
逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
答:算法层面可以通过正则化来防止,数据层面可以通过加大样本量或者通过特征选择减少特征量,过拟合归根结底就是是太过贴近于训练数据的特征了,正则化中的L1正则便是通过增大正值向降低模型复杂度,L2正则则是通过使参数趋于0降低模型抖动,两者都通过自己的方式抵抗过拟合。
2.用logiftic回归来进行实践操作,数据不限。
使用的数据集与老师上课时的一样。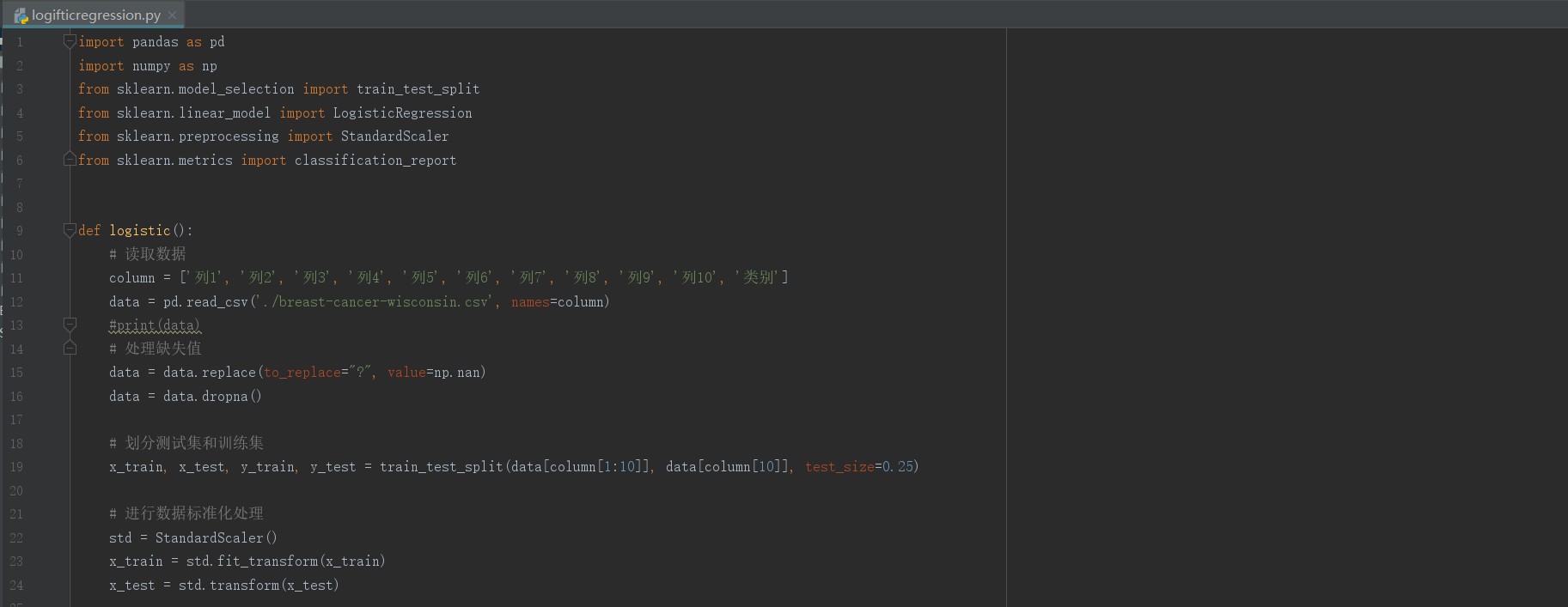
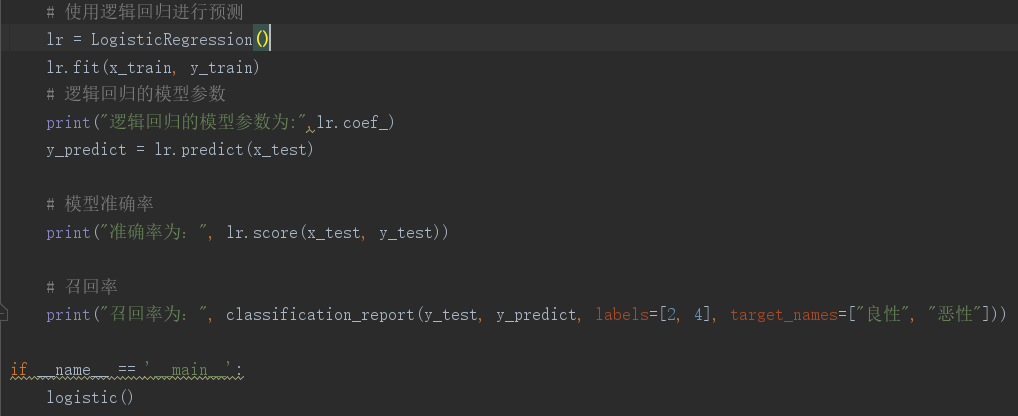

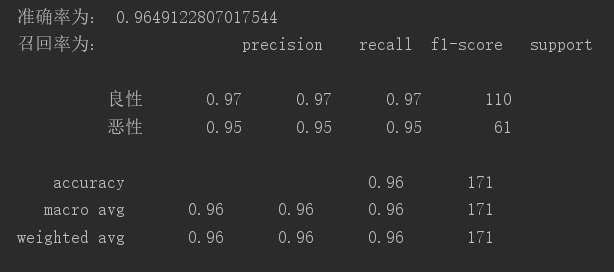
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
答:算法层面可以通过正则化来防止,数据层面可以通过加大样本量或者通过特征选择减少特征量,过拟合归根结底就是是太过贴近于训练数据的特征了,正则化中的L1正则便是通过增大正值向降低模型复杂度,L2正则则是通过使参数趋于0降低模型抖动,两者都通过自己的方式抵抗过拟合。
2.用logiftic回归来进行实践操作,数据不限。
使用的数据集与老师上课时的一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号