数据结构:散列表的基本概念
散列表
- 用于动态查找的一种数据结构
- 已知的几种查找方法:
- 顺序查找 O(N)
- 二分查找(静态查找)O(logN)
- 二叉搜索树O(h) 为二叉查找树的高度
- 平衡二叉树O(logN)
例子
- 在登录QQ的时候,QQ服务器
是如何核对你的身份?面对庞大的
用户群,如何快速找到用户信息? - 【分析】看看是否可以用二分法查找。
- 十亿(109 ≈ 230)有效用户,用二分查找30次。
- 十亿(109 ≈ 230) × 1K ≈ 1024G,1T连续空间。
- 按有效QQ号大小有序存储:在连续存储空间中,插入和删除一个新QQ号码将需要移动大量数据。
分析
- 如何快速搜索到需要的关键词?如果关键词不方便比较怎么办?
- 查找的本质: 已知对象找位置。
- 有序安排对象:全序、半序
- 直接“算出”对象位置:散列
散列查找法的两项基本工作:
-
计算位置:构造散列函数确定关键词存储位置;
-
解决冲突:应用某种策略解决多个关键词位置相同的问题
-
时间复杂度几乎是常量:O(1),即查找时间与问题规模无关!
-
对对象进行分类,名字+属性。
基本思想
“散列(Hashing)” 的基本思想是:
- 以关键字key为自变量,通过一个确定的函数 h(散列函数),计算出对应的函数值h(key),作为数据对象的存储地址。
- 可能不同的关键字会映射到同一个散列地址上,
即h(keyi) = h(keyj)(当keyi ≠keyj),称为“冲突(Collision)”。
----需要某种冲突解决策略
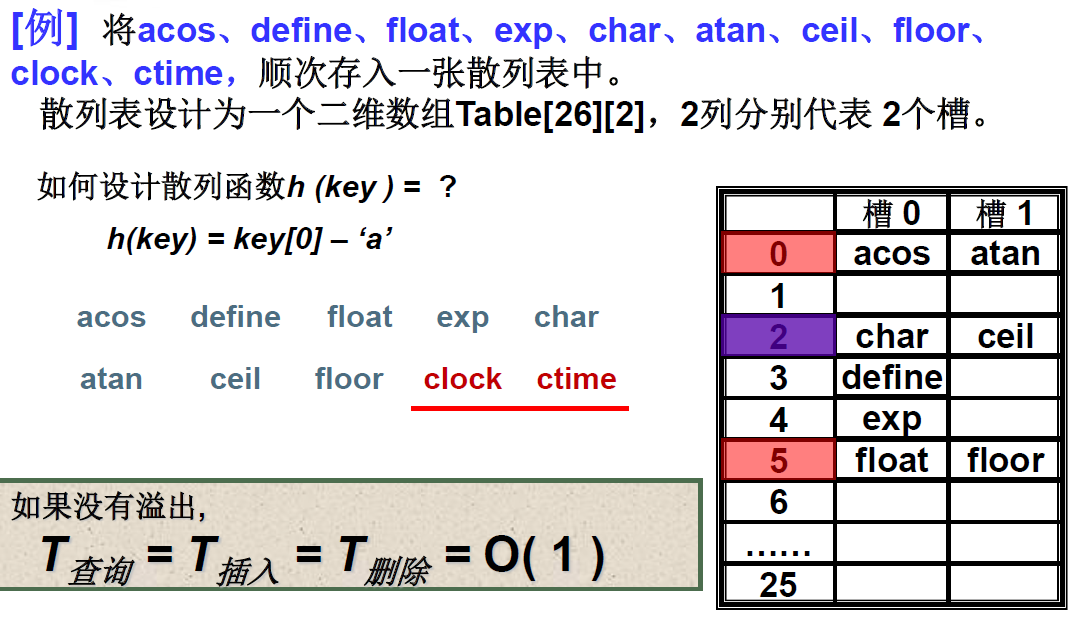
例子
- 装填因子(Loading Factor):设散列表空间大小为m,填入表中元素个数是n,则称α= n / m为散列表的装填因子