
404 Note Found队-现场编程
组员职责分工
| 组员 | 职责 |
|---|---|
| 绪佩 | 组织分工、改进前端、后端、云化 |
| 庄卉 | 改进前端、后端 |
| 家伟 | 算法关键词识别、附加题实现 |
| 家灿 | 数据库 |
| 一好 | 算法随机数、算法审查 |
| 鸿杰 | 算法随机数、算法审查 |
| 政演 | 提供算法思路、附加题idea思路、博客撰写 |
| 凯琳 | 前端审查 |
| 丹丹 | 前端审查 |
| 青元 | 前端改进 |
| 宇恒 | 前端审查 |
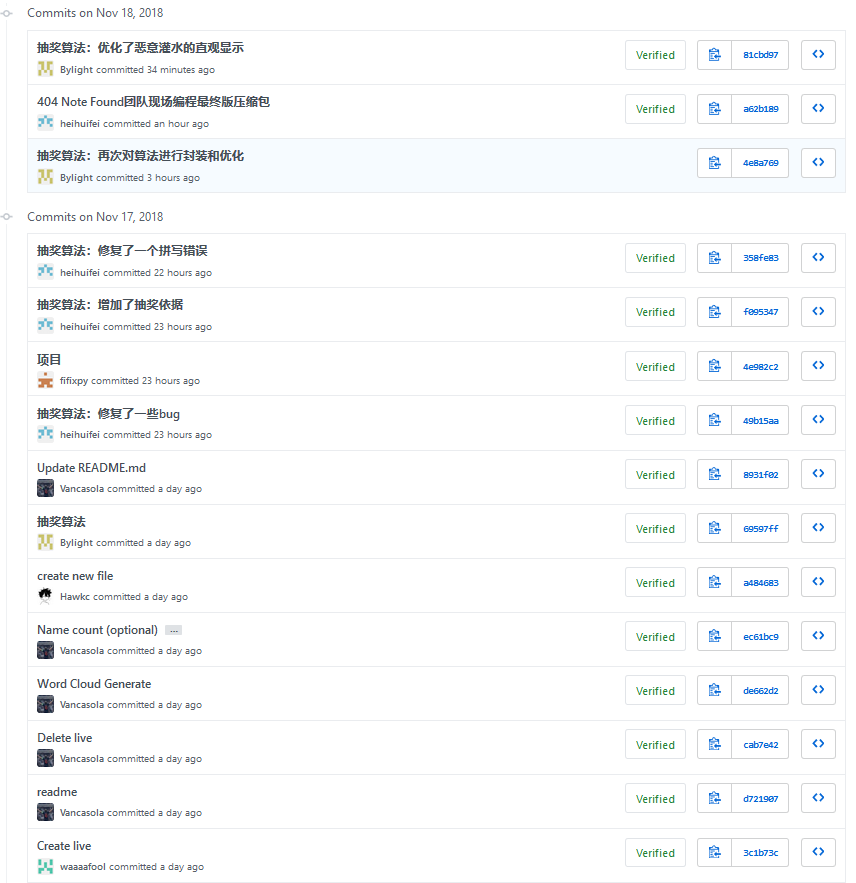
github 的提交日志截图
程序运行截图
运行结果
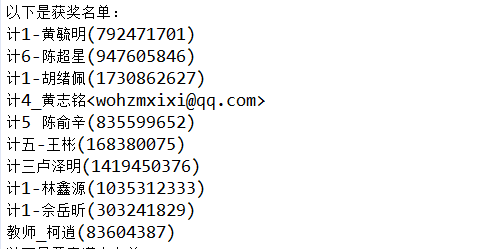
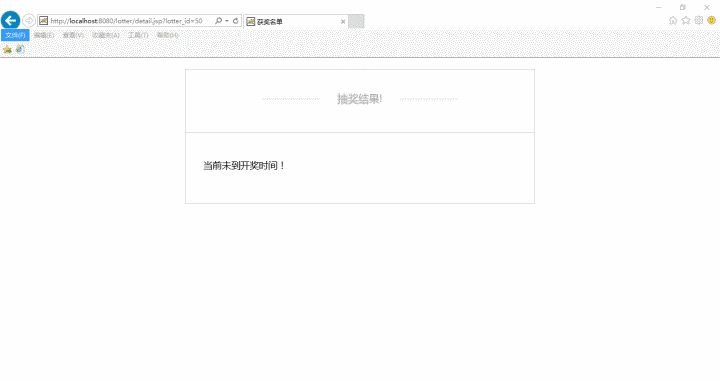
抽奖结果名单

程序运行环境
| 环境 | 名称 |
|---|---|
| 操作系统 | Windows10 |
| 编译器 | Eclipse javaee |
| 本地服务器 | Tomcat |
| 数据库 | MySQL |
| 可视化数据库工具 | Navicat |
GUI界面
进入界面

抽奖规则设定1
抽奖规则设定2
抽奖结果名单
错误提示
发布成功显示
基础功能实现
本算法具有以下模式:
- 不过滤模式:剔除机器,所有参与抽奖的人,都纳入开奖范围。
- 普通模式:筛除只参与抽奖而无发表任何原创言论的用户(抽奖机器人),鼓励大家积极参与有意义的发言。
- 深度模式:为了使发言更有意义,减少灌水,对以下用户的中奖概率进行降权处理:
- 只参与抽奖而无发表任何原创言论(抽奖机器人)
- 只参与抽奖且只发送表情(水军)
运行视频
视频链接:https://v.youku.com/v_show/id_XMzkyODA4NDY0OA==.html?spm=a2h0k.11417342.soresults.dtitle
随机算法:
LCG算法
我们的抽奖算法基于LCG算法,LCG(linear congruential generator)线性同余算法,是一个古老的产生随机数的算法。
本算法有以下优点:
- 计算速度快:抽奖时的算法时间复杂度是一个较大的问题,在微博开奖的时候,由于抽奖人数众多,(例如王思聪的抽奖微博,转发量、评论数、点赞数均达到了两千万,总数达到了六千万,输入量十分巨大)所以常常需要花费几十分钟的时间开奖,如此的算法性能是难以忍受的。对此,我们的算法基于LCG算法,利用其速度优势,减少开奖时间。
- 易于实现:算法易于理解,可以通过改变取余数来控制算法的空间复杂度与随机分布效果。且算法是线性的算法,和非线性的模型相比,具有较低的复杂度。
- 易于推广:本算法改变取余参数,对空间资源和随机准确率权衡,根据不同的设备资源和计算能力调优,具有很强的灵活性,易于使用推广。
本算法基于的LCG算法由以下参数组成:
| 参数 | m | a | c | X |
|---|---|---|---|---|
| 性质 | 模数 | 乘数 | 加数 | 随机数 |
| 作用 | 取模 | 移位 | 偏移 | 作为结果 |
LCG算法是如下的一个递推公式,每下一个随机数是当前随机数向左移动 log2 a 位,加上一个 c,最后对 m 取余,使随机数限制在 0 ~ m-1 内
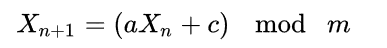
从该式可以看出,该算法由于构成简单,具有以下优点:
- 计算速度快
- 易于实现
- 易于写入硬件
以下是针对不同参数 lcg 产生随机数的效果图
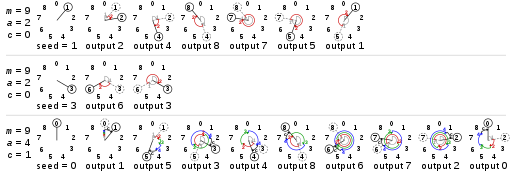
可以看出,针对不同的参数,lcg产生的效果差别很大
以下是针对不同环境下的参数选择
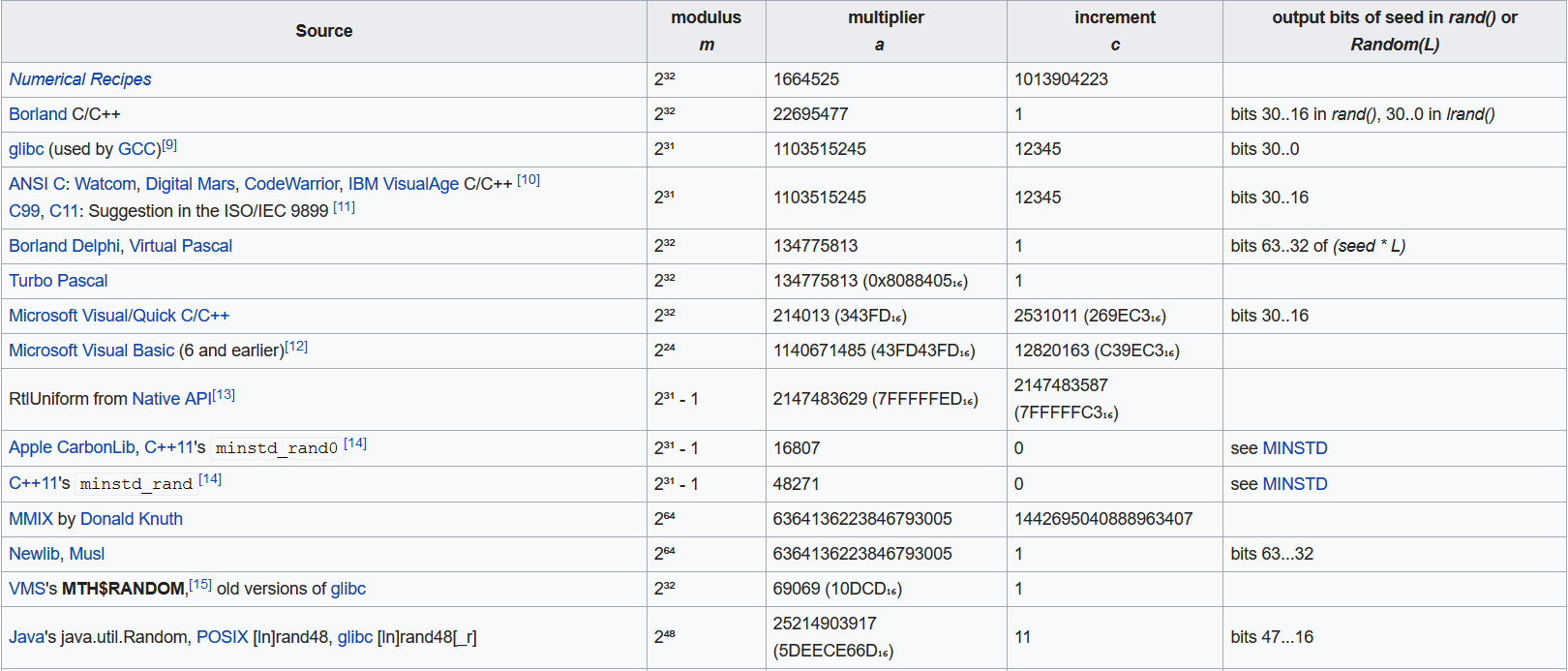
根据我们机器的情况,我们选择使用参数:
过滤(降权)算法
算法思路
抽奖算法对两种情况进行了处理:
无发言剔除:当用户只转发抽奖关键字,而没有相关发言时,直接剔出抽奖名单。
恶意刷屏:抽奖者可以自行定义一个抽奖阈值φ1,当发言数超过φ1时,对该用户进行中奖概率降权处理。
灌水剔除:抽奖者可以自行定义一个抽奖阈值φ2,发送的表情数超过阈值的时候,判定为灌水,剔出抽奖名单
for (Map.Entry<String, Integer> en : map.entrySet()) {
//System.out.println(en.getKey() + "=" + en.getValue());
x[i] = ( a * x[i-1] + b ) % m;
if (en.getValue() < 0) { //发言为空,剔出抽奖名单
i++;
continue;
} else if (en.getValue() > 0) { //恶意刷屏,降低权重
weight = en.getValue();
if (weight > 30) {
weight = 30;
}
x[i] = (int) (x[i] * ((double)(30 - weight) / 30.0));
}
map.put(en.getKey(), x[i]);
//System.out.println(en.getKey() + "=" + en.getValue());
i++;
}
红黑树
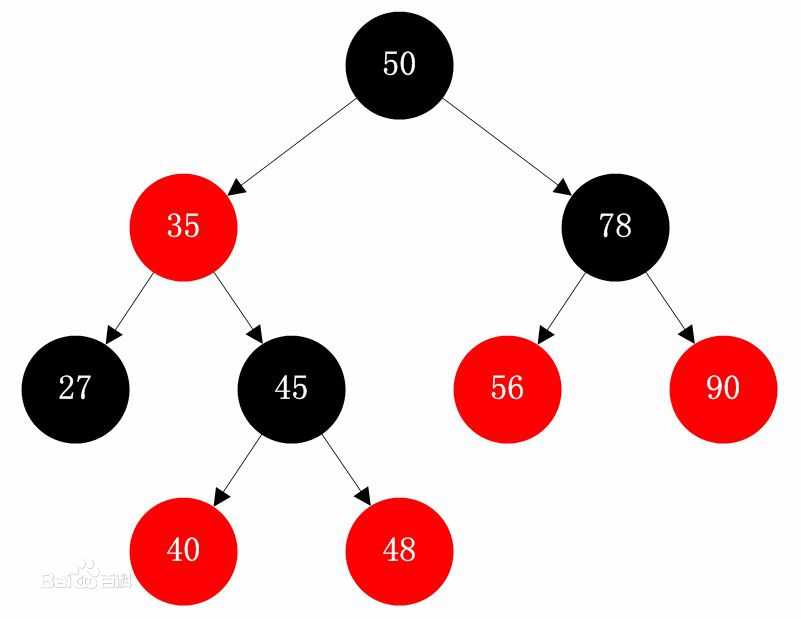
红黑树是一种自平衡的二叉查找树,是一种高效的查找树。
-
提供良好的效率:可在O(logN)时间内完成查找、增加、删除等操作,能保证在最坏情况下,基本的动态几何操作的时间均为O(lgn)。只要求部分地达到平衡要求,降低了对旋转的要求,任何不平衡都会在三次旋转之内解决,从而提高了效率。抽奖伏安法涉及大量增删改查操作,红黑树算法提供了良好的效率支撑。
-
提供性能下限保证:相比于BST,红黑树可以能确保树的最长路径不大于两倍的最短路径的长度,可见其查找效果的最低保证。最坏的情况下也可以保证O(logN)的复杂度,好于二叉查找树O(N)复杂度。在大数据量情况下,红黑树算法为抽奖算法提供良好的性能保证。
-
提供词频统计的高性能:红黑树的算法时间复杂度和AVL树相同,但统计性能更高。插入 AVL树和红黑树的速度取决于所插入的数据。在数据比较杂乱的情况,则红黑树的统计性能优于AVL树。在抽奖时时,数据分布较为杂乱,在此应用场景下,红黑树算法与抽奖器契合。
-
提供较小的资源开销:与基于哈希的算法相比,基于红黑树方法带来更小的资源开销,程序消耗内存较少。哈希的算法占用大量资源,需要维护大量的计数器,并且在哈希过程中消耗了大量的计算资源。抽奖系统器消耗的资源较少。
附加功能一
背景
现抽奖的人数也越来越多。例如:王思聪抽奖微博总数达到了六千万对每个抽奖账号还需要维护巨大的数据量。恶意灌水、转发的账号,或是机器人账号,将大大影响抽奖的性能。抽奖机器人大量的抽奖参与,也将给系统带来很大的影响。对此,我们设置了一个针对抽奖的恶意检测功能。可以针对灌水言论,设定一个阈值,可以对阈值进行调整。当发言数超过阈值时,报出该为恶意用户,可以列入黑名单。在之后的抽奖活动中,可以屏蔽黑名单中的用户,减少系统的资源消耗,同时保证公平性。该功能基于下文中基于sketch的数据处理功能,在较小的空间开销下,完成数据挖掘。
并且,该功能可以鼓励有意义的发言,减少恶意灌水等不良行为。
实现
如果除去关键字后发送内容为空判定为符合普通过滤规则,将除抽奖关键字外仅发送表情定义为恶意灌水,标记为num = 1,如果该id未出现过,存入map
private void handleMap(String talkContent) {
boolean flag = true;
int num = 0;
if (filterType != 1) {
talkContent = talkContent.replaceAll("#(.*)#", " ");
//talkContent.replaceAll("、", " ");
if (Pattern.matches("\\s*", talkContent)) { // 如果除去关键字后发送内容为空-->符合普通过滤规则
flag = false;
/*将除抽奖关键字外仅发送表情定义为恶意灌水,标记为num = 1*/
} else if (Pattern.matches("\\s*[\\[表情\\]]+\\s*", talkContent) && filterType == 3) {
//System.out.println(talkContent);
num = 1;
}
}
if (!map.containsKey(userID) && flag) { // 如果该id未出现过
map.put(userID, num); // 存入map
} else if (num > 0) {
num = (int) map.get(userID) + 1;
map.put(userID, num);
}
}
发言为空,剔出抽奖名单,恶意刷屏,降低权重,加入恶意灌水名单,因为文本中聊天样本数据过少,一次灌水即踢出名单,以下是文本数据大时考虑修改,少量刷屏仅降低权重
if (en.getValue() < 0) { //发言为空,剔出抽奖名单
i++;
continue;
} else if (en.getValue() > 0) { //恶意刷屏,降低权重
weight = en.getValue();
if (weight > 0) {
/*加入恶意灌水名单*/
//因为文本中聊天样本数据过少,一次灌水即踢出名单
if (!uselessName.contains(en.getKey())) {
uselessName.add(en.getKey());
x[i] = -1;
continue;
}
//以下是文本数据大时考虑修改,少量刷屏仅降低权重
if (weight > 30) {
weight = 30;
}
}
x[i] = (int) (x[i] * ((double)(30 - weight) / 30.0));
}
实现效果
此处仅仅对该功能进行测试,由于样本数据不足,设定的阈值也较小,将黑名单的内容输出到文件中可以显示如下内容:
附加功能二(迭代中)
我们将该系统实现在云端虚拟化设备上。用户可以在不同设备上调用该功能,便于产品的推广使用和推广。而且,人们常常忽略的是本地服务器的安全问题。本地服务器通常资源较少,安全机制不完善,一旦受到DDos攻击,功能将瘫痪。而在云端,有运营商提供良好的安全服务体系,大大提高安全性,保证系统能够正常运行。
我们做了以下部署工作:
-
将云端环境镜像与本地环境匹配正确
-
云端数据库进行同步
-
将项目文件压缩成wra形式传至云端
以上工作均正常操作完成
仍存在以下不足
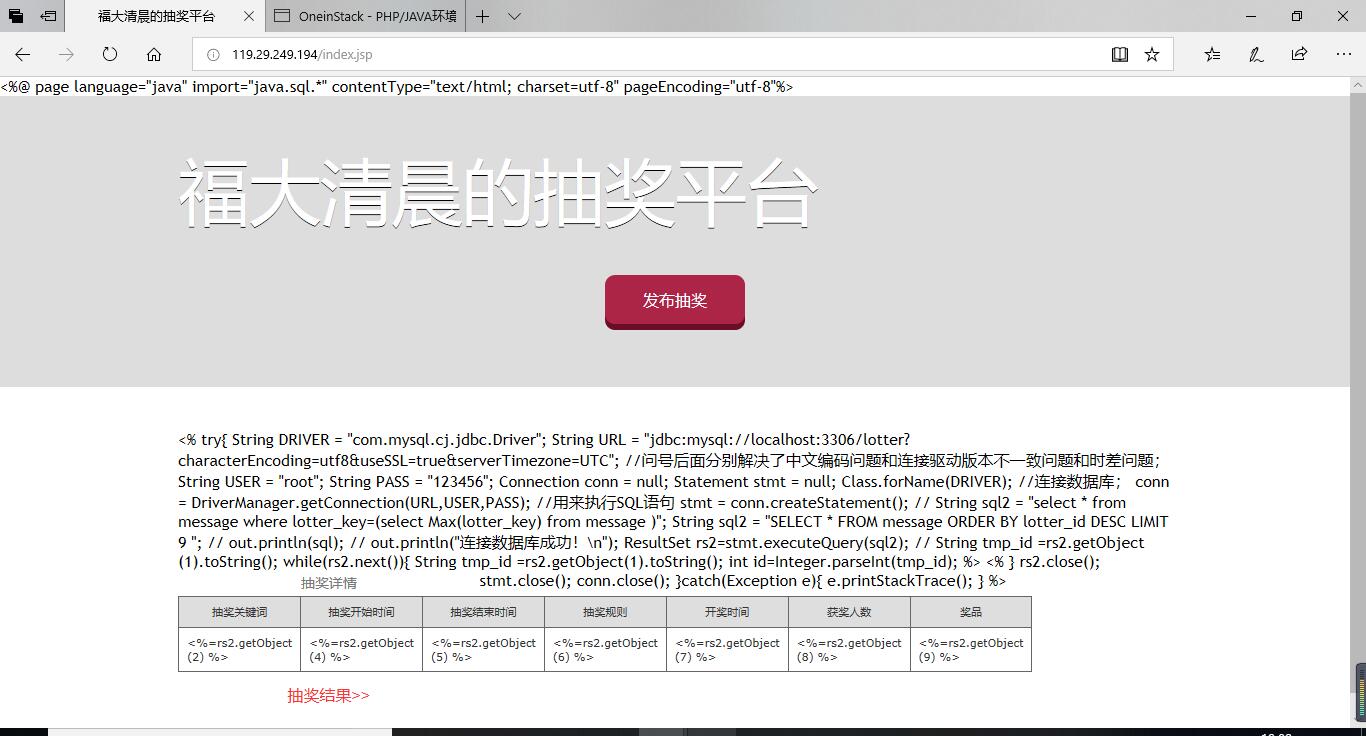
浏览器无法正常编译jsp中嵌入的java代码,导致和数据库交互无法实现,页面之间跳转出现bug。
云端链接(仍在优化中):http://119.29.249.194/index.jsp
目前情况:
附加功能三
本功能利用了Sketch对抽奖数据进行挖掘,可以保持在高速条件下对海量数据的快速处理,节省空间资源。
背景
现抽奖的活动越多,参与抽奖的人数也越来越多。例如:王思聪抽奖微博的转发量、评论数、点赞数均达到了两千万,总数达到了六千万,对每个抽奖账号还需要维护巨大的数据量。当需要对该数据进行处理挖掘的时候,巨大的数据量将消耗巨大的空间和计算资源。然而,我们有时候只需要部分的数据信息,例如:想了解每个地区用户的发言数,我们并不需要记下每一个用的发言数量,并将它们累加起来,在允许的误差范围内,只需要了解这个数量的近似值即可。对此,我们的算法基于Sketch的算法,将巨大的数据散列到Skecth内,在有限的空间内完成巨大的数据计算,减少资源开销。
引言
sketch 是一种基于散列的数据结构,可以对海量数据,实时地存储数据特征信息,只占用较小的空间资源,并且具备在理论上可证明的估计精度与内存的平衡特性。
Sketch的原理
sketch是基于散列的数据结构,通过设置散列函数,将具有相同散列值的键值数据存入相同的桶内,以减少空间开销。桶内的数据值作为测量结果,是真实值的近似。利用开辟二维地址空间,多重散列等技术减少散列冲突,提高测量结果的准确度。Count-Min 是一种典型的 sketch ,在 2004 年被提出。
实际上 Count-Min sketch 用到的是分类的思想:将具有相同哈希值的key归为一类,并使用同一个计数器计数。
当数据到来时,逐个记录所有数据的信息,会带来巨大的计算和空间资源开销。而我们的功能往往也无需记录所有的信息。
基于CM-Sketch实现
Count-Min sketch由多个哈希函数(f1……fn)和一张二维表组成。二维表的每个存储空间维护了一个计数器,其中每个哈希函数分别对应表中的每一行。当数据到来时,需要经过每个哈希函数 f1……fn 的处理,根据处理得到的哈希值分别存入每一行对应哈希值的计数器。有几个哈希函数,就要计算几次。算完后,取这m个计数器中的最小值,作为计算的最终值。
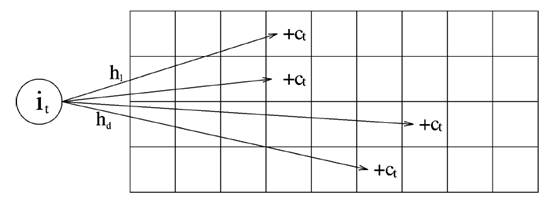
设计考量
测量值偏大:使用哈希的方法会产生冲突,多个数据哈希到同一个桶内,那么这个桶的计数值就会偏大。
-
为什么允许有误差:在大量数据条件下,若把所有信息都准确地记录下来,要消耗大量计算和空间开销,无法满足实时性;而且在很多情况下,并不需要非常精确的数据,在一定程度上可靠的估计值,便足以满足需求。
-
为什么要设置多个哈希函数:如果只设置一个哈希函数,多个流数据存入同一个桶,误差就会很大。通过设计多个哈希函数,减少哈希值的冲突,以减少误差。每个流都要经过所有哈希函数的处理,存入不同的计数器中。计数器的最小值虽然还是大于等于真实值,但最接近真实值。这也是 “ Count-Min ”的由来。
-
哈希函数个数:哈希函数越多,冲突越少,测量值越精确,但计算开销大。需要权衡测量精度和准确度,来设置合适的哈希函数个数。
解决方法
-
使用Sketch的方法,对数据进行处理,对文本数据进行处理后,设置好参数,使用多个散列函数对数据进行处理,将数据的出现次数存入桶内。以此我们的算法基于Sketch的算法,将巨大的数据散列到Skecth内,在有限的空间内完成巨大的数据计算,减少资源开销。
-
将CM-Sketch实现在抽奖系统当中,可以通过调整输入的两个参数值对空间资源和计算准确度进行近似:
- eps (for error), 0.01 < eps < 1
- gamma (probability for accuracy), 0 < gamma < 1
通过输入eps和gamma值,可以根据自己的系统环境调整资源开销。由于估计该测试环境的资源开销大小,需要具备良好的数学知识,并且对个方面数据进行评估计算。我们将空间开销抽象封装成错误估计值和精确度。只需要对自己的需求估计,确定该参数值,就可以满足对空间开销的确定。
- 完成了某个处理场景,对抽奖文本进行处理,得出每个用户的发言次数。
实现效果
以下是处理抽奖数据的类的定义:
public class CountMinSketch {
private static final long LONG_PRIME = 4294967311l;
private int width;
private int depth;
/**
* eps(for error), 0.01 < eps < 1 the smaller the berrer
*/
private double eps;
/**
* gammga(probability for accuracy), 0 < gamma < 1 the bigger the better
*/
private double gamma;
/**
* used in generation of hash funtion
*/
private int aj;
private int bj;
private int total;
/**
* array of arrays of counters
*/
//private HashMap<String, Integer> C = new HashMap<>();
private int[][] C;
private int[][] C2;
/**
* array of hash values for particular item contians two element arrays {aj,
* bj}
*/
private int[][] hashes;
public CountMinSketch(double eps, double gamma) {
this.eps = eps;
this.gamma = gamma;
width = (int) Math.ceil(Math.exp(1.00) / eps);
depth = (int) Math.ceil(Math.log(1.00 / gamma));
total = 0;
C = new int[depth][width];
C2 = new int[depth][width];
initHashes();
}
其中,以下部分完成了调整两个参数值对空间资源和计算准确度的权衡:
/**
* eps(for error), 0.01 < eps < 1 the smaller the berrer
*/
private double eps;
/**
* gammga(probability for accuracy), 0 < gamma < 1 the bigger the better
*/
private double gamma;
width = (int) Math.ceil(Math.exp(1.00) / eps);
depth = (int) Math.ceil(Math.log(1.00 / gamma));
效果截图


以上是算法得出的效果截图,两张图的结果几乎相同,少数数据略有不同,完成的功能的实现,达到预期效果,验证了该近似算法。
遇到的困难及解决方法
组员:胡绪佩
困难:
- 分工没有分很合理;
- 分好工的准备的不够充分;
- 和队友交流不够密切及时,导致他们误入歧途写了很久效率却还很低;
- JavaWeb不熟悉,差不多全忘了...重头再写很艰难;
- web界面细节布局还是处理的不够好,所以界面还挺丑;
- 其他作业、考试实在太多,忙不过来;
- 软工这么多项目,已经占用了太多太多其他学科的时间了;
解决办法
- 下次尽力在开始的时候明确合理分工;
- 争取高效率、及时的和队友交流(这次是因为下午有实验,队友直接就默默地开始打);
- 重头写也不难,不就是通个宵吗?
- 尽量把软工规定在每天什么时间做吧,不能再占用过多其他的时间了。大学不仅仅只有软工实践;
- 考试优先,考后熬夜;
组员:庄卉
困难:alpha还在单机阶段课堂实战已经进入web,时间分配不均,分工出现混乱,作为后端负责人没有检查环境软件版本甚至不少人没有某某软件,导致不熟悉。
解决办法:冷静冷静冷静,尽量不焦虑,事情一件一件来(嗯,体会到了濒临死亡的感觉)
组员:周政演
困难:时间太短,对代码要求很高,不允许迭代修改bug。算法全新,需要构思。附加题构思。
解决办法:考虑到前一段学习的djb2散列函数,修改使用LCG线性同余法,解决随机数的问题。考虑在实际场景下,微博转发数量太大,要进行数据挖掘等工作,需要耗费很大计算和空间资源,故使用LCG和Sketch解决。
组员:刘一好
困难:随机数生成算法需要从网上查阅很多相关资料,需要同后端使用相同的类和传参方式
组员:翟丹丹
困难:
1.编码方面,在其他人面前,真的是有点过于弱。
2.前端方面,浅显的还能写出来,深度一点的就会一直出bug。
3.擅长的东西过于单一,理解的知识也是过于肤浅,个人能力有待提升。
解决办法:
1.看教程,一步步来。
2.看队友操作,积累经验。
解决办法:在网上查找代码,并同其他同学交流,制定相同的传参规则
组员:刘恺琳
困难:前端界面太不友好,不了解代码,修改起来有难度。与后端交接时,返回值有待商榷。
解决办法:查看网上代码,下载模板进行修改。
组员:青元
困难:
- 不会写java,要现学
- 不会写html和css,要现学
解决办法:
- 只能尽量学。
组员:葛家灿
困难:
- 对于javaweb的0知识量,导致的无从下手
- 动态html页面的实现
- 页面之间跳转之后,怎么做到向新页面传递信息
解决办法
- 用servlrt实现一个动态页面的out,页面的数据数据从服务器的数据库中导出
- 用到中的action触发servlet,在form中使用type=hidden,作为一个隐藏域,传递它的value给servlet
- 有函数可以直接实现,服务器内部的页面跳转
组员:何家伟
困难:对于抽奖应该如何实现没有头绪
解决办法:求助了组内的周政演和黄鸿杰同学
组员:黄鸿杰
困难:
- 关于线性同余法的了解很粗浅
- 关于JAVA的String和DATE之间的转换
- 网络上基本上都是伪代码,在转化成JAVA代码过程中各种参数不知道怎么设置
解决办法:
- 稍微熟悉了JAVA代码的书写
- 修改网络博客上的转换实例符合项目的需求
- 找博客看原理,茫茫大海里面找到了有JAVA示例的代码修改
组员:何宇恒
困难:对于web很么有经验,对于排版,真的难为我这个男生
解决办法:找了一个婚庆的模板套了一下,改了些字和图
马后炮
由于本次现场编程开发进度低于预期,给每位同学一个一句话吐槽机会,格式为:如果……,那么……
组员:胡绪佩
如果能睡一个好觉,那么我会补一个月的觉
组员:何家伟
如果我有好好学搜索引擎或者好好看前端,那么这次作业大家做起来都会快很多
组员:周政演
如果时间长一点,那么我还有很多idea可以实现呢
组员:翟丹丹
如果我能力强一些,那么我的团队就可以更快更完美的完成这项项目。
组员:刘一好
如果给定时间长一点或者不在考试之前发布这么复杂的问题,那么大家能更轻松愉快地完成这项任务。
组员:刘恺琳
如果能拿到相关教程,学习一段时间,那么我们就不会感觉很慌张
组员:青元
如果能重来,那么我一定要在课前学习,课上装逼。
组员:庄卉
如果能重来一次,那么我可能会选择做自闭软件或者直接自闭吧
组员:何宇恒
如果我再强一些,那么我的团队就可以更开心的完成
组员:黄鸿杰
如果能重来一次,,那么大家能更轻松愉快地完成这项任务。
组员:葛家灿
如果我再强一些,那么我们就不会感觉很慌张
贡献分评估
| 队员名 | 贡献度 |
|---|---|
| 胡绪佩 | 15% |
| 周政演 | 11.5% |
| 黄鸿杰 | 8% |
| 葛家灿 | 9% |
| 何宇恒 | 4% |
| 胡青元 | 11.5% |
| 刘一好 | 4% |
| 刘恺琳 | 4% |
| 翟丹丹 | 6% |
| 何家伟 | 12% |
| 庄卉 | 15% |
PSP表格
| PSP2.1 | header 2 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | ·估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 150 | 240 |
| · Analysis | 需求分析(包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 180 | 150 |
| · Coding | · 具体编码 | 120 | 600 |
| · Code Review | · 代码复审 | 30 | 120 |
| · Test | ·测试(自我测试,修改代码,提交修改) | 100 | 100 |
| Reporting | 报告 | 10 | 10 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 730 | 1350 |
个人学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 5 | 5 | 阅读《构建之法》,重点了解了 NABCD 模型 |
| 2 | 0 | 0 | 10 | 15 | 找到了适合团队的原型工具,以及如何并行操作 |
| 3 | 68 | 68 | 6 | 6 | python字符处理复习、爬虫学习 |
| 4 | 78 | 146 | 7 | 13 | java爬虫学习 |
| 5 | 194 | 340 | 6 | 19 | 单元测试设计 |
| 6 | 0 | 340 | 10 | 29 | 需求报告撰写 |
| 7 | 0 | 340 | 5 | 34 | Alpha博客撰写 |
| 7 | 0 | 340 | 3 | 37 | Alpha2博客审查 |
| 7 | 0 | 340 | 3 | 40 | Alpha3博客审查 |
| 7 | 0 | 340 | 2 | 42 | Alpha4博客撰写 |
| 7 | 50 | 390 | 10 | 52 | 构思了随机算法、附加功能算法和具体思路,完成撰写叙述 |

