19-[模块]-json/pickle、shelve
1.序列化?
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
(1)把字典保存到文件
data = { 'roles': [ {'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': 'dog', 'life': 80}, ] } f = open('game_status', 'w') f.write(str(data))
(2)把字典从文件中读出来
f = open('game_status', 'r') data = f.read() dic = eval(data) print(dic)

2.json
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
Dumps 只是变成str
Dump 还可以存入文件
import json data = { 'roles': [ {'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': 'dog', 'life': 80}, ] } d = json.dumps(data) #仅转换为字符串 print(d, type(d)) d2 = json.loads(d) # 将数据从字符串转化为原来的格式 print(d2['roles']) # 运行结果 {"roles": [{"role": "monster", "type": "pig", "life": 50}, {"role": "hero", "type": "dog", "life": 80}]} <class 'str'> [{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': 'dog', 'life': 80}]
import json data = { 'roles': [ {'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': 'dog', 'life': 80}, ] } f = open('json_1', 'w') json.dump(data, f) # 把dict数据写入文件 f.close() f = open('json_1', 'r') data = json.load(f) # 把数据从文件读出,并且转换为原来的格式 print(data['roles']) # 运行结果 [{'life': 50, 'role': 'monster', 'type': 'pig'}, {'life': 80, 'role': 'hero', 'type': 'dog'}]

3.pickle
(1)json对不同数据类型操作
# 写入文件 import json f = open('json_2', 'w') d1 = {'name': 'alex', 'age': 22} l1 = [1, 2, 3, 4, 'dfa'] json.dump(d1, f) json.dump(l1, f) #文件内容 {"name": "alex", "age": 22}[1, 2, 3, 4, "dfa"]
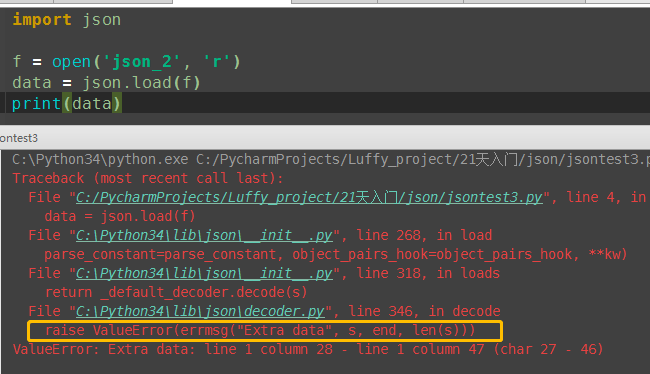
(2)pickle
import pickle d1 = {'name': 'alex', 'age': 22} d = pickle.dumps(d1) # 转换为bytes print(d) # 运行结果 b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00alexq\x02X\x03\x00\x00\x00ageq\x03K\x16u.'
import pickle d1 = {'name': 'alex', 'age': 22} l1 = [1, 2, 3, 4, 'dfa'] f = open('pick_1', 'wb') pickle.dump(d1,f) #dump写入文件 pickle.dump(l1,f)

import pickle f = open('pick_1', 'rb') data = pickle.load(f) print(data) #运行结果 {'name': 'alex', 'age': 22}
- 不能dump load 多次
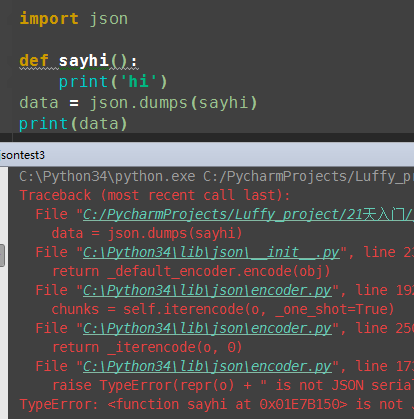
(3)函数也可以pickle 序列化
import pickle def sayhi(): print('hi') data = pickle.dumps(sayhi) print(data) #结果 b'\x80\x03c__main__\nsayhi\nq\x00.'
4.JSON VS Pickle

JSON:
优点:跨语言、体积小
缺点:只能支持int\str\list\tuple\dict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
5.shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
(1)序列化
import shelve f = shelve.open('shelve_test') # 打开一个文件 names = ["alex", "rain", "test"] info = {'name': 'alex', 'age': 22} f["names"] = names # 持久化列表 f['info_dic'] = info f.close()
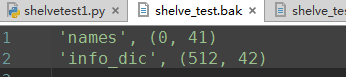


(2)反序列化
import shelve
d = shelve.open('shelve_test') # 打开一个文件
print(d['names'])
print(d['info_dic'])
#del d['test'] #还可以删除
In [1]: import shelve In [2]: f = shelve.open('shelve_test') In [3]: f Out[3]: <shelve.DbfilenameShelf at 0x36f5190> In [4]: f. f.cache f.dict f.keyencoding f.popitem f.update f.clear f.get f.keys f.setdefault f.values f.close f.items f.pop f.sync f.writeback In [4]: f.keys() Out[4]: KeysView(<shelve.DbfilenameShelf object at 0x036F5190>) In [5]: list(f.keys()) Out[5]: ['names', 'info_dic'] In [7]: list(f.items()) Out[7]: [('names', ['alex', 'rain', 'test']), ('info_dic', {'age': 22, 'name': 'alex'})] In [8]: f.get('names') Out[8]: ['alex', 'rain', 'test'] In [9]: f.get('info_dic') Out[9]: {'age': 22, 'name': 'alex'} In [10]: f['names'][1] Out[10]: 'rain' In [12]: f.close()
In [9]: f['names'] Out[9]: ['alex', 'rain', 'test'] In [11]: f['names'][1] Out[11]: 'rain' In [12]: f['names'][1] = 'RAIN' # 修改不成功 In [13]: f['names'] Out[13]: ['alex', 'rain', 'test'] In [14]: f['names']=[1,2,3] #这样修改 In [15]: f['names'] Out[15]: [1, 2, 3] In [16]: del f['names'] 删除 In [17]: f.get('names')
4
5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号