

1、MongoDB安装
建议安装 mongodb5.0,这样就不需要太多的手动配置,直接安装
配置环境变量,把安装目录下的bin添加到环境变量中
net start MongoDB // 启动服务
net stop MongoDB // 停止服务
注意:如果提示拒绝服务,那么cmd需要以管理的身份进行启动,mongodb的服务端口是27017
mongod --verson //查看版本
mongo // 启动mongo命令行管理界面
2、MongoDB的curd操作
创建数据库
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库
show dbs //查看所有数据库,不包含空数据库
db //显示当前数据库
show collections //查看所有集合
在数据库中创建集合
db.createCollection(name, options)
这里的name表示集合的名称, options表示配置

创建集合
db.createCollection('user') // 创建user的集合
在mongodb不需要去创建集合,当插入数据的时候会自动创建
插入数据
注意:在插入数据的时候,_id表示主键id,如果指定了则以指定的写入,如果不指定,系统会生成一个唯一的主键id
db.COLLECTION_NAME.insertOne({...data}) //插入一条数据
执行插入成功后返回, 相当于是上一语句的返回值
{
"acknowledged" : true,
"insertedId" : ObjectId("60fa07d62c50f9abe5c866c8") //自动生成的id
}
插入多条数据
db.COLLECTION_NAME.insertMany(
[...data],
{
ordered: <boolean> // 表示是否以乱序写入,默认是true
}
)
注意:如果将ordered参数设置为false,mongoDB可以打乱文档的写入的顺序,以便优化写入操作的性能, 在以顺序写入时一旦遇到错误,操作就会退出, 余下的文档无论正确与否都不会被写入, 如果以乱序写入文档,即使某些文档造成了错误,余下的正确文档仍然会被写入
创建多个文档或单个文档
db.COLLECTION_NAME.insert(
data | [...data],
{
ordered: <boolean>
}
)
注意:这条语句执行成功后,返回的是插入成功的条数,但是如果执行失败,那么将和insertMany的失败结果是一样的
insertOne, insertMany与Insert的区别
- 三个命令的返回的结果文件格式不一样
- insertOne与insertMany不支持db.collection.explain()命令,而insert支持db.collection.explain()命令
当用db.COLLECTION_NAME.save()处理一个新文档的时候,它会调用insert命令,所以返回的结果与Insert一致
ObjectId函数
通常来讲,可以使用ObjectId()来获得一个新的id,也可以使用该方法得到相应的创建时间
ObjectId() --得到一个新的id
ObjectId('6101d4e05a1ac41c41809c73') --得到以指定id的ObjectId
ObjectId('6101d4e05a1ac41c41809c73').getTimestamp() --获得创建的时间
读取数据
命令
db.COLLECTION_NAME.find(query, projection)
-- query 文档定义了读取操作时筛选文档的条件
-- projection 文档定义了对读取结果进行的投射即需要输出的字段
读取全部文档, 即不筛选也不投射
db.COLLECTION_NAME.find() 加上.pretty()可以使文档在命令行中显示的更清楚
匹配查询
db.user.find({name: 'abc'}) --表示查询名字为abc的数据
db.user.find({age: {$gt: 15}}) --表示查询年龄大于15的所有数据
db.user.find({name: {$lt: 'f'}}) --表示查询的姓名首字母在f之前的所有数据
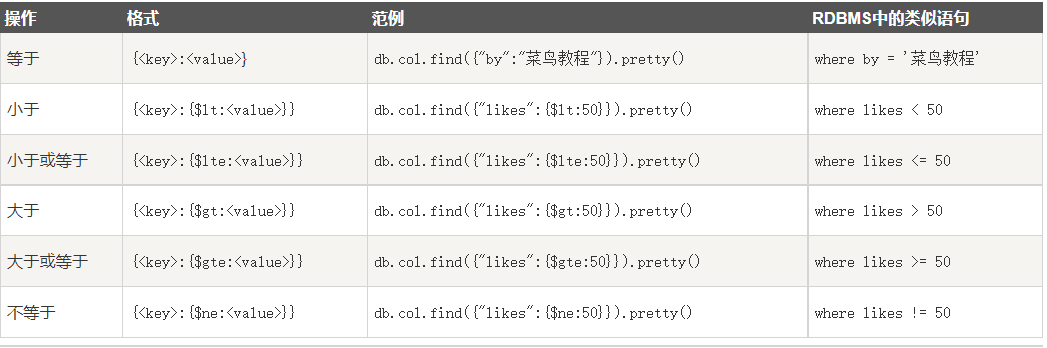
比较操作符
$in 匹配字符值与任一查询值相等的文档
$nin 匹配字符值与任一查询值都不相等的文档
db.user.find({name: {$in: ['aaa', 'bbb']}}) --表示读取名字是其中一项的所有组合
db.user.find({name: {$nin:['aaa', 'bbb']}}) --表示读取的名字不是其中一项的所有组合
逻辑操作符
$not 匹配筛选条件不成立的文档
$and 匹配多个筛选条件全部成立的文档
$or 匹配至少一个筛选条件成立的文档
$nor 匹配多个筛选条件全部不成立的文档
db.user.find({age: {$not: {$gt:12}}}) --表示筛选的数据的年龄小于等于12
db.user.find({$and: [{name: {$eq: 'aaa'}}, {age: {$gt: 5}}]}) --查找所有名字为aaa并且年龄大于5的所有数据
db.user.find({name: 'aaa', age: {$gt: 5}}) --与上面的效果一致
db.user.find({age: {$gt: 2, $lt: 30}}) --表示查找年龄大于2小于30的所有数据
db.user.find({$or: [{name: 'aaa'}, {name: 'bbb'}]}) --查找所有名字等于aaa或bbb的数据
db.user.find({name: {$in: ['aaa', 'bbb']}}) --与上面效果一样,但是命令简洁
db.user.find({$nor: [{name: 'aaa'}, {name: 'bbb'}]}) --表示查询名字即不等于aaa也不等于bbb的所有数据
字段操作符
$exists 匹配包含查询字段的文档, 值是true或false
$type 匹配字段类型符合查询值的文档
db.user.find({'age': {$exists: true}}) --表示读取所有含有age字段的所有数据
db.user.find({_id: {$type: “string”}}) --表示读取文档主键是字符串的所有值
db.user.find({_id: {$type: [“string”, “number”]}}) --表示读取文档主键是字符串或数据值
db.user.find({_id: {$type: ["objectId", "object"]}}) --表示读取文档主键是ObjectId或都是复合主键的情况
db.user.find({name: {$type: “null”}}) --找到所有name的值是null的文档
数组操作符
$all 匹配数组字段中包含所有查询值的文档
$elemMatch 匹配数组字段中至少存在一个值满足筛选条件的文档
--数据:{_id: ***, name: 'aaa', age: '12', addr: ["fujian", 'jiangxi']}
db.user.find('addr': {$all: ['fujian', 'jiangxi']}) --表示匹配到addr这个字段数组里的值,不论顺序,全部匹配即可
db.user.find({addr: {$elemMatch: {$eq: "fujian"}}}) --表示在addr数组字段中包含了fujian这个条件和筛选
db.user.find({addr: {$all: [{$elemMatch: {$eq:'fujian'}}, {$elemMatch: {$eq:'jiangxi'}}]}}) --表示在addr这个数组字段中全部满足匹配指定值
正则操作符
$regex 匹配满足正则表达式的文档
语法
{<field>: { : /pattern/, : '<options>' }}
{<field>: { : /pattern/<options> }}
使用
--在和$in操作符一起使用时,只能使用/prattern/<options>的方式
db.user.find({name: {$in: [/^a/, /^b/]}}) --表示查询name以a或者以b开头的所有字段
db.user.find({name: {$in: [/i/i, /A/i]}}) --表示查询name中包含i与A的所有数据,不区分大小写
--平时推荐使用{<field>: {: /pattern/, : '<options>'}}
db.user.find({name: {$regex: /A/, $options: 'i'}}) --表示查询姓名里包含A的所有数据,不区分大小写
文档游标操作
db.COLLECTION_NAME.find()返回的是一个文档集合游标, 在不迭代游标的情况下, 只列出前20个文档
var mycursor = db.user.find() --可以获得文档游标
注意: 当遍历完游标中所有的文档后,或者在10分钟后,游标就会自动关闭
可以使用noCursorTimeout()函数来取消10分钟后游标自动关闭的操作
var mycursor = db.user.find().noCursorTimeout() --取消游标自动关闭
mycursor.close() --手动关闭游标
在这之后, 在不遍历游标的情况下,需要手动进行关闭,但是如果遍历完游标,游标也会自动关闭
游标函数
mycursor.hasNext() --判断是否有下一个
mycursor.next() --取出下一个数据
while(mycursor.hasNext()) {
printjson(mycursor.next())
}
mycursor.forEach()
mycursor.forEach(printjson) --打印出所有的文档
mycursor.limit() --相同于mysql里的limit表示返回指定数量的文档
mycursor.skip() --相当于mysql里的offset表示跳过指定数据的文档
mycursor.skip(2).limit(2) --表示从第2条开始打印,打印出两条数据
mycursor.count(<applySkipLimit>)
--默认情况下, <applySkipLimit>为false, 即mycursor.count()不会考虑mycursor.skip()和mycursor.limit()的效果, 但是如果传入true那么就会受影响
--在数据库分布式结构比较复杂时,元数据中的文档数量可能不准确,在这种情况下,应该避免应用不提供筛选条件的mycursor.count()函数,而使用聚合管道来计算文档数量
mycursor.sort(<document>)
--这里的document定义了排序要求
--1表示由小到大的排列,-1表示由大到小的排列
例如
mycursor.sort({age: -1, score: 1}) --表示年龄小大到小,成绩由小到大的排列
注意:执行顺序 sort > skip > limit
文档投影
db.COLLECTION_NAME.find(<query>, <projection>) --不使用投影的时候,返回的是筛选条件的完整字段文档
projection语法 {field:inclusion} --1表示返回字段 0表示不返回字段
db.user.find({}, {name: 1, _id: 0}) --那么就只返回name字段,默认文档_id是会被返回的
注意:除了文档主键之外, 我们不可以在投影文档中混合使用包含和不包含这两种投影操作,即要么就列出所有想要的字段,要么就列出所有不想要的字段
db.user.find({}, {name: 1, _id: 0}) --可以被允许,因为_id是文档主键
db.user.find({}, {name: 1, age:0}) --不可以执行,因为两者都不是文档主键,并且同时存在
db.user.find({}, {name: 0}) --表示打印除了name字段以外的所有字段
--对数组进行文档投影
db.user.find({}, {name:1, _id:0, addr:{$elemMatch:{$eq: 'fujian'}}}) --表示如果addr中含有fujian的值,那么就显示,否则这个字段不显示
更新文档
db.COLLECTION_NAME.update()
db.COLLECTION_NAME.update(<query>, <update>, <options>)
--<query>文档定义了更新操作时筛选文档的条件, 与find里的筛选条件相同
--<update>文档提供了更新的内容
--<options>文档声明了一些更新操作的参数 {multi: <boolean>}表示是否更新多个文档即把所有匹配到的内容进行全量更新 {upsert: <boolean>}决定是去更新还是创建记录,配置该字段后,如果
没有匹配到文件就会创建一个对应文档 {arrayFilters: [...]}表示操作数组的过滤
--_id字段是不能被改变的
db.user.update({name: 'even'}, {name: 'even', age: 32}) --注意更新的时候需要把没有变化的字段写上去,否则系统会认为是删除字段的操作, 如果原来没有的字段,那么就视为添加字段
--默认只更新匹配到的第一条数据
文档更新操作符
$set 更新或新增字段(不会删除字段)
db.user.update({name: 'even'}, {$set: {sex: "man"}}) --会添加sex字段,但是不会删除没有写入的原有字段
db.user.update({name: 'even'}, {$set: {'info.fav': 'football'}}) --前提是info是个对象,那么更新对象用info.fav,需要加引号
--更新数组
db.user.update({name: 'bill'}, {$set: {'addr.1': "beijing"}}) --这里的’addr.1‘是表示原有数组的第一项, 如果是添加那么则可以把下标往后添加
$unset 删除字段
db.user.update({name: 'even'}, {$unset: {'like.test': ''}}) --会删除like对象下的test字段
db.user.update({name: 'even'}, {$unset: {'addr.0': ''}}) --会把add数组中的第一项删除,但是这里的删除是指把值设为null而不改变长度
$rename 重命名字段 --如果rename的字段不存在,那么文档将不会被改变, 如果新的字段在原来文档中就有,那么系统会先删除原有字段,然后再赋值新的字段
--可以利用$rename更把对象中的值放到外面一层,或者把外面一层的数据放到内嵌的对象中
db.user.update({name: 'even'}, {$rename: {info: "like.info"}}) --把外面的info字段放到like对象中
--注意:类似的操作对数组不能操作
$inc 加减字段值
$mul 相乘字段值
db.user.update({name: 'aaa'},{$inc: {age: 1}}) --age在原有的基础上加1,如果是负数,那么就是减1
db.user.update({name: 'aaa'},{$mul: {age: 2}}) --age在原有的基础出乘于2,如果是小数,那么就是除于
注意:以上方法只能使用在数值上,如果操作的是不存在的字段,那么会创建对应的字段,并且赋值为0
$min 比较减小字段值
$max 比较增大字段值
db.user.update({name: 'aaa'}, {$min: {age: 13}}) --表示找到指定的记录,比对age的值,取原本的值与当前的13进行比较,把值赋值为较小的值,如果原本的值比较小,那么数据不改变
db.user.update({name: 'aaa'}, {$max: {age: 33}}) --表示找到指定的记录,比对age的值,取原本的值与当前的33进行比较,把值赋值为较大的值,如果原本的值比较大,那么数据不改变
注意:如果比较不存在的值 ,那么系统默认会添加字段,并把值赋值给新添加的字段,如果比较的数据类型不一致,那么会比较BSON数据类型的排序规则进行比较
数组更新操作符
$addToSet 向数组增添元素
db.user.update({name: 'yes'}, {$addToSet: {fav: {$each: ['football', 'computer']}}})
--表示把【football, computer】中的每一项添加到fav中,而不是把总的数组添加到fav字段中
--$addToSet是表示字符串,布尔值,数值型添加不重复的值,如果重复的值则不添加,如果是数组或object那么要顺序值全部相等时视为相等
$pop 从数组删除元素
db.user.update({name: 'yes'}, {$pop: {fav: 1}}) --表示删除fav数组中的最后一项
db.user.update({name: 'yes'}, {$pop: {fav: -1}}) --表示删除fav数组中的第一项
db.user.update({name: 'yes'}, {$pop: {fav.3: -1}}) --表示删除fav数组中第四个数组的第一项
$pull 从数组中有选择性的移除元素
db.user.update({name: 'yes'}, {$pull: {fav: {$regex: /ea/, $options: 'i'}}}) --表示删除掉fav数组中包含有ea字符的所有项
db.user.update({name: 'yes'}, {$pull: {fav: {$elemMatch: {$regex: /ea/, $options: 'i'}}}}) --表示删除fav数组中所有含有ea字符串的子数组
$pullAll 从数组中有选择性的移除元素 相当于{$put: {<field>: $in: [<value1>, <value2>] }}}
语法: { $pullAll: {<field>: [<value1>, <value2>] }}}
$push 向数组中增添元素
向数组中添加元素,$push与$addToSet命令相似,但是$push命令的功能更强大,和$addToSet命令一样,如果$push中指定的数组字段不存在,这个字段会被添加到原文档中, 也可以与$each搭配使用
db.user.update({name: 'yes'}, {$push: {fav: {$each: ['eee', 'fff']}}}) --表示把【eee, fff】插入到fav数组的最后
db.user.update({name: 'yes'}, {$push: {fav: {$each: ['eee', 'fff'], $position: 0}}}) --表示把【eee, fff】插入到fav数组的第一位
$sort 对数据中的元素进行排序需要与$push, $each搭配使用
db.user.update({name: 'yes'}, {$push: {fav: {$each: ['eee', 'fff'], $sort: 1}}}) --表示把【eee, fff】插入到fav数组,并且进行由小到大的排序
$slice 从数组截取指定长度的数组,并且赋值给数组
数组中修改数据的操作
db.COLLECTION_NAME.update({<array>: <query selector>}, {<update operator>: {"array.$": value}})
--更新数组中的特定元素
--$是数组中第一个符合筛选条件的数组元素的点位符
> db.user.find({name:"yes"})
--{ "_id" : ObjectId("6105d6fe38ed539a9de23601"), "name" : "yes", "age" : 12, "fav" : [ "fff", "aaa", "bbb", "ccc", "ddd", "fff" ] }
> db.user.update({name: 'yes', fav: 'fff'}, {$set: {"fav.$": 'haha'}})
--WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user.find({name:"yes"})
--{ "_id" : ObjectId("6105d6fe38ed539a9de23601"), "name" : "yes", "age" : 12, "fav" : [ "haha", "aaa", "bbb", "ccc", "ddd", "fff" ] }
> db.user.find()
--{ "_id" : ObjectId("6113031aa9a15f04e8fac55c"), "name" : "even", "json" : [ { "name" : "aaa", "age" : 1 }, { "name" : "bbb", "age" : 2 }, { "name" : "ccc", "age" : 3 } ] }
> db.user.update({name:"even", "json.name": "bbb"}, {$set: {"json.$.age":18}})
--WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user.find()
--{ "_id" : ObjectId("6113031aa9a15f04e8fac55c"), "name" : "even", "json" : [ { "name" : "aaa", "age" : 1 }, { "name" : "bbb", "age" : 18 }, { "name" : "ccc", "age" : 3 } ] }
注意:只是更改符合条件的第一个元素
db.user.find()
--{ "_id" : ObjectId("6111ab9f4ddd3fd50dd2c37a"), "name" : "test", "age" : 12, "fav" : [ "bbb", "ccc", "ddd", "fff", [ "111", "222" ] ] }
db.user.update({name: "test"}, {$set: {"fav.$[]": 'test'}})
--WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
db.user.find()
--{ "_id" : ObjectId("6111ab9f4ddd3fd50dd2c37a"), "name" : "test", "age" : 12, "fav" : [ "test", "test", "test", "test", "test" ] }
注意:以上代码会把所以值都替换成指定的值
db.COLLECTION_NAME.save(<document>): 如果document文档中包含了_id字段, save()命令将会调用db.COLLECTION_NAME.update()命令{upsert: true}
如果需要更改数组中的多个值, 可以使用arrayFilters进行修改
> db.user.find({name: "even"})
--{ "_id" : ObjectId("6113031aa9a15f04e8fac55c"), "name" : "even", "json" : [ { "name" : "aaa", "age" : 3 }, { "name" : "aaa", "age" : 3 }] }
> db.user.update({name:"even"}, {$set: {"json.$[elem].age": 12}}, {arrayFilters: [{"elem.name": "aaa"}]})
--WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user.find({name: "even"})
--{ "_id" : ObjectId("6113031aa9a15f04e8fac55c"), "name" : "even", "json" : [{ "name" : "aaa", "age" : 12 }, { "name" : "aaa", "age" : 12 }]}
>
注意:这里的elem是指arrayFilters匹配到的元素, 具体可以参看官网 https://docs.mongodb.com/manual/reference/method/db.collection.update/#std-label-update-arrayFilters
删除文档
使用语句
db.collection.remove(<query>,<justOne>) --默认是删除所有满足条件的所有文档,如果只需要删除满足条件的第一篇文档,那么justOne可以设置为true
db.collection.remove({}) --删除所有文档
db.collection.drop() --表示除了删除文档,并且也把集合和索引都删除
注意:如果文档很多时,使用remove有的时候效率不高,这个时候推荐使用drop再创建集合,这样效率更高
3、mongodb的聚合操作
语法
db.COLLECTION_NAME.aggregate(<pipeline>, <options>)
--pipeline文档定义了操作中使用的聚合管道阶段和聚合操作符
--文档声明了一些聚合操作的参数
常见的聚合表达式
--字段路径表达式
$<field> --使用$来指示字段路径
$<field>.<sub-field> --使用$和. 来指示内嵌文档字段路径
--系统变量表达式
$$<variable> --使用$$来指示系统变量
如$$CURRENT --指示管道中当前操作的文档(相当于this), $$CURRENT.<field>和$<field>是等效的
--常量表达式
$literal: <value> --指示常量<value>
$literal: "$name" --指示常量字符串“$name”
$project --对输入文档进行再次投影
$match --对输入文档进行再次筛选
$limit --筛选出管道内前N篇文档
$skip --跳过管道内第N篇文档
$unwind --展开输入文档中的数组字段
$sort --对输入的文档进行排序
$lookup --对输入的文档进行查询操作
$group --对输入的文档进行分组
$out --将管道中的文档进行输出
注意:以下的操作使用的数据如下
{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28 }
{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30 }
{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29 }
$project --对输入文档进行再次投影
> db.user.aggregate([{$project: {_id: 0, name: "$name.first", age: 1 }}])
--输出
--{ "name" : "bill", "age" : 28 }
--{ "name" : "ven", "age" : 30 }
--{ "name" : "even", "age" : 29 }
> db.user.aggregate([{$project: {_id: 0, age: 1, name:["$name.first", "$name.middle", "$name.last"]}}])
--输出,如果是没有的字段,那么会输出null
--{ "age" : 28, "name" : [ "bill", null, "yu" ] }
--{ "age" : 30, "name" : [ "ven", null, "yu" ] }
--{ "age" : 29, "name" : [ "even", null, "yu" ] }
$match --对输入文档进行再次筛选
$match中使用的文档筛选语法, 和读取文档时的筛选语法相同,与find时的筛选用法是一样的
> db.user.aggregate([{$match: {"name.first": "even"}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29 }
> db.user.aggregate([{$match: {$and: [{age: {$gte: 29}}, {age: {$lte: 30}}]}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30 }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29 }
--$match与$project进行配合使用
> db.user.aggregate([{$match: {$and: [{age: {$gte: 29}}, {age: {$lte: 30}}]}}, {$project: {_id: 0, age: 1, name: "$name.first"}}])
--{ "age" : 30, "name" : "ven" }
--{ "age" : 29, "name" : "even" }
注意: $match是一个很常用的聚合阶段,应该尽量在聚合管道的开始阶段应用$match, 这样可以减少后续阶段中需要处理的文档数量, 优化聚合操作的性能
$limit --筛选出管道内前N篇文档
$skip --跳过管道内第N篇文档
> db.user.find()
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28 }
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30 }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29 }
> db.user.aggregate([{$skip: 1}, {$limit: 1}])
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30 }
$unwind --展开输入文档中的数组字段
为了方便演示对原始数据做些调整
{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28 }
{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "param" : [ ] }
{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : [ "aaa", "bbb" ] }
> db.user.aggregate([{$unwind: {path: "$param"}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : "aaa" }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : "bbb" }
注意:这个方法会把对应的数据拆开展示,但是不展示param为null [], 或者不存在的情况
> db.user.aggregate([{$unwind: {path: "$param", includeArrayIndex: "index"}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : "aaa", "index" : NumberLong(0) }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : "bbb", "index" : NumberLong(1) }
添加索引字段
> db.user.aggregate([{$unwind: {path: "$param", includeArrayIndex: "index", preserveNullAndEmptyArrays: true}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28, "index" : null }
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "index" : null }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : "aaa", "index" : NumberLong(0) }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : "bbb", "index" : NumberLong(1) }
把没有该字段的数据也进行一次展开
$sort --对输入的文档进行排序
> db.user.aggregate([{$sort: {age: 1}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28 }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "param" : [ "aaa", "bbb" ] }
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "param" : [ ] }
注意:用法与上面写的sort的用法一样,1表示升序, -1表示降序
$lookup --对输入的文档进行查询操作
使用单一字段进行查询
$lookup: {
from : <collection to join>,
localField:<field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
--同一数据库中的另一个查询集合

注意: 这个语法相当于mysql中的leftjoin的用法
当前的演示案例的数据
> db.user.find()
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28 }
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30 }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29 }
> db.info.find()
--{ "_id" : ObjectId("6118cb10f70c4e8e186d8a65"), "name" : "ven", "desc" : "this is ven desc" }
--{ "_id" : ObjectId("6118cb10f70c4e8e186d8a66"), "name" : "even", "desc" : "this even desc" }
--{ "_id" : ObjectId("6118cb10f70c4e8e186d8a67"), "name" : "bill", "desc" : "this is bill desc" }
使用$lookup
> db.user.aggregate([{$lookup:{from: "info", localField: "name.first", foreignField: "name", as: "info"}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28, "info" : [ { "_id" : ObjectId("6118cb10f70c4e8e186d8a67"), "name" : "bill", "desc" : "this is bill desc" } ] }
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "info" : [ { "_id" : ObjectId("6118cb10f70c4e8e186d8a65"), "name" : "ven", "desc" : "this is ven desc" } ] }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "info" : [ { "_id" : ObjectId("6118cb10f70c4e8e186d8a66"), "name" : "even", "desc" : "this even desc" } ] }
注意:如果localField是一个数组,那么info出来的数据也会是一一对应的数组, 那就可以配合$unwind进行使用,如果匹配不到,那么返回的是一个空数组
对字段进行筛选可以使用关键字pipeline
> db.user.aggregate([{$lookup: {from: "info", localField: "name.first", foreignField: "name", pipeline: [{$project: {_id: 0, desc: 1}}], as: "info"}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28, "info" : [ { "desc" : "this is bill desc" } ] }
--{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "info" : [ { "desc" : "this is ven desc" } ] }
--{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "info" : [ { "desc" : "this even desc" } ] }
--{ "_id" : ObjectId("6118ceb2f70c4e8e186d8a68"), "name" : { "first" : "ctbu", "last" : "yu" }, "age" : 23, "info" : [ ] }
$lookup的复杂运用
$lookup: {
from: <collection to join>,
let: {<var_1>: <expression>, ..., <var_n>: <expression>},
pipeline: [<pipeline to execute on the collection to join>],
as: <output array field>
}
--对查询集合中的文档使用聚合阶段进行处理, 这里的let是可选参数
对查询集合中的文档使用聚合阶段进行处理时,如果需要参考管道文档中的字段, 则必须使用let参数对字段进行声明
> db.user.aggregate([{$lookup:{from: "info", pipeline: [{$project: {_id: 0, desc: 1}}], as: "info"}}])
--{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28, "info" : [ { "desc" : "this is ven desc" }, { "desc" : "this even desc" }, { "desc" : "this is bill desc" } ] } --{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "info" : [ { "desc" : "this is ven desc" }, { "desc" : "this even desc" }, { "desc" : "this is bill desc" } ] } --{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "info" : [ { "desc" : "this is ven desc" }, { "desc" : "this even desc" }, { "desc" : "this is bill desc" } ] } --{ "_id" : ObjectId("6118ceb2f70c4e8e186d8a68"), "name" : { "first" : "ctbu", "last" : "yu" }, "age" : 23, "info" : [ { "desc" : "this is ven desc" }, { "desc" : "this even desc" }, { "desc" : "this is bill desc" } ] }
上面没有对条件做限定,只做了字段展示,所以会全部显示出来
> db.user.aggregate([{$lookup: {from: "info", let: {n: "$name.first"}, pipeline: [{$match: {$expr: {$eq: ["$name", "$$n"]}}}, {$project: {_id: 0, desc: 1}}], as: "info"}}]) --{ "_id" : ObjectId("6115afe39526539ff7a05d9f"), "name" : { "first" : "bill", "last" : "yu" }, "age" : 28, "info" : [ { "desc" : "this is bill desc" } ] } --{ "_id" : ObjectId("6115afe39526539ff7a05da0"), "name" : { "first" : "ven", "last" : "yu" }, "age" : 30, "info" : [ { "desc" : "this is ven desc" } ] } --{ "_id" : ObjectId("6115afe39526539ff7a05da1"), "name" : { "first" : "even", "last" : "yu" }, "age" : 29, "info" : [ { "desc" : "this even desc" } ] } --{ "_id" : ObjectId("6118ceb2f70c4e8e186d8a68"), "name" : { "first" : "ctbu", "last" : "yu" }, "age" : 23, "info" : [ ] }
注意: 在上面的表达式中,let中的n是表示对user中的字段引用,而match中需要对两个字段的值进行比较,有用到$$n,所以要用表达式$expr,但是$eq的写法区别于上面的写法,因为这里要对两个表的值进行引用,所以采用的数组的写法,在引用定义的变量时需要用$$进行修饰, $name.first表示的是当前表的字段, pipeline表示的是连接表的信息
> db.user.aggregate([{$project: {_id: 0, name: "$name.first", age: 1}},{$lookup: {from: "info", let: {n: "$name.first", a: "$age"}, pipeline: [{$project: {_id: 0, name: 1, desc: 1}}, {$match: {$expr: {$and: [{$eq: ["$name", "$$n"]}]}}}], as: "info"}}])
--{ "age" : 28, "name" : "bill", "info" : [ { "name" : "bill", "desc" : "this is bill desc" } ] }
--{ "age" : 30, "name" : "ven", "info" : [ { "name" : "ven", "desc" : "this is ven desc" } ] }
--{ "age" : 29, "name" : "even", "info" : [ { "name" : "even", "desc" : "this even desc" } ] }
--{ "age" : 23, "name" : "ctbu", "info" : [ ] }
注意:以上写法有点失误,在pipeline里面需要先match再project, 不然很容易所匹配的字段被project后,match找不到,所以建议先match, 再project
$group --对输入的文档进行分组
$group: {
_id: <expression>,
<field1>: { <accumulartor1> : <expression1> },
...
}
注意:这里的_id表示用于分组的字段, 暂时没有发现可以其他字段进行操作
> db.goods.find()
--{ "_id" : ObjectId("611b3fd0ab556f9418ed89c6"), "name" : "apple", "price" : 12, "count" : 5 }
--{ "_id" : ObjectId("611b3fd0ab556f9418ed89c7"), "name" : "pear", "price" : 11, "count" : 20 }
--{ "_id" : ObjectId("611b3fd0ab556f9418ed89c8"), "name" : "banana", "price" : 16, "count" : 5 }
--{ "_id" : ObjectId("611b3fd0ab556f9418ed89c9"), "name" : "grape", "price" : 9.8, "count" : 63 }
--{ "_id" : ObjectId("611b4026ab556f9418ed89ca"), "name" : "apple", "price" : 12, "count" : 1 }
--{ "_id" : ObjectId("611b4026ab556f9418ed89cb"), "name" : "banana", "price" : 16, "count" : 80 }
--{ "_id" : ObjectId("611b4026ab556f9418ed89cc"), "name" : "grape", "price" : 9.8, "count" : 12 }
--{ "_id" : ObjectId("611b4046ab556f9418ed89cd"), "name" : "apple", "price" : 12, "count" : 1 }
--{ "_id" : ObjectId("611b4046ab556f9418ed89ce"), "name" : "banana", "price" : 16, "count" : 80 }
--{ "_id" : ObjectId("611b4046ab556f9418ed89cf"), "name" : "grape", "price" : 9.8, "count" : 12 }
> db.goods.aggregate([{$group: {_id: "$name", sum: {$sum: {$multiply: ["$price", "$count"]}}, avg: {$avg: "$price"}, max: {$max: "$count"}, min: {$min: "$count"}}}])
--{ "_id" : "pear", "sum" : 220, "avg" : 11, "max" : 20, "min" : 20 }
--{ "_id" : "apple", "sum" : 84, "avg" : 12, "max" : 5, "min" : 1 }
--{ "_id" : "banana", "sum" : 2640, "avg" : 16, "max" : 80, "min" : 5 }
--{ "_id" : "grape", "sum" : 852.6000000000001, "avg" : 9.8, "max" : 63, "min" : 12 }
注意: 这里的$sum表示求和, $multiply表示求积, $avg表示求平均数, $max表示求最大值 , $min表示求最小值, 如果是$sum:1则是表示求文档的数量
> db.goods.aggregate([{$group: {_id: "$name", count: {$sum: 1}}}])
--{ "_id" : "banana", "count" : 3 }
--{ "_id" : "apple", "count" : 3 }
--{ "_id" : "grape", "count" : 3 }
--{ "_id" : "pear", "count" : 1 }
使用聚合函数求所有的文档的聚合值(把_id设置为null)
> db.goods.aggregate([{$group: {_id: null, count: {$sum: 1}, sum: {$sum: {$multiply: ["$price", "$count"]}}}}])
--{ "_id" : null, "count" : 10, "sum" : 3796.6 }
--把所有名称都放到一个数组里
> db.goods.aggregate([{$group: {_id: null, count: {$sum: 1}, sum: {$sum: {$multiply: ["$price", "$count"]}}, collect: {$push: "$name"}}}])
--{ "_id" : null, "count" : 10, "sum" : 3796.6, "collect" : [ "apple", "pear", "banana", "grape", "apple", "banana", "grape", "apple", "banana", "grape" ] }
--把所有名称都放到一个数组里,并且不重复
> db.goods.aggregate([{$group: {_id: null, count: {$sum: 1}, sum: --{$sum: {$multiply: ["$price", "$count"]}}, collect: {$addToSet: "$name"}}}])
{ "_id" : null, "count" : 10, "sum" : 3796.6, "collect" : [ "banana", "pear", "apple", "grape" ] }
$out --将管道中的文档进行输出
> db.goods.aggregate([{$group: {_id: null, count: {$sum: 1}, sum: {$sum: {$multiply: ["$price", "$count"]}}, collect: {$addToSet: "$name"}}}, {$out: "output"}])
注意: 该操作会把数据结果写入到output这个新的文档中
通常来讲, 每个聚合管道阶段使用的内存不能超过100MB,如果超过了就会报错,为了让程序执行下去可以添加 allowDiskUse: true配置,当内存不足时,会将操作数据写入临时文件中,这个临时文件会被写入dbPath下的_tmp文件夹下,默认值是/data/db
> db.goods.aggregate([{$group: {_id: "$name"}}],{allowDiskUse: true})
{ "_id" : "banana" }
{ "_id" : "pear" }
{ "_id" : "apple" }
{ "_id" : "grape" }
注意:对数组值的引用常见于 $project, $unwind, $lookup, $group
复杂例子操作
数据库
> show collections
--bag
--goods
--user
> db.bag.find()
--{ "_id" : ObjectId("612c140a2958f075bfdde1a8"), "name" : "bill", "goods" : "apply", "count" : 3 }
--{ "_id" : ObjectId("612c140a2958f075bfdde1a9"), "name" : "even", "goods" : "pear", "count" : 2 }
--{ "_id" : ObjectId("612c140a2958f075bfdde1aa"), "name" : "ven", "goods" : "grape", "count" : 6 }
--{ "_id" : ObjectId("612c140a2958f075bfdde1ab"), "name" : "bill", "goods" : "orange", "count" : 12 }
> db.goods.find()
--{ "_id" : ObjectId("612c113f2958f075bfdde1a1"), "name" : "apply", "price" : 11 }
--{ "_id" : ObjectId("612c113f2958f075bfdde1a2"), "name" : "pear", "price" : 12 }
--{ "_id" : ObjectId("612c113f2958f075bfdde1a3"), "price" : 13, "name" : "grape" }
--{ "_id" : ObjectId("612c113f2958f075bfdde1a4"), "name" : "orange", "price" : 10 }
> db.user.find()
--{ "_id" : ObjectId("612c144a2958f075bfdde1ac"), "name" : "bill", "age" : 18 }
--{ "_id" : ObjectId("612c144a2958f075bfdde1ad"), "name" : "ven", "age" : 12 }
--{ "_id" : ObjectId("612c144a2958f075bfdde1ae"), "name" : "even", "age" : 28 }
进行嵌套查询
db.bag.aggregate([
{$project: {_id: 0, name: 1, goods: 1, count: 1}},
{
$lookup: {
from: "goods",
let: {g: '$goods', c: '$count'},
pipeline: [{$match: {$expr: {$eq: ["$name", "$$g"]}}}, {$project: {_id: 0, price: 1, sum: {$multiply: ['$$c', '$price']}}}],
as: "msg"
}
},
{
$lookup: {
from: "user",
let: {n: "$name"},
pipeline: [{$match: {$expr: {$eq: ["$name", "$$n"]}}}, {$project: {_id: 0, age: 1}}],
as: "user"
}
},
])
结果:
--{ "name" : "bill", "goods" : "apply", "count" : 3, "msg" : [ { "price" : 11, "sum" : 33 } ], "user" : [ { "age" : 18 } ] }
--{ "name" : "even", "goods" : "pear", "count" : 2, "msg" : [ { "price" : 12, "sum" : 24 } ], "user" : [ { "age" : 28 } ] }
--{ "name" : "ven", "goods" : "grape", "count" : 6, "msg" : [ { "price" : 13, "sum" : 78 } ], "user" : [ { "age" : 12 } ] }
--{ "name" : "bill", "goods" : "orange", "count" : 12, "msg" : [ { "price" : 10, "sum" : 120 } ], "user" : [ { "age" : 18 } ] }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号