

调整inference过程中,神经网络识别物体种类数,思路整理
1.考虑使用训练好的imagenet模型分类图像
思路
来自http://www.cnblogs.com/sunshineatnoon/p/4678107.html,博客中作者使用bvlc_reference_caffenet.caffemodel模型来进行图像分类,重点在代码的最后一段
32 #预测图片类别
33 prediction = net.predict([input_image])
34 print 'predicted class:',prediction[0].argmax()
35
36 # 输出概率最大的前5个预测结果
37 top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
38 print labels[top_k]
考虑可以通过修改这一部分来调整预测到的物体种类
可能存在的问题
如果修改这段代码,是否只是不显示某些结果,而并不是不进行预测,如果这样的话时间上没有区别
相关资料
https://www.cnblogs.com/denny402/p/5111018.html 同样使用bvlc_reference_caffenet.caffemodel,流程更加清晰
2.使用yolo识别物体
(1)思路
对一张图片中的物体进行ps处理,以此达到改变物体数目的目的
(2)实验结果
当图片中只有1个人时,耗时如下

当图片中有5个人一只马时
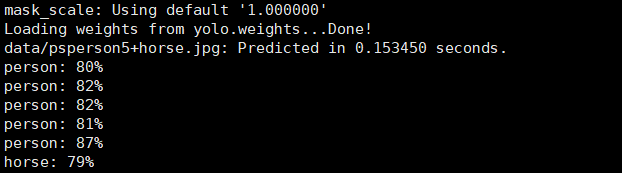
当图片中有5个人6只狗1个马时
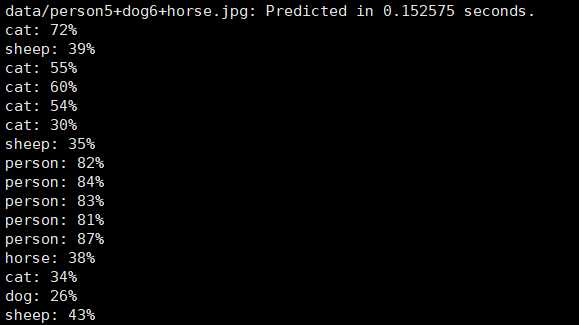
根据以上结果,初步可以得出结论,使用yolo做模型时,对于同样大小的图片,运行时间与图片中检测到的物体数目不存在直接的关系。当然因为ps的关系,有识别错误的现象,应该不影响结论
(3)可能存在的问题
问题应该是来自yolo本身,在论文中介绍,这是一个只需要一次就能够识别所有物体的模型
(4)相关资料
http://blog.csdn.net/ma3252788/article/details/74659230

 浙公网安备 33010602011771号
浙公网安备 33010602011771号