
1、mysql添加记录
--添加记录的语法(可添加单条记录或者多条记录),INTO是可以省略的,字段名也可以省略的,但是如果省略的话,后面对应的value的值就要全部填写 INSERT [INTO] tab_name [(col_name,...)] {VALUE|VALUES} (values...); --添加记录的语法(只可添加一条记录) INSERT tab_name SET 字段名称=字段值,...; --从表中查询记录进行添加 INSERT tab_name SELECT 字段名称 FROM tab1_name [WHERE 条件]
注意:通常情况下,以上语句在使用values插入单行数据的时候效率要比value来得高,但是插入多行数据的时候效率value要比values来得高,set与value|values相比效率要来得高,但是set是mysql的扩展,对于其他数据库是不存在的,所以可移值性比较低,并且set一次只能添加一条数据。
举例:
--测试用表 CREATE TABLE IF NOT EXISTS test( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '用户ID', name VARCHAR(20) NOT NULL COMMENT '用户名', sex ENUM('0','1','2') NOT NULL DEFAULT '0' COMMENT '性别0保密,1男,2女' )ENGINE=INNODB CHARSET=UTF8; --指定值 INSERT INTO test (name,sex) VALUES ('AA','0'); --不指定值,那么所对应的所有的值要全部写出来 INSERT test VALUES (NULL,'BB','1'); --插入多条记录,中间用逗号隔开,注意中英文状下的逗号 INSERT test (name,sex) VALUE ('CC','2'),('DD','1'),('EE','0'),('FF','2'); --应用set来添加数据 INSERT test SET name="GG",sex="2"; --进行批量插入 INSERT user (name,sex) SELECT name,sex FROM test WHERE sex="1"
2、修改记录
--更改记录的语法(有点类似INSERT..SET) UPDATE tab_name SET 字段名=字段值,...[WHERE 条件];
注意:如果没有指定where那么整张表的数据都会被更改。
--在id<3的名字后面加上ok,并且把性别改成默认值(默认值可以用DEFAULT来代替) UPDATE test SET name=CONCAT(name,'ok'),sex=DEFAULT WHERE id<=3; --SELECT * FROM test 输出 -- +----+------+-----+ -- | id | name | sex | -- +----+------+-----+ -- | 1 | AAok | 0 | -- | 2 | BBok | 0 | -- | 3 | CCok | 0 | -- | 4 | DD | 2 | -- | 5 | EE | 1 | -- | 6 | FF | 0 | -- | 7 | GG | 2 | -- +----+------+-----+
批量更新数据表
使用MYSQL自带语句进行批量更新
-- 使用update set 进行批量更新,注意:如果是多个条件的时候,每个条件的长度应该要相等 UPDATE tab_name SET 需修改的字段=CASE 参照字段 WHEN 参数字段值 THEN 修改字段值 ... END,...END [WHERE 条件]; -- 举例,根据id修改名字和年龄 UPDATE user SET name = CASE id WHEN 1 THEN "AA" WHEN 2 THEN "BB" END,age=CASE id WHEN 1 THEN 18 WHEN 2 THEN 22 END WHERE id IN (1,2); -- 查询修改记录,当查询到目标记录的时候进行修改,如果没有查询到则进行插入 INSERT INTO tab_name (字段名,...) VALUE (值,...) ON DUPLICATE KEY UPDATE 字段名=VALUES(字段名); -- 举例,注意:需要更改的字段放在ON DUPLICATE KEY UPDATE 后面 INSERT INTO `user` (id,name,age) VALUES (1,"小A",8),(2,"小B",18),(3,"小C",28),(4,"小D",38) ON DUPLICATE KEY UPDATE `name`=VALUES(name),age=VALUES(age); --谨慎使用 使用replace into 进行批量更新,注意该操作本质是对重复的记录先delete 后insert,如果更新的字段不全会将缺失的字段置为缺省值 REPLACE INTO tab_name (字段名,...) VALUE (值,...); -- 举例,如果在表中的唯一值里能匹配到相关的数据,那么会进行修改操作,否则会进行添加操作 REPLACE INTO user (id,name,age) VALUE (1,"CC",12),(2,"DD",27);
3、删除记录
--删除记录的语法,如果不添加条件,那么会删除全部记录 DELETE FROM tab_name [WHERE 条件]; --删除记录,同时也可以重置AUTO_INCREMENT的值 TRUNCATE [TABLE] tab_name
注意:如果不添加条件,那么会删除全部记录,但是通过delete删除的全部记录,不会重置AUTO_INCREMENT的值,但是可以通过ALTER TABLE tab_name AUTO_INCREMENT=1 进行设置
--删除所有ID大于3的记录 DELETE FROM test WHERE id>3; --SELECT * FROM test 输出 -- +----+------+-----+ -- | id | name | sex | -- +----+------+-----+ -- | 1 | AAok | 0 | -- | 2 | BBok | 0 | -- | 3 | CCok | 0 | -- +----+------+-----+
4、查询记录

--查询记录的基本语法 SELECT select_expr,...FROM tab_name [WHERE 条件] [GROUP BY {col_name | position} HAVING 二次筛选] [ORDER BY {col_name |position|expr} [ASC | DESC]] [LIMIT 限制结果集的显示条数]
[OFFSET 偏移量]
--可以使用库名.表名的形式查询数据(即可以不指定当前数据库的情况下进行表查询) SELECT select_expr,...FROM db_name.tab_name --可以给字段或者表名起别名(可以通过AS或者空隔对表名或者字段名进行起别名) SELECT col_name AS col_rename,... FROM tab_name AS tab_rename --建议要用AS来分隔,这个比较容易区分 SELECT col_name col_rename,... FROM tab_name tab_rename
注意:建议在起别名的时候,要加上AS以免引起混乱,并且在起别名的时候,要在字段上加上别名.字段,以免在以后在多表联查时避免错误。
select distinct * from `表名`;
--以上面建的表为例 SELECT * FROM ytest.test; -- 输出 -- +----+------+-----+ -- | id | name | sex | -- +----+------+-----+ -- | 1 | AAok | 0 | -- | 2 | BBok | 0 | -- | 3 | CCok | 0 | -- +----+------+-----+ --给字段起别名 SELECT t.name AS text,t.sex AS ss FROM ytest.test AS t; -- 输出 -- +------+----+ -- | text | ss | -- +------+----+ -- | AAok | 0 | -- | BBok | 0 | -- | CCok | 0 | -- +------+----+
distinct与sum,count一起使用
-- 原数组 -- +----+------+-------+-----+-------+ -- | id | name | score | sex | class | -- +----+------+-------+-----+-------+ -- | 1 | aaa | 80 | 女 | 二班 | -- | 2 | bbb | 30 | 男 | 二班 | -- | 3 | ccc | 40 | 女 | 二班 | -- | 4 | ddd | 50 | 男 | 一班 | -- | 5 | eee | 80 | 男 | 一班 | -- | 6 | fff | 70 | 女 | 一班 | -- | 1 | aaa | 80 | 女 | 二班 | -- +----+------+-------+-----+-------+ SELECT SUM(DISTINCT `score`), COUNT(DISTINCT `score`) FROM `worker`; -- 输出 -- +-----------------------+-------------------------+ -- | SUM(DISTINCT `score`) | COUNT(DISTINCT `score`) | -- +-----------------------+-------------------------+ -- | 270 | 5 | -- +-----------------------+-------------------------+
5、WHERE 的条件筛选(WHERE 条件会查询筛选出符合条件的记录,如果没有符合条件的记录,那么就会返回空记录)
a、where条件的比较运算符:= > >= < <= != <> <=>
--为原表添加一个字段 ALTER TABLE test ADD tDesc VARCHAR(30) COMMENT "描述"; --查询id=2的记录,其他用法也是一样的 SELECT id,name,sex FROM test WHERE id=2; --查询是否为空值 SELECT id,name FROM test WHERE tDesc IS NULL; SELECT id,name FROM test WHERE tDesc <=> NULL; --查询不为空值 SELECT id,name FROM test WHERE tDesc IS NOT NULL;
注意:<=>与=的用法基本一样,但是<=>是可以检测是否为NULL值,但是=不可以检测,同时<=>是MYSQL独有的语法,在其他语言不可以使用,而=可以通用
b、逻辑运算符:AND(逻辑与) OR(逻辑或) NOT(逻辑非) BETWEEN...AND...(介于两者之间)
-- 举例 SELECT id,name FROM test WHERE id<=2 AND sex='0'; -- 注意这个BETWEEN...AND...是包含1和2的 SELECT id,name FROM test WHERE id BETWEEN 1 AND 2; -- NOT 举例 SELECT id,name FROM test WHERE NOT (id = 1);
c、模糊查询like和 not like的使用
通配符%表示匹配0个1个或者多个字符,通配符_表示匹配一个字符
-- 匹配A前后有任意个字符的情况 SELECT id,name FROM test WHERE name LIKE "%A%"; -- 匹配A前有一个字付,后面任意个字符的情况 SELECT id,name FROM test WHERE name LIKE "_A%"; -- 匹配A前有一个字付,后面至少一个字符的情况 SELECT id,name FROM test WHERE name LIKE "_A_%";
6、GROUP BY 分组
group by 把值相同的放到一个组中,最终查询出的结果只会显示组中的一条记录
--举例 --的按照性别分组,group by 的值段可以没有在SELECT 里面 SELECT id,name,sex FROM test GROUP BY sex; --展示效果 -- +----+------+-----+ -- | id | name | sex | -- +----+------+-----+ -- | 10 | CC | 0 | -- | 8 | AA | 1 | -- | 9 | BB | 2 | -- +----+------+-----+
注意,如果 需要看组中的成员,那么可以用到函数GROUP_CONCAT
--查看组中的成员 SELECT id,GROUP_CONCAT(name),GROUP_CONCAT(sex) FROM test Group BY sex; --输出 -- +----+--------------------+-------------------+ -- | id | GROUP_CONCAT(name) | GROUP_CONCAT(sex) | -- +----+--------------------+-------------------+ -- | 10 | CC,EE | 0,0 | -- | 8 | AA,DD,GG | 1,1,1 | -- | 9 | BB,FF | 2,2 | -- +----+--------------------+-------------------+
GROUP BY 配合聚合函数使用
COUNT() 计数 SUM()求和 MAX() 最大值 MIN()最小值 AVG() 平均值
COUNT(col_name)与COUNT(*)的最大区别是,前者如果遇到值为null的时候,则不会计入范围,而后者会。所以后者可以作为统计总数用。
GROUP BY 与COUNT(*)结合的例子
--查看组中的成员,同时统计数量 SELECT sex,GROUP_CONCAT(name),COUNT(*) FROM test GROUP BY(sex); --输出 -- +-----+--------------------+----------+ -- | sex | GROUP_CONCAT(name) | COUNT(*) | -- +-----+--------------------+----------+ -- | 0 | CC,EE | 2 | -- | 1 | AA,DD,GG | 3 | -- | 2 | BB,FF | 2 | -- +-----+--------------------+----------+
GROUP BY 与SUM() , MAX() , MIN() , AVG() ,COUNT() 配合使用
--按性别分组,查看组中成员,个数,年龄总和,平均年龄,最小年龄,最大年龄 SELECT GROUP_CONCAT(name),COUNT(*),SUM(age),AVG(age),MAX(age),MIN(age) FROM test GROUP BY sex; --输出 -- +--------------------+----------+----------+----------+----------+----------+ -- | GROUP_CONCAT(name) | COUNT(*) | SUM(age) | AVG(age) | MAX(age) | MIN(age) | -- +--------------------+----------+----------+----------+----------+----------+ -- | CC,EE | 2 | 85 | 42.5000 | 47 | 38 | -- | AA,DD,GG | 3 | 103 | 34.3333 | 78 | 7 | -- | BB,FF | 2 | 48 | 24.0000 | 26 | 22 | -- +--------------------+----------+----------+----------+----------+----------+
SELECT COUNT(IF(`score`>50,1,NULL)) FROM `worker`; -- 输出 -- +------------------------------+ -- | COUNT(IF(`score`>50,1,NULL)) | -- +------------------------------+ -- | 2 | -- +------------------------------+
sum 函数在对单列进行求和时如果有Null值,是不影响值,当对多列进行sum统计时,就会有错误。
注意:如果GROUP BY 在和WHERE 使用的时候,WHERE 应该要放在GROUP BY 前面,不然会报错的。
--先查询年龄大小20岁的并按性别分组,查看组中成员,个数,年龄总和,平均年龄,最小年龄,最大年龄 SELECT GROUP_CONCAT(name),COUNT(*),SUM(age),AVG(age),MAX(age),MIN(age) FROM test WHERE age>20 GROUP BY sex; --输出 -- +--------------------+----------+----------+----------+----------+----------+ -- | GROUP_CONCAT(name) | COUNT(*) | SUM(age) | AVG(age) | MAX(age) | MIN(age) | -- +--------------------+----------+----------+----------+----------+----------+ -- | CC,EE | 2 | 85 | 42.5000 | 47 | 38 | -- | GG | 1 | 78 | 78.0000 | 78 | 78 | -- | BB,FF | 2 | 48 | 24.0000 | 26 | 22 | -- +--------------------+----------+----------+----------+----------+----------+
注意:如果对分组后的数据进行二次筛选,那么可以使用HAVING,并且HAVING要放在GROUP BY 后面,不然会报错的,HAVING与WHERE的不同之处在于后者不能对AS后的字段不能选择,而前者不能对未SELECT的字段进行选择。
--按性别分组,查看组中成员,个数,年龄总和,平均年龄,最小年龄,最大年龄,并且筛选年龄总和大于50的组 SELECT GROUP_CONCAT(name),COUNT(*),SUM(age) AS total,AVG(age),MAX(age),MIN(age) FROM test GROUP BY sex HAVING total>50; --输出 -- +--------------------+----------+-------+----------+----------+----------+ -- | GROUP_CONCAT(name) | COUNT(*) | total | AVG(age) | MAX(age) | MIN(age) | -- +--------------------+----------+-------+----------+----------+----------+ -- | CC,EE | 2 | 85 | 42.5000 | 47 | 38 | -- | AA,DD,GG | 3 | 103 | 34.3333 | 78 | 7 | -- +--------------------+----------+-------+----------+----------+----------+
在GROUP BY 后面 WITH ROLLUP 进行数据汇总,相当于把上面的值按一组情况进行统计
--按性别分组,查看组中成员,个数,年龄总和,平均年龄,最小年龄,最大年龄,并且进行全部数据的汇总 SELECT GROUP_CONCAT(name),COUNT(*),SUM(age),AVG(age),MAX(age),MIN(age) FROM test GROUP BY sex WITH ROLLUP; --输出 -- +----------------------+----------+----------+----------+----------+----------+ -- | GROUP_CONCAT(name) | COUNT(*) | SUM(age) | AVG(age) | MAX(age) | MIN(age) | -- +----------------------+----------+----------+----------+----------+----------+ -- | CC,EE | 2 | 85 | 42.5000 | 47 | 38 | -- | AA,DD,GG | 3 | 103 | 34.3333 | 78 | id 7 | -- | BB,FF | 2 | 48 | 24.0000 | 26 | 22 | -- | CC,EE,AA,DD,GG,BB,FF | 7 | 236 | 33.7143 | 78 | 7 | -- +----------------------+----------+----------+----------+----------+----------+
GROUP BY 也是可以进行多个分组统计的(中间用逗号隔开)
-- 数据源 +----+------+-------+-----+-------+ | id | name | score | sex | class | +----+------+-------+-----+-------+ | 1 | aaa | 80 | 女 | 二班 | | 2 | bbb | 30 | 男 | 二班 | | 3 | ccc | 40 | 女 | 二班 | | 4 | ddd | 50 | 男 | 一班 | | 5 | eee | 80 | 男 | 一班 | +----+------+-------+-----+-------+ SELECT `sex`, `class`, AVG(`score`) FROM `worker` GROUP BY `sex`, `class`; -- 输出 -- +-----+-------+------------+ -- | sex | class | avg(score) | -- +-----+-------+------------+ -- | 男 | 一班 | 65.0000 | -- | 男 | 二班 | 30.0000 | -- | 女 | 二班 | 60.0000 | -- +-----+-------+------------+
SELECT GROUP_CONCAT(`name`) AS "name",GROUP_CONCAT(`score`) AS "score",GROUP_CONCAT(`sex`) AS "sex",GROUP_CONCAT(`class`) AS "class",MAX(`score`),AVG(`score`) FROM `worker` GROUP BY `sex`,`class`; -- 输出 -- +---------+-------+-------+-----------+--------------+--------------+ -- | name | score | sex | class | MAX(`score`) | AVG(`score`) | -- +---------+-------+-------+-----------+--------------+--------------+ -- | ddd,eee | 50,80 | 男,男 | 一班,一班 | 80 | 65.0000 | -- | bbb | 30 | 男 | 二班 | 30 | 30.0000 | -- | aaa,ccc | 80,40 | 女,女 | 二班,二班 | 80 | 60.0000 | -- +---------+-------+-------+-----------+--------------+--------------+
7、ORDER BY 进行排序
ORDER BY 对数据进行排序 语法:ORDER BY 字段名 ASC|DESC 默认是ASC 升序,DESC 降序,同时也可以按照多个字段排序(如果两个字段相等的情况下)两个排序有逗号隔开,如果按照随机排序,那么用ORDER BY RAND() 即可
--按照年龄降序排序,如果有相同的情况下按照ID升序排序 SELECT * FROM test ORDER BY age DESC,id ASC; -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 14 | GG | 1 | 78 | -- | 12 | EE | 0 | 47 | -- | 10 | CC | 0 | 38 | -- | 13 | FF | 2 | 26 | -- | 9 | BB | 2 | 22 | -- | 8 | AA | 1 | 18 | -- | 11 | DD | 1 | 7 | -- +----+------+-----+-----+ -- 按照年龄随机排序 SELECT * FROM test ORDER BY RAND(); -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 8 | AA | 1 | 18 | -- | 14 | GG | 1 | 78 | -- | 10 | CC | 0 | 38 | -- | 11 | DD | 1 | 7 | -- | 9 | BB | 2 | 22 | -- | 12 | EE | 0 | 47 | -- | 13 | FF | 2 | 26 | -- +----+------+-----+-----+
8、LIMIT , OFFSET 限制结果集显示条数
LIMIT+一个值 => 显示结果集的前几条数据;
LIMIT+offset+row_count=> 从offset开始,显示row_count条数据
LIMIT +row_count OFFSET +offset => 意思同上(注意:offset要放在limit的后面,否则会报错)
--数据正常显示 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 8 | AA | 1 | 18 | -- | 9 | BB | 2 | 22 | -- | 10 | CC | 0 | 38 | -- | 11 | DD | 1 | 7 | -- | 12 | EE | 0 | 47 | -- | 13 | FF | 2 | 26 | -- | 14 | GG | 1 | 78 | -- +----+------+-----+-----+ --用LIMIT+数值 SELECT * FROM test ORDER BY id DESC LIMIT 3; -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 14 | GG | 1 | 78 | -- | 13 | FF | 2 | 26 | -- | 12 | EE | 0 | 47 | -- +----+------+-----+-----+ --用LIMIT+offset+row_count SELECT * FROM test ORDER BY id LIMIT 3,2; -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 11 | DD | 1 | 7 | -- | 12 | EE | 0 | 47 | -- +----+------+-----+-----+ --利用LIMIT+row_count OFFSET+offset SELECT * FROM test ORDER BY id ASC LIMIT 2 OFFSET 3; -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 11 | DD | 1 | 7 | -- | 12 | EE | 0 | 47 | -- +----+------+-----+-----+
利用limit与update ,delete进行配合使用
limit 与 update,delete 进行配合使用的时候只能用LIMIT+数值的模式,表示更新或者删除前几条数据
--limit 与 update 配合使用 UPDATE test SET age=22 LIMIT 3; -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 8 | AA | 1 | 22 | -- | 9 | BB | 2 | 22 | -- | 10 | CC | 0 | 22 | -- | 11 | DD | 1 | 7 | -- | 12 | EE | 0 | 47 | -- | 13 | FF | 2 | 26 | -- | 14 | GG | 1 | 78 | -- +----+------+-----+-----+ -- limit 与 delete 配合使用 DELETE FROM test LIMIT 1; -- 输出 -- +----+------+-----+-----+ -- | id | name | sex | age | -- +----+------+-----+-----+ -- | 9 | BB | 2 | 22 | -- | 10 | CC | 0 | 22 | -- | 11 | DD | 1 | 7 | -- | 12 | EE | 0 | 47 | -- | 13 | FF | 2 | 26 | -- | 14 | GG | 1 | 78 | -- +----+------+-----+-----+
9、多表查询
多表连接查询主要分成三部份,笛卡尔积的形式,内连接,外连接三种形式。
新建测试表
--员工表 CREATE TABLE IF NOT EXISTS user( id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT "用户ID", pid TINYINT UNSIGNED NOT NULL, name VARCHAR(20) NOT NULL, sex ENUM('0','1','2') DEFAULT "0" NOT NULL, age TINYINT UNSIGNED NOT NULL DEFAULT 0 )ENGINE=INNODB CHARSET=UTF8; --创建部门表 CREATE TABLE IF NOT EXISTS part( id TINYINT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '部门id', name VARCHAR(20) NOT NULL )ENGINE='INNODB' CHARSET=UTF8; --插入数据 INSERT part (name) VALUE ('html'),('css'),('javascript'),('php'),('java'); INSERT user (pid,name,sex,age) VALUE ('1','AA','2',22),('1','BB','2',21),('2','CC','1',24),('4','DD','1',24),('5','EE','1',28),('3','FF','2',25),('4','GG','0',23),('2','EE','1',18),('3','FF','2',27);
笛卡尔积的形式(进行多表查询是筛选语句不能少于n-1个)
-- 笛卡尔积连接 SELECT * FROM `emp`, `dept` WHERE emp.deptno = dept.deptno; -- 输出 -- +-------+--------+-----------+------+------------+---------+---------+--------+--------+------------+----------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | deptno | dname | loc | -- +-------+--------+-----------+------+------------+---------+---------+--------+--------+------------+----------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | 20 | RESEARCH | DALLAS | -- | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | 30 | SALES | CHICAGO | -- | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | 30 | SALES | CHICAGO | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | 20 | RESEARCH | DALLAS | -- | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | 30 | SALES | CHICAGO | -- | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | 30 | SALES | CHICAGO | -- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | 10 | ACCOUNTING | NEW YORK | -- | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | 20 | RESEARCH | DALLAS | -- | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | 10 | ACCOUNTING | NEW YORK | -- | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | NULL | 30 | 30 | SALES | CHICAGO | -- | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | 30 | SALES | CHICAGO | -- | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | 20 | RESEARCH | DALLAS | -- | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | 10 | ACCOUNTING | NEW YORK | -- +-------+--------+-----------+------+------------+---------+---------+--------+--------+------------+----------+
SELECT emp.*, dept.dname FROM `emp`, `dept` WHERE emp.deptno = dept.deptno;
自连接 :在同一张表的连接查询(就是给本表取个别名进行连接)
SELECT worker.ename, boss.ename FROM emp AS worker,emp AS boss WHERE worker.mgr=boss.empno; -- 输出 -- +--------+-------+ -- | ename | ename | -- +--------+-------+ -- | SCOTT | JONES | -- | FORD | JONES | -- | ALLEN | BLAKE | -- | WARD | BLAKE | -- | MARTIN | BLAKE | -- | TURNER | BLAKE | -- | JAMES | BLAKE | -- | MILLER | CLARK | -- | JONES | KING | -- | BLAKE | KING | -- | CLARK | KING | -- | SMITH | FORD | -- +--------+-------+ -- 查询和SMITH同一部门的员工 SELECT * FROM `emp` WHERE `deptno` = (SELECT `deptno` FROM `emp` WHERE `ename`="SMITH"); -- 输出 -- +-------+-------+---------+------+------------+---------+------+--------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | -- +-------+-------+---------+------+------------+---------+------+--------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | -- | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | -- | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | -- +-------+-------+---------+------+------------+---------+------+--------+ -- 查询10号部门都有哪些岗位,并且都有哪些员工在从事相关工作 SELECT * FROM `emp` WHERE `job` in (SELECT DISTINCT `job` FROM `emp` WHERE `deptno`=10); -- 输出 -- +-------+--------+-----------+------+------------+---------+------+--------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | -- +-------+--------+-----------+------+------------+---------+------+--------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | -- | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | -- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | -- | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | -- | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | -- | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | -- +-------+--------+-----------+------+------------+---------+------+--------+ -- 查询和小明数学,语文,英语成绩一样的学生 SELECT * FROM `student` WHERE (`chinese`,`english`,`math`) = (SELECT `chinese`,`english`,`math` FROM `student` WHERE `name`='小明'); -- 表emp -- +-------+--------+-----------+------+------------+---------+---------+--------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | -- +-------+--------+-----------+------+------------+---------+---------+--------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | -- | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | -- | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | -- | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | -- | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | -- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | -- | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | -- | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | -- | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | NULL | 30 | -- | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | -- | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | -- | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | -- +-------+--------+-----------+------+------------+---------+---------+--------+ -- 需求:显示高于自己部门平均工次的员工(名字,工资,部门平均工资) SELECT emp.ename,emp.sal,temp.avgSal FROM `emp`, (SELECT AVG(`sal`) AS 'avgSal', `deptno` FROM `emp` GROUP BY `deptno`) AS `temp` WHERE emp.deptno=temp.deptno AND emp.sal>temp.avgSal; -- 以上语句等价于下以语句 SELECT emp.ename,emp.sal,temp.avgSal FROM `emp` INNER JOIN (SELECT AVG(`sal`) AS avgSal, `deptno` FROM `emp` GROUP BY `deptno`) AS temp on emp.deptno=temp.deptno WHERE emp.deptno=temp.deptno AND emp.sal>temp.avgSal; -- 输出 -- +-------+---------+-------------+ -- | ename | sal | avgSal | -- +-------+---------+-------------+ -- | ALLEN | 1600.00 | 1566.666667 | -- | JONES | 2975.00 | 2443.750000 | -- | BLAKE | 2850.00 | 1566.666667 | -- | SCOTT | 3000.00 | 2443.750000 | -- | KING | 5000.00 | 2916.666667 | -- | FORD | 3000.00 | 2443.750000 | -- +-------+---------+-------------+
内连接:表示查询两个表中符合连接条件的记录(实际上就是利用where子句对两张(多表)形成的笛卡尔积进行筛选)
-- 语法,表示只显示两个表之间的公共部分 SELECT 字段名称,...FROM tab_name INNER JOIN tab_name2 ON 连接条件 -- 举例 SELECT u.id,u.name,u.sex,u.age,p.name FROM user AS u INNER JOIN part AS p ON u.pid=p.id; -- 输出 -- +----+------+-----+-----+------------+ -- | id | name | sex | age | name | -- +----+------+-----+-----+------------+ -- | 1 | AA | 2 | 22 | html | -- | 2 | BB | 2 | 21 | html | -- | 3 | CC | 1 | 24 | css | -- | 8 | EE | 1 | 18 | css | -- | 6 | FF | 2 | 25 | javascript | -- | 9 | FF | 2 | 27 | javascript | -- | 4 | DD | 1 | 24 | php | -- | 7 | GG | 0 | 23 | php | -- | 5 | EE | 1 | 28 | java | -- +----+------+-----+-----+------------+
外连接:外连接主要分为两种连接方式,左外连接与右外连接
左外连接:先显示左表中的全部记录,再去右表中查询复合条件的记录,不符合的以NULL值代替;
右外连接:先显示右表中的全部记录,再去左表中查询复合条件的记录,不符合的以NULL 值代替;
-- 语法 SELECT 字段名称,...FROM tab_name LEFT|RIGHT JOIN tab_name2 ON 连接条件
-- 左外边接 SELECT u.id,u.name,u.age,p.name FROM user AS u LEFT JOIN part AS p on u.pid=p.id; -- 右外边接 SELECT u.id,u.name,u.age,p.name FROM user AS u RIGHT JOIN part AS p on u.pid=p.id;
10、外键约束(保证表的一致性,完整性)
目录只有innodb的存储引擎支持外键,并且指向的主表的值是primary key 或者是 unique
表示当添加从表数据或者修改从表数据时,所关联的主表的外键指向的值是已经存在的
创建外键约束的方法有两个,一个是在建表的时候指定外键约束,一个是动态创建外键约束
-- 建表时创建外键约束语法(注意:子表的外键字段和主表的字段的类型要一致),如果外键字段没有创建索引,mysql会自动创建索引,后面表示是否设置级联操作 [CONSTRAINT 外键名称] FOREIGN KEY (字段名称) REFERENCES 主表(字段名称) [ON DELETE CASCADE ON UPDATE CASCADE];
注意:当外键子表下有数据的情况下,主表所对应的字段是不允许更改的,除非把子表所对应的数据删除。
CREATE TABLE IF NOT EXISTS job( id TINYINT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT 'JOB ID', name VARCHAR(20) NOT NULL )ENGINE=INNODB CHARSET=UTF8; CREATE TABLE IF NOT EXISTS user( id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '用户ID', name VARCHAR(20) NOT NULL, age TINYINT UNSIGNED NOT NULL DEFAULT 0, jid TINYINT UNSIGNED NOT NULL, CONSTRAINT user_fk_job FOREIGN KEY (jid) REFERENCES job(id) )ENGINE=INNODB CHARSET=UTF8; --如果有问题输入SET NAMES gbk; INSERT job (name) VALUE ("行政"),("人事"),("设计"),("编程"),("销售"); INSERT user (name,age,jid) VALUE ("小明",20,1),('小红',23,2),('小陈',34,3),('小刚',27,4),('小列',18,5),('小小',26,4); -- 提示删除失败,因为有外键约束 DELETE FROM job WHERE id=2;
动态添加和删除外键限制
-- 动态删除外键 ALTER TABLE tab_name DROP FOREIGN KEY foreign_name; -- 举例 ALTER TABLE user DROP FOREIGN KEY user_fk_job; -- 动态添加外键限制不指定外键名称 ALTER TABLE tab_name ADD FOREIGN KEY (字段名) REFERENCES 主表(字段名称) [ON DELETE CASCADE ON UPDATE CASCADE]; -- 动态添加外键限制并且指定外键名称 ALTER TABLE tab_name ADD CONSTRAINT 外键名称 FOREIGN KEY (字段名) REFERENCES 主表(字段名称) [ON DELETE CASCADE ON UPDATE CASCADE];
-- 举例
ALTER TABLE user ADD FOREIGN KEY (jid) REFERENCES job (id);
注意:设置级联操作,即主表进行删除或者更新之后,所对应的子表也会相对应的更新或者删除操作(CASCADE)
11、子查询(是指嵌入在其他sql查询语句的select语名,也叫嵌套查询)
单行子查询=》表示只返回一行数据的子查询语句
-- 查询和SMITH同一部门的员工 SELECT * FROM `emp` WHERE `deptno` = (SELECT `deptno` FROM `emp` WHERE `ename`="SMITH"); -- 输出 -- +-------+-------+---------+------+------------+---------+------+--------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | -- +-------+-------+---------+------+------------+---------+------+--------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | -- | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | -- | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | -- +-------+-------+---------+------+------------+---------+------+--------+
多行子查询=》表示返回多行数据的子查询语句(使用关键字In)
-- 查询10号部门都有哪些岗位,并且都有哪些员工在从事相关工作 SELECT * FROM `emp` WHERE `job` in (SELECT DISTINCT `job` FROM `emp` WHERE `deptno`=10); -- 输出 -- +-------+--------+-----------+------+------------+---------+------+--------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | -- +-------+--------+-----------+------+------------+---------+------+--------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | -- | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | -- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | -- | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | -- | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | -- | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | -- +-------+--------+-----------+------+------------+---------+------+--------+
内层语句的查询结果可以作为外层语句的查询结果,这种情况就称作为子查询。(注意子子查询要放在括号里面)
由IN,NOT IN,运算符,EXISTS等引发的子查询,以及由运算符引发的子查询
-- 由 IN 与 NOT IN 引发的子查询 SELECT id,name,age FROM user WHERE jid IN (SELECT id FROM job); SELECT id,name,age FROM user WHERE jid NOT IN (SELECT id FROM job); -- 由运算符引发的子查询 SELECT id,name,age FROM user WHERE jid=(SELECT id FROM job WHERE name ="编程"); -- 由EXISTS引发的子查询,表示当子查询的记录存在的情况下,才执行主查询的语句 SELECT id,name,age FROM user WHERE EXISTS (SELECT id FROM job WHERE id=20);
由 ANY SOME ALL 引发的子查询(下图表示的是右侧所对应的值在全组中的状态)
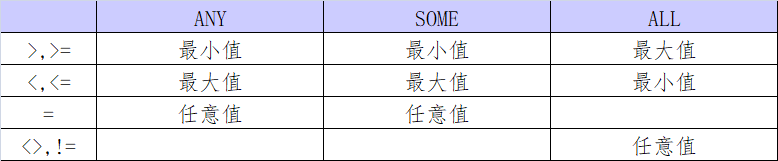
-- 数据展示 -- +----+------+-----+-----+ -- | id | name | age | jid | -- +----+------+-----+-----+ -- | 1 | 小明 | 20 | 1 | -- | 2 | 小红 | 23 | 2 | -- | 3 | 小陈 | 34 | 3 | -- | 4 | 小刚 | 27 | 4 | -- | 5 | 小列 | 18 | 5 | -- | 6 | 小小 | 26 | 4 | -- +----+------+-----+-----+ SELECT name,age FROM user WHERE age>ANY(SELECT age FROM user); -- 输出所有的结果 SELECT name,age FROM user WHERE age>=ALL(SELECT age FROM user); -- 输出小陈 34 SELECT name,age FROM user WHERE age = ANY(SELECT age FROM user); -- 输出全部记录,因为全部都能找到匹配的 SELECT id, name,age FROM user WHERE id<3 AND age !=ALL(SELECT age FROM user WHERE id>2); -- 输出id为1和2的记录
多列子查询 =》 如果我们的一个子查询,返回的结果是多列的,那我们就把这个子查询叫做多列子查询
-- 查询和小明数学,语文,英语成绩一样的学生 SELECT * FROM `student` WHERE (`chinese`,`english`,`math`) = (SELECT `chinese`,`english`,`math` FROM `student` WHERE `name`='小明');
括号里的字段和值是一一对应的关系
在from子句中使用的子查询
在from子句中出现在子查询,我们通常在会把在from中构建的临时表当作正常表来使用
-- 表emp -- +-------+--------+-----------+------+------------+---------+---------+--------+ -- | empno | ename | job | mgr | hiredate | sal | comm | deptno | -- +-------+--------+-----------+------+------------+---------+---------+--------+ -- | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | -- | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | -- | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | -- | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | -- | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | -- | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | -- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | -- | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | -- | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | -- | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | NULL | 30 | -- | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | -- | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | -- | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | -- +-------+--------+-----------+------+------------+---------+---------+--------+ -- 需求:显示高于自己部门平均工次的员工(名字,工资,部门平均工资) SELECT emp.ename,emp.sal,temp.avgSal FROM `emp`, (SELECT AVG(`sal`) AS 'avgSal', `deptno` FROM `emp` GROUP BY `deptno`) AS `temp` WHERE emp.deptno=temp.deptno AND emp.sal>temp.avgSal; -- 输出 -- +-------+---------+-------------+ -- | ename | sal | avgSal | -- +-------+---------+-------------+ -- | ALLEN | 1600.00 | 1566.666667 | -- | JONES | 2975.00 | 2443.750000 | -- | BLAKE | 2850.00 | 1566.666667 | -- | SCOTT | 3000.00 | 2443.750000 | -- | KING | 5000.00 | 2916.666667 | -- | FORD | 3000.00 | 2443.750000 | -- +-------+---------+-------------+
12、联合查询
UNION 语法:SELECT col_name,... FROM tab_name1 UNION SELECT col_name,...FROM tab_name2
UNION ALL 语法:SELECT col_name,... FROM tab_name1 UNION ALL SELECT col_name,...FROM tab_name2
注意:UNION 会去掉两个表中重复的值,而UNION ALL 只是简单的两个表的合并,并且UNION 或者 UNION ALL 前后的col_name的列数要一致,而且列名会以第一个SELECT 的列作为字段名称。
-- 举例,下面的名称就是第一个SELECT的AS后面的名称 SELECT name AS count FROM user UNION SELECT id FROM job -- 输出 -- +-------+ -- | count | -- +-------+ -- | 小明 | -- | 小红 | -- | 小陈 | -- | 小刚 | -- | 小列 | -- | 小小 | -- | 编程 | -- | 1 | -- | 2 | -- | 3 | -- | 4 | -- | 5 | -- | 7 | -- +-------+
13、正则表达式查询
使用方式,用 REGEXP "匹配方式" 就可以了,相当于JS里面的test 的功能。正则的写法同JS或者PHP一样。
语法: SELECT 字段名称,...FROM tab_name WHERE 字段名称 REGEXP "匹配模式"
-- 以小开始的数据 SELECT id,name FROM user WHERE name REGEXP '^小'; -- 以程结尾的数据 SELECT id,name FROM user WHERE name REGEXP '程$'; -- 包含明,红,刚的数据 SELECT id,name FROM user WHERE name REGEXP '明|红|刚';
14、mysql的三元运算符与IFNULL语句
CASE WHEN 条件 THEN 结果1 ELSE 结果2 END 语句
-- 与SUM合用 SELECT SUM(CASE WHEN c.checkresult= '合格' THEN 1 ELSE 0 END) AS qualified, SUM(CASE WHEN c.checkresult = '不合格' THEN 1 ELSE 0 END) AS disqualification, COUNT(*) AS count FROM tab_name WHERE [条件]; -- sql中ifnull用法: SELECT IFNULL(x,0,1) from tab_name; -- 解释:如果表a中x字段是null,输出为0,否则输出1 -- 扩展用法:select ifnull(SUM(x),0) from a;
ifnull(express1,express2) 当express1为空时返回express2函数,当express1不为空时返回express1函数,eg sum(ifnull(x,0));
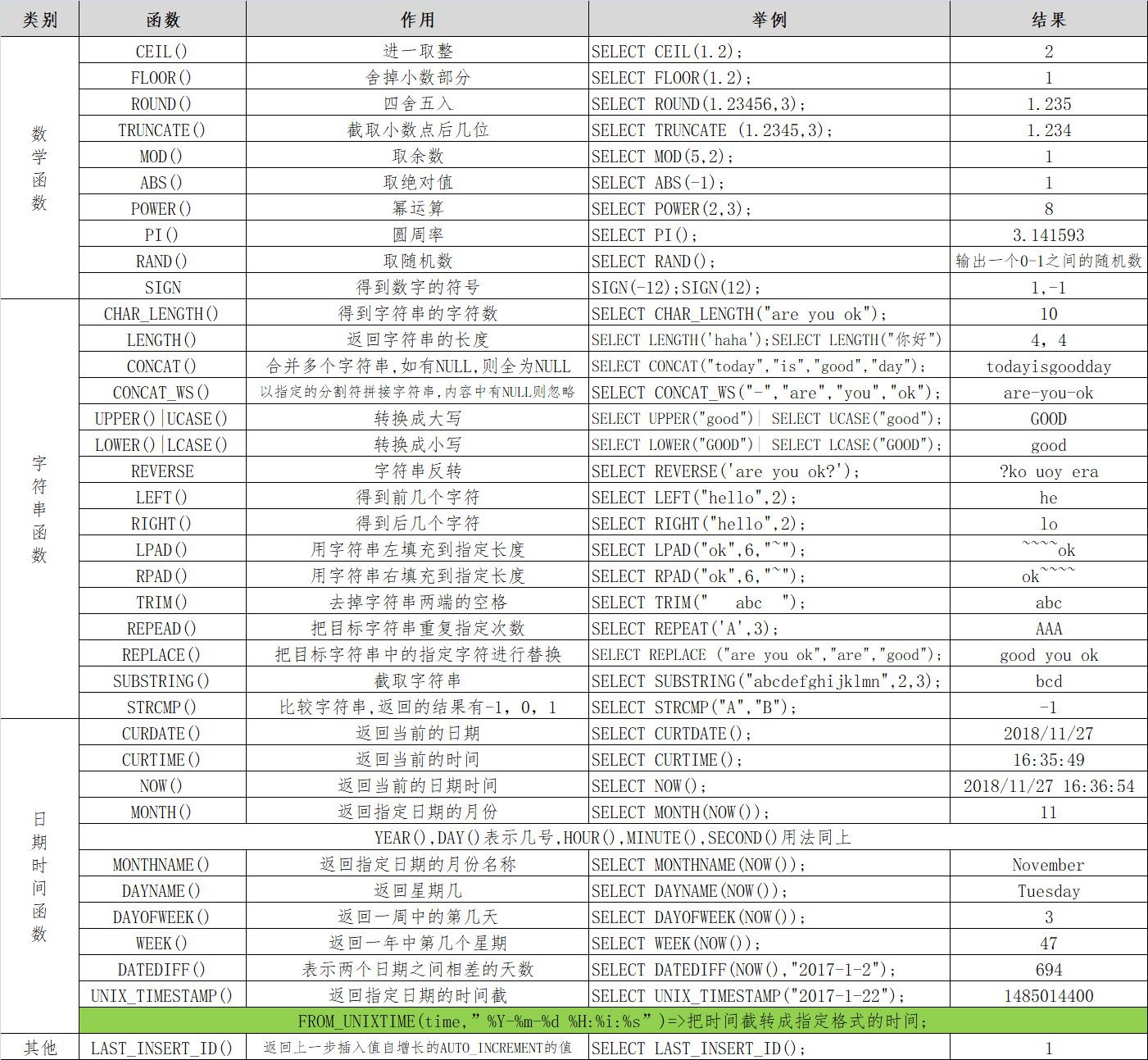
15、mysql 常用函数表(部份函数解析祥见函数那篇博客)
16、mysql 事务性操作
事务用于保证数据的一致性,它由一组相关的dml(增删改)语句组成,该组的dml语句要么全部成功,要么全部失败。
(注意:要引用支持事务的引擎如innodb)
mysql 事务的关键词
start transaction => 开始一个事务
savepoint => 保存点
rollback to => 回滚到某个保存点
rollback => 回滚
commit => 提交
在mysql 控制台实现事务控制
-- 插入案例表 CREATE TABLE IF NOT EXISTS `account` ( id INT UNSIGNED NOT NULL PRIMARY KEY, name VARCHAR(30) NOT NULL DEFAULT '', money DECIMAL(10,2) UNSIGNED NOT NULL DEFAULT 0.0 )CHARSET=utf8 COLLATE=utf8_general_ci ENGINE=innodb; INSERT INTO `account` (id, name, money) VALUES (111111, 'jim', 20000),(222222, 'jack', 32000);
实现事务的步骤
-- 开始一个事务 START TRANSACTION -- 声明一个保存点 SAVEPOINT first -- 执行增删改操作 -- 进行回退的操作 ROLLBACK TO first -- 如果操作完,没有问题,那么就可以正式提交 COMMIT
注意:当开启事务的时候系统自动设置了一个匿名的保存点,当需要回退的时候只需要用rollback就可以了,如果设置了多个保存点,进行回退的时候,当退到前面的保存点时,那么这个保存点后面的保存点就消失了
17、mysql 视图的增删查改
(1) 创建视图
create view 视图名 as select 语句;
(2) 视图的显示
show create view 视图名;
(3) 视图的修改
alter view 视图名 as 新的select 语句 ;
(4) 视图的删除
drop view 视图名1, 视图名2;
视图案例说明
l 以emp表为例
只让人查询emp的名称,job, 其它的信息不能查询? 这时我们就可以创建视图来解决这个问题 。
(1) 创建视图
create view myview as select ename, job from emp;
(2) 使用视图和使用一个普通表示一样样的.
(3) 对视图或者表的dml操作,会相互的影响
在视图中所有的操作可以和正常的表一样进行操作,如果要查看是否是视图表可以用show create table `视图表`
查看数据库中都有哪些视图用语句:show table status where comment='view'
例子=》 创建一个test的视图
CREATE VIEW `test` AS SELECT `account`.`name`, `account`.`money` FROM `account` WHERE `account`.`money`= (SELECT MAX(`money`) FROM `account`);
使用视图的好处
1.安全性
一些数据表有着重要的信息。有些字段是保密的,不能让用户直接看到。这时就可以创建一个视图,在这张视图中只保留一部分字段。这样,用户就可以查询自己需要的字段,不能查看保密的字段。
2.性能提升
关系数据库的数据常常会分表存储,使用外键建立这些表的之间关系。这时,数据库查询通常会用到连接(JOIN)。这样做不但麻烦,效率相对也比较低。如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用JOIN查询数据。
3.灵活性提升
如果系统中有一张旧的表,这张表由于设计的问题,即将被废弃。然而,很多应用都是基于这张表,不易修改。这时就可以建立一张视图,视图中的数据直接映射到新建的表。这样,就可以少做很多改动,也达到了升级数据表的目的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号