
DQN(Deep Reiforcement Learning) 发展历程(一)
马尔可夫理论
马尔可夫性质
- P[St+1 | St] = P[St+1 | S1,...,St]
- 给定当前状态 St ,过去的状态可以不用考虑
- 当前状态 St 可以代表过去的所有状态
- 给定当前状态的条件下,未来的状态和过去的状态相互独立。
马尔可夫过程(MP)
- 形式化地描述了强化学习的环境。
- 包括二元组(S,P)
- 根据给定的转移概率矩阵P,从当前状态St转移到下一状态St+1,
- 基于模型的(Model-based):事先给出了转移概率矩阵P
马尔可夫奖励过程(MRP)
- 和马尔可夫过程相比,加入了奖励r,加入了折扣因子gamma,gamma在0~1之间。
- 马尔可夫奖励过程是一个四元组⟨S, P, R, γ⟩
- 需要折扣因子的原因是
- 使未来累积奖励在数学上易于计算
- 由于可能经过某些重复状态,避免累积奖励的计算成死循环
- 用于表示未来的不确定性
- gamma越大表示越看中未来的奖励
值函数(value function)
- 引入了值函数(value function),给每一个状态一个值V,以从当前状态St到评估未来的目标G的累积折扣奖励的大小
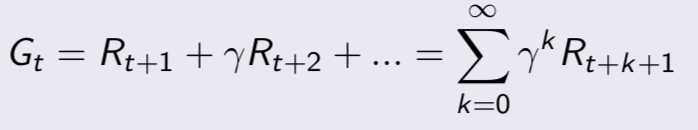
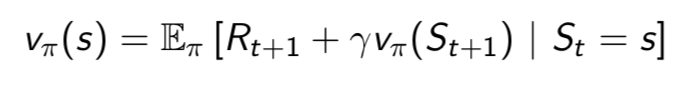
MRP求解
- v = R + γPv (矩阵形式)
- 直接解出上述方程时间复杂度O(n^3), 只适用于一些小规模问题
马尔可夫决策过程(MDP)
- 加入了一个动作因素a,用于每个状态的决策
- MDP是一个五元组⟨S, A, P, R, γ⟩
- 策略policy是从S到A的一个映射
效用函数
- 相比于值函数,加入了一个动作因素

优化的值函数
- 为了求最佳策略,在值函数求解时,选择一个最大的v来更新当前状态对应的v
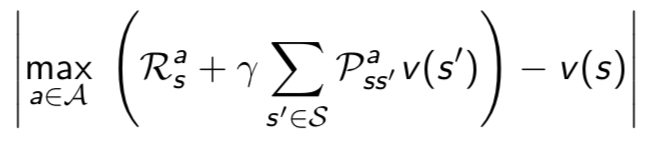
贝尔曼等式
- 和值函数的求解方法相比,不需要从当前状态到目标求解,只需要从当前状态到下一状态即可(根据递推公式)

参考
david siver 课程

