tidb损坏tikv节点怎么恢复集群
tikv节点宕机(机器再起不来),或者数据节点被rm -rf 掉了怎么办
正常情况下tikv节点down掉了。此时不要去执行store delete store_id 。数据一般可以正常访问,但是如果永久损坏的tikv节点。我们总想要把它移除。如何移除呢?
(移除kv节点过程中,如果kv节点健康在线,可以实现动态移除。如果kv节点不可用,可能导致访问数据的时候找不到region。【ERROR 9005 (HY000): Region is unavailable[try again later]】)
记移除一个损坏的tikv节点的过程:
1、动态移除kv节点
./pd-ctl -d -u http://192.168.100.73:4203 store delete 1
则该tikv节点状态会变为 "state_name": "Offline" 状态。
执行 operator show 会看到后台很多线程 transfer-peer 和 remove-peer 。

在此过程中可以先把故障节点的region 为leader 的转走先(理论上leader转义走了可以恢复正常,但实际并不一定):
scheduler add evict-leader-scheduler 1
调整作业调度的参数,加快region。(通过operator show可以看到调度进程。)
config set leader-schedule-limit 10
config set region-schedule-limit 10
config set replica-schedule-limit 20
如下图:我们会看到leader_count 和region_count 慢慢在减少。
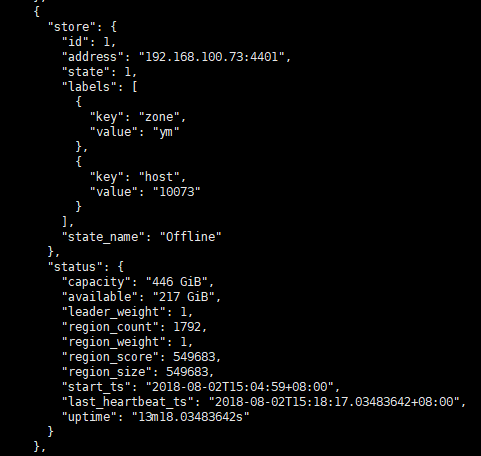
2、直至最后,有些region_count 一直不能自动transfer-peer 到别的kv节点。所以不能被 remove-peer。可以采取手动移除的办法:
(1):找出拥有损害kv节点的region。
pd-ctl -d -u http://192.168.100.73:4203 region check down-peer |grep -B 1 "start_key" |grep '"id":'|awk '{print "./pd-ctl -d -u http://192.168.100.73:4203 operator add remove-peer "$NF" 1"}'|sed s/,//g
(2):以上语句会生成如下类似的语句,执行之(1是store_id的id标志。)。
./pd-ctl -d -u http://192.168.100.73:4203 operator add remove-peer 4743 1
./pd-ctl -d -u http://192.168.100.73:4203 operator add remove-peer 171058 1
./pd-ctl -d -u http://192.168.100.73:4203 operator add remove-peer 11642 1
./pd-ctl -d -u http://192.168.100.73:4203 operator add remove-peer 4419 1
在此查看损坏的kv节点的信息:
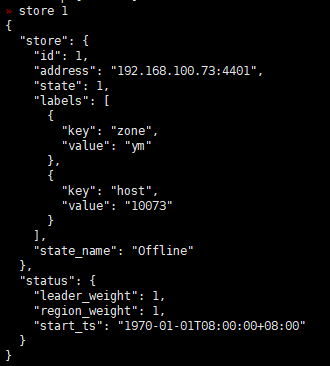
所有的region已经移除走,该kv节点已经不拥有任何region。理论上,此节点状态应该变为Tombstone。数据库恢复正常。但实际上可能会出现查询到坏的region节点。依然不正常。

怎么办呢?再次在pd工具下最新region。查看元数据信息,依然可以看到某些属于损坏kv的region。并且处于pendingpear状态。说明移除的region处于挂起状态,可能hung住:

这些损坏kv节点的pendingpears虽然不是leader 。但是依然影响tidb节点的数据操作,导致dml时候老报以下错误:
ERROR 9005 (HY000): Region is unavailable[try again later]
3、如何解决?启用kv节点修复数据工具:
停止所有kv节点,执行以下语句。命令将一些失败掉的机器从所有 Region 的 peers 列表中移除。这样,这些 Region 便可以在 TiKV 重启之后以剩下的健康的副本继续提供服务了。这个命令常常用于多个 TiKV store 损坏或被删除的情况。此命令会导致数据丢失,但因为在集群下我们有至少3个副本。所以基本上一个kv节点损坏并不会导致数据丢失,可放心执行。
tikv-ctl --db /path/to/tikv/db unsafe-recover remove-fail-stores 1
执行完以上语句后。在pd工具下查看store信息:
"state_name": "Tombstone" 表示下线成功的 TiKV 节点
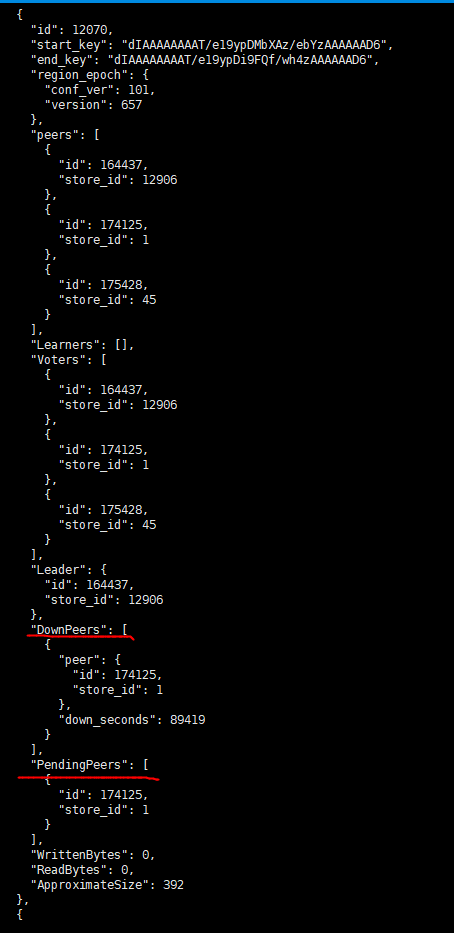
状态信息说明:
Up Stores:正常运行的 TiKV 节点数量
Disconnect Stores:短时间内通信异常的 TiKV 节点数量
LowSpace Stores:剩余可用空间小于 80% 的 TiKV 节点数量
Down Stores:停止工作的 TiKV 节点数量,如果大于 0,说明有节点不正常
Offline Stores:正在下线的 TiKV 节点数量(正在下线的 TiKV 节点还在提供服务)
Tombstone Stores:下线成功的 TiKV 节点数量
注:
如果集群不可用,紧急恢复集群,数据安全性不高。可以直接执行
tikv-ctl --db /path/to/tikv/db unsafe-recover remove-fail-stores 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号