
NoSQL 企业级应用 MongoDB 集群技术介绍
1. 单机介绍
2. 副本集介绍
在Mongodb3.0中副本集成员最多支持50个,也就是说副本集最大支持50个节点。
副本集每个节点数据支持32TB,副本集每个实例建议数据不要超过4TB,数据量大备份恢复时间会很长。
-
数据冗余
-
备份
-
镜像
-
读写分离(不可靠?)
通过客户端在连接时指定或者在主库指定slaveOk,由Secondary来分担读的压力,Primary只承担写操作。对于Replica Set中的Secondary节点默认是不可读的。
- 高可用
官方推荐MongoDB副本节点最少为3台,建议副本集成员为奇数,最多12个副本节点,最多7个节点参与选举。限制副本节点的数量,主要是因为一个集群中过多的副本节点,增加了复制的成本,反而拖累了集群的整体性能。太多的副本节点参与选举,也会增加选举的时间。而官方建议奇数的节点,是为了避免脑裂的发生。
架构
- 一主 + 一从 + 仲裁(即2副本 + 一个仲裁,在生产环境中此架构运用在分片集群中可以节省大量存储资源)
- 一主 + 二从 + 读写分离?
3. 分片介绍
-
海量数据
-
分散存储(解决磁盘空间不足问题)
-
高性能(提高写性能、大量数据放内存提高性能)
Sharding cluster是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建。sharding分片很好的解决了单台服务器磁盘空间、内存、cpu等硬件资源的限制问题,把数据水平拆分出去,降低单节点的访问压力。每个分片都是一个独立的数据库,所有的分片组合起来构成一个逻辑上的完整的数据库。因此,分片机制降低了每个分片的数据操作量及需要存储的数据量,达到多台服务器来应对不断增加的负载和数据的效果。
3.1 角色
- 分片服务器(Shard Server)
mongod实例,用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组成一个 relica set 承担,防止主机单点故障。这是一个独立普通的mongod进程,保存数据信息。可以是一个副本集也可以是单独的一台服务器。
- 配置服务器(Config Server)
mongod实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。这是一个独立的mongod进程,保存集群和分片的元数据,即各分片包含了哪些数据的信息。最先开始建立,启用日志功能。像启动普通的 mongod 一样启动配置服务器,指定configsvr 选项。不需要太多的空间和资源,配置服务器的 1KB 空间相当于真实数据的 200MB。保存的只是数据的分布表。
- 路由服务器(Route Server)
mongos实例,前端路由,客户端由此接入,且让整个集群看上去像单一数据库,对于前端应用,起到一个路由的功能,供程序连接。本身不保存数据,在启动时从配置服务器加载集群信息,开启 mongos 进程需要知道配置服务器的地址,指定configdb选项。
3.2 片键的意义
MongoDB中数据的分片是以集合为基本单位的,集合中的数据通过片键(Shard key)被分成多部分。其实片键就是在集合中选一个键,用该键的值作为数据拆分的依据。一个好的片键对分片至关重要。片键必须是一个索引,通过 sh.shardCollection 会自动创建索引。一个自增的片键对写入和数据均匀分布就不是很好, 因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片,但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos 会对结果进行归并排序。对集合进行分片时,你需要选择一个片键,片键是每条记录都必须包含的,且建立了索引的单个字段或复合字段,MongoDB按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。为了按照片键划分数据块,MongoDB使用基于范围的分片方式或者基于哈希的分片方式。
注意:
- 分片键是不可变。
- 分片键必须有索引。
- 分片键大小限制512bytes。
- 分片键用于路由查询。
- MongoDB不接受已进行collection级分片的collection上插入无分片
- 键的文档(也不支持空值插入)
3.3 合理的架构下需要多少个分片?
3.3.1 分片大小
分片的基本标准:
- 关于数据:数据量不超过3TB,尽可能保持在2TB一个片
- 关于索引:常用索引必须容纳进内存
存储限制
我们通常分片会使用默认的chunk大小为64M,如果我们的分片key (片键)values值是512字节,分片节点支持最大32768个也就是最大支持数据量为32768TB。一个片键大小不能超过512字节。
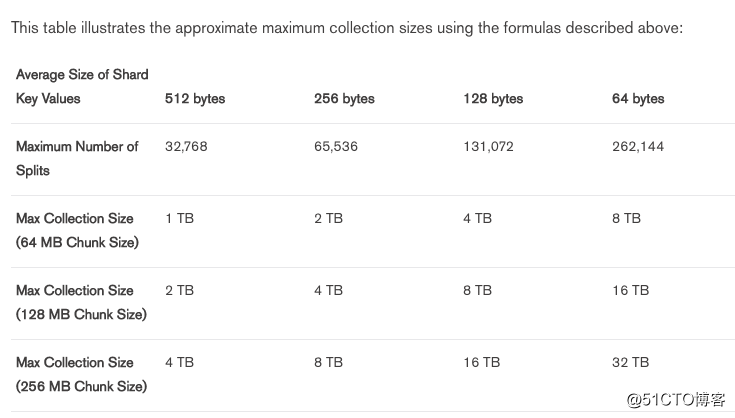
3.3.2 分片数量
根据存储总量,单服务器可挂载量,以及并发数相关指标计算。
3.4 硬件配置
对于读密集型应用,规划好服务器大小以保证在内存中能支撑整个工作集并且进行复制以得到更高的可用性。如果你服务器的内存(RAM)不能够保证在内存中容纳工作集,进行分片以从多个复本集群中整合内存(RAM)。使用与部署相同的服务器硬件创建一个概念验证系统。通过这个方法,你可以在你的概念验证系统中配置和测试一个服务器。接着,你可以根据需要,在扩展一个复制集或者增加一个分片进行拓展时,直接将其放入部署系统中。
4. MongoDB备份与恢复
4.1 mongoexport/mongoimport
- 导入/导出的是JSON格式。
- JSON可读性强但体积较大。
- 当无法使用BSON进行跨版本的数据迁移的时候,使用JSON格式是一个可选项。
- JSON虽然具有较好的跨版本通用性,但其只保留了数据部分,不保留索引,账户等其他基础信息。使用时应该注意。
4.2 mongodump/mongorestore
- 导入/导出的是BSON格式。
- BSON则是二进制文件,体积小但对人类几乎没有可读性。
- 在一些mongodb版本之间,BSON格式可能会随版本不同而有所不同。
- 所以不同版本之间使用可能不会成功,具体要看版本之间的兼容性。
- 跨版本并不推荐,实在要做请先检查文档看两个版本是否兼容(大部分时候是的)。
4.3 只针对replica或master/slave,满足这些准则MongoDB就可以进行point-in-time恢复操作
-
任意两次数据备份的时间间隔(第一次备份开始到第二次备份结束)不能超过oplog时间窗口覆盖范围。
-
在上次数据备份的基础上,在oplog时间窗口没有滑出上次备份结束的时间点前进行完整的oplog备份。
请充分考虑oplog备份需要的时间,权衡服务器空间情况确定oplog备份间隔。
实际应用中的注意事项
-
考虑到oplog时间窗口是个变化值,请关注oplog时间窗口的具体时间。
-
在靠近oplog时间窗口滑动出有效时间之前必须要有足够的时间dump出需要的oplog.rs,请预留足够的时间,不要顶满时间窗口再备份。
-
当灾难发生时,第一件事情就是要停止数据库的写入操作,以往oplog滑出时间窗口。
特别是像remove({})操作,瞬间就会插入大量d记录从而导致oplog迅速滑出时间窗口。
4.4 分片集群的备份注意事项
备份什么?
- configserver
- 每一个shard节点
备份需要注意什么?
- 元数据和真实数据要有对等性(blancer迁移的问题,会造成config和shard备份不一致)
- 不同部分备份结束时间点不一样,恢复出来的数据就是有问题的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号