2025.1.15 学习
2025.1.15 学习
api开放平台
我们希望在后端使用Http请求调用接口,应该怎么做呢
可以用Hutool工具库中的Http请求工具类,使用如下:
public class ApiClient {
public String getNameByGet(String name){
HashMap<String, Object> paramMap = new HashMap<>();
paramMap.put("name", name);
String result= HttpUtil.get("http://localhost:8080/api/name/", paramMap);
System.out.println(result);
return result;
}
public String getNameByPost(String name) {
HashMap<String, Object> paramMap = new HashMap<>();
paramMap.put("name", name);
String result= HttpUtil.post("http://localhost:8080/api/name/", paramMap);
System.out.println(result);
return result;
}
public String getUsernameByPost(User user){
String json =JSONUtil.toJsonStr(user);
HttpResponse httpResponse = HttpRequest.post("http://localhost:8080/api/name/user")
.body(json)
.execute();
System.out.println(httpResponse.getStatus());
System.out.println(httpResponse.body());
return httpResponse.body();
}
}
项目开在8080端口,提供了几个接口如下
@RestController
@RequestMapping("/name")
public class NameController {
@GetMapping("/")
public String getNameByGet(String name){
return "GET 你的名字是"+name;
}
@PostMapping("/")
public String getNameByPost(@RequestParam String name){
return "POST 你的名字是"+name;
}
@PostMapping("/user")
public String getUserNameByPost(@RequestBody User user){
return "POST 你的名字是"+user.getUsername();
}
}
八股
@Autowired注解和@Resouce注解
首先Spring官方是推荐@Autowired注解的,但是我们在idea中使用@Autowired注解,会有黄色波浪线,显示Field injection is not recommended。所以在项目中我们一般使用@Resource注解来进行依赖注入
接下来我们说一下二者的区别
-
@Autowired注解是按照类型方式自动装配,如果有多个同类型的Bean,则需要通过@Qualifier指定具体的Bean。
-
@Resource注解是Java自带的注入方式,按照名称自动装配,默认是按照属性名称进行匹配,如果需要按照Bean的名称进行匹配,可以使用@Resource(name="beanName")
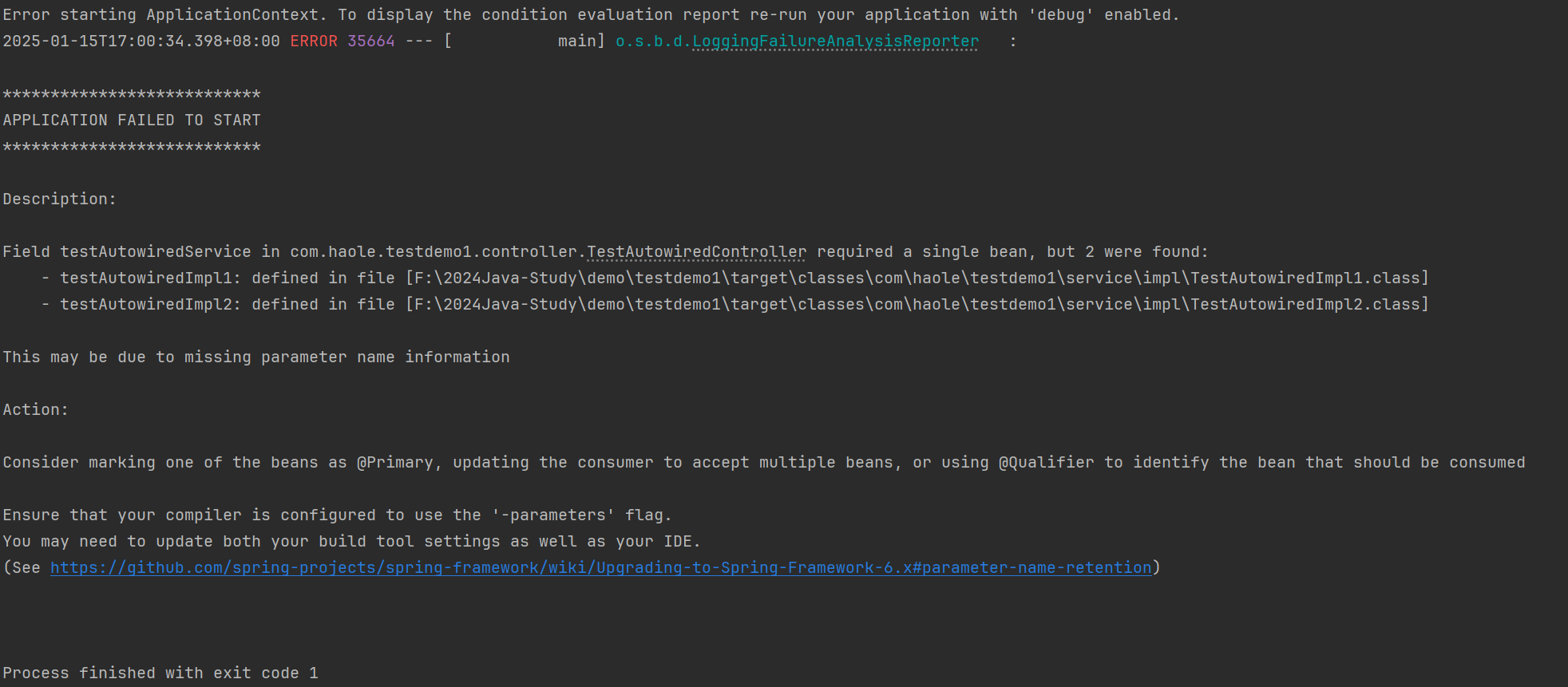
我们来试一下@Autowired注解找到两个可以注入的Bean会怎样
@RestController
@RequestMapping("/autowired")
public class TestAutowiredController {
@Autowired
private TestAutowired testAutowiredService;
@RequestMapping("/test")
public void test(){
testAutowiredService.AutoWiredTest();
}
}
//TestAutowired接口
public interface TestAutowired {
String AutoWiredTest();
}
//实现类1
@Service
public class TestAutowiredImpl1 implements TestAutowired {
@Override
public String AutoWiredTest() {
System.out.println("实现1");
return null;
}
}
//实现类2
@Service
public class TestAutowiredImpl2 implements TestAutowired {
@Override
public String AutoWiredTest() {
System.out.println("实现2");
return null;
}
}
报错如下:
Redis主从复制
Redis 的主从复制是指一个 Redis 实例(主节点)可以将数据复制到一个或多个从节点(从节点)),从节点从主节点获取数据并保持同步
流程
开始同步:从节点通过向主节点发送 PSYNC命令发起同步。
全量复制:如果是第一次连接或之前的连接失效,从节点会请求全量复制,主节点将当前数据快照(RDB文件)发送给从节点。
增量复制:
情况一:全量复制完毕后,主从之间会保持一个长连接,主节点会通过这个连接将后续的写操作传递给从节点执行,来保证数据的一致。
情况二:主从之间的网络可能不稳定,如果连接断开,主节点部分写操作未传递给从节点执行,主从数据就不一致了。此时有一种选择是再次发起全量同步,但是全量同步数据量比较大,非常耗时。因此 Redis 在 2.8 版本引入了增量同步(psync 其实就是 2.8引入的命令)仅需把连接断开其间的数据同步给从节点就好了。此时需要介绍下 repl_backlog_buffer。repl_backlog_buffer是一个环形缓冲区,默认大小为1m。主节点会将写入命令存到这个缓冲区中,但是大小有限,待写入的命令超过 1m 后,会覆盖之前的数据,因为是环形写入。增量同步也是 psync 命令,如果主节点判断从节点传递的 runid 和主节点一致,且根据 offset 判断数据还在repl_backlog_buffer 中,则说明可以进行增量同步。于是就去 repl_backlog_buffer 查找对应 offset之后的命令数据,写入到replication buffer中,最终将其发送给 slave节点。slave 节点收到指令之后执行对应的命令,一次增量同步的过程就完成了。
综上,我们也可以总结一下replication buffer和repl_backlog_buffer之间的区别。replication呢是主节点对应每个从节点都有的一块区域,用于在长连接过程中实时传输写命令,而repl_backlog_buffer在主节点上只有一个,存储最近的写命令,用于从服务器重新连接时的部分重同步。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构