webserver初体验
1 背景知识--http/1.1
HTTP请求报文解剖
HTTP请求报文由3部分组成(请求行+请求头+请求体):
下面是一个实际的请求报文:
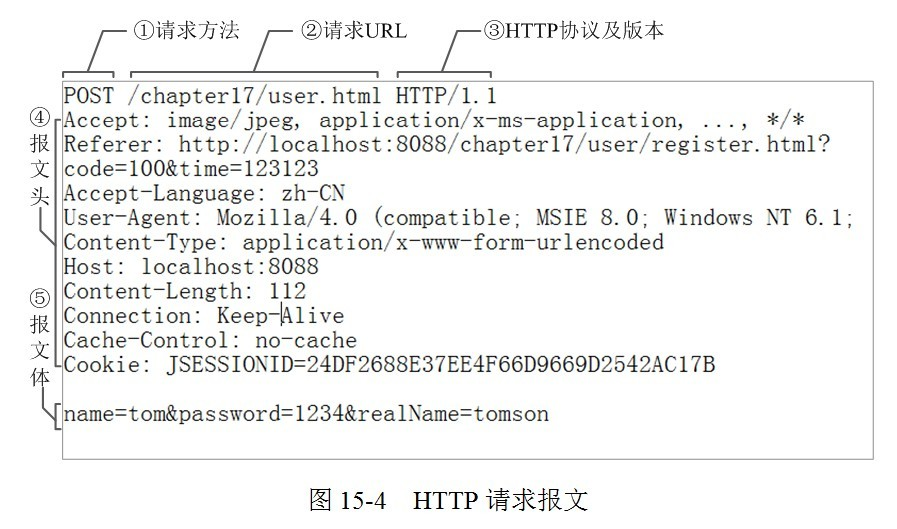
①是请求方法,GET和POST是最常见的HTTP方法,除此以外还包括DELETE、HEAD、OPTIONS、PUT、TRACE。不过,当前的大多数浏览器只支持GET和POST,Spring 3.0提供了一个HiddenHttpMethodFilter,允许你通过“_method”的表单参数指定这些特殊的HTTP方法(实际上还是通过POST提交表单)。服务端配置了HiddenHttpMethodFilter后,Spring会根据_method参数指定的值模拟出相应的HTTP方法,这样,就可以使用这些HTTP方法对处理方法进行映射了。
②为请求对应的URL地址,它和报文头的Host属性组成完整的请求URL,③是协议名称及版本号。
④是HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息。
⑤是报文体,它将一个页面表单中的组件值通过param1=value1¶m2=value2的键值对形式编码成一个格式化串,它承载多个请求参数的数据。不但报文体可以传递请求参数,请求URL也可以通过类似于“/chapter15/user.html? param1=value1¶m2=value2”的方式传递请求参数。
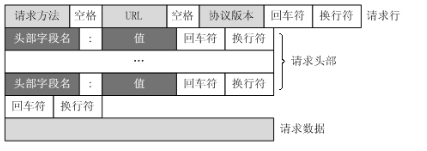
对照上面的请求报文,我们把它进一步分解,你可以看到一幅更详细的结构图:
HTTP响应报文解剖
响应报文结构
HTTP的响应报文也由三部分组成(响应行+响应头+响应体):
以下是一个实际的HTTP响应报文:

①报文协议及版本;
②状态码及状态描述;
③响应报文头,也是由多个属性组成;
④响应报文体,即我们真正要的“干货”。
响应状态码
和请求报文相比,响应报文多了一个“响应状态码”,它以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
- 1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
- 2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
- 3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
- 4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
- 5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
以下是几个常见的状态码:
200 OK
你最希望看到的,即处理成功!
303 See Other
我把你redirect到其它的页面,目标的URL通过响应报文头的Location告诉你。
唐僧:我哪有桃啊!去王母娘娘那找吧
304 Not Modified
告诉客户端,你请求的这个资源至你上次取得后,并没有更改,你直接用你本地的缓存吧,我很忙哦,你能不能少来烦我啊!
404 Not Found
你最不希望看到的,即找不到页面。如你在google上找到一个页面,点击这个链接返回404,表示这个页面已经被网站删除了,google那边的记录只是美好的回忆。
500 Internal Server Error
看到这个错误,你就应该查查服务端的日志了,肯定抛出了一堆异常,别睡了,起来改BUG去吧!
其它的状态码参见:http://en.wikipedia.org/wiki/List_of_HTTP_status_codes
有些响应码,Web应用服务器会自动给生成。你可以通过HttpServletResponse的API设置状态码:
- //设置状态码,状态码在HttpServletResponse中通过一系列的常量预定义了,如SC_ACCEPTED,SC_OK
- void setStatus(int sc)
常见的HTTP响应报文头属性
Cache-Control
响应输出到客户端后,服务端通过该报文头属告诉客户端如何控制响应内容的缓存。
下面的设置让客户端对响应内容缓存3600秒,也即在3600秒内,如果客户再次访问该资源,直接从客户端的缓存中返回内容给客户,不要再从服务端获取(当然,这个功能是靠客户端实现的,服务端只是通过这个属性提示客户端“应该这么做”,做不做,还是决定于客户端,如果是自己宣称支持HTTP的客户端,则就应该这样实现)。
- Cache-Control: max-age=3600
ETag
一个代表响应服务端资源(如页面)版本的报文头属性,如果某个服务端资源发生变化了,这个ETag就会相应发生变化。它是Cache-Control的有益补充,可以让客户端“更智能”地处理什么时候要从服务端取资源,什么时候可以直接从缓存中返回响应。
关于ETag的说明,你可以参见:http://en.wikipedia.org/wiki/HTTP_ETag。
Spring 3.0还专门为此提供了一个org.springframework.web.filter.ShallowEtagHeaderFilter(实现原理很简单,对JSP输出的内容MD5,这样内容有变化ETag就相应变化了),用于生成响应的ETag,因为这东东确实可以帮助减少请求和响应的交互。
下面是一个ETag:
- ETag: "737060cd8c284d8af7ad3082f209582d"
Location
我们在JSP中让页面Redirect到一个某个A页面中,其实是让客户端再发一个请求到A页面,这个需要Redirect到的A页面的URL,其实就是通过响应报文头的Location属性告知客户端的,如下的报文头属性,将使客户端redirect到iteye的首页中:
- Location: http://www.iteye.com
Set-Cookie
服务端可以设置客户端的Cookie,其原理就是通过这个响应报文头属性实现的:
- Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1
其它HTTP响应报文头属性
更多其它的HTTP响应头报文,参见:http://en.wikipedia.org/wiki/List_of_HTTP_header_fields
如何写HTTP请求报文头
在服务端可以通过HttpServletResponse的API写响应报文头的属性:
- //添加一个响应报文头属性
- void setHeader(String name, String value)
象Cookie,Location这些响应都是有福之人,HttpServletResponse为它们都提供了VIP版的API:
- //添加Cookie报文头属性
- void addCookie(Cookie cookie)
- //不但会设置Location的响应报文头,还会生成303的状态码呢,两者天仙配呢
- void sendRedirect(String location)
下面我已一个具体的案例来实际开发出一个webserver原型(比较简陋):
该项目共分为6个包,分别为:
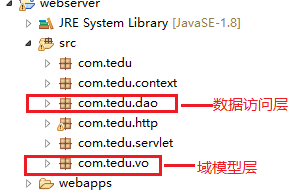
1 域模型层下主要是用户实体类等,该类只含有属性和set以及get等方法,不含有具体的业务逻辑。我的理解是该类就是一个封装了各种信息的实体类,用于供dao层服务,该类一般实现了序列化接口。
具体的UserInfo类代码如下:
package com.tedu.vo;
import java.io.Serializable;
/**
* 用户实体类
* @author Administrator
*
*/
public class UserInfo implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
private String username;
private String password;
private String nickname;
private String phonenumber;
public UserInfo() {
super();
}
public UserInfo(String username, String password, String nickname, String phonenumber) {
super();
this.username = username;
this.password = password;
this.nickname = nickname;
this.phonenumber = phonenumber;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
public String getPhonenumber() {
return phonenumber;
}
public void setPhonenumber(String phonenumber) {
this.phonenumber = phonenumber;
}
@Override
public String toString() {
return "UserInfo [username=" + username + ", password=" + password + ", nickname=" + nickname + ", phonenumber="
+ phonenumber + "]";
}
}
该类非常纯粹,不含有任何逻辑判断。
2 开发数据访问层(dao、dao.impl)
在该层中我并没有使用接口,直接定义了一个具体的实现类,该类直接与数据库等数据源进行交互,一般都离不开基本的CRUD(增删改查)操作,Dao层是直接和数据库交互的,所以Dao层的接口一般都会有增删改查这四种操作的相关方法。
类中方法的参数或者返回值一般为用户实体类实例,对于一些保存等操作,会有返回值标识是否保存成功
package com.tedu.dao;
import java.io.RandomAccessFile;
import java.util.Arrays;
import com.tedu.vo.UserInfo;
public class UserInfoDAO {
//保存用户信息
/**
* 如果写入成功则返回true 写入失败返回false
* @param userinfo
* @return
*/
public boolean save(UserInfo userinfo) {
try(RandomAccessFile raf=new RandomAccessFile("user.dat", "rw")){
//先将指针移动到文件末尾
raf.seek(raf.length());
String username=userinfo.getUsername();
String password=userinfo.getPassword();
String nickname=userinfo.getNickname();
String phonenumber=userinfo.getPhonenumber();
//
writeString(raf,username,20);
writeString(raf,password,32);
writeString(raf,nickname,32);
writeString(raf,phonenumber,32);
return true;
}catch(Exception e) {
e.printStackTrace();
}
return false;
}
private void writeString(RandomAccessFile raf, String string, int len) {
try {
byte [] data=string.getBytes("utf-8");
data=Arrays.copyOf(data , len);
raf.write(data);
}catch(Exception e) {
e.printStackTrace();
}
}
/**
* 在数据库中通过名字查找
* 如果没找到,则返回false
* 找到该用户,则返回该用户
* @param username
* @return
*/
public UserInfo findUserByUsername(String username) {
try(RandomAccessFile raf=new RandomAccessFile("user.dat", "rw")){
for (int i = 0; i < raf.length()/116; i++) {
raf.seek(i*116);
String name=readString(raf, 20);
if(name.equals(username)) {
//找到了
String pwd=readString(raf, 32);
String nickname=readString(raf, 32);
String phonenumber=readString(raf, 32);
return new UserInfo(name, pwd, nickname, phonenumber);
}
}
}catch(Exception e) {
e.printStackTrace();
}
return null;
}
private String readString(RandomAccessFile raf,int len) {
try {
byte [] data=new byte[len];
raf.read(data);
String str=new String(data, "utf-8").trim();
return str;
}catch(Exception e) {
e.printStackTrace();
}
return null;
}
public boolean update(UserInfo userinfo) {
try(RandomAccessFile raf=new RandomAccessFile("user.dat", "rw")){
String username=userinfo.getUsername();
String password=userinfo.getPassword();
String nickname=userinfo.getNickname();
String phonenumber=userinfo.getPhonenumber();
//先查找到要修改的记录位置
for (int i = 0; i < raf.length()/116; i++) {
raf.seek(i*116);
String name=readString(raf, 20);
if(name.equals(username)) {
writeString(raf, password, 32);
writeString(raf, nickname, 32);
writeString(raf, phonenumber, 32);
}
}
return true;
}catch(Exception e) {
e.printStackTrace();
}
return false;
}
}
3 开发web层
开发注册功能 该层会抽象出HttpServlet,所有Servlet继承于它。
从该层开始与浏览器request和response发生关系,可以使用request从请求端获取用户信息,并使用这些信息进行业务逻辑。
package com.tedu.servlet;
import com.tedu.dao.UserInfoDAO;
import com.tedu.http.HttpRequest;
import com.tedu.http.HttpResponse;
import com.tedu.vo.UserInfo;
public class RegServlet extends HttpServlet{
@Override
public void service(HttpRequest request, HttpResponse response) {
try {
//从请求端获取用户信息
String username=request.getParameter("username");
String password=request.getParameter("password");
String nickname=request.getParameter("nickname");
String phonenumber=request.getParameter("phonenumber");
UserInfoDAO dao=new UserInfoDAO();
if(dao.findUserByUsername(username)==null) {
//新用户
UserInfo newuser=new UserInfo(username, password, nickname, phonenumber);
dao.save(newuser);
forward("/myweb/reg_success.html",request,response);
}else {
forward("/myweb/reg_fail.html", request, response);
}
}catch(Exception e) {
e.printStackTrace();
}
}
}
RegServlet担任着以下几个职责:
1、接收客户端提交到服务端的表单数据。通过request对象取得表单数据。
2、校验表单数据的合法性,如果校验失败回显错误信息。
3、如果校验通过,调用dao层向数据库中注册用户。
4 开发ClientHandler,通过解析requestURI来判断是何种业务,然后调用具体的servlet来完成功能;如果是文件资源,则直接调用response直接写回给浏览器。
package com.tedu;
import java.io.File;
import java.net.Socket;
import com.tedu.context.HttpContext;
import com.tedu.http.HttpRequest;
import com.tedu.http.HttpResponse;
import com.tedu.servlet.LoginServlet;
import com.tedu.servlet.RegServlet;
import com.tedu.servlet.UpdateServlet;
public class ClientHandler implements Runnable{
private Socket socket;
public ClientHandler(Socket socket) {
super();
this.socket = socket;
}
@Override
public void run() {
try {
HttpRequest request=new HttpRequest(socket.getInputStream());
HttpResponse response=new HttpResponse(socket.getOutputStream());
//获取请求路径
String requestURI=request.getRequestURI();
//判断是否为注册业务
if("/myweb/reg".equals(requestURI)) {
RegServlet reg=new RegServlet();
reg.service(request, response);
}else if("/myweb/log_in".equals(requestURI)) {
LoginServlet log=new LoginServlet();
log.service(request, response);
}else if("/myweb/update".equals(requestURI)) {
UpdateServlet update=new UpdateServlet();
update.service(request, response);
}
//需要判断请求的文件是否存在?
File file=new File("webapps"+request.getRequestURI());
if(file.exists()) {
//解析出后缀名
String fileName=file.getName();
int index=fileName.lastIndexOf('.');
String extension=fileName.substring(index+1);
//通过解析出的后缀名设置介质类型
response.setContentType(HttpContext.getMimeType(extension));
response.setContentLength(file.length());
System.out.println("请求的文件存在");
response.setEntity(file);
response.flush();
}else {
System.out.println("请求的文件不存在");
}
}catch(Exception e) {
e.printStackTrace();
}finally {
try {
socket.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
}
5 HttpRequest类和HttpResponse类是较为底层的类,其完成的主要工作是解析浏览器的请求和发送数据给浏览器。
package com.tedu.http;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Map;
//解析请求
public class HttpRequest {
private InputStream in;
private String method;
//url临时保存地址
private String url;
private String protocol;
//进一步解析 前后按?隔开
private String requestURI;
private String queryString;
//存储所有参数 ?后面的
private Map<String, String> parameters=new HashMap<>();
//存储请求头
private Map<String, String> headers=new HashMap<>();
public HttpRequest(InputStream in) {
super();
this.in = in;
parseRequestLine();
//进一步解析url 分成requestURI queryRequest
parseUrl();
parseHeaders();
}
private void parseHeaders() {
String header;
while(!"".equals(header=readLine())) {
int index=header.indexOf(':');
headers.put(header.substring(0, index).trim(),
header.substring(index+1).trim());
}
}
//解析请求行
private void parseRequestLine() {
//先读一行
String requestLine=readLine();
String [] arrays=requestLine.split("\\s");
this.method=arrays[0];
this.url=arrays[1];
this.protocol=arrays[2];
parseUrl();
}
private String readLine() {
try {
StringBuilder builder=new StringBuilder("");
int d=-1;
char c2='a';
char c1='a';
while(true) {
d=in.read();
c2=(char)d;
if(c1==13&&c2==10) {
break;
}
builder.append(c2);
c1=c2;
}
return builder.toString().trim();
}catch(Exception e) {
e.printStackTrace();
}
return null;
}
//详细解析URL部分
private void parseUrl() {
if(url.contains("?")) {
String[] array=url.split("\\?");
requestURI=array[0];
queryString=array[1];
/*
* 拆分所有参数
* 1 按照&拆分出每个参数
*/
String [] paraArray=queryString.split("[&]");
for (String string : paraArray) {
//2 按照=拆分出每个键值对
/*
* 如果=右边没有值 则赋值为空字符串
*/
String [] arrays=string.split("=");
if(arrays.length==2) {
this.parameters.put(arrays[0], arrays[1]);
}else {
this.parameters.put(arrays[0], "");
}
}
}else {
requestURI=url;
}
}
public String getRequestURI() {
return requestURI;
}
//通过username password nickname phonenumber返回具体的值
public String getParameter(String name) {
return this.parameters.get(name);
}
}
package com.tedu.http; //回复响应 import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.OutputStream; import java.util.HashMap; import java.util.Map; import java.util.Map.Entry; import com.tedu.context.HttpContext; public class HttpResponse { private OutputStream out; private File entity; //用于存放响应头 HttpResponse内部维护了一个headers private Map<String, String> headers=new HashMap<>(); public HttpResponse(OutputStream out) { super(); this.out = out; } public void flush() { try { //写状态行 printLn("http/1.1 200 ok"); //写响应头 for (Entry<String, String> e : headers.entrySet()) { printLn(e.getKey()+":"+e.getValue()); } //响应头结束 printLn(""); //写响应正文 writeContent(); }catch(Exception e) { e.printStackTrace(); } } private void writeContent() throws Exception{ //写响应正文 FileInputStream fis=new FileInputStream(entity); BufferedInputStream br=new BufferedInputStream(fis); byte [] buf=new byte[1024*10]; int len=-1; while((len=br.read(buf))!=-1) { out.write(buf, 0, len); } br.close(); } private void printLn(String string) throws Exception{ out.write(string.getBytes("iso8859-1")); out.write('\r'); out.write('\n'); } public void setEntity(File entity) { this.entity = entity; } public void setContentType(String contentType) { this.headers.put(HttpContext.HEADER_CONTENT_TYPE, contentType); } public void setContentLength(long length) { this.headers.put(HttpContext.HEADER_CONTENT_LENGTH, length+""); } }
通过这个小例子,可以了解到mvc分层架构的项目搭建,在平时的项目开发中,也都是按照如下的顺序来进行开发的:
1、搭建开发环境
1.1 创建web项目
1.2 导入项目所需的开发包
1.3 创建程序的包名,在java中是以包来体现项目的分层架构的
2、开发domain
把一张要操作的表当成一个VO类(VO类只定义属性以及属性对应的get和set方法,没有涉及到具体业务的操作方法),VO表示的是值对象,通俗地说,就是把表中的每一条记录当成一个对象,表中的每一个字段就作为这个对象的属性。每往表中插入一条记录,就相当于是把一个VO类的实例对象插入到数据表中,对数据表进行操作时,都是直接把一个VO类的对象写入到表中,一个VO类对象就是一条记录。每一个VO对象可以表示一张表中的一行记录,VO类的名称要和表的名称一致或者对应。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号