
概率论11 协方差与相关系数
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明。谢谢!
前面介绍的分布描述量,比如期望和方差,都是基于单一随机变量的。现在考虑多个随机变量的情况。我们使用联合分布来表示定义在同一个样本空间的多个随机变量的概率分布。
联合分布中包含了相当丰富的信息。比如从联合分布中抽取某个随机变量的边缘分布,即获得该随机变量的分布,并可以据此,获得该随机变量的期望和方差。这样做是将视线限制在单一的一个随机变量上,我们损失了联合分布中包含的其他有用信息,比如不同随机变量之间的互动关系。为了了解不同随机变量之间的关系,需要求助其它的一些描述量。
协方差
协方差(covariance)表达了两个随机变量的协同变化关系。我们取一个样本空间,即学生的体检数据。学生的身高为随机变量X,学生的体重为随机变量Y。
| 160cm | 170cm | 180cm | |
| 60kg | 0.2 | 0.05 | 0.05 |
| 70kg | 0.05 | 0.3 | 0.05 |
| 80kg | 0.05 | 0.05 | 0.2 |
根据上表,大的身高(180cm)和大的体重(80kg)同时出现的概率较大(0.2),小的身高值(160cm)和小的体重(60kg)的概率也较大(0.2)。偏大的身高往往伴随偏大的体重,偏小的身高常伴随偏小的体重。这种“大”伴随着“大”,“小”伴随着“小”的情形,叫做正相关。根据上面的数据,身高和体重两个随机变量正相关性很强。
另一方面,如果“大”配“小”,“小”配“大”的概率很高,那么两个随机变量负相关。“最萌身高差”是负相关的一个范例。(样本空间为情侣的身高信息。可以定义男生身高为一个随机变量,女生身高为另一个随机变量)

正如其他的分布描述量一样,协方差从概率分布中提取信息,让我们获知分布的“性能”。对于一个已知的联合分布来说,任意两个随机变量之间都可以计算出一个协方差,即一个数值。
定义
协方差的定义如下,如果X和Y是联合分布的随机变量,且分别有期望[$\mu_X$],[$\mu_Y$],那么X和Y的协方差为
$$Cov(X, Y) = E[(X - \mu_X)(Y - \mu_Y)]$$
协方差的定义基于期望。根据期望的定义,协方差可以直接用于离散随机变量和连续随机变量。
我们已经知道,期望是某个随机变量根据概率的加权平均。我们所要加权平均的目标是[$X - \mu_X$]和[$Y - \mu_Y$]的乘积。随机变量和期望的差,代表了随机变量的取值和中心值的偏离程度,也就是我们上面所谓的“偏大”或者“偏小”的情况:正值的偏离表示“偏大”,负值的偏离表示“偏小”。如果是正相关,即大配大,小配小的情况,那么这一乘积为正;如果是负相关,乘积为负。所以,通过[$(X - \mu_X)(Y - \mu_Y)$]这个量,我们表达了X和Y的相关性。
回到刚才的数据来计算相关性,
| 160cm | 170cm | 180cm | |
| 60kg | 0.2 | 0.05 | 0.05 |
| 70kg | 0.05 | 0.3 | 0.05 |
| 80kg | 0.05 | 0.05 | 0.2 |
让身高为X,体重为Y。我们可以通过边缘分布,来分别获得X和Y的分布(回忆一下)。求得X和Y的期望,分别为170和70。计算各个格子中的[$(X-\mu_X)(Y-\mu_Y)$]
| 160cm | 170cm | 180cm | |
| 60kg | 100 | 0 | -100 |
| 70kg | 0 | 0 | 0 |
| 80kg | -100 | 0 | 100 |
上面的两个表,对应的格子相乘,并求和,就得到协方差:
$$\begin{align} Cov(X, Y) & = 0.2 \times 100 + 0.2 \times 100 + 0.05 \times (-100) + 0.05 \times (-100) \\ & = 30 \\ \end{align}$$
在上面的计算中,正相关的项目都分配有比较大的概率值。最终的协方差也是一个正值。
根据期望的性质,我们可以改写协方差的表达形式:
$$\begin{align} Cov(X, Y) & = E(XY - X\mu_X - Y\mu_X + \mu_X \mu_Y) \\ & = E(XY) - E(X)\mu_X - E(Y)\mu_Y + \mu_X \mu_Y \\ & = E(XY) - E(X)E(Y) \\ \end{align}$$
当X和Y独立时,有[$E(XY) = E(X)E(Y)$],[$Cov(X,Y) = 0$]。
(注意,[$Cov(X,Y) = 0$]并不意味着X和Y独立)
相关系数
正的协方差表达了正相关性,负的协方差表达了负相关性。对于同样的两个随机变量来说,计算出的协方差越大,相关性越强。
但随后一个问题,身高和体重的协方差为30,这究竟是多大的一个量呢?如果我们又发现,身高与鞋号的协方差为5,是否说明,相对于鞋号,身高与体重的的相关性更强呢?
这样横向对比超出了协方差的能力范围。从日常生活经验来说,体重的上下浮动大约为20kg,而鞋号的上下浮动大约可能只是5个号码。所以,对于体重来说,5kg与中心的偏离并不算大,而5个号码的鞋号差距,就可能是最极端的情况了。假设身高和体重的相关强度,与身高和鞋码的相关强度类似,但由于体重本身的数值上下浮动更大,所计算出的协方差也会更大。另一个情况,依然是计算身高与体重的协方差。数据完全不变,而只更改单位。我们的体重用克而不是千克做单位,计算出的协防差是原来数值的1000倍!
为了能进行这样的横向对比,我们需要排除用统一的方式来定量某个随机变量的上下浮动。这时,我们计算相关系数(correlation coefficient)。相关系数是“归一化”的协方差。它的定义如下:
$$\rho = \frac{Cov(X, Y)}{\sqrt{Var(X)Var(Y)}}$$
相关系数是用协方差除以两个随机变量的标准差。相关系数的大小在-1和1之间变化。再也不会出现因为计量单位变化,而数值暴涨的情况了。
依然使用上面的身高和体重数据,可以计算出
$$Var(X) = 0.3 \times (60 - 70)^2 + 0.3 \times (80 - 70)^2= 60$$
$$Var(Y) = 0.3 \times (180 - 170)^2 + 0.3 \times (160 - 170)^2 = 60$$
$$\rho = 30 / 60 = 0.5$$
这样一个“归一化”了的相关系数,更容易让人把握到相关性的强弱,也更容易在不同随机变量之间,做相关性的横向比较。
双变量正态分布
双变量正态分布是一种常见的联合分布。它描述了两个随机变量[$X1$]和[$X2$]的概率分布。概率密度的表达式如下:
$$f(x_1, x_2) = \frac{1}{2 \pi \sigma_1 \sigma_2 \sqrt{1 - \rho^2}} \exp\left[ -\frac{z}{2(1 - \rho^2)} \right]$$
其中,
$$z = \frac{(x_1 - \mu_1)^2}{\sigma_1^2} - \frac{2 \rho (x_1 - \mu_1) (x_2 - \mu_2)}{\sigma_1 \sigma_2} + \frac{(x_2 - \mu_2)^2}{\sigma_2^2}$$
[$X_1$]和[$X_2$]的边缘密度分别为两个正态分布,即正态分布[$N(\mu_1, \sigma_1)$], [$N(\mu_2, \sigma_2)$]。
另一方面,除非[$\rho = 0$],否则联合分布也并不是两个正态分布的简单相乘。可以证明,[$\rho$]正是双变量正态分布中,两个变量的相关系数。
我们现在绘制该分布的图像。可惜的是,现在的scipy.stats并没有该分布。我们需要自行编写。
选取所要绘制的正态分布,为了简单起见,让[$\mu_1 = 0$], [$\mu_2=0$], [$\sigma_1 = 1$],[$ \sigma_2 = 1$]。
我们先让[$\rho = 0$],此时的联合分布相当于两个正态分布的乘积。绘制不同视角的同一分布,结果如下。可以看到,概率分布是中心对称的。
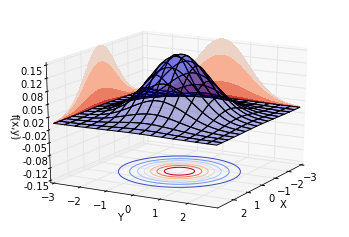
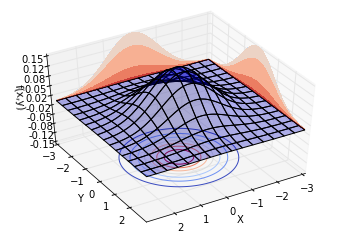
再让[$\rho = 0.8$],也就是说,两个随机变量的相关系数为0.8。绘制不同视角的同一分布,结果如下。可以看到,概率分布并不中心对称。沿着[$Y = X$]这条线,概率曲面隆起,概率明显比较高。而沿着[$Y = -X$]这条线,概率较低。这也就是我们所说的正相关。
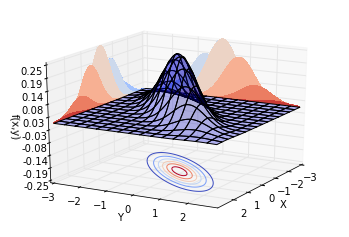
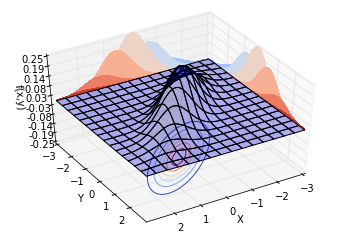
现在,[$\rho$]对于我们来说,有了更具体的现实意义。:-)
# By Vamei from scipy.stats import norm import numpy as np # this function is to generate a pdf of bivariate normal distribution def bivar_norm(mu1, mu2, sigma1, sigma2, rho): # pdf of bivariate norm def pdf(x1, x2): # get z part1 = (x1 - mu1)**2/sigma1**2 part2 = - 2.*rho*(x1 - mu1)*(x2 - mu2)/sigma1*sigma2 part3 = (x2 - mu2)**2/sigma2**2 z = part1 + part2 + part3 cof = 1./(2.*np.pi*sigma1*sigma2*np.sqrt(1 - rho**2)) return cof*np.exp(-z/(2.*(1 - rho**2))) return pdf pdf1 = bivar_norm(0, 0, 1, 1, 0) pdf2 = bivar_norm(0, 0, 1, 1, 0.8) from mpl_toolkits.mplot3d import Axes3D from matplotlib import cm from matplotlib.ticker import LinearLocator, FormatStrFormatter import matplotlib.pyplot as plt # plot function def space_surface(pdf, xp, yp, zlim, rot1=30, rot2=30): fig = plt.figure() ax = fig.gca(projection='3d') X = np.arange(*xp) Y = np.arange(*yp) X, Y = np.meshgrid(X, Y) Z = pdf(X, Y) surf = ax.plot_surface(X, Y, Z, rstride=8, cstride=8, alpha = 0.3) cset = ax.contour(X, Y, Z, zdir='z', offset=zlim[0], cmap=cm.coolwarm) cset = ax.contourf(X, Y, Z, zdir='x', offset=xp[0], cmap=cm.coolwarm) cset = ax.contourf(X, Y, Z, zdir='y', offset=yp[0], cmap=cm.coolwarm) for angle in range(rot1 + 0, rot1 + 360): ax.view_init(rot2, angle) ax.set_zlim(*zlim) ax.zaxis.set_major_locator(LinearLocator(10)) ax.zaxis.set_major_formatter(FormatStrFormatter('%.02f')) ax.set_xlabel("X") ax.set_ylabel("Y") ax.set_zlabel("f(x,y)") # fig.colorbar(surf, shrink=0.5, aspect=5) xp = [-3, 3, 0.05] yp = [-3, 3, 0.05] zlim1 = [-0.15, 0.15] zlim2 = [-0.25, 0.25] space_surface(pdf1, xp, yp, zlim1, 30, 20) space_surface(pdf1, xp, yp, zlim1, 60, 45) space_surface(pdf2, xp, yp, zlim2, 30, 20) space_surface(pdf2, xp, yp, zlim2, 60, 45)
总结
协方差
“归一化”的度量: 相关系数
如果你喜欢这篇文章,欢迎推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号