
【K8s概念】Jobs
参考:https://kubernetes.io/zh/docs/concepts/workloads/controllers/job/
Job 会创建一个或者多个 Pods,并将继续重试 Pods 的执行,直到指定数量的 Pods 成功终止。 随着 Pods 成功结束,Job 跟踪记录成功完成的 Pods 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pods。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
一种简单的使用场景下,你会创建一个 Job 对象以便以一种可靠的方式运行某 Pod 直到完成。 当第一个 Pod 失败或者被删除(比如因为节点硬件失效或者重启)时,Job 对象会启动一个新的 Pod。
你也可以使用 Job 以并行的方式运行多个 Pod。
运行示例 Job
下面是一个 Job 配置示例。它负责计算 π 到小数点后 2000 位,并将结果打印出来。 此计算大约需要 10 秒钟完成。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
操作命令:
kubectl describe jobs/pi
pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath='{.items[*].metadata.name}')
echo $pods
kubectl logs $pods
编写 Job 规约
Job 中 Pod 的 RestartPolicy 只能设置为 Never 或 OnFailure 之一。
Job 的并行执行
适合以 Job 形式来运行的任务主要有三种:
- 非并行 Job:
- 通常只启动一个 Pod,除非该 Pod 失败。
- 当 Pod 成功终止时,立即视 Job 为完成状态。
- 具有 确定完成计数 的并行 Job:
- .spec.completions 字段设置为非 0 的正数值。
- Job 用来代表整个任务,当成功的 Pod 个数达到 .spec.completions 时,Job 被视为完成。
- 当使用 .spec.completionMode="Indexed" 时,每个 Pod 都会获得一个不同的 索引值,介于 0 和 .spec.completions-1 之间。
- 带 工作队列 的并行 Job:
- 不设置 spec.completions,默认值为 .spec.parallelism。
- 多个 Pod 之间必须相互协调,或者借助外部服务确定每个 Pod 要处理哪个工作条目。 例如,任一 Pod 都可以从工作队列中取走最多 N 个工作条目。
- 每个 Pod 都可以独立确定是否其它 Pod 都已完成,进而确定 Job 是否完成。
- 当 Job 中 任何 Pod 成功终止,不再创建新 Pod。
- 一旦至少 1 个 Pod 成功完成,并且所有 Pod 都已终止,即可宣告 Job 成功完成。
- 一旦任何 Pod 成功退出,任何其它 Pod 都不应再对此任务执行任何操作或生成任何输出。 所有 Pod 都应启动退出过程。
对于 非并行 的 Job,你可以不设置 spec.completions 和 spec.parallelism。 这两个属性都不设置时,均取默认值 1。
对于 确定完成计数 类型的 Job,你应该设置 .spec.completions 为所需要的完成个数。 你可以设置 .spec.parallelism,也可以不设置。其默认值为 1。
对于一个 工作队列 Job,你不可以设置 .spec.completions,但要将.spec.parallelism 设置为一个非负整数。
控制并行性
并行性请求(.spec.parallelism)可以设置为任何非负整数。 如果未设置,则默认为 1。 如果设置为 0,则 Job 相当于启动之后便被暂停,直到此值被增加。
实际并行性(在任意时刻运行状态的 Pods 个数)可能比并行性请求略大或略小, 原因如下:
对于 确定完成计数 Job,实际上并行执行的 Pods 个数不会超出剩余的完成数。 如果 .spec.parallelism 值较高,会被忽略。
对于 工作队列 Job,有任何 Job 成功结束之后,不会有新的 Pod 启动。 不过,剩下的 Pods 允许执行完毕。
如果 Job 控制器 没有来得及作出响应,或者
如果 Job 控制器因为任何原因(例如,缺少 ResourceQuota 或者没有权限)无法创建 Pods。 Pods 个数可能比请求的数目小。
Job 控制器可能会因为之前同一 Job 中 Pod 失效次数过多而压制新 Pod 的创建。
当 Pod 处于体面终止进程中,需要一定时间才能停止。
处理 Pod 和容器失效
Pod 中的容器可能因为多种不同原因失效,例如因为其中的进程退出时返回值非零, 或者容器因为超出内存约束而被杀死等等。 如果发生这类事件,并且 .spec.template.spec.restartPolicy = "OnFailure", Pod 则继续留在当前节点,但容器会被重新运行。 因此,你的程序需要能够处理在本地被重启的情况,或者要设置 .spec.template.spec.restartPolicy = "Never"。 关于 restartPolicy 的更多信息,可参阅 Pod 生命周期。
整个 Pod 也可能会失败,且原因各不相同。 例如,当 Pod 启动时,节点失效(被升级、被重启、被删除等)或者其中的容器失败而 .spec.template.spec.restartPolicy = "Never"。 当 Pod 失败时,Job 控制器会启动一个新的 Pod。 这意味着,你的应用需要处理在一个新 Pod 中被重启的情况。 尤其是应用需要处理之前运行所产生的临时文件、锁、不完整的输出等问题。
注意,即使你将 .spec.parallelism 设置为 1,且将 .spec.completions 设置为 1,并且 .spec.template.spec.restartPolicy 设置为 "Never",同一程序仍然有可能被启动两次。
如果你确实将 .spec.parallelism 和 .spec.completions 都设置为比 1 大的值, 那就有可能同时出现多个 Pod 运行的情况。 为此,你的 Pod 也必须能够处理并发性问题。
Pod 回退失效策略
在有些情形下,你可能希望 Job 在经历若干次重试之后直接进入失败状态,因为这很 可能意味着遇到了配置错误。 为了实现这点,可以将 .spec.backoffLimit 设置为视 Job 为失败之前的重试次数。 失效回退的限制值默认为 6。 与 Job 相关的失效的 Pod 会被 Job 控制器重建,回退重试时间将会按指数增长 (从 10 秒、20 秒到 40 秒)最多至 6 分钟。 当 Job 的 Pod 被删除时,或者 Pod 成功时没有其它 Pod 处于失败状态,失效回退的次数也会被重置(为 0)。
说明: 如果你的 Job 的 restartPolicy 被设置为 "OnFailure",就要注意运行该 Job 的容器 会在 Job 到达失效回退次数上限时自动被终止。 这会使得调试 Job 中可执行文件的工作变得非常棘手。 我们建议在调试 Job 时将 restartPolicy 设置为 "Never", 或者使用日志系统来确保失效 Jobs 的输出不会意外遗失。
Job 终止与清理
Job 完成时不会再创建新的 Pod,不过已有的 Pod 也不会被删除。 保留这些 Pod 使得你可以查看已完成的 Pod 的日志输出,以便检查错误、警告 或者其它诊断性输出。 Job 完成时 Job 对象也一样被保留下来,这样你就可以查看它的状态。 在查看了 Job 状态之后删除老的 Job 的操作留给了用户自己。 你可以使用 kubectl 来删除 Job(例如,kubectl delete jobs/pi 或者 kubectl delete -f ./job.yaml)。 当使用 kubectl 来删除 Job 时,该 Job 所创建的 Pods 也会被删除。
默认情况下,Job 会持续运行,除非某个 Pod 失败(restartPolicy=Never) 或者某个容器出错退出(restartPolicy=OnFailure)。 这时,Job 基于前述的 spec.backoffLimit 来决定是否以及如何重试。 一旦重试次数到达 .spec.backoffLimit 所设的上限,Job 会被标记为失败, 其中运行的 Pods 都会被终止。
终止 Job 的另一种方式是设置一个活跃期限。 你可以为 Job 的 .spec.activeDeadlineSeconds 设置一个秒数值。 该值适用于 Job 的整个生命期,无论 Job 创建了多少个 Pod。 一旦 Job 运行时间达到 activeDeadlineSeconds 秒,其所有运行中的 Pod 都会被终止,并且 Job 的状态更新为 type: Failed 及 reason: DeadlineExceeded。
注意 Job 的 .spec.activeDeadlineSeconds 优先级高于其 .spec.backoffLimit 设置。 因此,如果一个 Job 正在重试一个或多个失效的 Pod,该 Job 一旦到达 activeDeadlineSeconds 所设的时限即不再部署额外的 Pod,即使其重试次数还未 达到 backoffLimit 所设的限制。
例如:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-timeout
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
注意 Job 规约和 Job 中的 Pod 模版规约 都有 activeDeadlineSeconds 字段。 请确保你在合适的层次设置正确的字段。
还要注意的是,restartPolicy 对应的是 Pod,而不是 Job 本身: 一旦 Job 状态变为 type: Failed,就不会再发生 Job 重启的动作。 换言之,由 .spec.activeDeadlineSeconds 和 .spec.backoffLimit 所触发的 Job 终结机制 都会导致 Job 永久性的失败,而这类状态都需要手工干预才能解决。
自动清理完成的 Job
完成的 Job 通常不需要留存在系统中。在系统中一直保留它们会给 API 服务器带来额外的压力。 如果 Job 由某种更高级别的控制器来管理,例如 CronJobs, 则 Job 可以被 CronJob 基于特定的根据容量裁定的清理策略清理掉。
已完成 Job 的 TTL 机制
FEATURE STATE: Kubernetes v1.12 [alpha]
自动清理已完成 Job (状态为 Complete 或 Failed)的另一种方式是使用由 TTL 控制器所提供 的 TTL 机制。 通过设置 Job 的 .spec.ttlSecondsAfterFinished 字段,可以让该控制器清理掉 已结束的资源。
TTL 控制器清理 Job 时,会级联式地删除 Job 对象。 换言之,它会删除所有依赖的对象,包括 Pod 及 Job 本身。 注意,当 Job 被删除时,系统会考虑其生命周期保障,例如其 Finalizers。
例如:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
Job pi-with-ttl 在结束 100 秒之后,可以成为被自动删除的对象。
如果该字段设置为 0,Job 在结束之后立即成为可被自动删除的对象。 如果该字段没有设置,Job 不会在结束之后被 TTL 控制器自动清除。
注意这种 TTL 机制仍然是一种 Alpha 状态的功能特性,需要配合 TTLAfterFinished 特性门控使用。有关详细信息,可参考 TTL 控制器的文档。
Job 模式
Job 对象可以用来支持多个 Pod 的可靠的并发执行。 Job 对象不是设计用来支持相互通信的并行进程的,后者一般在科学计算中应用较多。 Job 的确能够支持对一组相互独立而又有所关联的 工作条目 的并行处理。 这类工作条目可能是要发送的电子邮件、要渲染的视频帧、要编解码的文件、NoSQL 数据库中要扫描的主键范围等等。
在一个复杂系统中,可能存在多个不同的工作条目集合。这里我们仅考虑用户希望一起管理的 工作条目集合之一 — 批处理作业。
并行计算的模式有好多种,每种都有自己的强项和弱点。这里要权衡的因素有:
- 每个工作条目对应一个 Job 或者所有工作条目对应同一 Job 对象。 后者更适合处理大量工作条目的场景; 前者会给用户带来一些额外的负担,而且需要系统管理大量的 Job 对象。
- 创建与工作条目相等的 Pod 或者令每个 Pod 可以处理多个工作条目。 前者通常不需要对现有代码和容器做较大改动; 后者则更适合工作条目数量较大的场合,原因同上。
- 有几种技术都会用到工作队列。这意味着需要运行一个队列服务,并修改现有程序或容器 使之能够利用该工作队列。 与之比较,其他方案在修改现有容器化应用以适应需求方面可能更容易一些。
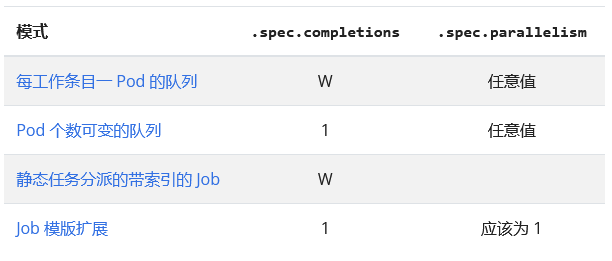
下面是对这些权衡的汇总,列 2 到 4 对应上面的权衡比较。 模式的名称对应了相关示例和更详细描述的链接。

当你使用 .spec.completions 来设置完成数时,Job 控制器所创建的每个 Pod 使用完全相同的 spec。 这意味着任务的所有 Pod 都有相同的命令行,都使用相同的镜像和数据卷,甚至连 环境变量都(几乎)相同。 这些模式是让每个 Pod 执行不同工作的几种不同形式。
下表显示的是每种模式下 .spec.parallelism 和 .spec.completions 所需要的设置。 其中,W 表示的是工作条目的个数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号