2-16 阶段考核
1,口述问题
- 学会看英文文档,源码目前不涉及
- 好的程序员,不能只懂一门语言,
- C语言,底层,推荐书目
- 变量命名规则和团队保持一致
- 编码格式(比较模糊)


2.不会的问题
编码格式: python2解释器是ASCII python3解释器是UTF-8 python2中 bytes = str Unicode是独立的类型 python3 str是unicode编码 所有的unicode字符编码后都是bytes格式
3.考题
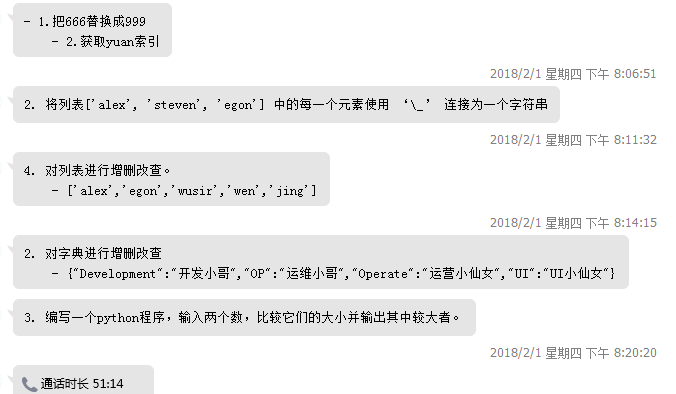
# -*- coding:utf-8 -*- # s = "www.luffycity.com" # print(s.split('.')) # 2. 切割字符串"luffycity"为"luffy","city" # s1 = "luffycity" # s1_1 = s1[0:5] # s1_2 = s1[5:] # print(s1_1,s1_2) # 5. 有如下字符串:n = "路飞学城" # - 将字符串转换成utf-8的字节,再将转换的字节重新转换为utf-8的字符串 # - 字符串转换成gbk的字节,再将转换的字节重新转换为utf-8的字符串 # n = "路飞学城" # # # print(n,type(n)) # print(n.encode('utf-8')) # print(n.encode('utf-8').decode('utf-8')) # print(n.encode('gbk')) # print(n.encode('gbk').decode('utf-8')) # 列表['alex','egon','yuan','wusir','666'] # - 1.把666替换成999 # - 2.获取yuan索引 # li = ['alex','egon','yuan','wusir','666'] # # li[-1] = '999' # li.index('yuan') # li[-3:] # 2. 将列表['alex', 'steven', 'egon'] 中的每一个元素使用 ‘\_’ 连接为一个字符串 # li = ['alex', 'steven', 'egon'] # # print('\_'.join(li)) # 4. 对列表进行增删改查。 # - ['alex','egon','wusir','wen','jing'] # li = ['alex','egon','wusir','wen','jing'] # li.remove(li[2]) # li.insert(2,'json') # print(li) # 对字典进行增删改查 # dic = {"Development":"开发小哥","OP":"运维小哥","Operate":"运营小仙女","UI":"UI小仙女"} # del dic['Development'] # dic['Development'] = '开发小哥' # 3. 编写一个python程序,输入两个数,比较它们的大小并输出其中较大者。 a = input("输入数字a:") b = input("输入数字b:") if a.isdigit() and b.isdigit(): if int(a) > int(b): print(a) else: print(b) else: print("请重新输入")
4.frozenset:不可变集合
set()和 frozenset()工厂函数分别用来生成可变和不可变的集合。如果不提供任何参数,默认
会生成空集合。如果提供一个参数,则该参数必须是可迭代的,即,一个序列,或迭代器,或支持
迭代的一个对象,例如:一个列表或一个字典。
>>> s=set('cheeseshop') 使用工厂方法创建 >>> s {'h', 'c', 'o', 's', 'e', 'p'} >>> type(s) <type 'set'> >>> s={'chessseshop','bookshop'}直接创建,类似于list的[]和dict的{},不同于dict的是其中的值,set会将其中的元素转换为元组 >>> s {'bookshop', 'chessseshop'} >>> type(s) <type 'set'> 不可变集合创建: >>> t=frozenset('bookshop') >>> t frozenset({'h', 'o', 's', 'b', 'p', 'k'})
1 >>> s.add('z') #添加 2 >>> s 3 set(['c', 'e', 'h', 'o', 'p', 's', 'z']) 4 >>> s.update('pypi') #添加 5 >>> s 6 set(['c', 'e', 'i', 'h', 'o', 'p', 's', 'y', 'z']) 7 >>> s.remove('z') #删除 8 >>> s 9 set(['c', 'e', 'i', 'h', 'o', 'p', 's', 'y']) 10 >>> s -= set('pypi')#删除 11 >>> s 12 set(['c', 'e', 'h', 'o', 's']) 13 >>> del s #删除集合
只有可变集合能被修改。试图修改不可变集合会引发异常。 1 >>> t.add('z') 2 Traceback (most recent call last): 3 File "<stdin>", line 1, in ? 4 AttributeError: 'frozenset' object has no attribute 'add'
5.函数:string.join()
Python中有join()和os.path.join()两个函数,具体作用如下:
join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
os.path.join(): 将多个路径组合后返回
1、join()函数 语法: 'sep'.join(seq) 参数说明 sep:分隔符。可以为空 seq:要连接的元素序列、字符串、元组、字典 上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串 返回值:返回一个以分隔符sep连接各个元素后生成的字符串 2、os.path.join()函数 语法: os.path.join(path1[,path2[,......]]) 返回值:将多个路径组合后返回 注:第一个绝对路径之前的参数将被忽略
#对序列进行操作(分别使用' '与':'作为分隔符) >>> seq1 = ['hello','good','boy','doiido'] >>> print ' '.join(seq1) hello good boy doiido >>> print ':'.join(seq1) hello:good:boy:doiido #对字符串进行操作 >>> seq2 = "hello good boy doiido" >>> print ':'.join(seq2) h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o #对元组进行操作 >>> seq3 = ('hello','good','boy','doiido') >>> print ':'.join(seq3) hello:good:boy:doiido #对字典进行操作 >>> seq4 = {'hello':1,'good':2,'boy':3,'doiido':4} >>> print ':'.join(seq4) boy:good:doiido:hello #合并目录 >>> import os >>> os.path.join('/hello/','good/boy/','doiido') '/hello/good/boy/doiido'
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号