
Spring中XML的解析过程
1.AbstractApplicationContext.obtainBeanFactory方法中,模版调用
2.AbstractRefreshableApplicationContex.refreshBeanFactory
该方法中会创建 DefaultListableBeanFactory用于收集BeanDefinition对象
会继续模版调用
3.AbstractXMLApplicationContext.loadBeanDefinitions方法
该方法中会进行委托调用
4.XMLBeanDefinitionReader.loadBeanDefinitions
该方法会 进行 模版调用
5.AbstractBeanDefinitionReader.loadBeanDefinitions
该方法会继续模版调用
6.XMLBeanDefinitionReader.loadBeanDefinitions
该方法会调用该类中的方法
7.XMLBeanDefinitionReader.doLoadBeanDefinitions
会继续类内调用
8.XMLBeanDefinitionReader.doLoadDocument
类内方法调用
9.DefaultDocument.loadDocument
通过w3c.dom解析成一个Document对象
10.XmlBeanDefinitionReader.registerBeanDefinitions
继续调用
11.DefaultBeanDefinitionDocumentReader.registerBeanDefinitions
类内调用
12.DefaultBeanDefinitionDocumentReader.parseBeanDefinition
再进行委托调用,解析默认的Bean标签
13.BeanDefinitionParserDelegate.parseBeanDefinitionElement
类内方法调用
14.BeanDefinitionParserDelegate
createBeanDefinition...
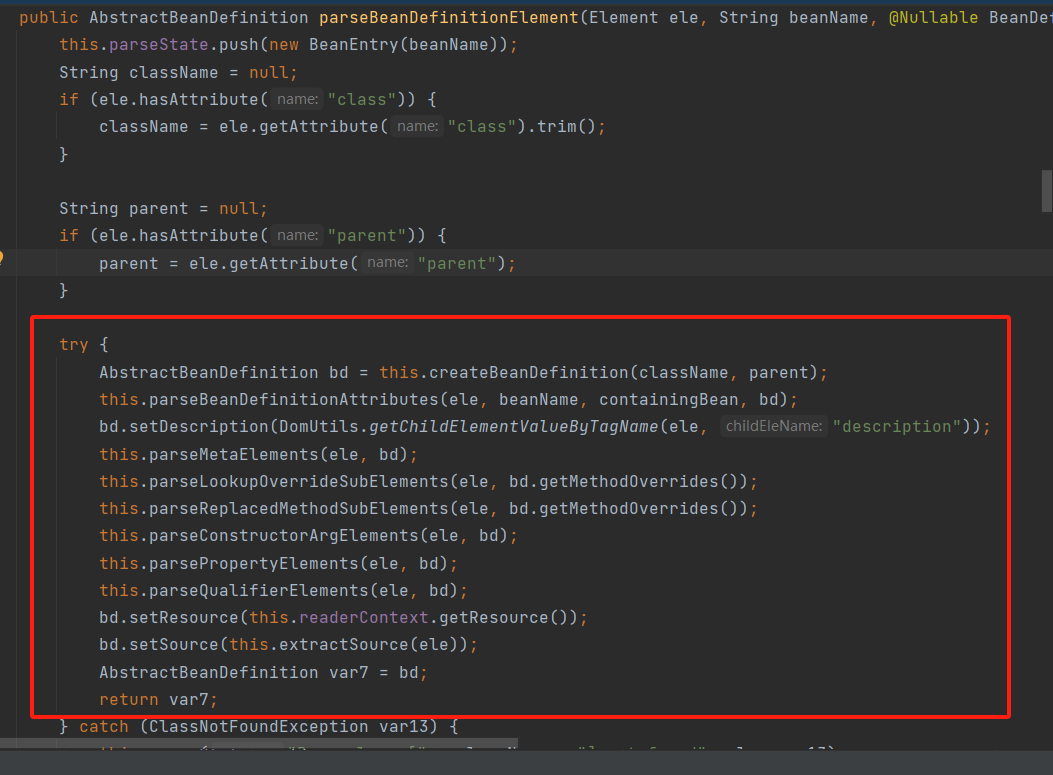
最终解析出bean标签的所有对应的所有标签
class,parent,singleton,abstract,lazy-init,autowire,depends-on,autowire-candidate,primary,init-method,destory-method,factory-method,
factory-bean,description,meta,lookup-method,replaced-method,constructor-arg,propertyqualifier,
并最终将这些标签解析成BeanDefinition对象所对应的属性,属性参考 https://www.cnblogs.com/velloLei/p/18249742
15.BeanDefinitionParserDelgate.parseCustomElement
自定义标签需要自己注册标签解析器
自定义标签解析器需要做三个工作
一、自定义标签解析器
最好继承AbstractSimpleBeanDefinitionParser,这样很多基础方法都已经实现,只需要专注doParse方法就行
二、自定义NamespaceHandler,将标签解析器注册到spring容器
最好继承NamespaceHandlerSupport,基本方法都已被实现,只需要重写init方法,将解析器注册到容器
三、在META-INF目录下,创建spring.handlers文件用于url=handler,让spring进行加载注册
通过SPI的加载方式,将uri于命名空间对应,在xml配置时能进行相关提示。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~