9-[函数]-内置函数
内置参数详解
https://docs.python.org/3/library/functions.html?highlight=built#ascii
http://www.liujiangblog.com/course/python/40

abs():绝对值函数
In [4]: abs(-1) Out[4]: 1
all()、any()
all() 接收一个可迭代对象,如果对象里的所有元素的bool运算值都是True,那么返回True,否则False。
any() 接收一个可迭代对象,如果迭代对象里有一个元素的bool运算值是True,那么返回True,否则False。与all()是一对兄弟。
>>> all([1,1,1]) True >>> all([1,1,0]) False >>> any([0,0,1]) True >>> any([0,0,0]) False
ascii()
调用对象的__repr__()方法,获得该方法的返回值。__repr__()方法是由对象所属类型实现的方法。不可以简单地理解为print或echo。
In [37]: ascii('\n') Out[37]: "'\\n'"
In [94]: s = 'alex路飞' In [95]: ascii(s) Out[95]: "'alex\\u8def\\u98de'"
bin()、oct()、hex()
三个函数是将十进制数分别转换为2/8/16进制。
In [41]: bin(2) Out[41]: '0b10' In [42]: oct(9) Out[42]: '0o11' In [43]: hex(17) Out[43]: '0x11'
bool()
测试一个对象或表达式的执行结果是True还是False。这个在布尔数据类型章节中已经很详细的介绍过了。Ps:实际上bool是一个类,不是函数,bool()的返回值是一个布尔类型的实例。builtins中的很多函数,其实都是类,比如bytes(),str()等等。
In [46]: a = [] In [47]: bool(a) Out[47]: False
bytearray
实例化一个bytearray类型的对象。参数可以是字符串、整数或者可迭代对象。bytearray是Python内置的一种可变的序列数据类型,具有大多数bytes类型同样的方法。
当参数是字符串的时候,需要指定编码类型。
当参数是整数时,会创建以该整数为长度,包含同样个数空的bytes对象的数组。
当参数是个可迭代的对象时,该对象必须是一个取值范围0 <= x < 256的整数序列。
>>> a = bytearray("asdff",encoding='utf-8') >>> b = bytearray(10) >>> b bytearray(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00') >>> d = bytearray([1,2,3]) >>> d bytearray(b'\x01\x02\x03') >>> d = bytearray([1,2,300]) Traceback (most recent call last): File "<pyshell#12>", line 1, in <module> d = bytearray([1,2,300]) ValueError: byte must be in range(0, 256)
bytes()、str()
bytes() 将对象转换成字节类型。
str() 将对象转换成字符串类型,同样也可以指定编码方式。
Bytes和string之间的互相转换,更多使用的是encode()和decode()方法。
In [55]: i = 2 In [56]: bytes(i) Out[56]: b'\x00\x00' In [57]: s Out[57]: 'alex' In [58]: bytes(s) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-58-52a4404dba0a> in <module>() ----> 1 bytes(s) TypeError: string argument without an encoding In [59]: bytes(s,encoding='utf-8') Out[59]: b'alex' In [60]: bytes(s,encoding='GBK') Out[60]: b'alex'
In [61]: i = 2 In [62]: str(i) Out[62]: '2' In [63]: b = b'alex' In [64]: b Out[64]: b'alex' In [65]: str(b) #注意 Out[65]: "b'alex'" In [66]: str(b,encoding='GBK') Out[66]: 'alex' In [67]: str([1,2,3]) Out[67]: '[1, 2, 3]'
callable()
判断对象是否可以被调用。
>>> def f1(): pass >>> callable(f1) True >>> a = "123" >>> callable(a) False >>> class Foo: def __init__(self,name,age): self.name = name self.age = age >>> f_obj = Foo("jack",20) >>> callable(f_obj) False >>> callable(Foo) True
chr()、ord()
chr() 返回某个十进制数对应的ASCII字符,例如:chr(99) = ‘c’。它可以配合random.randint(65,91)随机方法,生成随机字符,用于生产随机验证码。
ord()与chr()相反,返回某个ASCII字符对应的十进制数,例如,ord('A') = 65
In [73]: chr(97) Out[73]: 'a' In [74]: chr(98) Out[74]: 'b' In [76]: import random In [77]: chr(random.randint(65,91)) Out[77]: 'W' In [78]: chr(random.randint(65,91)) Out[78]: 'J' In [79]: chr(random.randint(65,91)) Out[79]: 'G'
In [83]: ord('a') Out[83]: 97
classmethod()、staticmethod()和property()
类机制中,用于生成类方法、静态方法和属性的函数。
compile()
将字符串编译成Python能识别或执行的代码。 也可以将文件读成字符串再编译。
In [85]: s = "print('alex')" In [86]: compile(s) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-86-c6c296b3a5b2> in <module>() ----> 1 compile(s) In [87]: exec(s) alex
complex()
通过数字或字符串生成复数类型对象。
>>> complex(1,2) (1+2j)
delattr()、setattr()、getattr()、hasattr()
类机制中,分别用来删除、设置、获取和判断属性。
dir()
显示对象所有的属性和方法。最棒的辅助函数之一!
>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'builtins', 'r', 's'] >>> dir([1,2,]) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
vars() 打印函数的局部变量
与dir()方法类似,不过dir()方法返回的是key,vars()方法返回key的同时还把value一起打印了。
>>> vars() {'li': [1, 2, 3], '__builtins__': <module 'builtins' (built-in)>, '__spec__': None, '__package__': None, '__doc__': None, '__name__': '__main__', '__loader__': <class '_frozen_importlib.BuiltinImporter'>, 'dic1': {'name': 'alex'}} >>>
int()、float()、list()、dict()、set()、tuple()
与bool()、str()、bytes()一样,它们都是实例化对应数据类型的类。
divmod()
除法,同时返回商和余数的元组。
In [91]: 10/3 Out[91]: 3.3333333333333335 In [92]: 10//3 Out[92]: 3 In [93]: divmod(10,3) Out[93]: (3, 1)
enumerate()
枚举函数,在迭代对象的时候,额外提供一个序列号的输出。注意:enumerate(li,1)中的1表示从1开始序号,默认从0开始。注意,第二个参数才是你想要的序号开始,不是第一个参数。
dic = { "k1":"v1", "k2":"v2", "k3":"v3", } for i, key in enumerate(dic, 1): print(i,"\t",key)
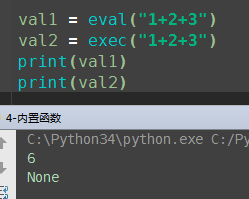
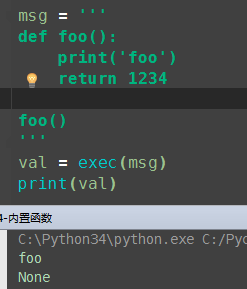
eval()、exec()
eval() 将字符串直接解读并执行。有返回值。只能处理单行代码
exec() 执行字符串或compile方法编译过的字符串,没有返回值。可以处理多行代码
In [97]: eval('print("alex")') alex
frozenset()
返回一个不能增加和修改的集合类型对象。
In [10]: s = set('AELX') In [11]: s Out[11]: {'A', 'E', 'L', 'X'} In [12]: type(s) Out[12]: set In [15]: s.add('ssss') In [16]: s Out[16]: {'A', 'E', 'L', 'X', 'ssss'} In [13]: b = frozenset('alex') In [14]: type(b) Out[14]: frozenset In [17]: b.add('sssss') --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-17-5193daec784b> in <module>() ----> 1 b.add('sssss') AttributeError: 'frozenset' object has no attribute 'add'
globals()
列出当前环境下所有的全局变量。注意要与global关键字区分!
>>> globals() {'__builtins__': <module 'builtins' (built-in)>, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__doc__': None, '__name__': '__main__'} >>>
hash()
为不可变对象,例如字符串生成哈希值的函数, 密码加密
>>> hash('123') 2825772880459179561 >>> hash('123') 2825772880459179561
help()
返回对象的帮助文档。谁用谁知道!
>>> a = [1,2,3] >>> help(a) Help on list object: class list(object) | list() -> new empty list | list(iterable) -> new list initialized from iterable's items ...
id()
返回对象的内存地址,常用来查看变量引用的变化,对象是否相同等。常用功能之一!
>>> id(0) 1456845856 >>> id(True) 1456365792 >>> a = "Python" >>> id(a) 37116704
input()
接收用户输入,返回一个输入的字符串。
>>> a = input("Please input a number: ") Please input a number: 100 >>> a '100' >>> type(a) <class 'str'>
isinstance()
判断一个对象是否是某个类的实例。比type()方法适用面更广。 判断浮点数
>>> isinstance(123,int) True >>> isinstance(123.11,float) True
issubclass()
issubclass(a,b),判断a是否是b的子类。
>>> class Foo: pass >>> class Goo(Foo): pass >>> issubclass(Goo, Foo) True
iter()
制造一个迭代器,使其具备next()能力。
>>> lis = [1, 2, 3] >>> i = iter(lis) >>> i <list_iterator object at 0x0000000002B4A128> >>> next(i) 1
len()
返回对象的长度。不能再常用的函数之一了。
locals()
返回当前可用的局部变量。
>>> locals() {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'a': '100', 'lis': [1, 2, 3], 'i': <list_iterator object at 0x0000000002B4A128>, 'dic': {'k1': 'v1'}}
>>> def f(): ... n = 3 ... print(locals()) ... >>> f() {'n': 3}
max()/min():
返回给定集合里的最大或者最小的元素。可以指定排序的方法!
lst=['abcdhush8','abc9iujtwertwert','abcdjlas','abcdj897h'] a = min(lst,key=len) print(a)
sum() 求和.
>>> sum(1,2,3) # 需要传入一个可迭代的对象 Traceback (most recent call last): File "<pyshell#15>", line 1, in <module> sum(1,2,3) TypeError: sum expected at most 2 arguments, got 3 >>> sum([1,2,3]) # 传入一个列表 6 >>> sum({1:1,2:2}) # 突发奇想,作死传入一个字典 3
In [1]: a = [1,2,3,4,5] In [2]: min(a) Out[2]: 1 In [3]: max(a) Out[3]: 5 In [4]: sum(a) Out[4]: 15
memoryview(obj)
返回obj的内存视图对象。obj只能是bytes或bytesarray类型。memoryview对象的使用方法如下:
>>> v = memoryview(b'abcefg') >>> v[1] 98 >>> v[-1] 103 >>> v[1:4] <memory at 0x7f3ddc9f4350> >>> bytes(v[1:4]) b'bce'
next()
通过调用迭代器的__next__()方法,获取下一个元素。
object()
该方法不接收任何参数,返回一个没有任何功能的对象。object是Python所有类的基类。
open()
打开文件的方法。
pow()
幂函数。
>>> pow(3, 2) 9
print()
>>> help(print) Help on built-in function print in module builtins: print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (stream); defaults to the current sys.stdout. sep: string inserted between values, default a space. end: string appended after the last value, default a newline. flush: whether to forcibly flush the stream.
# end参数 >>> s = 'alex, my name is job \n,age is 22' >>> s 'alex, my name is job \n,age is 22' >>> >>> print(s) alex, my name is job ,age is 22 >>> >>> print(s,end='') alex, my name is job ,age is 22>>> >>> >>> print(s,end="|") alex, my name is job ,age is 22|>>> >>>
# sep参数 >>> print('alex','job') alex job >>> >>> print('alex','job',sep='|') alex|job
# f参数 写入文件 >>> msg = '2222' >>> f = open('1','w') >>> print(msg,'2222',sep='|', end='', file=f) #文件内容 cat 1 2222|2222
range()
class range(object) | range(stop) -> range object | range(start, stop[, step]) -> range object | | Return a sequence of numbers from start to stop by step.
repr()
调用对象所属类的__repr__方法,与print功能类似。
>>> s = "hashdfh" >>> repr(s) "'hashdfh'"
reversed()
反转,逆序对象
>>> reversed # reversed本身是个类 <class 'reversed'> >>> reversed([1,2,3,4,5]) # 获得一个列表反转器 <list_reverseiterator object at 0x0000022E322B5128> >>> a = reversed([1,2,3,4,5]) >>> a <list_reverseiterator object at 0x0000022E32359668> >>> list(a) # 使用list方法将它转换为一个列表 [5, 4, 3, 2, 1]
round()
四舍五入.
In [20]: round(1.23456) Out[20]: 1 In [21]: round(1.23456,2) # 保留2位 小数 Out[21]: 1.23 In [22]: round(1.23456,3) Out[22]: 1.235
slice()
返回一个切片类型的对象。slice是一个类,一种Python的数据类型。Python将对列表等序列数据类型的切片功能单独拿出来设计了一个slice类,可在某些场合下使用。
| indices(...) | S.indices(len) -> (start, stop, stride) | | Assuming a sequence of length len, calculate the start and stop | indices, and the stride length of the extended slice described by | S. Out of bounds indices are clipped in a manner consistent with the | handling of normal slices.
>>> s = slice(1, 10, 2) # 开始:停止:步长 >>> s slice(1, 10, 2) >>> type(s) <class 'slice'> >>> lis = [i for i in range(10)] >>> lis [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> lis[s] # 注意用法 [1, 3, 5, 7, 9]
>>> list1 = list(range(10)) >>> list1 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> >>> list1[1:10:2] [1, 3, 5, 7, 9] >>>
super()
调用父类。面向对象中类的机制相关。后面介绍。
type()
显示对象所属的数据类型。常用方法!前面已经展示过。
zip():拉链
组合对象。将对象逐一配对。
list_1 = [1,2,3] list_2 = ['a','b','c'] s = zip(list_1,list_2) print(list(s)) -------------------------------- 运行结果: [(1, 'a'), (2, 'b'), (3, 'c')]
组合3个对象:
list_1 = [1, 2, 3, 4] list_2 = ['a', 'b', 'c', "d"] list_3 = ['aa', 'bb', 'cc', "dd"] s = zip(list_1, list_2, list_3) print(list(s)) 运行结果: [(1, 'a', 'aa'), (2, 'b', 'bb'), (3, 'c', 'cc'), (4, 'd', 'dd')]
那么如果对象的长度不一致呢?多余的会被抛弃!以最短的为基础!
list_1 = [1,2,3] list_2 = ['a','b','c',"d"] s = zip(list_1,list_2) print(list(s)) -------------------------------- 运行结果: [(1, 'a'), (2, 'b'), (3, 'c')]
sorted()
排序方法。有key和reverse两个重要参数。
基础用法: 直接对序列进行排序
>>> sorted([36, 5, -12, 9, -21]) [-21, -12, 5, 9, 36]
指定排序的关键字。关键字必须是一个可调用的对象。例如下面的例子,规则是谁的绝对值大,谁就排在后面。
>>> sorted([36, 5, -12, 9, -21], key=abs) [5, 9, -12, -21, 36]
指定按反序排列。下面的例子,首先按忽略大小写的字母顺序排序,然后倒序排列。
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) ['Zoo', 'Credit', 'bob', 'about']
map()
映射函数。使用指定的函数,处理可迭代对象,并将结果保存在一个map对象中,本质上和大数据的mapreduce中的map差不多。
使用格式:obj = map(func, iterable),func是某个函数名,iterable是一个可迭代对象。
细心的同学可能发现了,我除了组合一些成对的或者同类系列的内置函数。还有map()函数,连同后面的filter()、zip()、sorted()和__import__()函数都没有介绍。因为这几个内置函数功能非常强大,使用场景非常多,Python非常贴心地帮我们实现并内置了!
li = [1,2,3] data = map(lambda x :x*100,li) # 这里直接使用了一个匿名函数 print(type(data)) # 返回值是一个map对象,它是个迭代器。 data = list(data) # 可以用list方法将map对象中的元素全部生成出来,保存到一个列表里。 print(data) ------------------------------------------------------ 运行结果: <class 'map'> [100, 200, 300]
filter()
过滤器,用法和map类似。在函数中设定过滤的条件,逐一循环对象中的元素,将返回值为True时的元素留下(注意,不是留下返回值!),形成一个filter类型的迭代器。
li = [11,22,33,44,55] result = filter(lambda x: x>33,li) print(list(result)) ---------------------------------------------- 结果: [44, 55] ------------------------------------------- # 等同于 li = [11,22,33,44,55] y = [a for a in li if a > 33] print(y)
>>> import functools >>> functools. functools.MappingProxyType( functools._gt_from_ge( functools.__delattr__( functools.RLock( functools._gt_from_le( functools.__dict__ functools.WRAPPER_ASSIGNMENTS functools._gt_from_lt( functools.__dir__( functools.WRAPPER_UPDATES functools._le_from_ge( functools.__eq__( functools.WeakKeyDictionary( functools._le_from_gt( functools.__format__( functools._CacheInfo( functools._le_from_lt( functools.__ge__( functools._HashedSeq( functools._lt_from_ge( functools.__getattribute__( functools.__all__ functools._lt_from_gt( functools.__gt__( functools.__cached__ functools._lt_from_le( functools.__hash__( functools.__doc__ functools._make_key( functools.__init__( functools.__file__ functools.cmp_to_key( functools.__le__( functools.__loader__ functools.get_cache_token( functools.__lt__( functools.__name__ functools.lru_cache( functools.__ne__( functools.__package__ functools.namedtuple( functools.__new__( functools.__spec__ functools.partial( functools.__reduce__( functools._c3_merge( functools.partialmethod( functools.__reduce_ex__( functools._c3_mro( functools.reduce( functools.__repr__( functools._compose_mro( functools.singledispatch( functools.__setattr__( functools._find_impl( functools.total_ordering( functools.__sizeof__( functools._ge_from_gt( functools.update_wrapper( functools.__str__( functools._ge_from_le( functools.wraps( functools.__subclasshook__( functools._ge_from_lt( functools.__class__( >>> functools.reduce(lambda x,y:x+y, [1,2,3,4,5,6]) 21 >>> functools.reduce(lambda x,y:x+y, [1,2,3,4,5,6],1) 22 >>> functools.reduce(lambda x,y:x+y, [1,2,3,4,5,6],2) 23 >>> functools.reduce(lambda x,y:x+y, [1,2,3,4,5,6],3) 24

 浙公网安备 33010602011771号
浙公网安备 33010602011771号