10 [面向对象]-元类
1、exec的使用
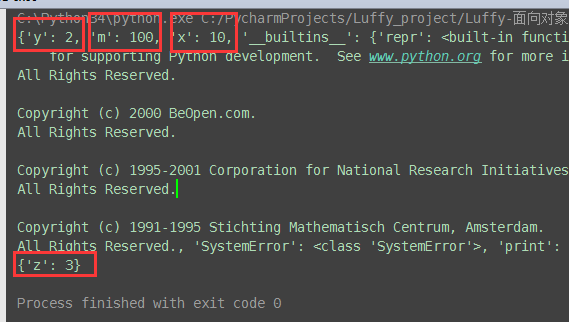
# 储备知识 # 参数1:字符串形式的命令 # 参数2:全局作用域(字典形式),如果不指定默认使用globals() # 参数3:局部作用域(字典形式),如果不指定默认就使用locals() # print(globals()) # 全局作用域 g = { 'x': 1, 'y': 2, # global x,m } # 局部作用域 l = {} # z = 3 exec(""" global x,m x = 10 m = 100 z = 3 """, g, l) # global x,m 全局作用域 g # z = 3 局部作用域 l print(g) print(l)
2、一切皆对象:类也是对象
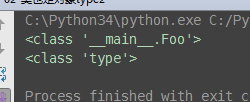
# 一切皆对象,对象可以怎么用? # 1.都可以被引用,x = obj # 2.都可以当做函数的参数传入 # 3.都可以当做函数的返回值 # 4.都可以当做容器类的元素 (容器类,list,dict,tuple) l = [func,time,obj,1] # 类也是对象,Foo=type(...) class Foo: pass obj = Foo() print(type(obj)) # obj的类型是Foo 类 print(type(Foo)) # Foo的类型是type
3、什么是元类?
- 产生类的类称之为元类,默认所以用class定义的类,他们的元类是type
元类是类的类,是类的模板 元类是用来控制如何创建类的,正如类是创建对象的模板一样,而元类的主要目的是为了控制类的创建行为 元类的实例化的结果为我们用class定义的类,正如类的实例为对象(f1对象是Foo类的一个实例,Foo类是 type 类的一个实例) type是python的一个内建元类,用来直接控制生成类,python中任何class定义的类其实都是type类实例化的对象

4、定义类的两种方式
(1)方式一:使用class关键字
class Chinese:
country = 'china'
def __init__(self, name, age):
self.name = name
self.age = age
def talk(self):
print('%s is talking' % self.name)
(2)方式二:就是手动模拟class创建类的过程):将创建类的步骤拆分开,手动去创建
# 定义类的三要素: # 类名, # 类的父类 -->类的基类们, # 类体 --->类的名称空间
class_name = 'Chinese' # 类名 class_bases = (object,) # 类的基类 # 类体 class_body = """ country = 'china' def __init__(self,name,age): self.name = name self.age = age def talk(self): print("%s is talking" % self.name) """ # 生成类的局部名称空间,即填充字典 class_dict = {} exec(class_body, globals(), class_dict) # exec(p_object, globals, locals) print(class_dict) # 调用元类type(也可以自定义)来产生类Chinense Chinese = type(class_name, class_bases, class_dict)

#实现类调用 man = Chinese('alex', 22) print(Chinese.__dict__) print(man.__dict__) # 运行结果 {'__init__': <function __init__ at 0x0023B150>, 'talk': <function talk at 0x01DE3810>, 'country': 'china'} {'__doc__': None, 'talk': <function talk at 0x01DE3810>, 'country': 'china', '__dict__': <attribute '__dict__' of 'Chinese' objects>, '__init__': <function __init__ at 0x0023B150>, '__weakref__': <attribute '__weakref__' of 'Chinese' objects>, '__module__': '__main__'} {'age': 22, 'name': 'alex'}
5.自定义元类控制类的行为
(1)创建类
一个类没有声明自己的元类,默认他的元类就是type,除了使用元类type, 用户也可以通过继承type来自定义元类(顺便我们也可以瞅一瞅元类如何控制类的行为,工作流程是什么)
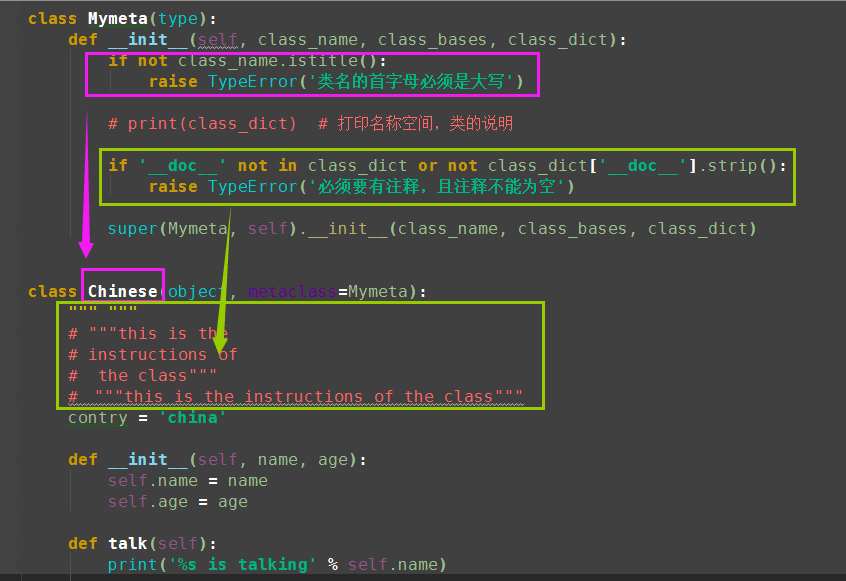
class Mymeta(type): def __init__(self, class_name, class_bases, class_dict): print(class_name) # 类名 print(class_bases) # 类的基类 print(class_dict) # 类的命名空间 super(Mymeta, self).__init__(class_name, class_bases, class_dict) class Chinese(object, metaclass=Mymeta): contry = 'china' def __init__(self, name, age): self.name = name self.age = age def talk(self): print('%s is talking' % self.name)
Chinese
(<class 'object'>,)
{'__module__': '__main__', '__qualname__': 'Chinese', 'talk': <function Chinese.talk at 0x01F33780>,
'__init__': <function Chinese.__init__ at 0x01F33738>, 'contry': 'china'}
(2)自定义类的行为

6、控制类的实例化行为
(1)__call__ 方法
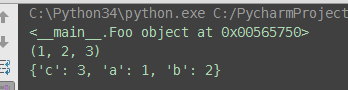
class Foo(object): def __call__(self, *args, **kwargs): print(self) print(args) print(kwargs) # 调用类People,并不会触发__call__ foo = Foo() # 调用对象obj(1,2,3,a=1,b=2,c=3),才会出发对象的绑定方法obj.__call__(1,2,3,a=1,b=2,c=3) foo(1,2,3,a=1,b=2,c=3) # #总结:如果说类People是元类type的实例,那么在元类type内肯定也有一个__call__, # 会在调用People('egon',18)时触发执行,然后返回一个初始化好了的对象obj
(2)元类中的call方法
总结:如果说类People是元类type的实例,那么在元类type内肯定也有一个__call__,会在调用People('egon',18)时触发执行,然后返回一个初始化好了的对象obj
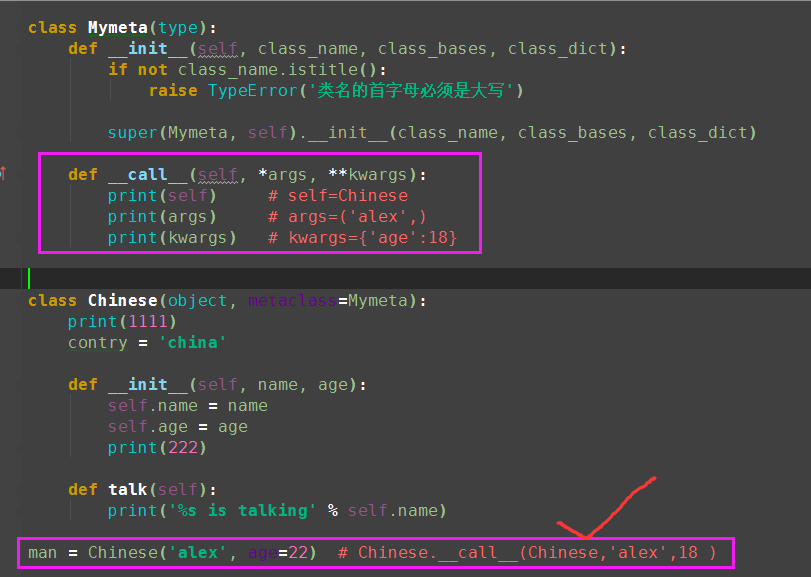
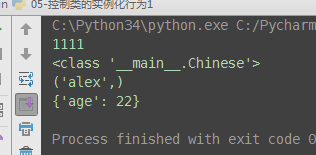
(3)自定义元类,控制类的调用(即实例化)的过程
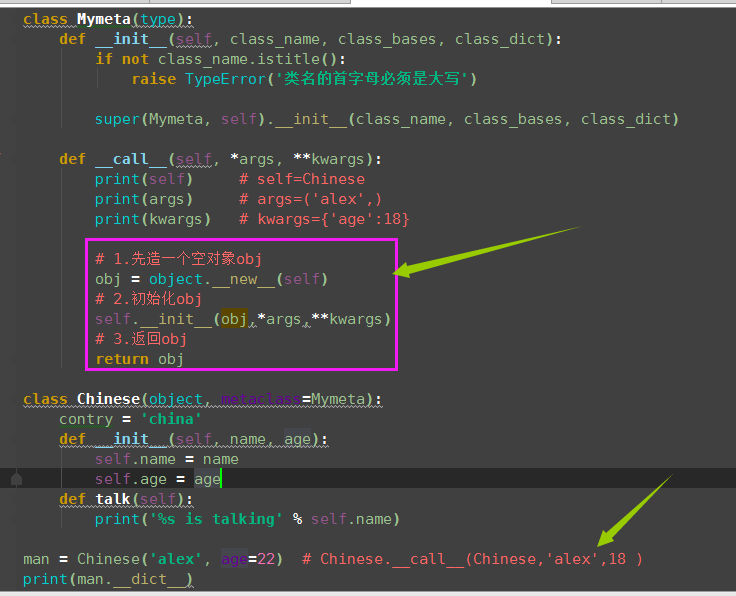
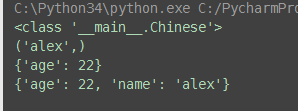
(4)单例模式
-
基于元类实现单例模式,比如数据库对象,实例化时参数都一样,就没必要重复产生对象,浪费内存
class Mysql: __instance = None # obj1 # 类属性 def __init__(self): self.host = '127.0.0.1' self.port = 3306 @classmethod def single(cls): if not cls.__instance: obj = cls() cls.__instance = obj return cls.__instance def conn(self): pass def execute(self): pass # obj1 = Mysql() # obj2 = Mysql() # obj3 = Mysql() # # print(obj1) # print(obj2) # 3个不同的内存地址 # print(obj3) # 不是同一块内存,不是同一个对象 obj1 = Mysql.single() obj2 = Mysql.single() obj3 = Mysql.single() print(obj1 is obj2 is obj3) # True
7.应用:定制元类实现单例模式
class Mymeta(type): def __init__(self, class_name, class_bases, class_dict): # 定义类Mysql时就触发 if not class_name.istitle(): # #Mysql(...)时触发 raise TypeError('类名必须大写') super(Mymeta,self).__init__(class_name, class_bases, class_dict) self.__instance = None def __call__(self, *args, **kwargs): if not self.__instance: obj = object.__new__(self) # 产生对象 # new方法只是创建了类对象,没有初始化,没有实例化对象 self.__init__(obj) # 初始化对象 self.__instance = obj # 上述两步可以合成下面一步 # self.__instance=super().__call__(*args,**kwargs) return self.__instance class Mysql(object,metaclass=Mymeta): def __init__(self): self.host = '127.0.0.1' self.port = 3306 def conn(self): pass def execute(self): pass obj1 = Mysql() obj2 = Mysql() obj3 = Mysql() print(obj1 is obj2 is obj3) # True
8、 练习题
练习一:在元类中控制把自定义类的数据属性都变成大写


class Mymetaclass(type): def __new__(cls,name,bases,attrs): update_attrs={} for k,v in attrs.items(): if not callable(v) and not k.startswith('__'): update_attrs[k.upper()]=v else: update_attrs[k]=v return type.__new__(cls,name,bases,update_attrs) class Chinese(metaclass=Mymetaclass): country='China' tag='Legend of the Dragon' #龙的传人 def walk(self): print('%s is walking' %self.name) print(Chinese.__dict__) ''' {'__module__': '__main__', 'COUNTRY': 'China', 'TAG': 'Legend of the Dragon', 'walk': <function Chinese.walk at 0x0000000001E7B950>, '__dict__': <attribute '__dict__' of 'Chinese' objects>, '__weakref__': <attribute '__weakref__' of 'Chinese' objects>, '__doc__': None} '''
练习二:在元类中控制自定义的类无需init方法
1.元类帮其完成创建对象,以及初始化操作;
2.要求实例化时传参必须为关键字形式,否则抛出异常TypeError: must use keyword argument
3.key作为用户自定义类产生对象的属性,且所有属性变成大写
class Mymetaclass(type): # def __new__(cls,name,bases,attrs): # update_attrs={} # for k,v in attrs.items(): # if not callable(v) and not k.startswith('__'): # update_attrs[k.upper()]=v # else: # update_attrs[k]=v # return type.__new__(cls,name,bases,update_attrs) def __call__(self, *args, **kwargs): if args: raise TypeError('must use keyword argument for key function') obj = object.__new__(self) #创建对象,self为类Foo for k,v in kwargs.items(): obj.__dict__[k.upper()]=v return obj class Chinese(metaclass=Mymetaclass): country='China' tag='Legend of the Dragon' #龙的传人 def walk(self): print('%s is walking' %self.name) p=Chinese(name='egon',age=18,sex='male') print(p.__dict__)
9、单例模式下,高并发,线程安全
1、问题描述
kubernete包两年前的版本大概是64的样子,后来不知道什么原因,可能维护的人觉得Configuration对象有很多域都是可供用一个的,弄了个metaclass,目的是当创建这个类的第一个实例后,后续的实例都以第一个实例为基准,也就成了62的样子。 我的代码在使用的时候,每次都回创建一个新的configuration实例
# _*_ coding : UTF-8 _*_ # Author : Jack """ File_name : Function : Date : """ from kubernetes.client import Configuration # 创建一个实例化对象a # a = Configuration() # # 创建一个实例化对象b # b = Configuration() # # a = Configuration # # b = Configuration # # # a.api_key = {'authorization': "token a"} # # 修改父类中init方法中api_key的属性,在初始化init参数时,实例已经存在 # a.api_key['authorization'] = "token a" # # # b.api_key = {'authorization': "token b"} # # 修改父类中api_key的属性,在初始化init参数,由于初始化时实例已经存在,相当于init共用,这样b的值就覆盖了a的值 # b.api_key['authorization'] = "token b" # # 所以输出结果会是b的值 # print(a.api_key['authorization']) a = Configuration() a.api_key['authorization'] = "token a" print(a.api_key['authorization']) b = Configuration() b.api_key['authorization'] = "token b" print(a.api_key['authorization'])
那么问题来了, 为什么会偶尔出现401, 也就是说发给集群A的token,实际上属于B
2、原因

3、结论
https://raising.iteye.com/blog/2246125
https://www.cnblogs.com/Piers/p/9333645.html
https://meizhi.iteye.com/blog/537563
多线程下,共享的数据,不安全,
需要锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号