bupt_os_lab2
1.2024年7.4-7.8学习总结/暑假day7-112.2024.6.6学习java&算法3.2024年6.7--6.17学习总结4.2024年7.3学习总结/暑假day65.2024年6.27-7.2学习总结/暑假day1--56.2024年6.23-6.26学习总结7.2024年6.18-6.22学习总结8.2024年7.9-7.19学习总结/暑假day12-229.2024年7.26-7.29学习总结/day29-3210.编程日记 批量导入数据11.编程日记 后端使用redis12.编程日记 更改redis存储默认序列化器13.ide启动多个实例14.session和cookie15.java多线程16.bupt_os_lab117.11.12 ali-oss上传图片18.sql 1661
19.bupt_os_lab2
20.11.18 学习21.11.21 打工22.IntelliJ IDEA格式化快捷键失效23.leetcode78 子集24.leetcode39 组合总和25.11.30学习日记26.12.6详解前后端对接27.2024.12.9 小bug28.12.23软工踩坑29.leetcode 104530.2024.12.26 os lab331.2024.12.27复习日记32.一文搞定宝塔LINUX部署上线前后端分离项目33.2025.1.2复习34.leetcode 178935.leetcode131 分割回文串36.2025.1.13 redis乱码问题解决37.2025.1.15 学习38.2025.2.17 学习39.2025.2.18 学习40.2025.2.19 学习41.2025.2.24学习42.git clone问题解决43.2025.2.27 学习44.2025.3.4 学习easy_lab2
作业地址:https://github.com/BUPT-OS/easy_lab/tree/lab2
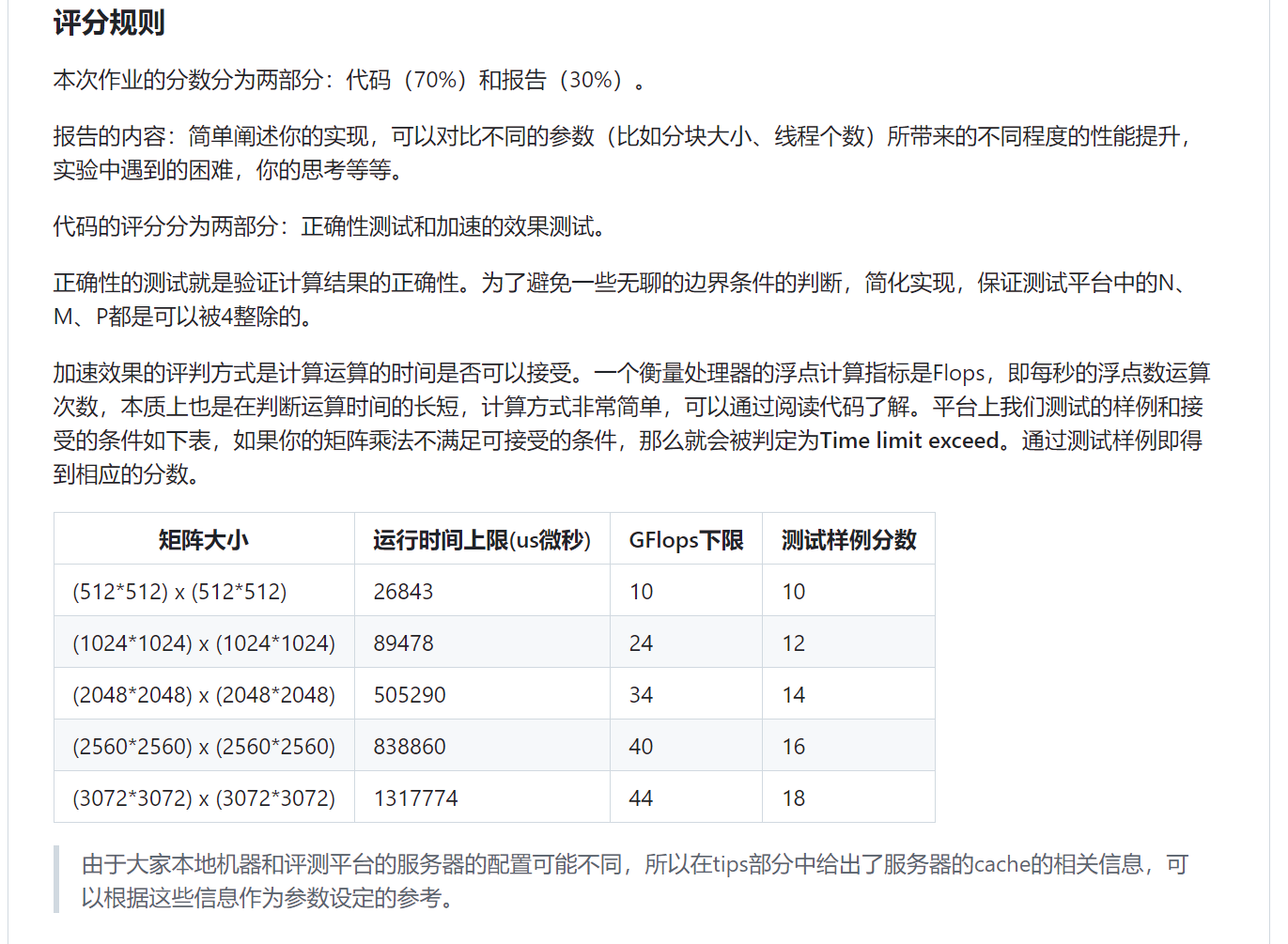
以下均为multiply.cpp代码
22分多线程,分块,调整计算顺序
#include "multiply.h"
#include <emmintrin.h> // SSE2
#include <pmmintrin.h> // SSE3
#include <thread>
#include <vector>
// 定义块大小和线程数量
#define BLOCK_SIZE 32
void block_multiply(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P],
int i_start, int i_end, int j_start, int j_end)
{
for (int ii = i_start; ii < i_end; ii += BLOCK_SIZE) {
for (int jj = j_start; jj < j_end; jj += BLOCK_SIZE) {
for (int kk = 0; kk < M; kk += BLOCK_SIZE) {
// 块内循环
for (int i = ii; i < ii + BLOCK_SIZE && i < i_end; i++) {
for (int j = jj; j < jj + BLOCK_SIZE && j < j_end; j++) {
__m128d sum = _mm_setzero_pd(); // 初始化 SIMD 累加器
// 使用循环展开和 SIMD 加速
int k;
for (k = kk; k <= kk + BLOCK_SIZE - 2 && k < M; k += 2) {
__m128d m1 = _mm_loadu_pd(&matrix1[i][k]);
__m128d m2 = _mm_set_pd(matrix2[k+1][j], matrix2[k][j]);
sum = _mm_add_pd(sum, _mm_mul_pd(m1, m2));
}
double temp[2];
_mm_storeu_pd(temp, sum);
result_matrix[i][j] += temp[0] + temp[1];
// 处理剩余的元素
for (; k < kk + BLOCK_SIZE && k < M; k++) {
result_matrix[i][j] += matrix1[i][k] * matrix2[k][j];
}
}
}
}
}
}
}
void matrix_multiplication(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P])
{
// 初始化结果矩阵
for (int i = 0; i < N; i++) {
for (int j = 0; j < P; j++) {
result_matrix[i][j] = 0.0;
}
}
// 确定线程数量
int num_threads = std::thread::hardware_concurrency();
std::vector<std::thread> threads;
int rows_per_thread = N / num_threads;
// 创建线程池
for (int t = 0; t < num_threads; t++) {
int i_start = t * rows_per_thread;
int i_end = (t == num_threads - 1) ? N : (t + 1) * rows_per_thread;
// 每个线程处理矩阵的一个子块
threads.emplace_back(block_multiply, matrix1, matrix2, result_matrix, i_start, i_end, 0, P);
}
// 等待所有线程完成
for (auto &th : threads) {
th.join();
}
}
36分
#include "multiply.h"
#include <cstdio>
#include <thread>
#include <immintrin.h>
#include <pmmintrin.h>
#include <algorithm>
#include <pthread.h>
#define L1_BLOCK_SIZE 64
#define L2_BLOCK_SIZE 128
#define L3_BLOCK_SIZE 256
typedef struct {
int thread_id;
double (*matrix1)[M];
double (*matrix2)[P];
double (*result_matrix)[P];
int block_size;
} ThreadData;
void block_matrix_multiply(double (*matrix1)[M], double (*matrix2)[P], double (*result_matrix)[P],
int row_start, int row_end, int col_start, int col_end, int mid_start, int mid_end, int block_size) {
for (int i = row_start; i < row_end; i++) {
double *temp_rm = result_matrix[i];
for (int k = mid_start; k < mid_end; k++) {
double temp_m1 = matrix1[i][k];
double *temp_m2 = matrix2[k];
int j = col_start;
for (; j + 7 < col_end; j += 8) {
__m512d m1 = _mm512_set1_pd(temp_m1);
__m512d m2 = _mm512_loadu_pd(temp_m2 + j);
__m512d rm = _mm512_loadu_pd(temp_rm + j);
__m512d res = _mm512_fmadd_pd(m1, m2, rm); // FMA 优化
_mm512_storeu_pd(temp_rm + j, res);
}
for (; j < col_end; j++) {
temp_rm[j] += temp_m1 * temp_m2[j];
}
}
}
}
void* thread_matrix_multiply(void* arg) {
ThreadData* data = (ThreadData*)arg;
int NUM_THREADS = std::thread::hardware_concurrency();
int rows_per_thread = (N + NUM_THREADS - 1) / NUM_THREADS;
int start_row = data->thread_id * rows_per_thread;
int end_row = std::min(start_row + rows_per_thread, N);
for (int i = start_row; i < end_row; i += data->block_size) {
int block_i_end = std::min(i + data->block_size, end_row);
for (int j = 0; j < P; j += data->block_size) {
int block_j_end = std::min(j + data->block_size, P);
for (int k = 0; k < M; k += data->block_size) {
int block_k_end = std::min(k + data->block_size, M);
block_matrix_multiply(data->matrix1, data->matrix2, data->result_matrix,
i, block_i_end, j, block_j_end, k, block_k_end, data->block_size);
}
}
}
pthread_exit(NULL);
}
void matrix_multiplication(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P]) {
// 初始化结果矩阵
for (int i = 0; i < N; ++i) {
for (int j = 0; j < P; ++j) {
result_matrix[i][j] = 0.0;
}
}
int NUM_THREADS = std::thread::hardware_concurrency();
pthread_t threads[NUM_THREADS];
ThreadData thread_data[NUM_THREADS];
// 动态选择分块大小
int block_size;
if (N >= 2048) {
block_size = L3_BLOCK_SIZE;
} else if (N >= 1024) {
block_size = L2_BLOCK_SIZE;
} else {
block_size = L1_BLOCK_SIZE;
}
for (int i = 0; i < NUM_THREADS; i++) {
thread_data[i].thread_id = i;
thread_data[i].matrix1 = matrix1;
thread_data[i].matrix2 = matrix2;
thread_data[i].result_matrix = result_matrix;
thread_data[i].block_size = block_size;
pthread_create(&threads[i], NULL, thread_matrix_multiply, (void*)&thread_data[i]);
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
}
70分:加上o3优化,会快非常多
#include "multiply.h"
#include <cstdio>
#include <thread>
#include <immintrin.h>
#include <pmmintrin.h>
#include <algorithm>
#include <pthread.h>
#pragma GCC optimize("O3")
#define L1_BLOCK_SIZE 64
#define L2_BLOCK_SIZE 128
#define L3_BLOCK_SIZE 256
typedef struct {
int thread_id;
double (*matrix1)[M];
double (*matrix2)[P];
double (*result_matrix)[P];
int block_size;
} ThreadData;
void block_matrix_multiply(double (*matrix1)[M], double (*matrix2)[P], double (*result_matrix)[P],
int row_start, int row_end, int col_start, int col_end, int mid_start, int mid_end, int block_size) {
for (int i = row_start; i < row_end; i++) {
double *temp_rm = result_matrix[i];
for (int k = mid_start; k < mid_end; k++) {
double temp_m1 = matrix1[i][k];
double *temp_m2 = matrix2[k];
int j = col_start;
for (; j + 7 < col_end; j += 8) {
__m512d m1 = _mm512_set1_pd(temp_m1);
__m512d m2 = _mm512_loadu_pd(temp_m2 + j);
__m512d rm = _mm512_loadu_pd(temp_rm + j);
__m512d res = _mm512_fmadd_pd(m1, m2, rm); // FMA 优化
_mm512_storeu_pd(temp_rm + j, res);
}
for (; j < col_end; j++) {
temp_rm[j] += temp_m1 * temp_m2[j];
}
}
}
}
void* thread_matrix_multiply(void* arg) {
ThreadData* data = (ThreadData*)arg;
int NUM_THREADS = std::thread::hardware_concurrency();
int rows_per_thread = (N + NUM_THREADS - 1) / NUM_THREADS;
int start_row = data->thread_id * rows_per_thread;
int end_row = std::min(start_row + rows_per_thread, N);
for (int i = start_row; i < end_row; i += data->block_size) {
int block_i_end = std::min(i + data->block_size, end_row);
for (int j = 0; j < P; j += data->block_size) {
int block_j_end = std::min(j + data->block_size, P);
for (int k = 0; k < M; k += data->block_size) {
int block_k_end = std::min(k + data->block_size, M);
block_matrix_multiply(data->matrix1, data->matrix2, data->result_matrix,
i, block_i_end, j, block_j_end, k, block_k_end, data->block_size);
}
}
}
pthread_exit(NULL);
}
void matrix_multiplication(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P]) {
// 初始化结果矩阵
for (int i = 0; i < N; ++i) {
for (int j = 0; j < P; ++j) {
result_matrix[i][j] = 0.0;
}
}
int NUM_THREADS = std::thread::hardware_concurrency();
pthread_t threads[NUM_THREADS];
ThreadData thread_data[NUM_THREADS];
// 动态选择分块大小
int block_size;
if (N >= 2048) {
block_size = L3_BLOCK_SIZE;
} else if (N >= 1024) {
block_size = L2_BLOCK_SIZE;
} else {
block_size = L1_BLOCK_SIZE;
}
for (int i = 0; i < NUM_THREADS; i++) {
thread_data[i].thread_id = i;
thread_data[i].matrix1 = matrix1;
thread_data[i].matrix2 = matrix2;
thread_data[i].result_matrix = result_matrix;
thread_data[i].block_size = block_size;
pthread_create(&threads[i], NULL, thread_matrix_multiply, (void*)&thread_data[i]);
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构