
Alertmanager高可用简介
参考:
https://www.prometheus.wang/ha/alertmanager-high-availability.html
为了提升Promthues的服务可用性,通常用户会部署两个或者两个以上的Promthus Server,它们具有完全相同的配置包括Job配置,以及告警配置等。当某一个Prometheus Server发生故障后可以确保Promthues持续可用。
同时基于Alertmanager的告警分组机制即使不同的Prometheus Sever分别发送相同的告警给Alertmanager,Alertmanager也可以自动将这些告警合并为一个通知向receiver发送。
Alertmanager特性:
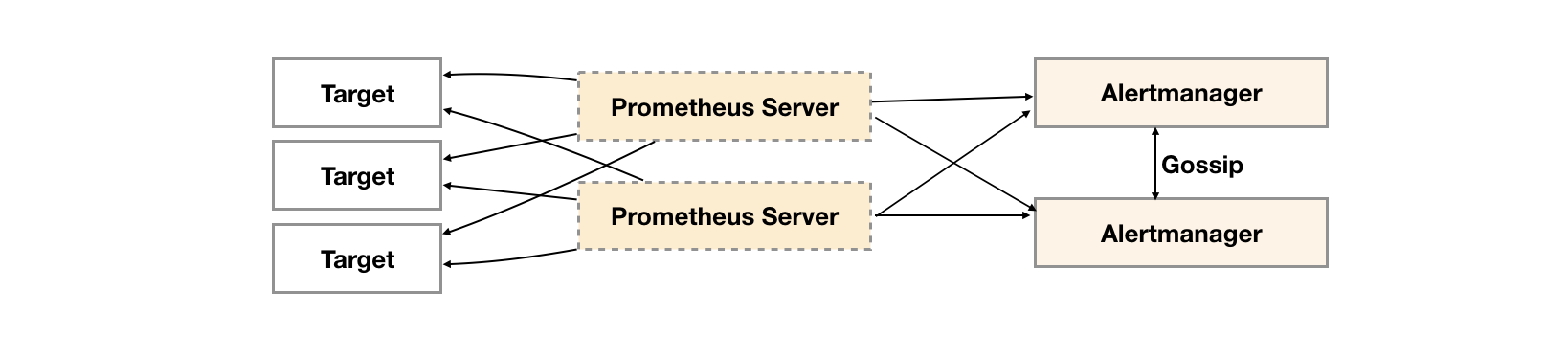
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
Gossip协议
Gossip是分布式系统中被广泛使用的协议,用于实现分布式节点之间的信息交换和状态同步。Gossip协议同步状态类似于流言或者病毒的传播,如下所示:
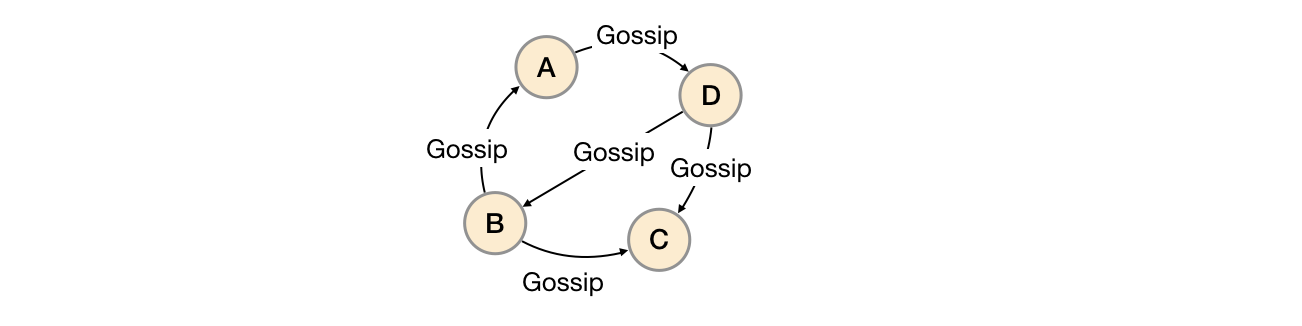
一般来说Gossip有两种实现方式分别为Push-based和Pull-based。在Push-based当集群中某一节点A完成一个工作后,随机的从其它节点B并向其发送相应的消息,节点B接收到消息后在重复完成相同的工作,直到传播到集群中的所有节点。而Pull-based的实现中节点A会随机的向节点B发起询问是否有新的状态需要同步,如果有则返回。
在简单了解了Gossip协议之后,我们来看Alertmanager是如何基于Gossip协议实现集群高可用的。如下所示,当Alertmanager接收到来自Prometheus的告警消息后,会按照以下流程对告警进行处理:
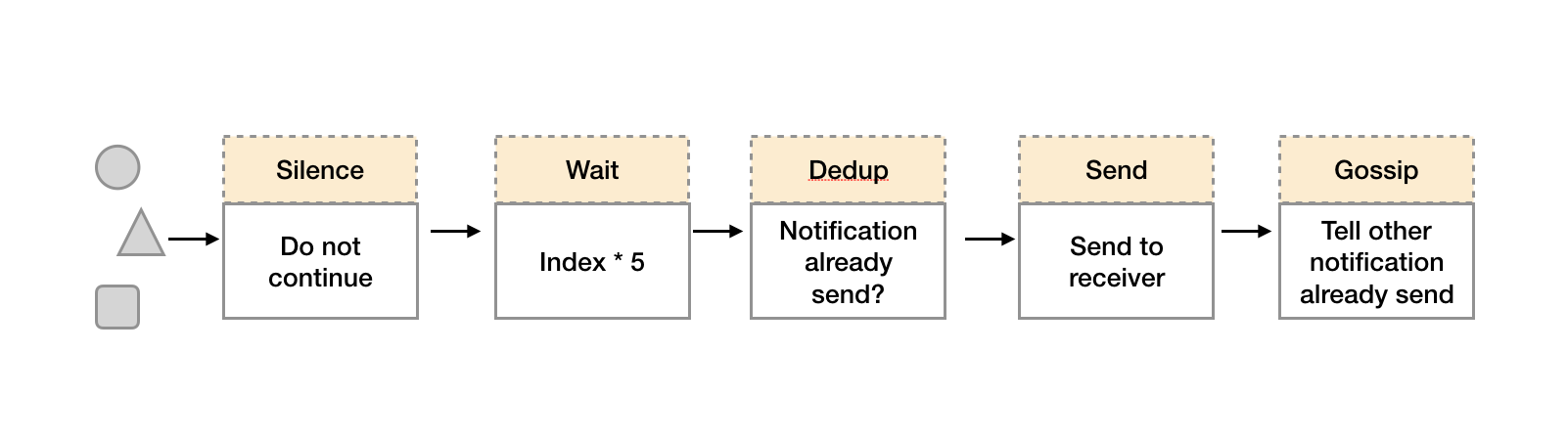
1.在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知。
2.在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间。
3.当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知。
4.告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。
因此如下所示,Gossip机制的关键在于两点:
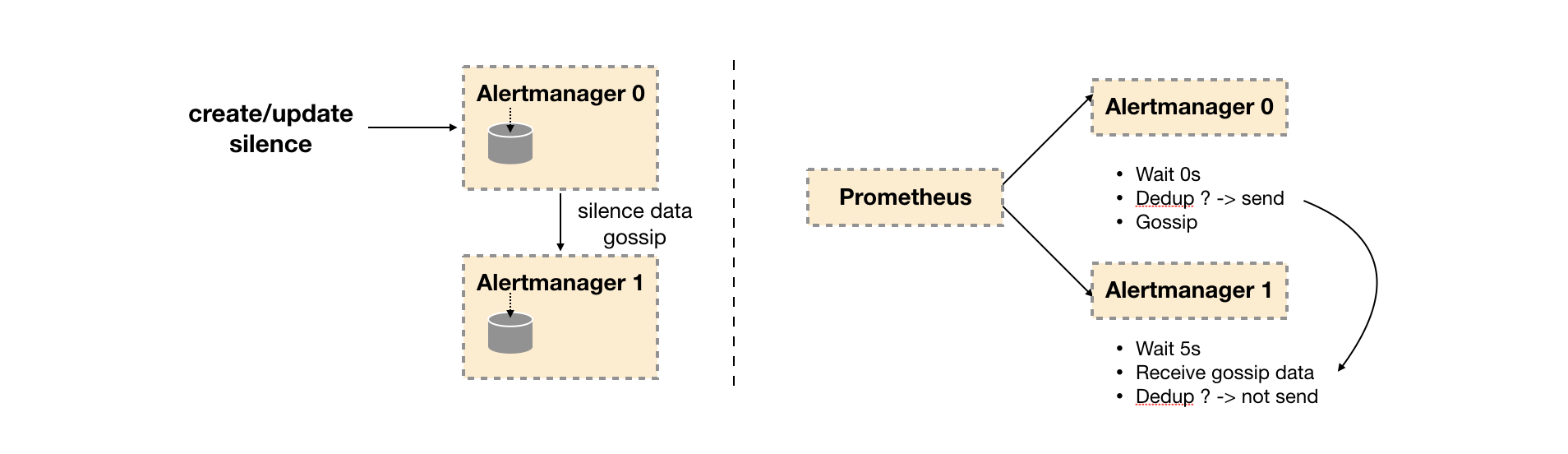
- Silence设置同步:Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态,当有新的Silence产生时使用Push-based方式在集群中传播Gossip信息。
- 通知发送状态同步:告警通知发送完成后,基于Push-based同步告警发送状态。Wait阶段可以确保集群状态一致。
Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP系统,即可用性和分区容错性。同时对于Prometheus Server而言保持了配置了简单性,Promthues Server之间不需要任何的状态同步。
集群配置
为了能够让Alertmanager节点之间进行通讯,需要在Alertmanager启动时设置相应的参数。其中主要的参数包括:
- --cluster.listen-address string: 当前实例集群服务监听地址
- --cluster.peer value: 初始化时关联的其它实例的集群服务地址
多实例Prometheus与Alertmanager集群
由于Gossip机制的实现,在Promthues和Alertmanager实例之间不要使用任何的负载均衡,需要确保Promthues将告警发送到所有的Alertmanager实例中:
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
- 127.0.0.1:9094
- 127.0.0.1:9095
创建Promthues集群配置文件/etc/prometheus/prometheus-ha.yml,完整内容如下:
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
rule_files:
- /etc/prometheus/rules/*.rules
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
- 127.0.0.1:9094
- 127.0.0.1:9095
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号