Redis持久化之内存快照(RDB)
我们都知道Redis是内存数据库,它将自己的数据存储的内存中。这样一旦服务器进程退出(断电、重启等原因),那么数据将会丢失。为了解决这个问题,Redis提供两种持久化的方式来将数据持久化到硬盘上,即内存快照(RDB)与AOF日志。
1 什么是内存快照
所谓内存快照,顾名思义就是给内存拍个照,在某个时刻把内存中的数据记录下来,以文件的形式保存到硬盘上,这样即使宕机,数据依然存在。在服务器重启后只需要把“照片”中的数据恢复即可。
RDB持久化就是把当前进程的数据在某个时刻生成快照(一个压缩的二进制文件)保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发。
1.1 RDB文件的创建
RDB文件的创建可以手动触发,也可以自动触发。
1.1 手动触发
手动触发分别对应save和bgsave命令:
1.1.1 save命令
save命令会阻塞当前Redis服务器,直到RDB过程完成为止。在服务器进程阻塞期间,服务器不能处理任何命令请求。因此,当save命令正在执行时,客户端发送的所有命令都会被拒绝,知道save命令执行完毕。
redis>save //等待,直到RDB文件创建完毕
ok
注意:
Redis的单线程模型就决定了,我们要尽量避免所有会阻塞主线程的操作,由于Save命令执行期间阻塞服务器进程,对于内存比较大的实例会造成长时间阻塞,因此线上环境不建议使用。
1.1.2 bgsave命令
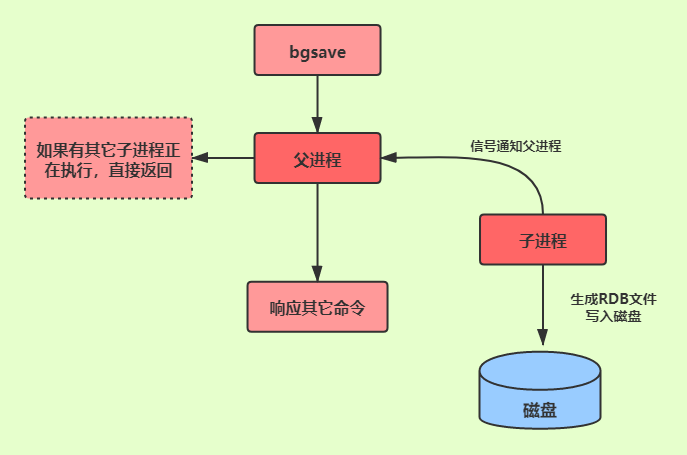
bgsave命令会派生出一个子进程(而不是线程),由子进程进行RDB文件创建,而父进程继续处理命令。
redis>bgsave
Background saving started //直接返回,由子进程进行RDB文件创建
redis> //继续处理其它命令
注意:
- 在bgsave命令执行的时候,为了避免父进程与子进程同时执行两个rdbSave的调用而产生竞争条件,客户端发送的save命令会被服务器拒绝。
- 如果bgsave命令正在执行,bgrewriteaof(aof重写)命令会被延迟到bgsave命令之后执行,如果bgrewriteaof命令正在执行,那么客户端发送的bgsave命令会被服务器拒绝。
- 虽然bgsave命令是由子进程进行RDB文件的生成,但是fork()创建子进程的时候会阻塞父进程(详情请往下看)。
1.2 自动触发
因为bgsave命令可以在不阻塞服务器进程的情况下保存,所以redis可以通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次bgsave命令。如:我们向服务器设置如下配置(这也是redis默认的配置):
save 900 1
save 300 10
save 60 10000
那么只要满足如下条件中的一个bgsave命令就会被执行:
- 服务器在900秒内对数据库进行了至少1次修改
- 服务器在300秒内对数据库进行了至少10次修改
- 服务器在60秒内对数据库进行了至少10000次修改
1.2 RDB文件的载入
在Redis启动的时候,只要检测到RDB文件的存在,就会自动加载RDB文件。需要注意的是
-
因为AOF文件的更新频率通常比RDB文件的更新频率高,所以口如果服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。
-
只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态。
注意:服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止
2 内存快照的问题
了解了什么是Redis的RDB持久化,我们来思考两个问题。
2.1 快照的时候数据可以修改吗
Redis RDB持久化是对某一时刻的内存中的全量数据进行拍照。这让我们不得不思考,快照的时候数据可以修改吗?
首先,如果我们使用save命令做持久化,那么由于Redis单线程模型的原因,在持久化的过程中会阻塞,是不能执行其它命令的。也许有人会说可以使用bgave命令,但使用bgsave就没有问题了吗?
我们在拍照的时候,通常摄影师是不让我们动的,因为一动可能照片就模糊了。在Redis 进行内存快照的时候也会如此。如果我们持久化的过程中,有些数据被修改了。那么就会破坏快照的正确性与完整性。
比如在t时刻,我们对内存进行快照,此时我们希望的是记录下来t时刻内存中所有的数据,假设我们的RDB操作需要10s的时间,而t+2s我们执行了一个修改操作把Key1的值由A修改成了B,而此时RDB操作却还没有把Key1的值写入磁盘。在t+5s的时候读取到key1的值写入磁盘。那么此次快照记录的Key1的值就是B,而不是t时刻的A。这样就破坏了RDB文件的正确性。
RDB文件的生成是需要时间的,如果快照执行期间数据不能被修改,对于业务系统来说不能接受的。那么Redis 是如何解决这个问题的呢?
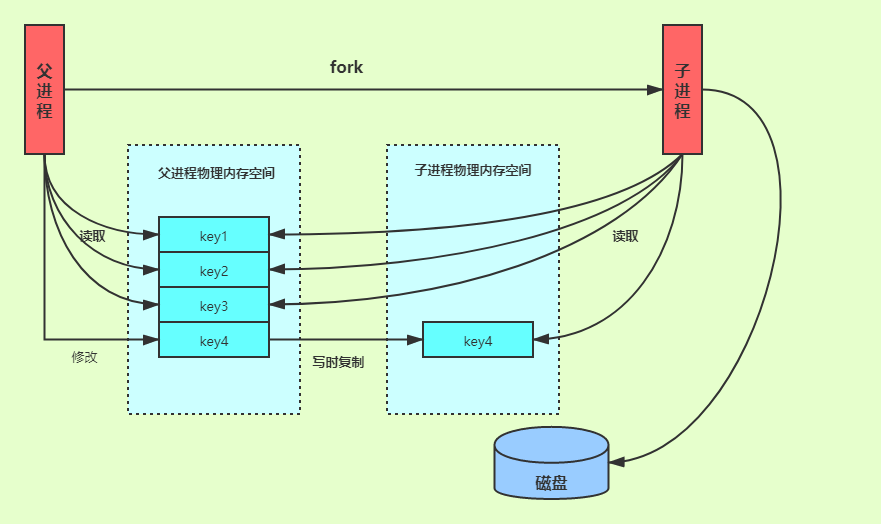
Redis 借助了操作系统提供的写时复制技术(Copy-On-Write, COW),可以让在执行快照的同时,正常处理写操作。简单来说,bgsave fork子进程的时候,并不会完全复制主进程的内存数据,而是只复制必要的虚拟数据结构,并不为其分配真实的物理空间,它与父进程共享同一个物理内存空间。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,此时会给子进程分配一块物理内存空间,把要修改的数据复制一份,生成该数据的副本到子进程的物理内存空间。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
2.2 可以频繁进行快照操作吗
假设我们在t 时刻做了一次快照,然后又在 t+n 时刻做了一次快照,而在这期间,发生了数据修改。而此时宕机了,那么,只能按照 t 时刻的快照进行恢复。那么这n秒的数据就彻底丢失无法恢复了。
所以,要想尽可能恢复数据,就只能缩短快照执行的时间间隔,间隔的时间越小,丢失数据也就越少。那么可以频繁的执行快照操作吗?
我们知道bgsave 执行时并不阻塞主线程,但是这不代表可以频繁执行快照操作。
一方面,持久化是一个写入磁盘的过程,频繁将全量数据写入磁盘,会给磁盘带来很大压力,频繁执行快照也容易导致前一个快照还没有执行完,后一个又开始了,这样多个快照竞争有限的磁盘带宽,容易造成恶性循环。
再者,bgsave所fork出来的子进程执行操作虽然并不会阻塞父进程的操作,但是fork出子进程的操作却是由主进程完成的,会阻塞主进程,fork子进程需要拷贝进程必要的数据结构,其中有一项就是拷贝内存页表(虚拟内存和物理内存的映射索引表),这个拷贝过程会消耗大量CPU资源,拷贝完成之前整个进程是会阻塞的,阻塞时间取决于整个实例的内存大小,实例越大,内存页表越大,fork阻塞时间也就越久。
也许有人会想到是否可以做增量快照呢?也就是只对上一次快照之后的数据做快照。
首先思路肯定是可以,但是增量快照要求记住哪些数据上一次快照之后产生的。这就需要额外的元数据来记录这些信息,会引入额外的空间消耗。这对于内存资源宝贵的 Redis 来说,并不是一个很好的方案。
总结:
RDB的优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集。
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复。
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能。
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些。
RDB的缺点
- 耗时、耗性能。RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求。如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度。
- 不可控、丢失数据。如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你。虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据。
如果不能频繁执行快照操作,那么该如何解决两次快照之间的数据丢失的问题呢?Redis 还提供了另外一种持久化方式——AOF(append to file)日志。
关于AOF日志请看Redis持久化-AOF

 浙公网安备 33010602011771号
浙公网安备 33010602011771号