Kafka常用命令及详细介绍
常用操作
- 获取ip
export ipadd=$(hostname -I | tr -d [:space:])
- 查询操作
# 查询 group 分组
./kafka-consumer-groups.sh --bootstrap-server $ipadd:9092 --list
# 查看消费情况
./kafka-consumer-groups.sh --bootstrap-server $ipadd:9092 --describe --group logstash
# 查看 topic
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --list
# 查看大小
./kafka-log-dirs.sh --describe --bootstrap-server $ipadd:9092 --topic-list xwmicro
# 查看分片数
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic public_to_elk
- 分片操作
# 增加分片数量
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --alter --topic xwmicro --partitions 4
- 新建 topic
./kafka-topics.sh --create --topic bank_credit_kafka_topic --replication-factor 1 --partitions 1 --zookeeper localhost:2181
- 删除操作
# 删除废弃的 topic
./zookeeper-shell.sh localhost:2181 rmr /brokers/topics/hestia-binhai
# 删除废弃的 group
./kafka-consumer-groups.sh --bootstrap-server $ipadd:9092 --delete --group console-consumer-3189
- 释放磁盘空间
# 立即清空
./kafka-configs.sh --zookeeper 127.0.0.1:2181 --alter --entity-type topics --entity-name xwmicro --add-config retention.ms=1000
# 1 day 24*3600*1000
./kafka-configs.sh --zookeeper 127.0.0.1:2181 --alter --entity-type topics --entity-name xwmicro --add-config retention.ms=86400000
# 3day 24*3600*1000*3 (如果延迟超过3天,消息会丢失)
./kafka-configs.sh --zookeeper 127.0.0.1:2181 --alter --entity-type topics --entity-name xwmicro --add-config retention.ms=259200000
- 调整 topic 接收单个 message 的大小
# 10M
./kafka-configs.sh --zookeeper 127.0.0.1:2181 --alter --entity-type topics --entity-name ylbank_credit_kafka_topic --add-config max.message.bytes=10485760
- 积压累计
./kafka-consumer-groups.sh --bootstrap-server $ipadd:9092 --describe --group logstash | awk '/10.0/{sum+=$5} END {print sum}'
Sentry kafka 清理
sentry 实例 172.16.3.148, docker-compose 运行,使用 docker system df -v 查看 Images、Containers、Volumes 占用情况。
其中数据占用较大的是是 sentry-postgres 和 sentry-kafka。我们的环境中,sentry-kafka 磁盘占用一度超过 210G, sentry-postgres 超过 70G,累计300G磁盘直接满了,必须要清理老旧数据。
根据资料,这两个主要包括监控数据和kafak日志,因此可以根据自身需要设置保留时间。监控数据保留90天,日志数据保留7天;
- 清理 postgres
# 设置sentry保留90天监控数据,但不会直接从postgres删除,只是将它标记为 deleted
docker-compose --file docker-compose.yml exec worker sentry cleanup --days 90
# 在 postgres 容器中执行数据清理
# postgres 在清理旧表时,会创建新的临时表存储保留的数据,因此需要一定的磁盘空间,否则会报错
docker exec -it sentry_onpremise_postgres_1 bash
vacuumdb -U postgres -d postgres -v -f --analyze
- kafka log
# 先将日志保留时间设置为1天,之前应该是存了1年多
docker exec sentry_onpremise_kafka_1 kafka-configs --zookeeper zookeeper:2181 --alter --entity-type topics --entity-name events --add-config retention.ms=86400000
# 待磁盘空间释放过后,再设置日志保留周期为7天
docker exec sentry_onpremise_kafka_1 kafka-configs --zookeeper zookeeper:2181 --alter --entity-type topics --entity-name events --add-config retention.ms=604800000
Kafka 术语
The basic architecture of Kafka is organized around a few key terms: topics, producers, consumers, and brokers.
All Kafka messages are organized into topics. If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic. A consumer pulls messages off of a Kafka topic while producers push messages into a Kafka topic. Lastly, Kafka, as a distributed system, runs in a cluster. Each node in the cluster is called a Kafka broker.
Kafka 主题剖析
Kafka topics are divided into a number of partitions.
Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers — each partition can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel. Consumers can also be parallelized so that multiple consumers can read from multiple partitions in a topic allowing for very high message processing throughput.
Each message within a partition has an identifier called its offset. The offset the ordering of messages as an immutable sequence. Kafka maintains this message ordering for you. Consumers can read messages starting from a specific offset and are allowed to read from any offset point they choose, allowing consumers to join the cluster at any point in time they see fit. Given these constraints, each specific message in a Kafka cluster can be uniquely identified by a tuple consisting of the message’s topic, partition, and offset within the partition.
-
Log Anatomy
Another way to view a partition is as a log. A data source writes messages to the log and one or more consumers reads from the log at the point in time they choose. In the diagram below a data source is writing to the log and consumers A and B are reading from the log at different offsets. -
Data Log
Kafka retains messages for a configurable period of time and it is up to the consumers to adjust their behaviour accordingly. For instance, if Kafka is configured to keep messages for a day and a consumer is down for a period of longer than a day, the consumer will lose messages. However, if the consumer is down for an hour it can begin to read messages again starting from its last known offset. From the point of view of Kafka, it keeps no state on what the consumers are reading from a topic.
Kafka 生产者
Producers write to a single leader, this provides a means of load balancing production so that each write can be serviced by a separate broker and machine. In the first image, the producer is writing to partition 0 of the topic and partition 0 replicates that write to the available replicas.
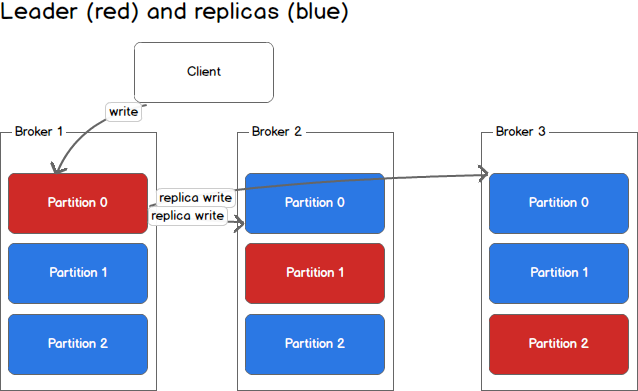
In the second image, the producer is writing to partition 1 of the topic and partition 1 replicates that write to the available replicas.
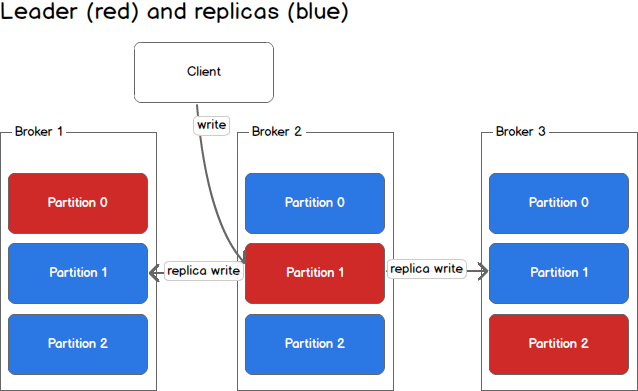
Since each machine is responsible for each write, throughput of the system as a whole is increased.
kafka 消费者和消费组
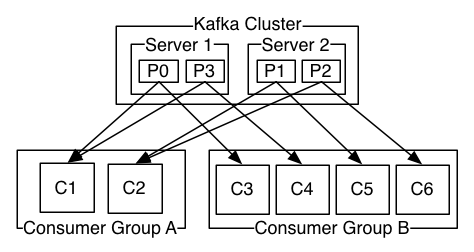
Consumers read from any single partition, allowing you to scale throughput of message consumption in a similar fashion to message production. Consumers can also be organized into consumer groups for a given topic — each consumer within the group reads from a unique partition and the group as a whole consumes all messages from the entire topic. If you have more consumers than partitions then some consumers will be idle because they have no partitions to read from. If you have more partitions than consumers then consumers will receive messages from multiple partitions. If you have equal numbers of consumers and partitions, each consumer reads messages in order from exactly one partition.
The following picture from the Kafka documentation describes the situation with multiple partitions of a single topic. Server 1 holds partitions 0 and 3 and server 2 holds partitions 1 and 2. We have two consumer groups, A and B. A is made up of two consumers and B is made up of four consumers. Consumer Group A has two consumers of four partitions — each consumer reads from two partitions. Consumer Group B, on the other hand, has the same number of consumers as partitions and each consumer reads from exactly one partition.
一致性和可用性
Consistency and Availability
Before beginning the discussion on consistency and availability, keep in mind that these guarantees hold as long as you are producing to one partition and consuming from one partition. All guarantees are off if you are reading from the same partition using two consumers or writing to the same partition using two producers.
Kafka makes the following guarantees about data consistency and availability:
(1) messages sent to a topic partition will be appended to the commit log in the order they are sent,
(2) a single consumer instance will see messages in the order they appear in the log,
(3) a message is committed when all in sync replicas have applied it to their log, and
(4) any committed message will not be lost, as long as at least one in sync replica is alive.
The first and second guarantee ensure that message ordering is preserved for each partition. Note that message ordering for the entire topic is not guaranteed. The third and fourth guarantee ensure that committed messages can be retrieved. In Kafka, the partition that is elected the leader is responsible for syncing any messages received to replicas. Once a replica has acknowledged the message, that replica is considered to be in sync. To understand this further, lets take a closer look at what happens during a write.
写入处理
Handling Writes
When communicating with a Kafka cluster, all messages are sent to the partition’s leader. The leader is responsible for writing the message to its own in sync replica and, once that message has been committed, is responsible for propagating the message to additional replicas on different brokers. Each replica acknowledges that they have received the message and can now be called in sync.
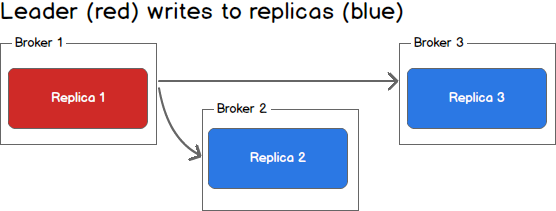
Leader Writes to Replicas
When every broker in the cluster is available, consumers and producers can happily read and write from the leading partition of a topic without issue. Unfortunately, either leaders or replicas may fail and we need to handle each of these situations.
失败处理
Handling Failure
- First Replica Fails
What happens when a replica fails? Writes will no longer reach the failed replica and it will no longer receive messages, falling further and further out of sync with the leader.
In the image below, Replica 3 is no longer receiving messages from the leader.
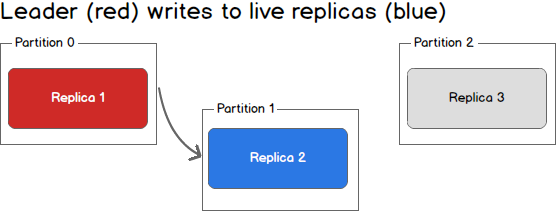
- Second Replica Fails
What happens when a second replica fails? The second replica will also no longer receive messages and it too becomes out of sync with the leader.
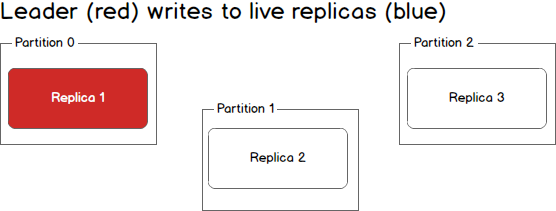
At this point in time, only the leader is in sync. In Kafka terminology we still have one in sync replica even though that replica happens to be the leader for this partition.
- Third Replica Fails
What happens if the leader dies? We are left with three dead replicas.
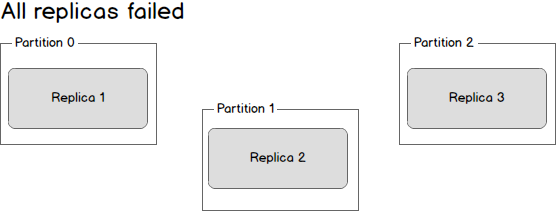
Replica one is actually still in sync — it cannot receive any new data but it is in sync with everything that was possible to receive. Replica two is missing some data, and replica three (the first to go down) is missing even more data.
Given this state, there are two possible solutions:
The first, and simplest, scenario is to wait until the leader is back up before continuing. Once the leader is back up it will begin receiving and writing messages and as the replicas are brought back online they will be made in sync with the leader.
The second scenario is to elect the second broker to come back up as the new leader. This broker will be out of sync with the existing leader and all data written between the time where this broker went down and when it was elected the new leader will be lost. As additional brokers come back up, they will see that they have committed messages that do not exist on the new leader and drop those messages. By electing a new leader as soon as possible messages may be dropped but we will minimized downtime as any new machine can be leader.
Taking a step back, we can view a scenario where the leader goes down while in sync replicas still exist.
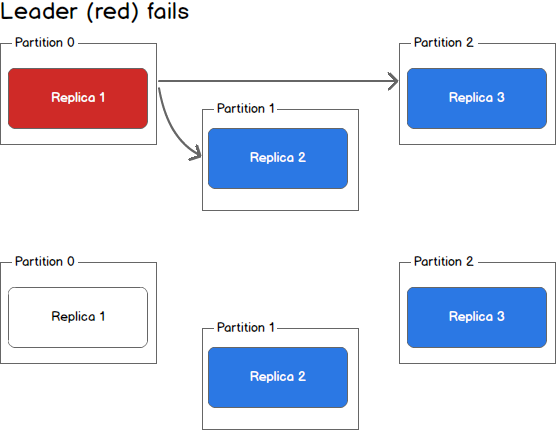
- Leader Fails
In this case, the Kafka controller will detect the loss of the leader and elect a new leader from the pool of in sync replicas. This may take a few seconds and result in LeaderNotAvailable errors from the client. However, no data loss will occur as long as producers and consumers handle this possibility and retry appropriately.
Kafka 客户端一致性
Consistency as a Kafka Client
Kafka clients come in two flavours: producer and consumer. Each of these can be configured to different levels of consistency.
For a producer we have three choices. On each message we can (1) wait for all in sync replicas to acknowledge the message, (2) wait for only the leader to acknowledge the message, or (3) do not wait for acknowledgement. Each of these methods have their merits and drawbacks and it is up to the system implementer to decide on the appropriate strategy for their system based on factors like consistency and throughput.
On the consumer side, we can only ever read committed messages (i.e., those that have been written to all in sync replicas). Given that, we have three methods of providing consistency as a consumer: (1) receive each message at most once, (2) receive each message at least once, or (3) receive each message exactly once. Each of these scenarios deserves a discussion of its own.
For at most once message delivery, the consumer reads data from a partition, commits the offset that it has read, and then processes the message. If the consumer crashes between committing the offset and processing the message it will restart from the next offset without ever having processed the message. This would lead to potentially undesirable message loss.
A better alternative is at least once message delivery. For at least once delivery, the consumer reads data from a partition, processes the message, and then commits the offset of the message it has processed. In this case, the consumer could crash between processing the message and committing the offset and when the consumer restarts it will process the message again. This leads to duplicate messages in downstream systems but no data loss.
Exactly once delivery is guaranteed by having the consumer process a message and commit the output of the message along with the offset to a transactional system. If the consumer crashes it can re-read the last transaction committed and resume processing from there. This leads to no data loss and no data duplication. In practice however, exactly once delivery implies significantly decreasing the throughput of the system as each message and offset is committed as a transaction.
In practice most Kafka consumer applications choose at least once delivery because it offers the best trade-off between throughput and correctness. It would be up to downstream systems to handle duplicate messages in their own way.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号