爬取糗事百科最新的段子
最近突然对爬虫颇感兴趣,于是一直在学习静觅的技术博客,这篇权当是篇学习笔记罢。
1. 准备
简单起见,我们只需要实现把最新的段子爬取,并且把图片过滤即可。也就是说,我们需要爬取的网站是http://www.qiushibaike.com/hot/page/1,1表示最新一页,第一页的意思。
糗事百科不需要登录即可以实现爬虫,但是有个地方需要注意,获取网页的时候需要加入含有 User-Agent 信息的头部。这个名为User-Agent的信息,可以这样获得,如下:
打开浏览器,进入网址,按下F12,接着按下F5刷新页面,在调试面板上点击Network,效果如下:
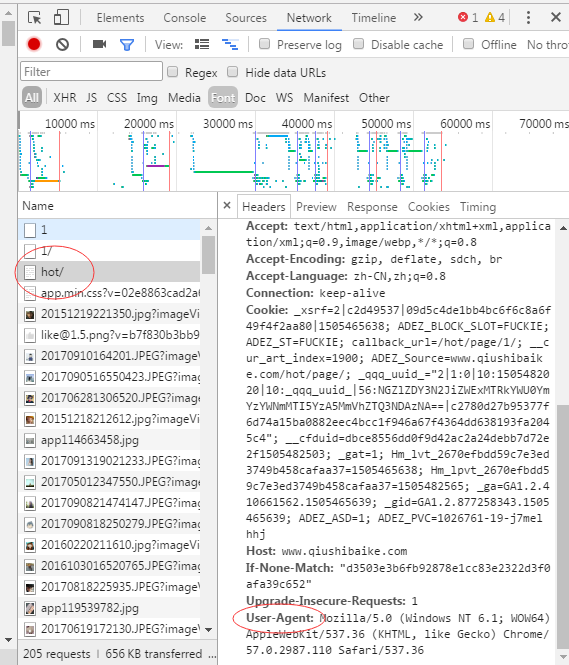
有个这个字段的头部信息,我们就可以开开心心地爬虫了。接下来则是观察其html的标签、结构,然后构造正则表达式去匹配。空白处右键选择查看网页源代码,如下:

有了这些分析,写代码应该就很容易了。
2. 代码
# -*- coding:utf-8 -*-
import urllib2
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
def analysis(ori_html):
pattern = re.compile('<div class="article block untagged mb15 .*?" id=.*?>.*?' \
'<div.*?author clearfix">.*?<a.*?<img.*?alt="(?P<user>.*?)">.*?</a>.*?<a.*?<h2>.*?</h2>' \
'.*?<div.*?<span>(?P<content>.*?)</span>.*?stats-vote">.*?<i class="number">(?P<vote>.*?)</i>' \
'.*?stats-comments">.*?<i class="number">(?P<comment>.*?)</i>', re.S)
items = re.findall(pattern, ori_html)
count = 1
for item in items:
print "---------------------------------" + str(count) + "---------------------------------"
user = item[0]
content = item[1]
vote = item[2]
comment = item[3]
print "用户:" + user
print "内容:\n\t" + content.strip('\n').replace('<br/>', '\n\t')
print "点赞数:" + vote
print "评论数:" + comment
count += 1
print ""
if __name__ == "__main__":
page = 1
url = "http://www.qiushibaike.com/hot/page/" + str(page)
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) " \
"AppleWebKit/537.36 (KHTML, like Gecko) " \
"Chrome/57.0.2987.110 Safari/537.36"
headers = {'User-Agent' : user_agent}
try:
request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
ori_html = response.read().decode('UTF-8')
analysis(ori_html)
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
3. 运行结果
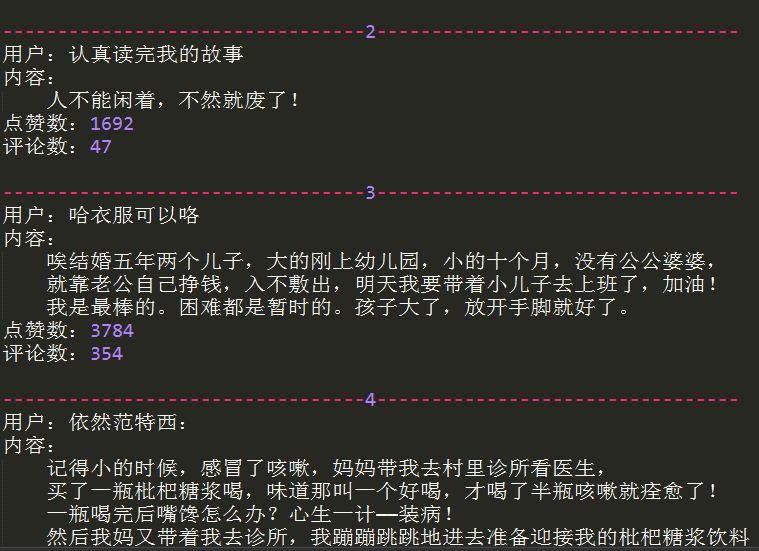
作者: vachester
出处:http://www.cnblogs.com/vachester/
邮箱:xcchester@gmail.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号