02_机器学习概述、dataSet、特征工程【day1】
0、Xmind
1、机器学习概述
1.what is ML?
data 规律 预测


2. why need the ML?

2.what feild of ML?
4.what worth of ML?
替换手动,减少企业成本

2、数据集的结构
1. data来源
企业日益积累的大量数据(互联网公司更为显著)
政府掌握的各种数据
科研机构的实验数据
… ...
2.data of ML
文件格式:csv
myql: 1) 性能瓶颈、读取seed
2) 格式of data
pandas: read tool
numpy: 释放了GIL (cpython中的历史遗留,Jpython无)
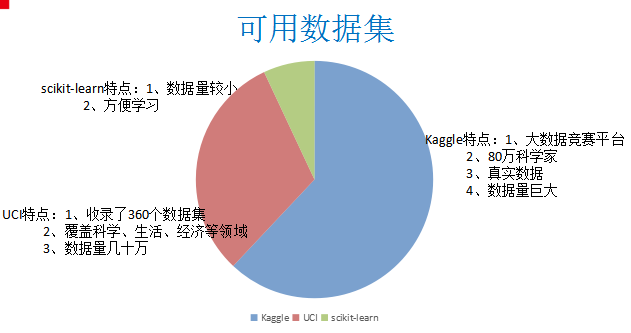
3.useful dataset
Kaggle网址:https://www.kaggle.com/datasets
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
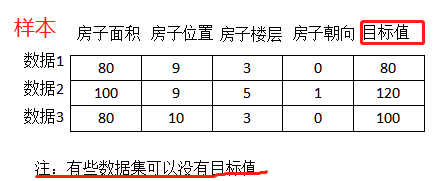
4.dataset的结构组成
结构: 特征值+目标值
dataFrame

5.data的特征处理:pandas、sklearn
dataFrame 缺失值,data transform
ML中的data: 重复值? don't need to 去重
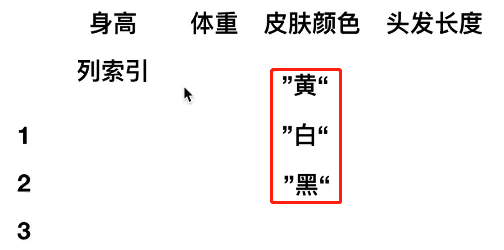
皮肤的颜色如何转换成计算机识别的data?
sklearn: 对特征的处理
panads:read tool


3、数据的特征工程
1、特征工程的影响
why 不同teams 的score 不同?
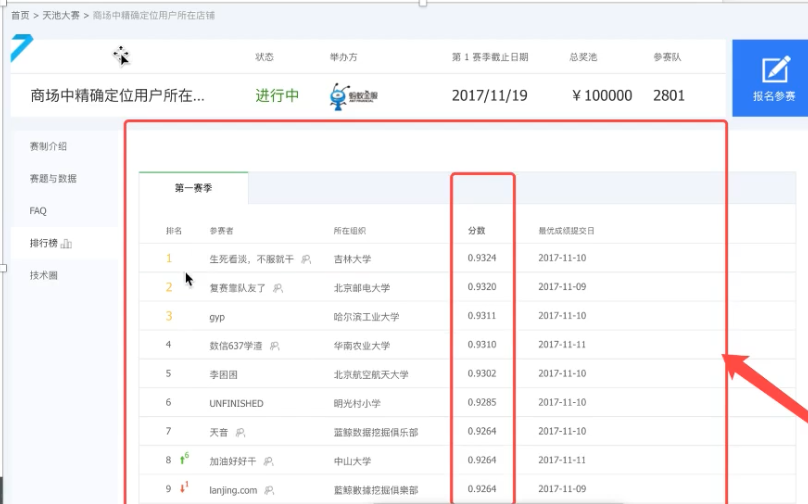
特征工程影响:the same 算法 ,the same dataset,“特征处理”不同,scores不同
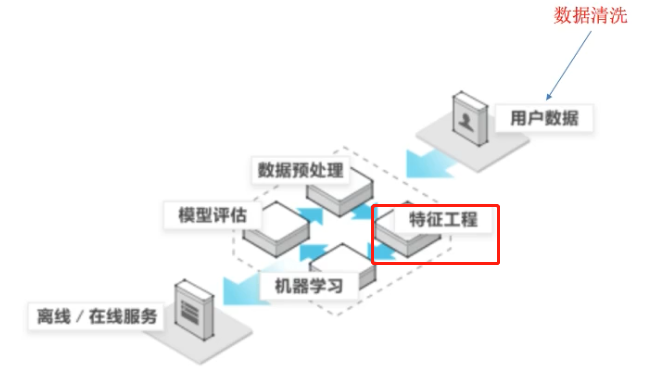
2、what is 特征工程
提高效果

3、what mean of 特征工程
直接影响预测的result
4、scikit-learn工具介绍
1) scikit-learn库的安装
python、ML算法、文档、易上手、丰富api、0.19


2) 安装
创建一个基于Python3的虚拟环境(可以在你自己已有的虚拟环境中): mkvirtualenv –p /usr/bin/python3.5 ml3 在ubuntu的虚拟环境当中运行以下命令 pip3 install Scikit-learn 然后通过导入命令查看是否可以使用: import sklearn
注:安装scikit-learn需要Numpy,pandas等库
pip3 install numpy
pip3 install pandas
3) 各种算法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号