2-1. 变量
变量的创建与id
例1:name = 'oldboy'
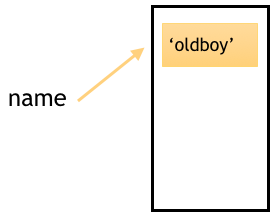
首先,当我们定义了一个变量name = ‘oldboy’的时候,在内存中其实是做了这样一件事:
程序开辟了一块内存空间,将‘oldboy’存储进去,再让变量名name指向‘oldboy’所在的内存地址。如下图所示:
例2:两个变量名一个值
提问:当我执行下面这段代码的时候,程序是怎么处理的呢?
name1 = 'oldboy' name2 = 'oldboy'
我们猜想会有两种可能:
第一种情况:程序分别在内存中开辟了两块儿空间来存储‘oldboy’这个值,并且让name1和name2指向这两个值。如下左图
第二种情况:由于两个值内容一致,所以程序只开辟一块儿空间存储‘oldboy’,并让name1和name2只想着个值。如下右图
提问:大家来猜测一下会是哪种情况?
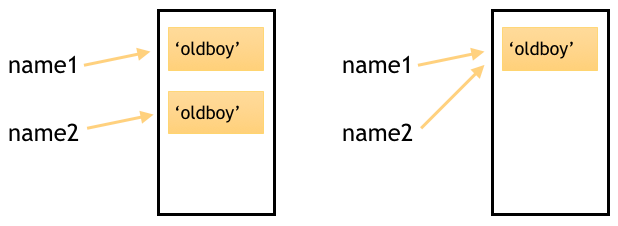
其实上面的两种猜想都是对的。正常情况下字符串在内存里就是如我们猜想的第一种情况一样,每一次创建一个变量都会在内存中申请一块儿空间。
但是,python认为一些“看起来像python标识符的字符”和小整数字在开发中是常用的,因此出于节省内存的角度思考,对于这部分字符串和数字做出了优化[-5,257),
python解释器会由于要定义的新变量内容与之前定义过的变量内容相同而不让这部分内容占用新的内存空间。
我们如何证明我们的想法呢?
python为我们提供了一个id()方法,可以查看一个变量的内存地址。
>>> name1 = 'oldboy' >>> name2 = 'oldboy' >>> name1_id = id(name1) >>> name2_id = id(name2) >>> print(name1_id,name2_id) (4459387232, 4459387232)
执行完这段代码就基本验证了我们的思想,由于‘oldboy’是一个简单的字符串,因此python解释器做了优化,内存里只有一个‘oldboy’,name1和name2都指向同一块儿内存地址。
如果是长字符串呢?就米有优化机制啦!
>>> a = 'this is a very long sentence' >>> b = 'this is a very long sentence' >>> id(a) 4394464720 >>> id(b) 4394464640
对于[-5,257)范围内的数字也有优化机制:
>>> a = 256 >>> b = 256 >>> id(a) 4297546112 >>> id(b) 4297546112 >>> a = -5 >>> b = -5 >>> id(a) 4297537760 >>> id(b) 4297537760
但是超过这个范围可就不太行了:
>> a=257 >>> b=257 >>> id(a) 4402490032 >>> id(b) 4403650768 >> a = -6 >>> b=-6 >>> id(a) 4402490032 >>> id(b) 4403650768
例3:一个变量名2个值
提问:如果像下面这样写自己的代码,最终打印name会得到什么结果?
name = 'oldboy' name = 'alex' print(name)
我想大家的答案是一致的,name此时应该是‘alex’,当我们在程序中对变量进行重复赋值时,就是对一个变量进行修改.
代码解读:
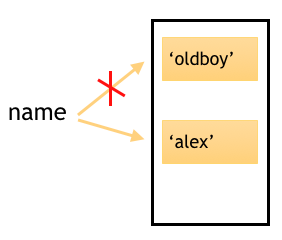
程序先申请了一块内存空间来存储‘oldboy’,让name变量名指向这块内存空间
读到name=‘alex’之后又申请了另一块内存空间来存储‘alex’,并让原本指向‘oldboy’内存的链接断开,让name再指向‘alex’。
如下图所示:
例4:变量的赋值与修改
提问:如果像下面这样写自己的代码,最终打印name1和name2会分别得到什么结果?
name1 = 'oldboy' name2 = name1 name1 = 'alex' print(name1,name2)
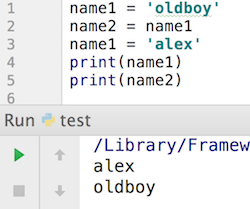
这里大家就会产生一些争论了,先执行一下给大家看。
要想知道上面问题的结果是为什么,首先要了解在内存中两个变量的存储情况
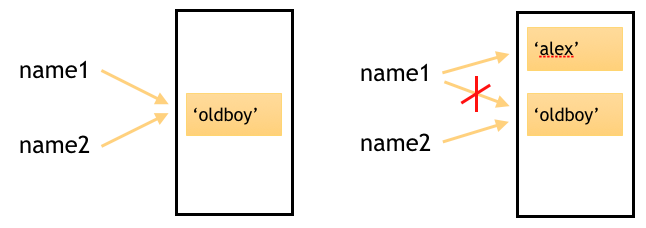
从上面的示意图中我们可以知道,当执行name2=name1这句话的时候,事实上是让name2指向了‘oldboy’所在的内存地址。
修改name1的值,相当于断开了name1到‘oldboy’的链接,重新建立name1和‘alex’之间的链接。在这个过程中,始终没有影响到name2和‘oldboy‘之间的关系,因此name2还是‘oldboy’,而name1变成了‘alex’。
身份运算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号