
代码优化小技巧(持续更新......)
1. 无论读取char型还是int型, 都只需一条指令
x86: movl(int) movb(char)
arm: ldr(int) ldrb(char)
ARM早期编译器不支持ldrb strb,在操作char类型时, 32bit处理器下用ldr加载R0寄存器(char所在的4byte), 假设在低8位,就左移24bit,右移24bit
如果在第二byte, 就左移16bit再右移24bit, 换而言之对char类型操作要附加两条指令, 因此尽量用int或者long, 不过这种情况一去不回, ldrb、ldrh都只需一条指令
什么左移右移硬件实现了, ldrb加载到R0寄存器高24bit就是0!
2. 局部变量尽可能使用int/long类型(在ARMV4 char是无符号的)
使用char“可能”节省栈空间, 无论char还是int都一条读指令搞定(LDRB/LDR),问题在于int型溢出会自动归零, 而char溢出只会向bit8置1, 变成256,
我们希望255再++后是0而不是256(因为是char), 所以每次参与计算后都会与0xff(类似动作), 所以:int一条取指令, char取指令 与0xff 两条
如果for循环的话, for(char i=0; i<64; i++) 每次++后会与0xff, 共65条指令! 这里引发另一个重要的问题是, 如果i是全局变量且i=255再++的话 bit8置1变成256,
在下一条与0xff时被打断了比如中断, 然后中断取的值应该是0的却是256, 这就危险了!
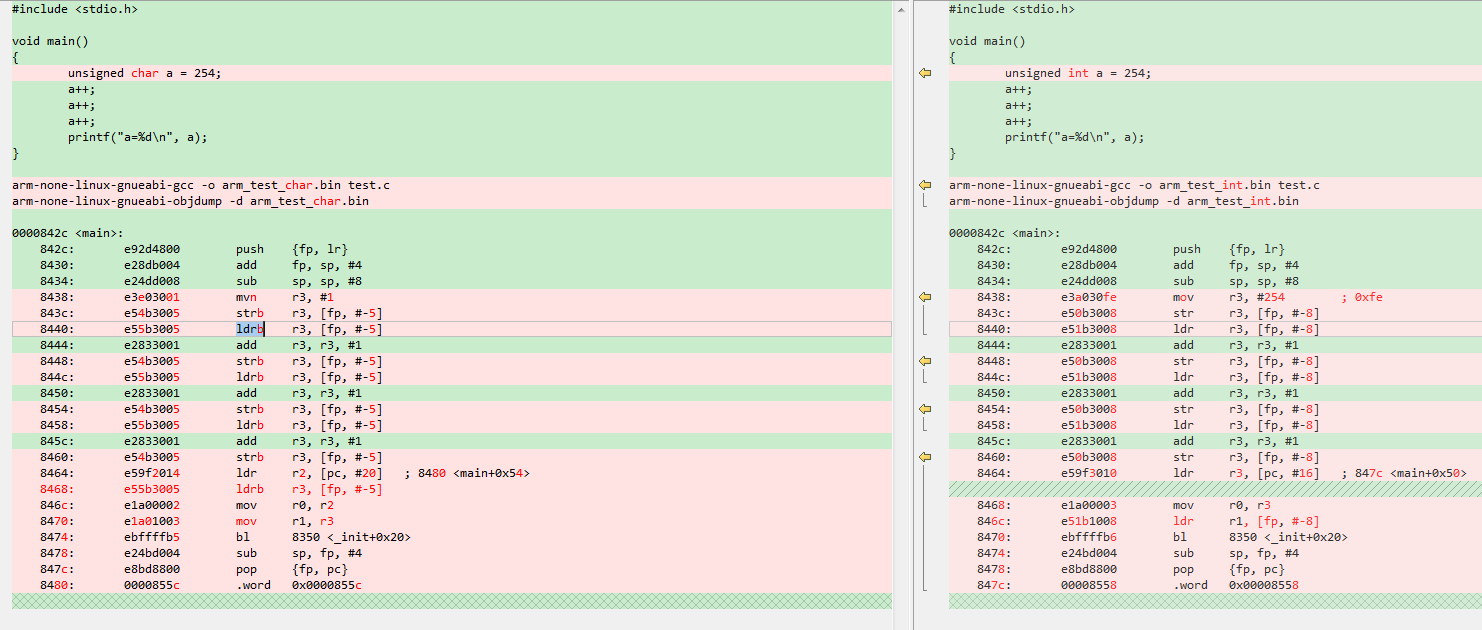
用个代码测试一下是不是这样的:
X86: 测试程序只是变量a的类型不一样, 反编译发现在操作char a时会有个movzbl 前置归零命令(等价上文与0xff), int型的代码明显指令少很多!
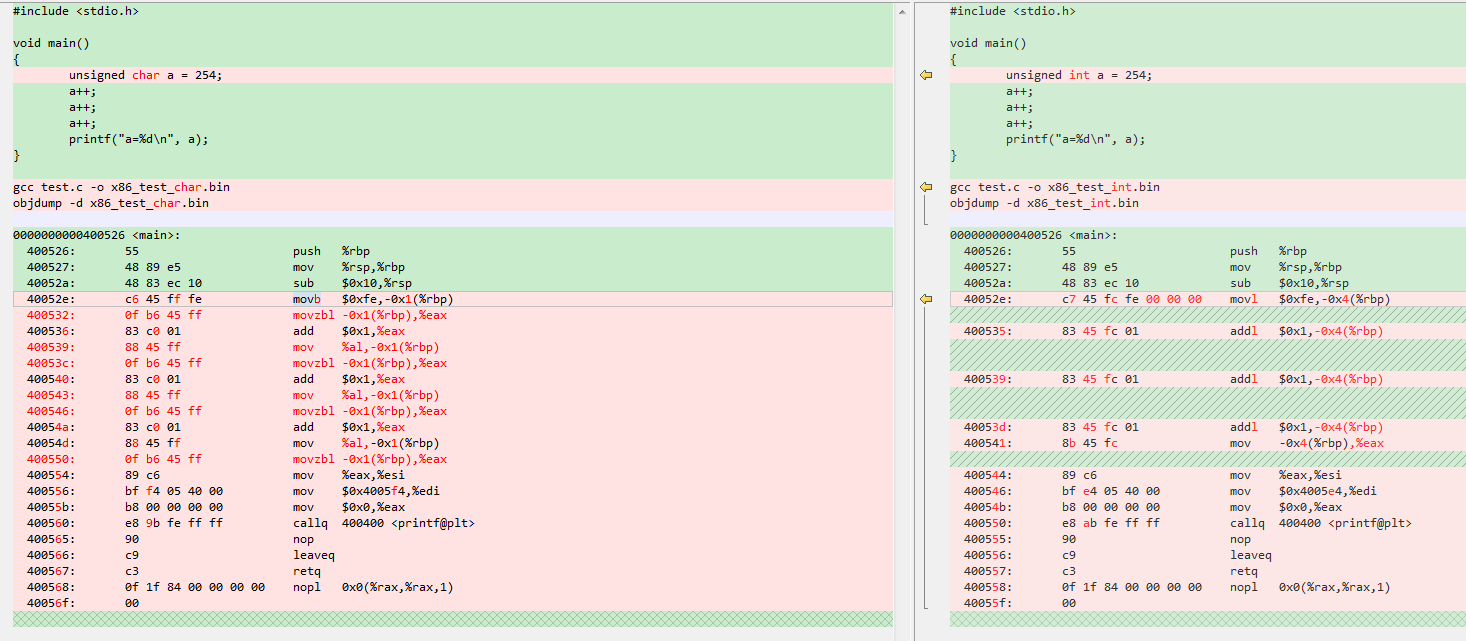
ARM: arm还好, 指令差不多, 看来影响大的是x86
3. 数组型操作比指针型更高效
示例代码:


#include <stdio.h> int main() { char *char_p, char_arr[5]={0,1,2}; short *short_p, short_arr[5]={1,2,3}; int *int_p, int_arr[5]={2,3,4}; char_p=char_arr; short_p=short_arr; int_p=int_arr; printf("111\n"); (*(char_p+2)) ++; printf("222\n"); char_arr[2] ++; printf("111\n"); (*(short_p+2)) ++; printf("222\n"); short_arr[2] ++; printf("111\n"); (*(int_p+2)) ++; printf("222\n"); int_arr[2] ++; return 0; }
编译和反汇编:
0000000000400596 <main>: 400596: 55 push %rbp 400597: 48 89 e5 mov %rsp,%rbp 40059a: 48 83 ec 60 sub $0x60,%rsp 40059e: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax 4005a5: 00 00 4005a7: 48 89 45 f8 mov %rax,-0x8(%rbp) 4005ab: 31 c0 xor %eax,%eax 4005ad: c7 45 f0 00 00 00 00 movl $0x0,-0x10(%rbp) 4005b4: c6 45 f4 00 movb $0x0,-0xc(%rbp) 4005b8: c6 45 f1 01 movb $0x1,-0xf(%rbp) 4005bc: c6 45 f2 02 movb $0x2,-0xe(%rbp) 4005c0: 48 c7 45 c0 00 00 00 movq $0x0,-0x40(%rbp) 4005c7: 00 4005c8: 66 c7 45 c8 00 00 movw $0x0,-0x38(%rbp) 4005ce: 66 c7 45 c0 01 00 movw $0x1,-0x40(%rbp) 4005d4: 66 c7 45 c2 02 00 movw $0x2,-0x3e(%rbp) 4005da: 66 c7 45 c4 03 00 movw $0x3,-0x3c(%rbp) 4005e0: 48 c7 45 d0 00 00 00 movq $0x0,-0x30(%rbp) 4005e7: 00 4005e8: 48 c7 45 d8 00 00 00 movq $0x0,-0x28(%rbp) 4005ef: 00 4005f0: c7 45 e0 00 00 00 00 movl $0x0,-0x20(%rbp) 4005f7: c7 45 d0 02 00 00 00 movl $0x2,-0x30(%rbp) 4005fe: c7 45 d4 03 00 00 00 movl $0x3,-0x2c(%rbp) 400605: c7 45 d8 04 00 00 00 movl $0x4,-0x28(%rbp) 40060c: 48 8d 45 f0 lea -0x10(%rbp),%rax 400610: 48 89 45 a8 mov %rax,-0x58(%rbp) 400614: 48 8d 45 c0 lea -0x40(%rbp),%rax 400618: 48 89 45 b0 mov %rax,-0x50(%rbp) 40061c: 48 8d 45 d0 lea -0x30(%rbp),%rax 400620: 48 89 45 b8 mov %rax,-0x48(%rbp) 400624: bf 54 07 40 00 mov $0x400754,%edi 400629: e8 32 fe ff ff callq 400460 <puts@plt> 40062e: 48 8b 45 a8 mov -0x58(%rbp),%rax 400632: 48 83 c0 02 add $0x2,%rax 400636: 0f b6 10 movzbl (%rax),%edx 400639: 83 c2 01 add $0x1,%edx 40063c: 88 10 mov %dl,(%rax) 40063e: bf 58 07 40 00 mov $0x400758,%edi 400643: e8 18 fe ff ff callq 400460 <puts@plt> 400648: 0f b6 45 f2 movzbl -0xe(%rbp),%eax 40064c: 83 c0 01 add $0x1,%eax 40064f: 88 45 f2 mov %al,-0xe(%rbp) 400652: bf 54 07 40 00 mov $0x400754,%edi 400657: e8 04 fe ff ff callq 400460 <puts@plt> 40065c: 48 8b 45 b0 mov -0x50(%rbp),%rax 400660: 48 83 c0 04 add $0x4,%rax 400664: 0f b7 10 movzwl (%rax),%edx 400667: 83 c2 01 add $0x1,%edx 40066a: 66 89 10 mov %dx,(%rax) 40066d: bf 58 07 40 00 mov $0x400758,%edi 400672: e8 e9 fd ff ff callq 400460 <puts@plt> 400677: 0f b7 45 c4 movzwl -0x3c(%rbp),%eax 40067b: 83 c0 01 add $0x1,%eax 40067e: 66 89 45 c4 mov %ax,-0x3c(%rbp) 400682: bf 54 07 40 00 mov $0x400754,%edi 400687: e8 d4 fd ff ff callq 400460 <puts@plt> 40068c: 48 8b 45 b8 mov -0x48(%rbp),%rax 400690: 48 83 c0 08 add $0x8,%rax 400694: 8b 10 mov (%rax),%edx 400696: 83 c2 01 add $0x1,%edx 400699: 89 10 mov %edx,(%rax) 40069b: bf 58 07 40 00 mov $0x400758,%edi 4006a0: e8 bb fd ff ff callq 400460 <puts@plt> 4006a5: 8b 45 d8 mov -0x28(%rbp),%eax 4006a8: 83 c0 01 add $0x1,%eax 4006ab: 89 45 d8 mov %eax,-0x28(%rbp) 4006ae: b8 00 00 00 00 mov $0x0,%eax 4006b3: 48 8b 4d f8 mov -0x8(%rbp),%rcx 4006b7: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx 4006be: 00 00 4006c0: 74 05 je 4006c7 <main+0x131> 4006c2: e8 a9 fd ff ff callq 400470 <__stack_chk_fail@plt> 4006c7: c9 leaveq 4006c8: c3 retq 4006c9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
0000842c <main>: 842c: e92d4800 push {fp, lr} 8430: e28db004 add fp, sp, #4 8434: e24dd038 sub sp, sp, #56 ; 0x38 8438: e3a03000 mov r3, #0 843c: e50b3018 str r3, [fp, #-24] ; 0xffffffe8 8440: e3a03000 mov r3, #0 8444: e54b3014 strb r3, [fp, #-20] ; 0xffffffec 8448: e3a03001 mov r3, #1 844c: e54b3017 strb r3, [fp, #-23] ; 0xffffffe9 8450: e3a03002 mov r3, #2 8454: e54b3016 strb r3, [fp, #-22] ; 0xffffffea 8458: e24b3024 sub r3, fp, #36 ; 0x24 845c: e3a02000 mov r2, #0 8460: e5832000 str r2, [r3] 8464: e2833004 add r3, r3, #4 8468: e3a02000 mov r2, #0 846c: e5832000 str r2, [r3] 8470: e2833004 add r3, r3, #4 8474: e3a02000 mov r2, #0 8478: e1c320b0 strh r2, [r3] 847c: e2833002 add r3, r3, #2 8480: e3a03001 mov r3, #1 8484: e14b32b4 strh r3, [fp, #-36] ; 0xffffffdc 8488: e3a03002 mov r3, #2 848c: e14b32b2 strh r3, [fp, #-34] ; 0xffffffde 8490: e3a03003 mov r3, #3 8494: e14b32b0 strh r3, [fp, #-32] ; 0xffffffe0 8498: e24b3038 sub r3, fp, #56 ; 0x38 849c: e3a02000 mov r2, #0 84a0: e5832000 str r2, [r3] 84a4: e2833004 add r3, r3, #4 84a8: e3a02000 mov r2, #0 84ac: e5832000 str r2, [r3] 84b0: e2833004 add r3, r3, #4 84b4: e3a02000 mov r2, #0 84b8: e5832000 str r2, [r3] 84bc: e2833004 add r3, r3, #4 84c0: e3a02000 mov r2, #0 84c4: e5832000 str r2, [r3] 84c8: e2833004 add r3, r3, #4 84cc: e3a02000 mov r2, #0 84d0: e5832000 str r2, [r3] 84d4: e2833004 add r3, r3, #4 84d8: e3a03002 mov r3, #2 84dc: e50b3038 str r3, [fp, #-56] ; 0xffffffc8 84e0: e3a03003 mov r3, #3 84e4: e50b3034 str r3, [fp, #-52] ; 0xffffffcc 84e8: e3a03004 mov r3, #4 84ec: e50b3030 str r3, [fp, #-48] ; 0xffffffd0 84f0: e24b3018 sub r3, fp, #24 84f4: e50b3008 str r3, [fp, #-8] 84f8: e24b3024 sub r3, fp, #36 ; 0x24 84fc: e50b300c str r3, [fp, #-12] 8500: e24b3038 sub r3, fp, #56 ; 0x38 8504: e50b3010 str r3, [fp, #-16] 8508: e59f00b0 ldr r0, [pc, #176] ; 85c0 <main+0x194> 850c: ebffff8f bl 8350 <_init+0x20> 8510: e51b3008 ldr r3, [fp, #-8] 8514: e2833002 add r3, r3, #2 8518: e5d32000 ldrb r2, [r3] 851c: e2822001 add r2, r2, #1 8520: e20220ff and r2, r2, #255 ; 0xff 8524: e5c32000 strb r2, [r3] 8528: e59f0094 ldr r0, [pc, #148] ; 85c4 <main+0x198> 852c: ebffff87 bl 8350 <_init+0x20> 8530: e55b3016 ldrb r3, [fp, #-22] ; 0xffffffea 8534: e2833001 add r3, r3, #1 8538: e20330ff and r3, r3, #255 ; 0xff 853c: e54b3016 strb r3, [fp, #-22] ; 0xffffffea 8540: e59f0078 ldr r0, [pc, #120] ; 85c0 <main+0x194> 8544: ebffff81 bl 8350 <_init+0x20> 8548: e51b300c ldr r3, [fp, #-12] 854c: e2833004 add r3, r3, #4 8550: e1d320b0 ldrh r2, [r3] 8554: e2822001 add r2, r2, #1 8558: e1a02802 lsl r2, r2, #16 855c: e1a02822 lsr r2, r2, #16 8560: e1c320b0 strh r2, [r3] 8564: e59f0058 ldr r0, [pc, #88] ; 85c4 <main+0x198> 8568: ebffff78 bl 8350 <_init+0x20> 856c: e15b32b0 ldrh r3, [fp, #-32] ; 0xffffffe0 8570: e2833001 add r3, r3, #1 8574: e1a03803 lsl r3, r3, #16 8578: e1a03823 lsr r3, r3, #16 857c: e14b32b0 strh r3, [fp, #-32] ; 0xffffffe0 8580: e59f0038 ldr r0, [pc, #56] ; 85c0 <main+0x194> 8584: ebffff71 bl 8350 <_init+0x20> 8588: e51b3010 ldr r3, [fp, #-16] 858c: e2833008 add r3, r3, #8 8590: e5932000 ldr r2, [r3] 8594: e2822001 add r2, r2, #1 8598: e5832000 str r2, [r3] 859c: e59f0020 ldr r0, [pc, #32] ; 85c4 <main+0x198> 85a0: ebffff6a bl 8350 <_init+0x20> 85a4: e51b3030 ldr r3, [fp, #-48] ; 0xffffffd0 85a8: e2833001 add r3, r3, #1 85ac: e50b3030 str r3, [fp, #-48] ; 0xffffffd0 85b0: e3a03000 mov r3, #0 85b4: e1a00003 mov r0, r3 85b8: e24bd004 sub sp, fp, #4 85bc: e8bd8800 pop {fp, pc} 85c0: 000086a0 .word 0x000086a0 85c4: 000086a4 .word 0x000086a4
横向对比:
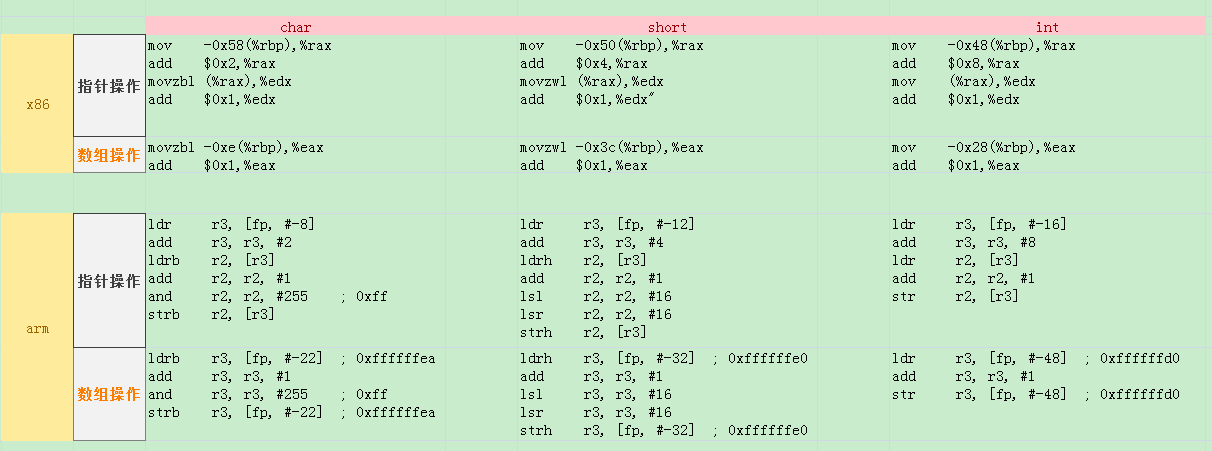
这里可以很明显得出结论: 使用数组操作比指针高效!, 理由很简单, 编译器认为数组偏移多少成员其对于地址都是确定的, 取数组[0]和[3]没有区别就是个地址, 而指针偏移是一个独立行为,
所以要显性执行这个动作, 因此多出这部分指令!
这个表还有其他有意思的地方, 比如前面第二条 x86用前置归零movzbl, 而arm用and与或者lsl/lsr右移右移处理溢出, 用int变量比char、short高效
4. 有符号与无符号加减乘都一样, 无符号除效率更高
以下只列出x86编译器反汇编, arm编译出来也是一样的结论
/* 示例: 乘法指令一样 */ int main() { int a,b; unsigned int ua,ub; b = a * 5; ub = ua * 5; return 0; } 00000000004004d6 <main>: 4004d6: 55 push %rbp 4004d7: 48 89 e5 mov %rsp,%rbp 4004da: 8b 55 f0 mov -0x10(%rbp),%edx //取a变量 4004dd: 89 d0 mov %edx,%eax 4004df: c1 e0 02 shl $0x2,%eax 4004e2: 01 d0 add %edx,%eax 4004e4: 89 45 f4 mov %eax,-0xc(%rbp) //将a算好的值直接赋值b变量 4004e7: 8b 55 f8 mov -0x8(%rbp),%edx //取ua变量 4004ea: 89 d0 mov %edx,%eax 4004ec: c1 e0 02 shl $0x2,%eax 4004ef: 01 d0 add %edx,%eax 4004f1: 89 45 fc mov %eax,-0x4(%rbp) //将ua算好的值直接赋值ub变量 4004f4: b8 00 00 00 00 mov $0x0,%eax 4004f9: 5d pop %rbp 4004fa: c3 retq 4004fb: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
/* 示例: 除法指令更少 */
int main() { int a,b; unsigned int ua,ub; b = a / 5; ub = ua / 5; return 0; } =========================== 00000000004004d6 <main>: 4004d6: 55 push %rbp 4004d7: 48 89 e5 mov %rsp,%rbp 4004da: 8b 4d f0 mov -0x10(%rbp),%ecx //取a变量 4004dd: ba 67 66 66 66 mov $0x66666667,%edx 4004e2: 89 c8 mov %ecx,%eax 4004e4: f7 ea imul %edx 4004e6: d1 fa sar %edx 4004e8: 89 c8 mov %ecx,%eax 4004ea: c1 f8 1f sar $0x1f,%eax 4004ed: 29 c2 sub %eax,%edx 4004ef: 89 d0 mov %edx,%eax 4004f1: 89 45 f4 mov %eax,-0xc(%rbp) //将a算好的值直接赋值b变量 4004f4: 8b 45 f8 mov -0x8(%rbp),%eax //取ua变量 4004f7: ba cd cc cc cc mov $0xcccccccd,%edx 4004fc: f7 e2 mul %edx 4004fe: 89 d0 mov %edx,%eax 400500: c1 e8 02 shr $0x2,%eax 400503: 89 45 fc mov %eax,-0x4(%rbp) //将ua算好的值直接赋值ub变量 400506: b8 00 00 00 00 mov $0x0,%eax 40050b: 5d pop %rbp 40050c: c3 retq 40050d: 0f 1f 00 nopl (%rax)
5.
%、/ 算术花费20~100周期, 以ring buffer为例 off = (off + cnt) % buf_size; // 每次都%哪怕不大于buf_size 耗时50个周期 更高效写法: off += cnt; if(off > buf_size) off -= buf_size; 耗两条指令, 或者3条 如果一定要除法, 要unsigned!
6. 函数参数数量不要超多4个, R0~R3保存函数参数, 多余会放入栈去
7. enum大小取决编译器
8. 每次除法时, 取模是无偿得到的, 反过来也是
p.x = offset % line_size; //%时R0存储除后的除数, R1存储余数
p.y = offset / line_size; //直接利用上面的R0赋值p.y

 浙公网安备 33010602011771号
浙公网安备 33010602011771号