
shell语言学习(二)
1、概念
Shell是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务, Shell脚本(shell script),是一种为Shell编写的脚本程序。我们经常说的shell通常都是指shell脚本。
2、脚本输出方法
a、echo [选项] [内容]
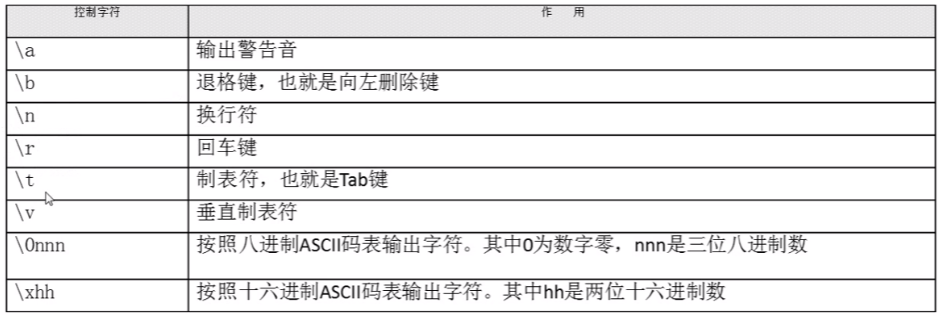
当选项为 -e的时候,内容里面出现以上的内容时,就会识别上表中的符号
如 echo -e “hel\blo” => 输出 helo
echo输出颜色表示:echo -e "\e[1;31mthis is test \e[0m"
#30m: 黑色 #31m:红色 #32m:绿色 #33m:黄色 #34m:蓝色 #35m:洋红 #36m:青色 #37m:白色
3、脚本的声明
#!/bin/bash //可以用echo $SHELL进行查看
echo 'hello world!'
说明:
#!告诉系统这个脚本需要什么解释器来执行。- 文件扩展名
.sh不是强制要求的。 - 方法1 直接运行解释器,
hello.sh作为 Shell 解释器的参数。此时 Shell 脚本就不需要指定解释器信息,第一行可以去掉。 - 方法2 hello.sh 作为可执行程序运行,Shell 脚本第一行一定要指定解释器。
注意:在shell中常常会看到exit 0 这里的0表示成功退出非0表求错误退出。
添加别名的方法
alias 查看系统下所有另名
alias rm=''rm -i" 添加另外 ,但这种方式在系统重启后就会失效
如果需要永久的保留,就需要写入变量配置文件
vim ~/.bashrc
unalias 别名 删除别名
更改完后 source ~/.bashrc 或者 .~/.bashrc 这样配置文件才会生效
4、脚本的运行
// 方法1 sh hello.sh // 方法2 u表示所有者 x表示执行权限 chmod u+x hello.sh ./hello.sh
5、shell变量
定义:Shell 变量分为系统变量和自定义变量。系统变量有$HOME、$PWD、$USER等,显示当前 Shell 中所有变量:set, 查看系统变量用env 。
变量名可以由字母、数字、下划线组成,不能以数字开头。
#!/bin/bash
name='testName' //注意:这里是不能有空格的
readonly name //一旦声明了readonly,那么这个为师是只读的,不允许更改
//使用变量
echo $name
//或者
echo ${name}
删除变量
#!/bin/bash
name='aaa';
readonly name;
age=20;
unset name; //readonly 的变量是不能被删除
unset age; //可以被删除
注意:变量的定义与变量的删除都不用$符来修饰
通常上面定义的是全局变量,不建议定义全局变量,可以使用局部变量,在变量前面添加local 关键字
# 定义局部变量
function test2(){
local -i a=3 //如果declare与local并在的时候,写法可以省去declare
declare -i b=3
}
$n n为数字, $0代表命令本身, $1-$9代表第1到第9个参数,10以上的参数需要用大括号包含,如${10}
$* 这个变量代表命令中所有的参数,$*把所有变量看作一个整体(相当是一个字符串,‘1 2 3’)
$@ 这个变量也代表命令中所有的参数, 不过$@把每个参数进行区分
$# 这个变量代表命令中所有参数的个数
#!/bin/bash
sum1=$1;
sum2=$2;
sum=$(($1 + $2));
echo "sum1 + sum 2 = ${sum}";
执行的时候用 sh sum.sh 1 3 这时1和3表示传入的参数,如果是调试模式下去执行 sh -x sum.sh 1 3
6、shell字符串
双引号的字符串拼接
#!/bin/bash
name='bill';
age=20;
echo -e "\e[1;34m 我的名字叫"${name}"我今年"$age"岁了\e[0m";
echo -e "\e[1;35m 我的名字叫${name},我今年${age}岁了\e[0m";
双引号可以解析引号内的内容
your_name='runoob'
str="Hello, I know you are \"$your_name\"! \n"
echo -e $str
单引号的字符串拼接
# 使用单引号拼接
greeting_2='hello, '$your_name' !'
greeting_3='hello, ${your_name} !'
echo $greeting_2 $greeting_3
获取字符串的长度

#!/bin/bash
name="are you ok ???";
echo "name的长度是:${#name}";
echo "name的长度是"`expr length "$name"`;
提取查询的子串的长度

echo `expr match "$name" today` //输出5
echo `expr match $name good` //输出0
注意:这里是需要从第一位开始匹配的
提取子字符串
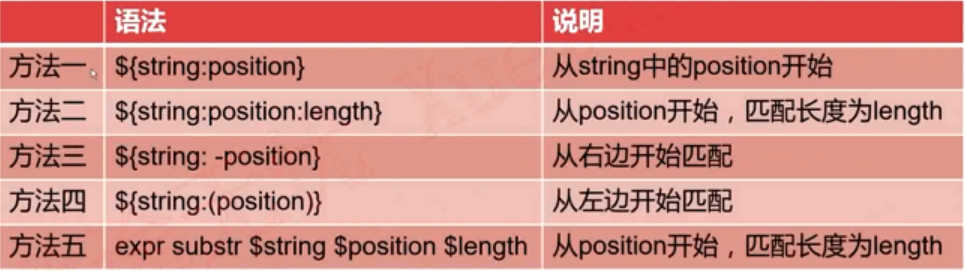
注意:第三个方法的负数最好有一个空格,或者采用第四种方法,表示的是从左边截取几位数
#!/bin/bash
str="bill is super man!";
echo "第二个字符到第六个字符是${str:2:6}";
#输出 第二个字符到第六个字符是ll is
echo ${str: -3} //输出 an! 注意中间需要有一个空格
string="abcdefghijklmnopqrstuvwxyz";
echo ${str: -12:3} //输出opq 注意从右边开始算,取正常顺序的3个字符
查找子字符串
查找是从第1位开始,如果没有找到那么就返回0,例如查找ac是先查找a然后再查找c,看哪个先找到,那么就返回先找到的部份,当a与c都能找到的情况下,返回比较小的值
#!/bin/bash
str="abcdefghijklmnopqrstuvwxyz";
echo `expr index "$str" s`;
echo `expr index "$str" ac`;
注意: 以上脚本中 ` 是反引号,而不是单引号 ',不要看错了哦。
变量替换

举例:
#!/bin/bash str="I see a yellow duck looking at me"; clip1=${str#*a}; clip2=${str##*a}; echo $clip1; //输出 yellow duck looking at me echo $clip2; //输出 t me clip3=${str%a*}; clip4=${str%%a*}; echo $clip3; //输出 I see a yellow duck looking echo $clip4; //输出 I see clip5=${str/a/bb}; clip6=${str//a/bb}; echo $clip5; //输出 I see bb yellow duck looking at me echo $clip6; //输出 I see bb yellow duck looking bbt me
文本练习

#!/bin/bash
str="Bigdata process framework is Hadoop, Hadoop is an open source project";
function show_tip() {
echo "*******************************";
echo "(1)打印string的长度";
echo "(2)删除字符串中所有的Hadoop";
echo "(3)替换第一个Hadoop为Mapreduce";
echo "(4)替换全部Hadoop为Mapreduce";
echo "*******************************"
}
function show_len() {
echo "string的长度是${#str}";
}
function del_str() {
echo ${str//Hadoop};
}
function rep_str() {
echo ${str/Hadoop/Mapreduce};
}
function rep_all_str() {
echo ${str//Hadoop/Mapreduce};
}
while true;
do
echo "【str=$str】";
show_tip;
read -p "请选择对应的操作1|2|3|4|q|Q: " choice
case $choice in
1) show_len;;
2) del_str;;
3) rep_str;;
4) rep_all_str;;
q|Q) exit;;
*) echo "输入有误,请重新输入(1|2|3|4|q|Q)";
esac
done
7、数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似于 C 语言,数组元素的下标由 0 开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于 0。
数组的定义
数组名=(值1 值2 ... 值n)
declare -a 数组名
也可以采用各个项来定义
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen
输出数组
#!/bin/bash
arr=("a" "b" "c" "d");
echo ${arr[0]}; //输出第0项
echo ${arr[@]}; //输出所有项数组
echo ${arr[*]}; //输出数组的所有项
输出数组的长度
#!/bin/bash
arr=("aa" "bbb" "cccc" "ddddd");
echo "数组的长度是"${#arr[@]}; #输出4
echo "这个也是数组的长度"${#arr[*]}; #输出4
echo "这个是数组中单项的长度"${#arr[3]}; #输出5
8、函数的定义
函数的定义方式:
函数名()
{
函数体(一堆命令的集合,来实现某个功能)
}
function 函数名()
{
函数体(一堆命令的集合,来实现某个功能)
}
function_name() {
command
command
}
function function_name() {
command
command
}
函数中return说明:
1.return可以结束一个函数,类似于前面讲的循环控制语句break(结束当前循环,执行循环体后面的代码)
2.return默认返回函数中最后一个命令的退出状态,也可以给定参数值,该参数值的范围是0-256之间。
3.如果没有return命令,函数将返回最后一个Shell的退出值。
$n表示输出第n位参数,$@与$*的意思一样表示输出所有的参数,$#表示参数的个数
#!/bin/bash function func() { echo $1,$@; } func "gaga";
练习:
#!/bin/bash function count { case $2 in +) echo `expr $1 + $3`;; -) echo `expr $1 - $3`;; \*) echo `expr $1 * $3`;; /) echo `expr $1 / $3`;; esac } count $1 $2 $3 //调用的时候 sh bash.sh 12 + 2
函数的返回值

return 返回值 只能返回1-255的整数。通常return只是用来供其他地方调用获取状态,因此通常仅返回0或1;0表示成功,1表示失败
echo 返回值可以返回任何字符串结果 。通常echo用于返回数据,比如一个字符串值或者列表值。
#!/bin/bash
function getUser {
user=$(cat /etc/passwd|cut -d ":" -f 1);
echo $user; //返回值是查询结果
}
data=`getUser`;
for var in $data;
do
echo $var;
done;
exit;
9、shell中的read命令
简单读取
#!/bin/bash
echo "请输入任意的内容";
read content; //把输入的内容赋值给content这个变量
echo "你输入的内容是"$content;
- -p 后面跟提示信息,即在输入前打印提示信息。
- -t 后面跟秒数,定义输入字符的等待时间。
- -s 安静模式,在输入字符时不再屏幕上显示,例如login时输入密码。
- -n 后跟一个数字,定义输入文本的长度,很实用。
#!/bin/bash
read -p "请输入任意的内容:" content;
echo "你输入的内容是:"$content;
#!/bin/bash
if read -t 5 -p "请5秒内输入用户名:" user; //这里在-t后面跟数据可以有空格,也可以没有空格
then
echo "您输入的用户名是:"$user;
else
echo "对不起,你输入超时";
fi
exit 0;
#!/bin/bash
read -n1 -p "请选择Y|N" sign //这里的-n后面跟数据可以有空格,也可以没有空格
echo "你输入的是:"$sign;
10、字符串的运算符
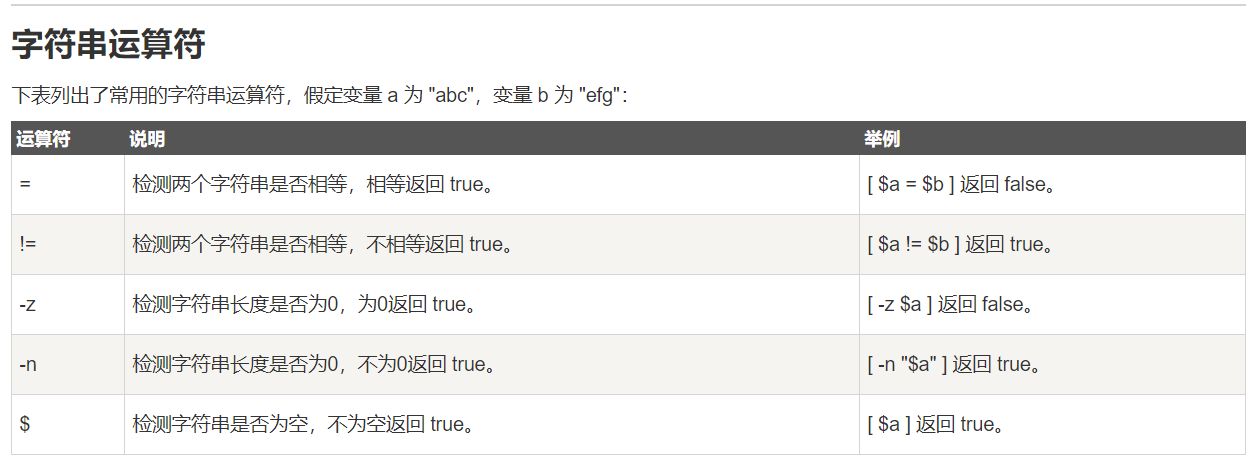
使用[[ ... ]]条件判断结构,而不是[ ... ],能够防止脚本中的许多逻辑错误。比如,&&、||、<和> 操作符能够正常存在于[[ ]]条件判断结构中,但是如果出现在[ ]结构中的话,会报错。比如可以直接使用if [[ $a != 1 && $a != 2 ]], 如果不适用双括号, 则为if [ $a -ne 1] && [ $a != 2 ]或者if [ $a -ne 1 -a $a != 2 ]。
#!/bin/bash
read -n1 -p "请输入对应的指令Y|N" sign;
if [[ $sign = "Y" || $sign = "y" ]] //这里的[[]]的前后都要加上空格,在if后面也要加上空格
then
echo "你输入的是肯定的回答";
elif [[ $sign = "N" || $sign = "n" ]]
then
echo "你输入的是否定的回答";
else
echo "输入的字符不合法,请输入Y|N";
fi
exit 0;
11、流程控制语句
if...elif...else例子如上
case 语句,相当其他语法的switch
#!/bin/bash
num=12;
case $num in
1|2|3|4|5|6|7|8|9) echo '这个值是小于10的值';;
10) echo "这个值是等于10的值";;
*) echo "这个值是大于10的值";;
esac
exit 0;
for语名的使用
#!/bin/bash
for((i=0; i<=10; i++)); do
echo "现在输出的是"${i};
done;
exit 0;
注意:这里使用的是双括号
#!/bin/bash
arr=("aa" "bb" "cc" "dd" "ee");
for per in ${arr[@]};
do
echo "值为"$per;
done
exit 0;
while的使用
#!/bin/bash
int=1
while(( $int<=5 ))
do
echo $int
let "int++"
done
注意:这里的Let相当于(())的用法
12、命令替换

#!/bin/bash
echo $(date +%Y);
echo `date +%Y`;
echo "明年是"$((`date +%Y` + 1))"年";
echo "明年是"$(($(date +%Y) + 1))"年";
如果没有命令替换,那么会输出命令
#!/bin/bash
//当本机的ngnix进程没有的时候,那么重新启动nginx服务
nginx_process_num = $(ps -ef | grep nginx | grep -v grep | wc -1) //重点表示过滤
if [ $nginx_process_num -eq 0 ];
then
systemctl start nginx
fi
13、cut的使用
常用命令 cut -d ":" -f 1 表示从字符串中截取一部份 -d:表示自定义分隔符,默认为制表符,“:” 表示以:进行分割, -f:与-d一起使用,指定显示哪个区域。1:表示取第一部份
#!/bin/bash
name="this is test are you ok???";
echo $name|cut -d " " -f 1; //输出 this
14、wc的使用
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
wc testfile
- -l或--lines 只显示行数。
- -w或--words 只显示字数。
wc test.sh //输出 6 11 72 bash.sh
ls -l|wc -l //输出 3 表示有3条记录
15、bc的使用
bc 命令是任意精度计算器语言,通常在linux下当计算器用。一般来讲,等式的小数位数决定了答案的位数
#!/bin/bash
echo "scale=2;3/8" | bc; //输出 0.37
echo "0.356 * 2" | bc; //输出0.712


向上取整与向下取整的函数封装
parseFloat() {
echo "$1 + 0.000" | bc
}
floor() {
a=$(parseFloat $1)
b=$(parseFloat $2)
echo `echo "scale=0; $a/$b" | bc`
}
ceil() {
a=$(parseFloat $1)
b=$(parseFloat $2)
num=$(echo "scale=2; $a/$b" | bc)
int=$(floor $a $b)
if [ $(echo "$int < $num"|bc) -eq 1 ];
then
echo $(($int+1))
else
echo $int;
fi
}
round() {
a=$(parseFloat $1)
b=$(parseFloat $2)
num=$(echo "scale=2; $a/$b" | bc)
int=$(floor $a $b)
middle=$(echo "$int + 0.5" | bc)
if [ $(echo "$middle < $num"|bc) -eq 1 ];
then
echo $(($int+1))
else
echo $int;
fi
}
echo $(floor 11 3) 3
echo $(floor 12 3) 4
echo $(floor 13 3) 4
echo $(floor 14 3) 4
echo $(ceil 11 3) 4
echo $(ceil 12 3) 4
echo $(ceil 13 3) 5
echo $(ceil 14 3) 5
echo $(round 11 3) 4
echo $(round 12 3) 4
echo $(round 13 3) 4
echo $(round 14 3.3) 4
echo $(round 15 3) 5
16、ps的用法
ps命令 用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
以下是ps的常用用法
ps axo pid,comm,pcpu # 查看进程的PID、名称以及CPU 占用率
ps aux | sort -rnk 4 # 按内存资源的使用量对进程进行排序
ps aux | sort -nk 3 # 按 CPU 资源的使用量对进程进行排序
ps -A # 显示所有进程信息
ps -u root # 显示指定用户信息
ps -efL # 查看线程数
ps -e -o "%C : %p :%z : %a"|sort -k5 -nr # 查看进程并按内存使用大小排列
ps -ef # 显示所有进程信息,连同命令行
ps -ef | grep ssh # ps 与grep 常用组合用法,查找特定进程
ps -C nginx # 通过名字或命令搜索进程
ps aux --sort=-pcpu,+pmem # CPU或者内存进行排序,-降序,+升序
ps -f --forest -C nginx # 用树的风格显示进程的层次关系
ps -o pid,uname,comm -C nginx # 显示一个父进程的子进程
ps -e -o pid,uname=USERNAME,pcpu=CPU_USAGE,pmem,comm # 重定义标签
ps -e -o pid,comm,etime # 显示进程运行的时间
ps -aux | grep named # 查看named进程详细信息
ps -o command -p 91730 | sed -n 2p # 通过进程id获取服务名称
例如查找linux中nginx的进程 ps -ef| grep nginx | grep -v grep
17、有类型的变量(即类型声明)
在shell中进行变量类型声明,需要通过declare和typeset两个命令进行操作,这两者是等价的, 下在以declare为例:
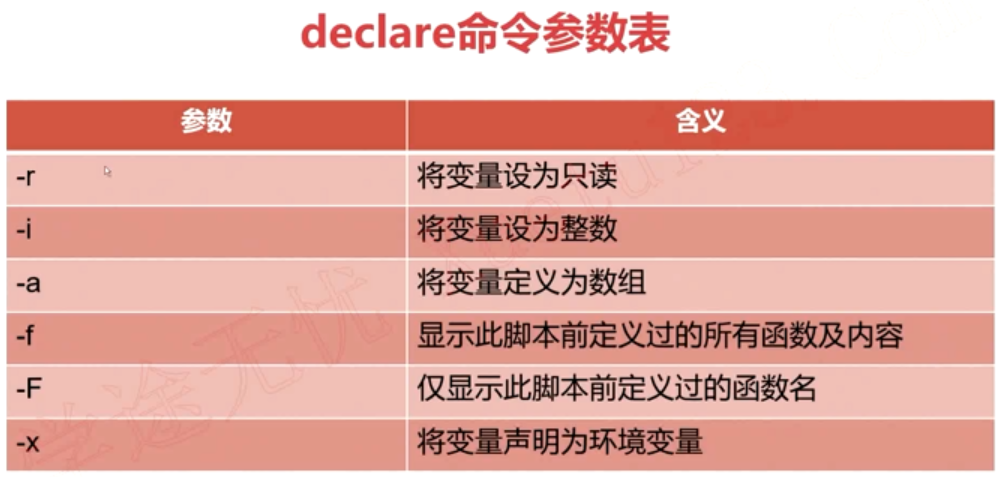
注意:声明了环境变量后,在脚本中就可以直接使用
取消声明的变量
取消声明的变量
declare +r 取消只读
declare +i 取消只为整型
declare +a 取消只为数组
declare +x 取消只为环境变量
18、bash数学运算之expr
语法:

注意:expr后面每个单语需要有空格,operator表示运算符

注意:在expr运算中,特殊的符号需要加上转义符号
#!/bin/bash
num1=100;
num2=200;
num3=$(expr $num1 + $num2); //使用这种语法,在赋值的时候需要进行转义
num4=`expr $num2 + $num3`;
num5=$(($num3 + $num4));
echo $num3;
echo $num4;
echo $num5;
注意:$(())不是一个表达式,但是可以进行赋值, expr是一个表达式,命令,可以单独运行,所以在expr进行赋值的时候,需要进行命令的替换。
练习:
[root@instance-yvmni62c ~]# cat bash.sh
#!/bin/bash
info() {
echo "********************************************";
echo "输入一个数求和";
echo "********************************************";
}
isInt() {
num=$(echo "scale=0; $1/1"|bc);
echo `expr $num \>= $1`;
}
getTotal() {
num=0;
for((i=0; i<=$1; i++));
do
num=$(($num + $i));
done
echo "总和是"$num;
}
while true
do
info;
read -p "请输入一个数:" count;
echo $count;
if [ $count -gt 0 ] && [ $(isInt $count) -eq 1 ]
then
getTotal $count;
else
echo "输入的数字格式有误";
fi
done
判断是否是正整数
#!/bin/bash
read -p "输入一个数 " count;
expr $count + 1 &> /dev/null;
echo $?; //输出0表是是正整数 1是负数 2是小数
19、sleep表示睡眠
sleep(参数)
#!/bin/bash b='' for ((i=0;$i<=100;i++)) do printf "Progress:[%-100s]%d%%\r" $b $i sleep 0.1 b=#$b done echo
20、find的使用细节
![]()
常用选项配置


find命令总结
常用选项:
-name 查找/etc目录下以conf结尾的文件 find /etc -name '*conf'
-iname 查找当前目录下文件名为aa的文件,不区分大小写 find . - iname aa
-user 查找文件属主为hdfs的所有文件 find . -user hdfs
-group 查找文件属组为yarn的所有文件 find,- group yarn
-type
f 文件 find . -type f
d 目录 find . -type d
c 字符设备文件 find . -type c
b 块设备文件 find . -type b
l 链接文件 find . -type l
p 管道文件 find . -type p
-size
-n 大小大于n的文件
+n 大小小于n的文件
n 大小等于n的文件
例子1:查找/etc目录下小于10000字节的文件 find /etc -size -10000c
例子2:查找/etc目录下大于1M的文件 find /etc -size +1M
-mtime
-n n天以内修改的文件
+n n天以外修改的文件
n 正好n天修改的文件
例子1:查找/etc目录下5天之内修改且以con结尾的文件 find /etc -mtime -5 -name '*.conf'
例子2:查找/etc目录下10天之前修改且属主为xoot的文件 find/etc -mtime +10 -user root
对查找到的结果进行操作
语法 find【路径】【选项】【操作】-exec command {} \;
例子:


练习:
#!/bin/bash
if [ ! -d 'abc' ];
then
echo "文件夹不存在的哈";
exit;
fi
function dealFile {
cd ~;
mkdir -p 'bf/conf';
mkdir -p 'bf/sh';
cd "abc";
find ./ -name "*.conf" -exec mv {} ../bf/conf/ \;
wait $! #等待上个命令执行完成
find ./ -name "*.sh" -exec mv {} ../bf/sh \;
wait $!;
cd ~;
rm -rf abc;
mv bf abc;
cd abc;
}
#对所对应的两个文件夹进行压缩处理,conf采用bz2压缩,sh采用gz压缩
function packFile {
tar -jcvf conf.tar.bz2 ./conf
tar -zcvf sh.tar.gz ./sh
#删除原有的目录
rm -rf conf sh;
}
21、grep与egrep的使用
grep: 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
egrep: 用于在文件内查找指定的字符串。egrep执行效果与grep -E相似,使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
grep的语法格式:
◆第一种形式: grep [option] [ pattern] [file1,file2...] 这种形式主要是在文件中查找,遍历文件的每一行,如果有匹配的就把那行列出来;
◆第二种形式: command | grep [option][pattern] 这种形式主要是在命令的终端中进行查找
grep常用的配置选项


grep -r ~/ 表示在~目录下对所有文件进行递归查询,在普通文件下是没有意义的。

注意:添加 --color=auto表示关键字以高亮显示 ,为了更方便的使用grep --color=auto 那么可以配置临时别名 alias grep='grep --color=auto' 如果需要配置全局别名,那么需要编辑 /etc/bashrc这个文件,在不动其他东西的情况下,在末尾添加 alias grep='grep --color=auto' , 另外需要重新读取一下配置 source /etc/bashrc 方可使用
22、sed的使用
sed:流编辑器。对标准输出或文件逐行进行处理
sed的语法格式:
stdout | sed [option] "sed的命令 | 地址定位"
sed [option] 'sed的命令|地址定位' filename
说明:引用shell script中的变量应使用双引号,而非通常使用的单引号
option:
-e 进行多项编辑,即对输入行应用多条sed命令时使用
-n 取消默认的输出
-f 指定sed脚本的文件名
-r 使用扩展正则表达式
-i inplace,原地编辑(修改源文件)
option祥解
-e可以理解成或的关系,如果有有一个可以不写,但是有多个就都要写
sed -n -e '/day/p' -e '/ok/p' test.txt //表示输出含day,也输出含有ok的行
注意:也相当于在语句中间用分号隔开,如下面例子
sed -nr '/^888/p;/^999/p' test.txt
sed -nr -e '/^888/p' -e '/^999/p' test.txt
#注意:上面两种表达的效果是一样的
-f可以理解为file,例如新建一个文件key.txt里面的内容是 /ok/p
sed -n -f key.txt test.txt //表示把key.txt中的内容拿到test.txt中进行匹配
-r表示正则表达式
sed -n -r '/ok|day/p' test.txt
-i表示修改文件内容
sed -n -i 's/day/today/g;p' test.txt //表示把文中的day 改成today;p表示输出(可省),如果没有-i那么只是把改的结果输出给你,原文不更改,加-i后会更改原文件
命令祥解
命令 p 表示打印行
sed 'p' test.txt #这里的p是个命令表示print的意思 , 原来sed有打印的意思,所以这里会输出2次
sed -n 'p' test.txt #静默打印当前文件所有行
sed -n '1p' test.txt #打印文件的第一行
sed -n '1,3p' test.txt # 打印文件的第一行至第三行
sed -nr '/day/p' test.txt # 打印文件匹配到的day单词的行 // 表示正则匹配
命令 d 表示删除行
sed 'd' test.txt # 删除所有行
sed '1d' test.txt # 删除第一行
sed '1,3d' test.txt # 删除第一行至第三行
sed -r '/day/d' test.txt # 删除正则匹配到的day的行
命令 i 表示在当前行之前插入文本。多行时除最后一行外,每行末尾需用"\"续行 相当于vim的O
命令 a 表示在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“\”续行 相当于vim的o
命令 c 表示用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用"\"续行 整行替换
sed '$i check' test.txt # 在最后一行的前一行插入check
sed '1i check' test.txt # 在第一行插入check
sed '1,3i check' test.txt # 在第一行至第三行插入check
sed -r '/day/i check' test.txt # 在匹配到正则的行前插入check
sed '1i hello\nworld' test.txt # 第一行插入hello第二行插入world
sed '1i hello\
world' test.txt #作用同上
#注意 a 表示在行后追加
sed '$c check' test.txt # 最后一行替换成check
sed '1c check' test.txt # 第一行替换成check
sed '1,3c check' test.txt # 第一至第三行替换成check
sed -r '/day/c check' test.txt # 把匹配到正则的每一行替换成check
命令 r 表示从指定文件中读取内容再插入到当前文件中的指定行
命令 w 表示把指定的内容写入到指定的文件中
sed '1r a.txt' test.txt #表示把a.txt的内容插入到当前文件的第一行
sed '1,3r a.txt' test.txt #表示把a.txt的内容在1至3行中每行都插入
sed '$r a.txt' test.txt #表示把a.txt的内容追加到末尾
sed -r '/day/r a.txt' test.txt #表示把a.txt的内容插入到匹配到的day字段的每行上
sed '1w a.txt' test.txt # 表示把test.txt的第一行写入到a.txt
sed -r '/^start/,/end$/w a.txt' #表示把以start开头的,end结尾的文本写入到a.txt中
注意: r 是追加式的把内容添加到指定行的后面
命令 s 表示用一个字符替换另一个字符
命令 g 表示在行内进行全局替换
sed 's/a/b/' test.txt #表示以行为单位,把第一个a字母替换成b字母
sed -n 's/a/b/p' test.txt #表示在上面的基础上,不打印全部,只打印替换的行 (注意:在进行真实文件编辑的时候不要带p不然会把默认输出的添加到真实文件中)
sed 's/a/b/g' test.txt #表示以行为单位,把所有的a字母替换成b字母
sed -n 's/a/b/gp' test.txt #表示在上面的基础上,只打印变更的行
# 注意s命令支持自定义分割符
sed -n 's#a#b#gp' test.txt #该语句与上面的语句一个效果,只是采用了自定义的分割符
# s命令的分割符里面支持编辑正则表达式,但是最好前加面 r
sed -r 's/^/#/' test.txt # 表示在test.txt文件的每一行开头加上#号
sed -r 's/^#//' test.txt # 表示删除test.txt文件的每一行开头的#号
sed -r '/^666/,/888$/s/^/#/' test.txt #表示在s前面正则表达式的范围内对每一行的行首添加#号
sed -r 's/[\/\\:\*\?]//g' test.txt #表示把所有的\/:*?全部进行删除操作
命令 & 表示保存查找串以便在替换串中引用
命令 = 打印行号
命令 !表示排除指定行
sed -r 's/999/a&/g' test.txt #这里的&指定的是前面分割符中的内容,即999
sed -n '/999/=' a.txt #表示输出999内容的行
sed -n '1,3!p' a.txt #表示除了第一至第三行
注意在shell中 ^$ 是表示空行的意思
综合举例
sed -r '/(^#|^$)/d;i are you ok' my.cnf > my.txt # 表示删除my.cnf文件中的以#号开头以及空行,得出结果后并且每行前插入are you ok后把结果输出到my.txt文件中
23、awk的使用(注意:要使用单引号,除非要引用变量)
awk是一种编程语言, 主要用于在linux/unix下对文本和数据进行处理
awk的模式:1、命令模式; 2、脚本模式
命令模式的语法结构
awk 选项 'command' 文件名
#常用选项
-F 定义字段分割符号,默认的分割符是空格
-v 定义变量并赋值
#命令部份
#正则表达式, 地址定位
'/root/{awk语句}' sed中: '/root/p'
'NR==1,NR==5{awk语句}' sed中: '1,5p'
'/^root/,/^ftp/{awk语句}' sed中:'/^root/,/^ftp/p'
#awk多个语句时需要用分号隔开 {awk语句;awk语句;...}
'{print $0;print $1}' sed中:'p'
'NR==5{print $0}' sed中:'5p'
注:awk命令语句间用分号间隔
#BEGIN...END...语句
'BEGIN{awk语句};{处理中};END{awk语句}'
'BEGIN{awk语句};{处理中}'
'{处理中};END{awk语句}'
脚本模式
脚本运行
方法1:
awk 选项 -f awk的脚本文件 要处理的文本文件
awk -f awk.sh filename
sed -f sed.sh -i filename
方法2:
./awk的脚本文件(或者绝对路径) 要处理的文本文件
./awk.sh filename
./sed.sh filename
脚本编写
#!/bin/awk -f 定义魔法字符
以下是awk引号里的命令清单,不要用引号保护命令,多个命令用分号间隔
BEGIN{FS=":"}
NR==1,NR==3{print $1"\t"$NF}
...
awk的内部相关变量
|
变量
|
变量说明
|
备注
|
|---|---|---|
|
$0
|
当前处理行的所有记录
|
|
|
$1,$2,$3...$n
|
文件中每行以间隔符号分割的不同字段
|
awk -F: '{print $1,$3}'
|
|
NF
|
当前记录的字段数(列数)即总共的列数
|
awk -F: '{print NF}'
|
|
$NF
|
最后一列
|
$(NF-1)表示倒数第二列
|
|
FNR/NR
|
行号
|
|
|
FS
|
定义间隔符
|
'BEGIN{FS=":"};{print $1,$3}',如果定义两个,那么用:"-F[ :]+" (用单引或双引引起来)表示分割符可以是 `空格` 或者`:` |
|
OFS
|
定义输出字段分隔符,默认空格
|
'BEGIN{OFS="\t"};print $1,$3}'
|
|
RS
|
输入记录分割符,默认换行
|
'BEGIN{RS="\t"};{print $0}'
|
|
ORS
|
输出记录分割符,默认换行
|
'BEGIN{ORS="\n\n"};{print $1,$3}'
|
|
FILENAME
|
当前输入的文件名
|
|
示例1
# 表示定义分割符为:并且打印第一部份与倒数第二部份
awk -F: '{print $1,$(NF-1)}' 1.txt
# 定义分割符为:打印第一部份,倒数第二部分,最后一部份,总的分割数量,
awk -F: '{print $1,$(NF-1),$NF,NF}' 1.txt
# 匹配root关键字行,并且打印匹配到的行的内容
awk '/root/{print $0}' 1.txt
awk '/root/' 1.txt
# 定义分割符为:打印第一部份以及最后一部份
awk -F: '/root/{print $1,$NF}' 1.txt
# 打印第一行至每五行的内容
awk 'NR==1,NR==5' 1.txt
awk 'NR==1,NR==5{print $0}' 1.txt
# 表示打印第一行与第五行并且匹配root的内容
awk 'NR==1,NR==5;/^root/{print $0}' 1.txt
注意:如果有多个匹配规则需要以分号 ;进行隔开
FS和OFS:
#表示重新定义分割符,以:进行分割,然后查询以666开头888结尾的,打印第一部份与最后一部份
awk 'BEGIN{FS=":"};/^666/,/888$/{print $1,$NF}' test.txt
#表示打印出来的两部份结构$1与$NF两者以 - 符号相连接
awk -F: 'BEGIN{OFS="-"};/^666/,/888$/{print $1,$NF}' test.txt
awk -F: '/^666/,/888$/{print $1"-"$NF}' a.txt
#注意:以上两种写法效果一样,在print不同部份时以,进行连接,相当于一个空格
RS和ORS:
RS通俗的来讲:告诉程序怎么识别一行就结束了,默认是换行则结束,但是定义了换行符后,默认的\n还是存在的除非用ORS进行重新调整
awk 'BEGIN{RS="&";ORS="@"};{print $0}' a.txt #表示遇到&或者\n则认为是一行结束了
ORS表示处理完文本后,以什么为结尾进行行与行的拼接
awk 'BEGIN{ORS="**"};{print $0}' a.txt #表示处理完文本后,以**取代\n为结尾进行文本拼接
awk中的变量定义
awk -v NUM=3 -F: '{ print $NUM }' /etc/passwd #相当于打印$3
awk -v NUM=3 -F: '{ print NUM }' /etc/passwd # 打印的是变量
awk -v num=1 'BEGIN{print num}' # 打印变量
1
awk -v num=1 'BEGIN{print $num}' #结果为空,因为在执行文件前
#注意: awk中调用定义的变量不需要加$
BEGIN...END的使用示例
awk -F: 'BEGIN{ print "Login_shell\t\tLogin_home\n*******************"};{print $NF"\t\t"$(NF-1)};END{print "************************"}' 1.txt
awk 'BEGIN{ FS=":";print "Login_shell\tLogin_home\n*******************"};{print $NF"\t"$(NF-1)};END{print "************************"}' 1.txt
Login_shell Login_home
************************
/bin/bash /root
/sbin/nologin /bin
/sbin/nologin /sbin
/sbin/nologin /var/adm
/sbin/nologin /var/spool/lpd
/bin/bash /home/redhat
/bin/bash /home/user01
/sbin/nologin /var/named
/bin/bash /home/u01
/bin/bash /home/YUNWEI
************************************
使用 printf 对打印出来的数据进行格式化
print函数 类似echo
# date |awk '{print "Month: "$2 "\nYear: "$NF}'
# awk -F: '{print "username is: " $1 "\t uid is: "$3}' /etc/passwd
printf函数 类似echo -n
# awk -F: '{printf "%-15s %-10s %-15s\n", $1,$2,$3}' /etc/passwd
# awk -F: '{printf "|%15s| %10s| %15s|\n", $1,$2,$3}' /etc/passwd
# awk -F: '{printf "|%-15s| %-10s| %-15s|\n", $1,$2,$3}' /etc/passwd
awk 'BEGIN{FS=":"};{printf "%-15s %-15s %-15s\n",$1,$6,$NF}' a.txt
%s 字符类型 strings %-20s
%d 数值类型
占15字符
- 表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加\n
举例
u_name h_dir shell
***************************
***************************
awk -F: 'BEGIN{OFS="\t\t";print"u_name\t\th_dir\t\tshell\n***************************"}{printf "%-20s %-20s %-20s\n",$1,$(NF-1),$NF};END{print "****************************"}'
# awk -F: 'BEGIN{print "u_name\t\th_dir\t\tshell" RS "*****************"} {printf "%-15s %-20s %-20s\n",$1,$(NF-1),$NF}END{print "***************************"}' /etc/passwd
格式化输出:
echo print
echo -n printf
{printf "%-15s %-20s %-20s\n",$1,$(NF-1),$NF}
awk与正则表达式的综合运用
| 运算符 | 说明 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| ~ | 匹配 |
| !~ | 不匹配 |
| ! | 逻辑非 |
| && | 逻辑与 |
| || | 逻辑或 |
# 从第一行开始匹配到以lp开头行
awk -F: 'NR==1,/^lp/{print $0 }' passwd
# 从第一行到第5行
awk -F: 'NR==1,NR==5{print $0 }' passwd
# 从以lp开头的行匹配到第10行
awk -F: '/^lp/,NR==10{print $0 }' passwd
# 从以root开头的行匹配到以lp开头的行
awk -F: '/^root/,/^lp/{print $0}' passwd
# 打印以root开头或者以lp开头的行
awk -F: '/^root/ || /^lp/{print $0}' passwd
awk -F: '/^root/;/^lp/{print $0}' passwd
# 显示5-10行
awk -F':' 'NR>=5 && NR<=10 {print $0}' /etc/passwd
awk -F: 'NR<10 && NR>5 {print $0}' passwd
# 打印30-39行以bash结尾的内容:
awk 'NR>=30 && NR<=39 && $0 ~ /bash$/{print $0}' passwd
# 理解;号和||的含义:
awk 'NR>=3 && NR<=8 || /bash$/' 1.txt
awk 'NR>=3 && NR<=8;/bash$/' 1.txt
# 打印IP地址
ifconfig eth0|awk 'NR>1 {print $2}'|awk -F':' 'NR<2 {print $2}'
ifconfig eth0|grep Bcast|awk -F':' '{print $2}'|awk '{print $1}'
ifconfig eth0|grep Bcast|awk '{print $2}'|awk -F: '{print $2}'
ifconfig eth0|awk NR==2|awk -F '[ :]+' '{print $4RS$6RS$8}'
ifconfig eth0|awk "-F[ :]+" '/inet addr:/{print $4}'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号