
第一次个人编程作业
GitHub链接
首先给出gitHub链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 7 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 7 |
| Development | 开发 | 860 | 1166 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 335 |
| · Design Spec | · 生成设计文档 | 40 | 2 |
| · Design Review | · 设计复审 | 40 | 2 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 20 | 12 |
| · Coding | · 具体编码 | 320 | 676 |
| · Code Review | · 代码复审 | 20 | 2 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 137 |
| Reporting | 报告 | 140 | 129 |
| · Test Repor | · 测试报告 | 40 | 75 |
| · Size Measurement | · 计算工作量 | 40 | 34 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 20 |
| 合计 | 1010 | 1302 |
计算模块接口的设计与实现过程
在面向搜索引擎编程之后,以我对几个查重算法的理解下——simhash更像是评价是否有,海明距离难以体现出抄了多少。minHash与Jaccard系数,这两个是相似的,这两个的问题在于他无法体现出每个词出现的次数,在Jaccard里一个词出现多次与出现一次的效果相同。这点在长文本非常致命。所以在考虑之后,我使用了余弦相似性。他充分运用了次数(当然这个在一些情况也是一个大问题)
余弦相似度的原理,就是将文章通过词频构建向量,计算两个向量的相似程度——即夹角。这可以用余弦值得到
即
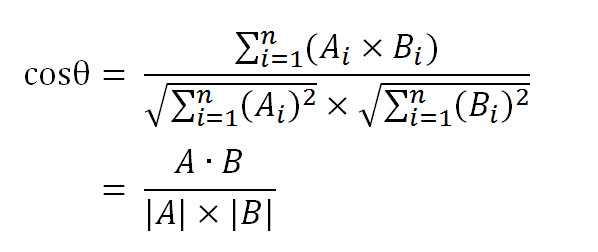
因此我可以先分词(这里使用了结巴分词),然后通过Map来存词在两篇文章各自出现次数,然后处理
然而,当我初次实现时,我却遇到一个诡异的问题,文本相似度基本高达1。这是为什么呢?
在考证之后



前面三十万是A平方的合计值,我们可以看到仅“的”就提供了将近九万的值,也就是说,“我”与“的”已经影响了这边文章查重的50%以上。
这合理吗?不这不合理!
我们要解决这个问题,必须引入权重。
我一开始瞄上了TdIdf算法。很可惜我没有在网上找到可以导的包。。。。但是我通过对它的想法,写了一个程序(虽然程序名字写的是tfIdf但是我用的与一开始的定义有着相当大的不同)——我对五本小说进行结巴分词,然后将词与词频以json格式存起来了。
然而关于权重,在几次测试之后发现。如果以log的形式,由于log函数的递增速度过慢,像以“我”这个词为例,他的权重会是正常词的一半,但是在平方的状况下依旧不够有效。
我使用的权重是 (出现次数最多的词的次数)/(词的出现次数+1)的平方根 。
所以在计算余弦向量时,先解析了.json文件,然后对每个词的运算引入查重。

计算模块接口部分的性能改进


时间的大头是在结巴算法的初始化,另外一个是对json文件的转化。我一开始以为时间是消耗在I/O操作,所以我使用了多线程。

但就结果而言,并没有什么卵用,其实时间的消耗估计是在cpu,我确实无计可施。
计算模块部分单元测试展示


测试包括了
@Test(timeout = 5000)
public void Test(){
String[] str = {IN_PATH+"time1.txt",IN_PATH+"time2.txt",filePath+"result/ans_time.txt"};
Main.main(str);
}
这类测超时的,也有对jieba分词,以及文本处理的测试。使用的是Junit。但是在分支覆盖率查询时视乎运行会慢很多。
计算模块部分异常处理说明
我设计了两个异常
package Except;
public class FileIsNullExcept extends RuntimeException{
public FileIsNullExcept(){
super();
}
public FileIsNullExcept(String message){
super(message);
}
}
这是文件为空的异常
package Except;
public class SimilarExcept extends RuntimeException{
public SimilarExcept(){
super();
}
public SimilarExcept(String message){
super(message);
}
}
这是相似为1会报错
并在测试中进行了测试;
@Test(expected = FileIsNullExcept.class)
public void test3FileNullExcept() {
String[] str = {filePath+"test/null.txt",IN_PATH+"time2.txt",filePath+"result/ans_time.txt"};
Main.main(str);
}
@Test(expected = SimilarExcept.class)
public void Test4SimilarExcept(){
String[] str = {IN_PATH+"time2.txt",IN_PATH+"time2.txt",filePath+"result/ans_time.txt"};
Main.main(str);
}
总结
- 这次还是有问题不够满意,比如文件读取时的编码,还有权重的算法,这是我目前能力的不足。希望下次能做的好点的吧。
- 我这次项目的没有仔细用过设计文档,毕竟难以在一开始获得详细的全貌,以及很多其中的问题还是需要面向搜索引擎编程。但是目前看,尽早的详细思路其实可以避免后期走入大坑,下次我还是得进行详细事先计划。
