" : 9
}
],
"wikipediaLanguage" : "en",
"wikipediaId" : "Microsoft",
"wikipediaUrl" : "https://en.wikipedia.org/wiki/Microsoft",
"bingId" : "a093e9b9-90f5-a3d5-c4b8-5855e1b01f85",
"type" : "Organization"
},
.......
]
}
],
"errors" : []
}
本项目的后续处理中,需要将识别出来的实体type与表单中的文本整合起来,按照一定的格式构造出新的表单,以用于模型训练。
3.相关问题
3.1识别粒度
文本分析API现已发布的有两个版本:
-
最新稳定版 API - v2.1
-
最新预览版 API - v3.0-Preview.1
此文档写明了两个版本对实体识别类型的差异以及增加的功能。在API使用的过程中,我们想要实现将类似于"1020 Enterprise Way Sunnayvale, CA 87659"的文本段识别为"Address",但是在实际调用过程中,该API将字段里的每个单词分离,分别识别为"Quantity","Location","Quantity",并且自动忽略了"Enterprise Way"字段,无法实现地缘政治实体的识别,只能提取出位置信息。但是在在线体验网站上,却能将该字段整体识别为"Address":

一开始使用的是2.1版本,但是将其更新为3.0版本也并未解决此问题,所以目前采取的处理方式是一旦识别到"Location"即将其处理为"Address"。可能出现的问题是由于实体识别的粒度不够精细,导致表单生成数据不合理的问题。
3.2安全性
由于实体识别过程涉及到表单中真实姓名、地址、邮箱等信息,所以调用该API的安全性也是必须得考虑的问题,需要了解发送给认知服务的数据是如何处理的。通过查阅相关文档,微软认知服务对于数据的隐私和安全性有比较完善的保护体系,由 Azure 基础结构提供支持,提供了企业级的安全性、可用性、合规性及可管理性,可参阅符合性产品/服务和隐私详细信息。此文档概述了 Azure 认知服务安全的各个方面,例如使用传输层安全性、身份验证、安全配置敏感数据,以及客户密码箱客户数据访问,再加上密钥管理和身份验证等操作,提供了比较全面的隐私和安全保护。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号