P4017 最大食物链计数
题目描述
题目背景
你知道食物链吗?Delia 生物考试的时候,数食物链条数的题目全都错了,因为她总是重复数了几条或漏掉了几条。于是她来就来求助你,然而你也不会啊!写一个程序来帮帮她吧。
题目描述
给你一个食物网,你要求出这个食物网中最大食物链的数量。
(这里的“最大食物链”,指的是生物学意义上的食物链,即最左端是不会捕食其他生物的生产者,最右端是不会被其他生物捕食的消费者。)
Delia 非常急,所以你只有 11 秒的时间。
由于这个结果可能过大,你只需要输出总数模上 8011200280112002 的结果。
输入格式
第一行,两个正整数 n、mn、m,表示生物种类 nn 和吃与被吃的关系数 mm。
接下来 mm 行,每行两个正整数,表示被吃的生物A和吃A的生物B。
输出格式
一行一个整数,为最大食物链数量模上 8011200280112002 的结果。
输入输出样例
输入 #1复制
5 7 1 2 1 3 2 3 3 5 2 5 4 5 3 4输出 #1复制
5说明/提示
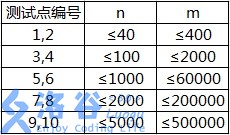
各测试点满足以下约定:
【补充说明】
数据中不会出现环,满足生物学的要求。(感谢 @AKEE )
拓扑排序算法求解
分析
题目最后说不会出现环——想到肯定要拓扑排序
用f[i]表示能到i的路径总数
- 首先对于初始入度为0的点u,其
f[u]值应该是1,可以假想有一条边指向了该点,即有一条路径可以到该点 - 对其他入度不为0的每个点
u,f[u]应该等于能到u点的所有点j的f[j]的总和- 对整个图拓扑排序,排序过程中对每个点
u,对于u指向的所有节点k,f[k] += f[u]
- 对整个图拓扑排序,排序过程中对每个点
代码
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<vector>
#include<queue>
using namespace std;
typedef long long LL;
const int N = 5010;
const int mod = 80112002;
int n,m;
vector<int> h[N]; // 存图
int chu[N], ru[N]; // 记录出度、入度
int f[N]; // f[i]表示到i有多少条路径
bool has_fa[N]; // 记录每个节点有没有父亲节点
LL res = 0;
//拓扑排序
void tor()
{
queue<int> q;
for(int i = 1; i <= n; i++)
{
if(!has_fa[i]) // 入度为0的点进入队列中,到该点的路径为1
{
q.push(i);
f[i] = 1;
}
}
while(q.size())
{
int t = q.front();
q.pop();
// 看t是不是食物链最低层节点
if(h[t].size() == 0)
{
res = (res + f[t]) % mod;
continue; // 它也没有指向的点,不continue也可以
}
// 遍历t所有的邻接点
for(int i = 0; i < h[t].size(); i++)
{
int j = h[t][i]; // 邻居点j
// 到j点的路径数 += 到t点的路径数
f[j] = (f[j] + f[t]) % mod;
ru[j]--; // 入度-1
if(ru[j] == 0)
{
q.push(j);
}
}
}
}
int main()
{
scanf("%d%d", &n, &m);
while(m --)
{
int a, b;
scanf("%d%d", &a, &b);
h[b].push_back(a); // b -> a; b吃a
has_fa[a] = true;
chu[b]++;
ru[a]++;
}
tor();
cout << res << endl;
return 0;
}
一开始用dfs做的,只能过前两个点,不过当数据量小的时候也是一种思路:
dfs(u)返回从u能到最后出度为0节点的路径数
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
typedef long long LL;
const int mod = 80112002;
const int N = 500010, M = 2*N;
int h[N], e[N], ne[N], idx = 0;
bool st[N];
bool has_fa[N];
int n, m;
void add(int a, int b)
{
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
// 从u能走路径数
int dfs(int u)
{
st[u] = true;
int t = 0;
for(int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if(!st[j])
{
if(h[j] == -1)
{
t = (t + 1) % mod;
}
else t = (t + dfs(j) ) % mod;
}
}
st[u] = false;
return t;
}
int main()
{
memset(h, -1, sizeof h);
scanf("%d%d", &n, &m);
while(m --)
{
int a, b;
scanf("%d%d", &a, &b);
add(b, a); // b -> a
has_fa[a] = true;
}
int res = 0;
for(int i = 1; i <= n; i++)
{
if(!has_fa[i]) res = (res + dfs(i)) % mod;
}
// for(int i = 1; i <= n; i++)
// {
// res = max(res, dfs(i)) ;
// }
cout << res % mod << endl;
return 0;
}
时间复杂度
参考文章
https://www.luogu.com.cn/blog/CJYblog/p4017-zui-tai-si-wu-lian-ji-shuo-ti-xie
题目分析:
首先 ,要知道这道题是 TopoTop**o 拓扑排序。不妨先从拓扑排序定义下手,分析题目的性质。经分析得:
食物链中的生物 —— 节点
生物之间的关系 —— 有向边
为了方便描述,我们将
不会捕食其他生物的 生产者 叫做 最佳生产者
不会被其他生物捕食的 消费者 叫做 最佳消费者
由于数据中不会出现环,所以 最大食物链 即 左端是 最佳生产者 ,右端是 最佳消费者 的路径
而 只要最左端是 最佳生产者 的路径(即最右端可以不是 最佳消费者 的最大食物链) 我们称之为 类食物链
既然 食物链中的生物 可以看成 节点,那么 最佳生产者 的入度一定为 00, 而 最佳消费者 的出度也为 00
思路引导
想要找到一条 最大食物链 ,那么这条路径的 起点 入度要为0,终点 出度要为0。 故:
既要记录入度,还要记录出度!
现在的问题转换成了,如何找到图中所有 左端点入度为0 且 右端点出度为0 的路径的数量
正解
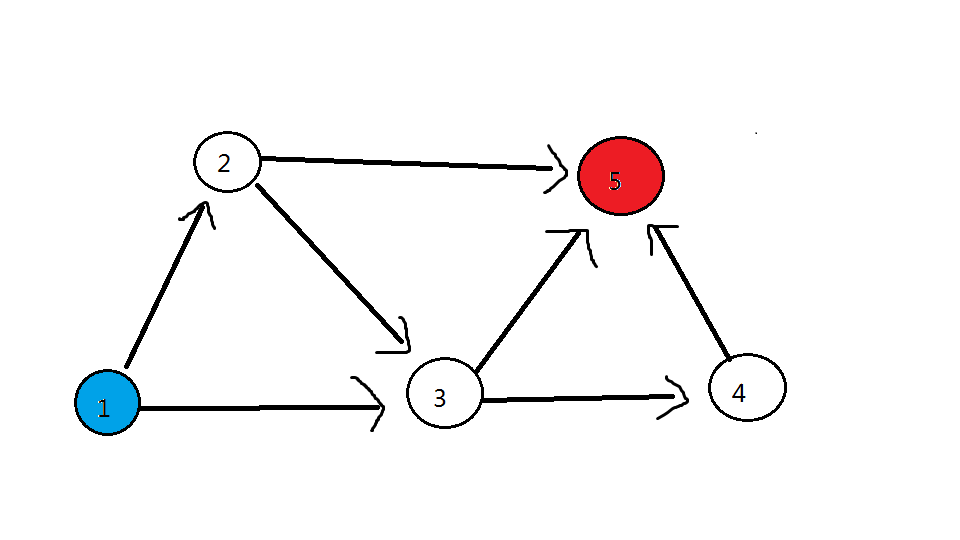
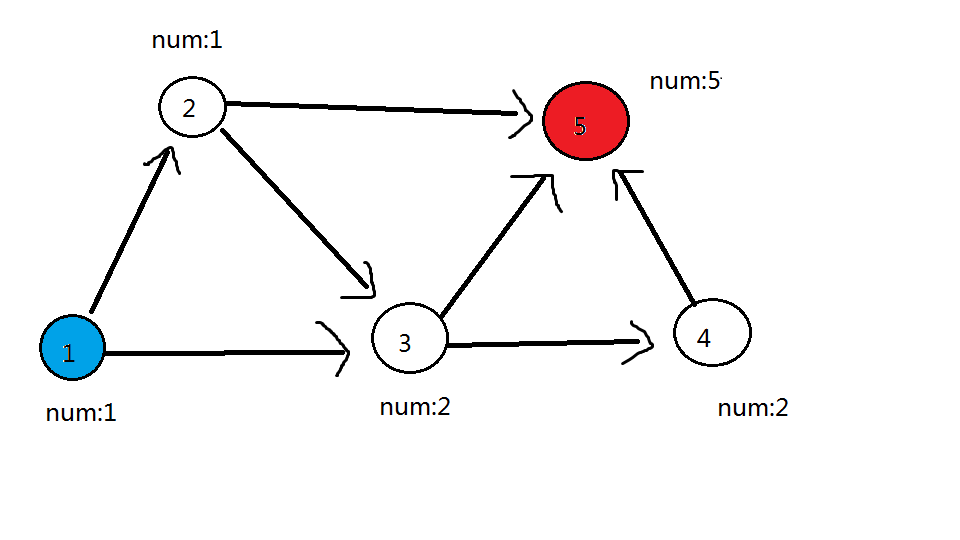
我们拿起笔,在草稿纸上画一个图进行推算。接下来将使用 样例 进行举例。
(将 最佳生产者 涂上 蓝色,最佳消费者 涂上 红色)
发现: 答案为 到所有 红色点 的路径条数的 总和
(这里的 路径条数总和 不是 连向它有几条边 ,而是以它结束的 最大食物链 数量的总和)
对于上图,55 号点的对应路径数量 取决于:以 到 55 号点的三个点( 22 号、33 号、44 号) 结尾的 类食物链 条数的总和。
而 以 22 号、33 号、44 号 结尾的 类食物链 取决于:以 可以到达 22 号、33号、44号点 的点 结尾的 类食物链 条数的总和。
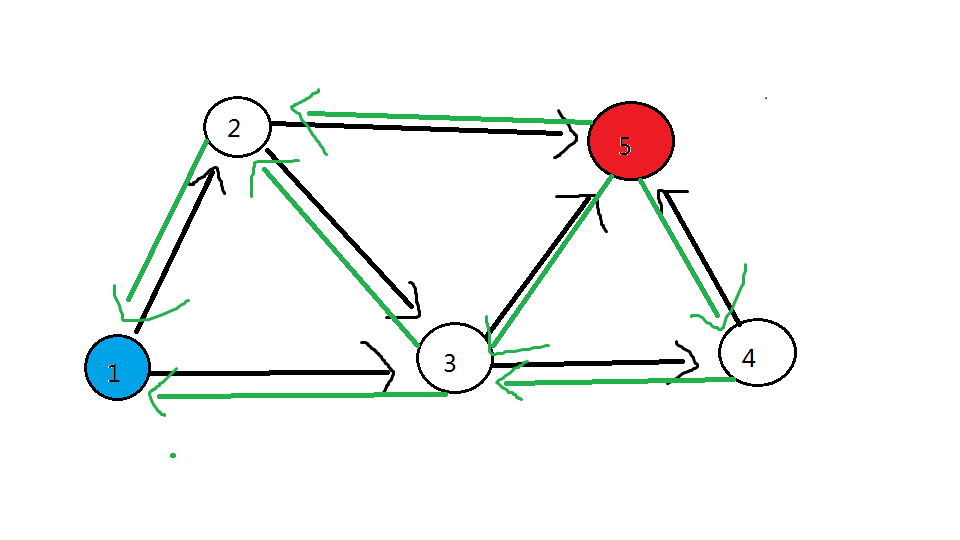
以此类推,显然对于 以 任一点 结尾的 类食物链 的数量,都取决于 蓝色点
各点数量对应关系在下图用绿色边标注
重点:
使用拓扑排序,由题意得知 TopoTop**o 排序第一轮被删掉的点 一定是 蓝色点(最佳生产者),而令 蓝色点 的答案为 11。
当第一轮删点时,将蓝色点可以到的点 的答案 都加上 蓝色点的 答案(即加 11)。
即:拓扑排序 需要删除的点的答案 都累加到 它可以到达的点 上面去
这样我们就将边的累加 转换到了 点之间的累加。
最后累加所有 红色点(最佳消费者) 的答案,输出即可。
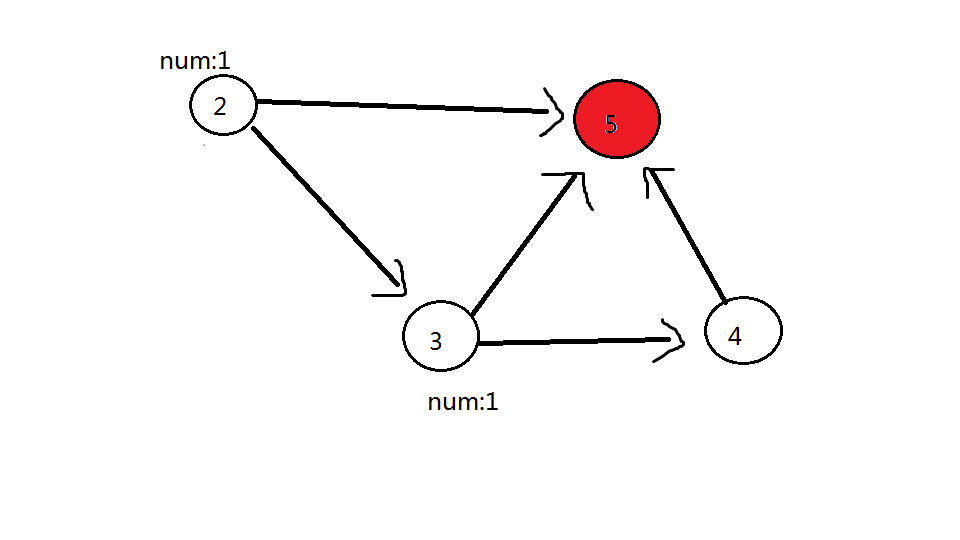
以第 $i$ 号点结束的 类食物链 数量 = 以 可到达 $i$ 号点 的点 结尾的 类食物链 数量的和以下是模拟操作过程:
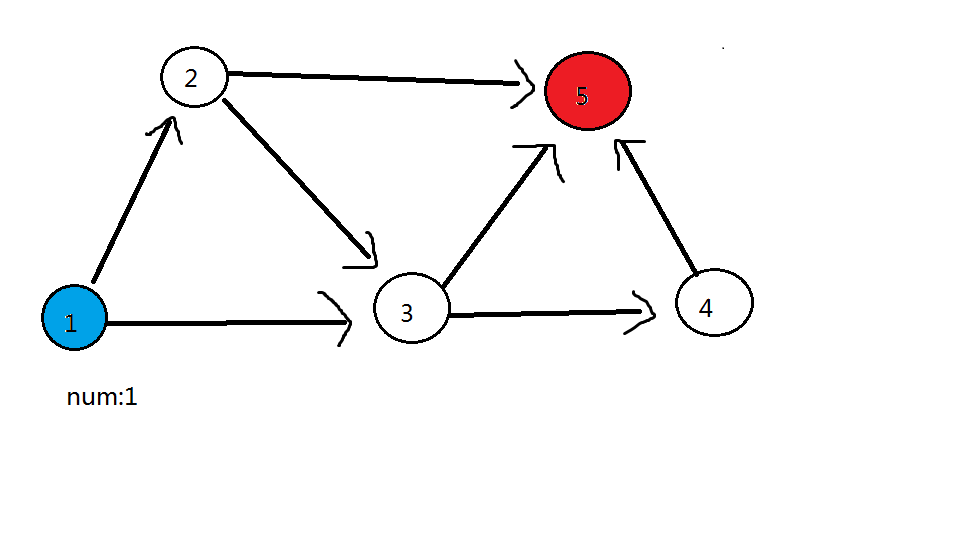
加载时间较慢,请稍等第一轮:删除 11 号蓝色点,11 号蓝色点可以到的点(22 号点、33 号点)都加 11
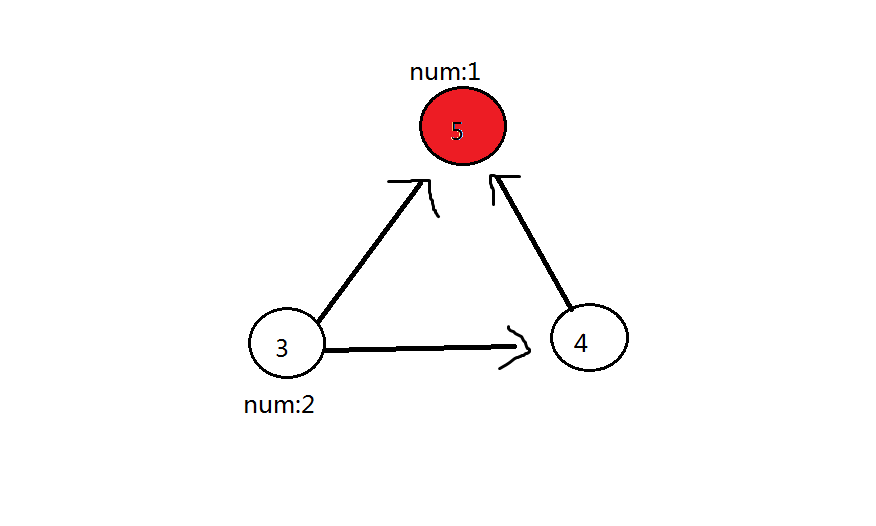
第二轮:删除 22 号点,22 号点可以到的点(33 号点、55 号红色点)都加 11。此时 33 号点答案为 22,55 号点答案为 11
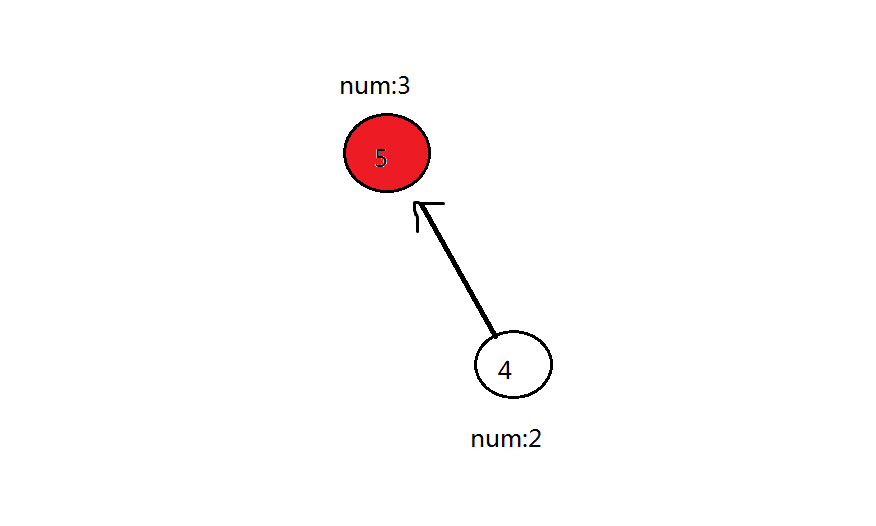
第三轮:删除 33 号点,33 号点可以到的点(44 号点、55 号红色点)都加 22。此时 55 号点答案为 33,44 号点答案为 22
第四轮:最后删除 44 号点,44 号点可以到的点(55 号红色点)加 22,此时 55 号点答案为 55
可见全图只有 55 号一个红色点,那么答案就是 55 号点的答案———— 55 了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号