
Ceph Mimic版本配置Prometheus监控
参考:
https://docs.ceph.com/en/mimic/mgr/prometheus/
https://grafana.com/grafana/dashboards/2842
提供 Prometheus 导出器以从 ceph-mgr 中的收集点传递 Ceph 性能计数器。
Ceph-mgr 从所有 MgrClient 进程(例如,mons 和 OSD)接收带有性能计数器模式数据和实际计数器数据的 MMgrReport 消息,并保留最后 N 个样本的循环缓冲区。
这个插件创建一个 HTTP 端点(像所有 Prometheus 导出器一样)并在轮询(或 Prometheus 术语中的“抓取”)时检索每个计数器的最新样本。HTTP 路径和查询参数被忽略;所有报告实体的所有现有计数器都以文本说明格式返回。
1. 启用prometheus输出模块
ceph mgr module enable prometheus1.1 配置
默认情况下,模块将接受主机上所有 IPv4 和 IPv6 地址端口9283上的 HTTP 请求。端口和侦听地址都可以使用ceph config-key set、 mgr/prometheus/server_addr和mgr/prometheus/server_port键进行配置。此端口已在 Prometheus 中注册。
2. 统计名称和标签
统计信息的名称与 Ceph 的名称完全相同,带有非法字符.,-和::被翻译为_,并在所有名称前加上ceph_前缀。
所有守护进程统计信息都有一个ceph_daemon标签,例如“osd.123”,用于标识它们来自守护进程的类型和 ID。一些统计信息可能来自不同类型的守护进程,因此当查询类似 OSD 的 RocksDB 统计信息时,您可能希望过滤以“osd”开头的 ceph_daemon 以避免混入MON的 RocksDB 统计信息。
集群统计信息(即 Ceph 集群的全局统计信息)具有适合其报告内容的标签。例如,与池相关的指标具有pool_id标签。
代表核心 Ceph 直方图的长期运行平均值由一对<name>_sum和<name>_count指标表示。这类似于Prometheus中直方图的表示方式, 也可以类似地对待它们。
2.1 池和 OSD 元数据SERIES
输出特殊SERIES以启用对某些元数据字段的显示和查询。
池有这样的ceph_pool_metadata字段:
ceph_pool_metadata{pool_id="2",name="cephfs_metadata_a"} 1.0OSD 有这样一个ceph_osd_metadata字段:
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096",device_class="ssd",ceph_daemon="osd.0",public_addr="172.21.9.34:6801/19096",weight="1.0"} 1.02.2 将驱动器统计信息与 NODE_EXPORTER 相关联
Ceph 的 prometheus 输出旨在与 Prometheus node_exporter 的通用主机监控结合使用。
为了使 Ceph OSD 统计信息与 node_exporter 的驱动统计信息相关联,特殊SERIES的输出如下:
ceph_disk_occupation{ceph_daemon="osd.0",device="sdd", exported_instance="myhost"}要使用它通过 OSD ID 获取磁盘统计信息,请在 prometheus 查询中使用and运算符或*运算符。所有元数据指标(如 ``ceph_disk_occupation`` 的值为 1,因此它们与 *. 保持中立。使用* 允许使用group_left和group_right分组修饰符,以便生成的指标具有来自查询一侧的附加标签。
目标是运行类似的查询:
rate(node_disk_bytes_written[30s]) and on (device,instance) ceph_disk_occupation{ceph_daemon="osd.0"}开箱即用上述查询不会返回任何指标,因为instance两个指标的标签不匹配。ceph_disk_occupation的instance标签将是当前活动的 MGR 节点。
以下两节概述了解决此问题的两种方法。
3. 使用 LABEL_REPLACE
label_replace函数可以在查询中为度量添加标签或更改其标签。
要关联 OSD 及其磁盘写入速率,可以使用以下查询:
label_replace(rate(node_disk_bytes_written[30s]), "exported_instance", "$1", "instance", "(.*):.*") and on (device,exported_instance) ceph_disk_occupation{ceph_daemon="osd.0"}4. 配置 PROMETHEUS 服务器
4.1 HONOR_LABELS
要使 Ceph 能够输出与任何主机相关的正确标记的数据,请在将 ceph-mgr 端点添加到您的 prometheus 配置时使用honor_labels设置。
这允许 Ceph 导出正确的instance标签,而不会被 prometheus 覆盖。如果没有此设置,Prometheus 会应用一个instance标签,其中包含来自series game的端点的主机名和端口。因为 Ceph 集群有多个管理器守护程序,所以当活动管理器守护程序更改时,这会导致 instance标签发生虚假更改。
4.2 NODE_EXPORTER 主机名标签
设置您的instance标签以匹配该instance字段中 Ceph 的 OSD 元数据中显示的内容。这通常是节点的短主机名。
仅当您想将 Ceph 统计信息与主机统计信息关联时才需要这样做,但您可能会发现在所有情况下都这样做很有用,以防您将来想要进行关联。
4.3 示例配置
此示例显示了在名为 senta04 的服务器上运行 ceph-mgr 和 node_exporter 的单节点配置。请注意,这需要为每个node_exporter目标单独添加适当的实例标签。
这只是一个例子:还有其他方法可以配置 prometheus 抓取目标和标签重写规则。
4.3.1 PROMETHEUS.YML
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'node'
file_sd_configs:
- files:
- node_targets.yml
- job_name: 'ceph'
honor_labels: true
file_sd_configs:
- files:
- ceph_targets.yml4.3.2 CEPH_TARGETS.YML
[
{
"targets": [ "senta04.mydomain.com:9283" ],
"labels": {}
}
]4.3.3 NODE_TARGETS.YML
[
{
"targets": [ "senta04.mydomain.com:9100" ],
"labels": {
"instance": "senta04"
}
}
]5. 注释
Counters和gauges输出;目前没有histograms和长期平均线。Ceph 的二维histograms 可能会简化为两个单独的一维histograms ,并且可以将长期运行平均值导出为 Prometheus 的摘要类型。
与许多 Prometheus 导出器一样,时间戳是由服务器的抓取时间建立的(Prometheus 期望它同步轮询实际的计数器进程)。可以在统计报告中提供时间戳,但 Prometheus 团队强烈建议不要这样做。这意味着时间戳将延迟不可预测的数量;目前尚不清楚这是否会出现问题,但值得了解。
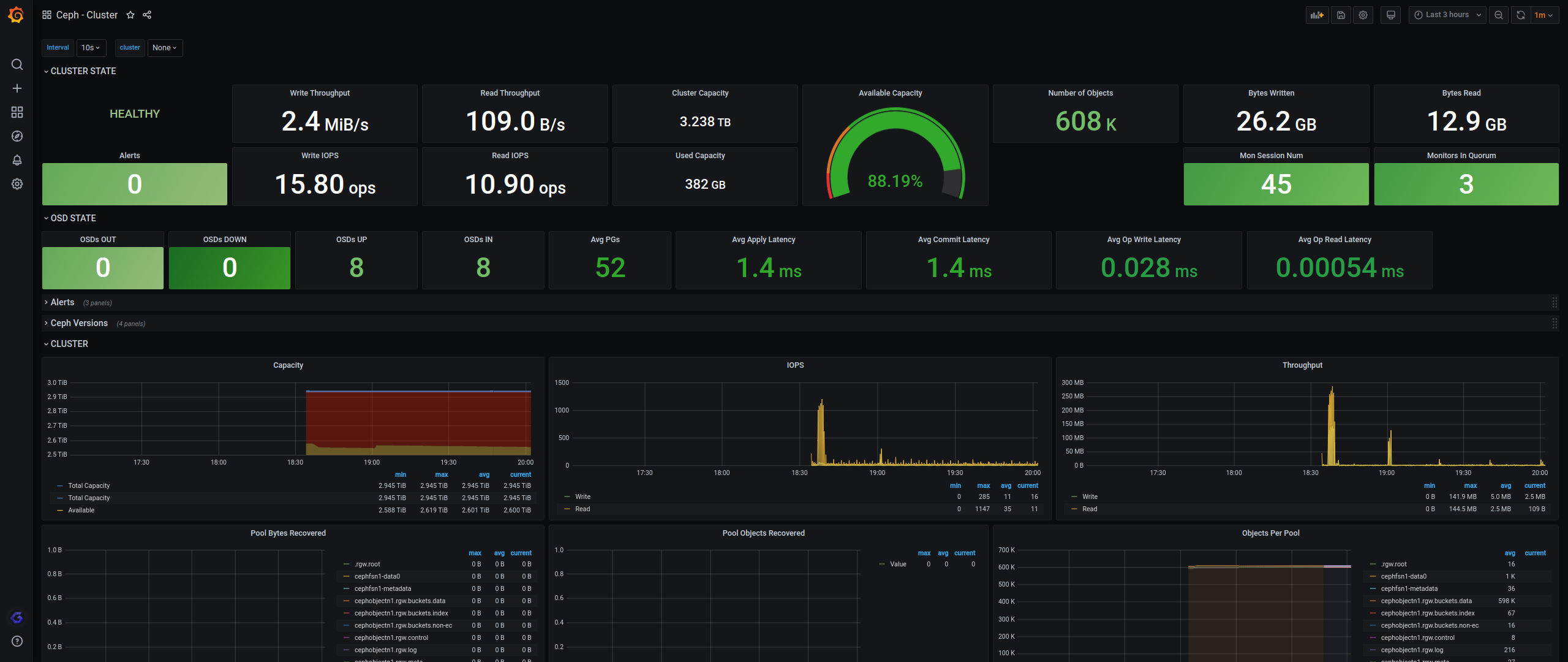
6. Grafana模板
参考:https://grafana.com/grafana/dashboards/2842

 浙公网安备 33010602011771号
浙公网安备 33010602011771号